目录
1、研究背景
2、研究的目的
3、方法论
3.1 Boundary Point Detection Network(BPDN)
3.2 Recognition Network
3.3 Loss Functions
4、实验及结果
论文连接:https://ojs.aaai.org/index.php/AAAI/article/view/6896
1、研究背景
最近,旨在同时从杂乱图像中检测和识别文本的端到端文本识别在计算机视觉中受到了越来越多的关注。由于文本检测广泛的实际应用,如办公自动化、网络内容安全、智能交通系统、地理位置和视觉搜索,从自然图像中自动阅读文本已引起极大关注。
在过去的十年中,场景文本检测和识别作为阅读系统的两个独立的子任务被广泛研究,但事实上,文本检测与识别是高度相关且相互补充的。最近的端到端文本识别方法证实了这一假设,该方法将检测和识别阶段与端到端可训练神经网络相结合。这些定位方法遵循类似的流程。首先,检测每个文本实例的水平/定向边界框。然后,裁剪检测到的边界框内的图像块或CNN特征,并将其馈送到序列识别模型。得益于特征共享和联合优化,可以同时增强检测和端到端识别的性能。尽管取得了可喜的进展,但大多数现有的点样方法受到处理不规则形状文本(如曲线文本)的困扰。对于一般的端到端OCR系统,处理具有任意形状的文本是不可避免的,因为曲线文本和其他类型的不规则文本在我们的现实世界中非常常见。
2、研究的目的
传统的方法中,检测到的每个文本实例的边界框都是用矩形来表示,但矩形框在描述不规则文本的边界框时有很大的局限性,因为它包含或多或少的背景信息,这给文本识别阶段带来了困难。在本文中,检测的目的是预测一组边界点,其对于描述场景文本的各中妆容更灵活。同时,边界点可以准确获取不规则文本区域的CNN特征。利用边界点,不规则文本可以容易地被转换或矫正为规则文本。为了有效 的提取文本边界点,采用从粗到细的策略,使用两级CNN检测器检测每个文本实例的最小定向矩形框。然后,在定向矩形框中执行边界的预测。基于边界点的方法比矩形框更灵活、更准确地表示任意形状的文本。
3、方法论
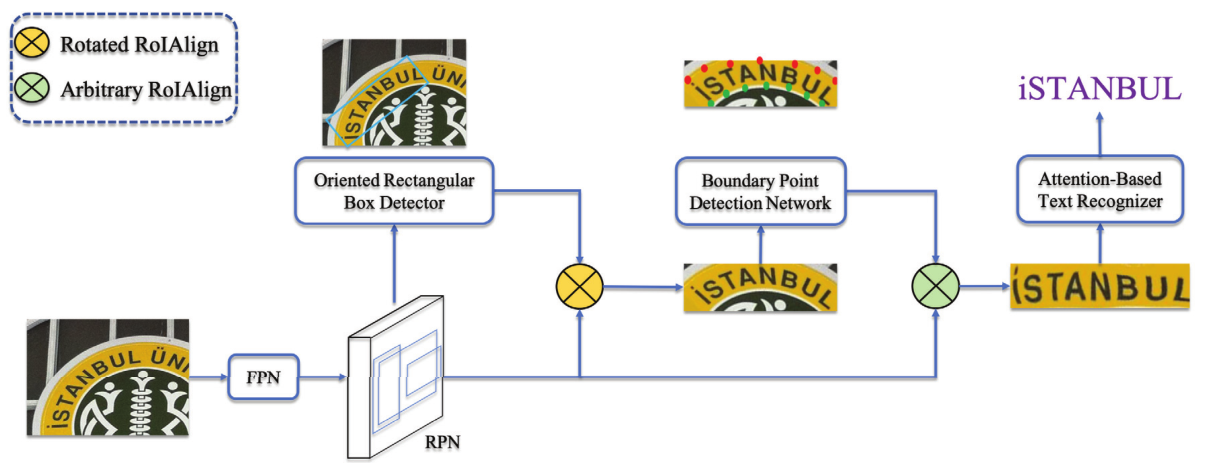
图1
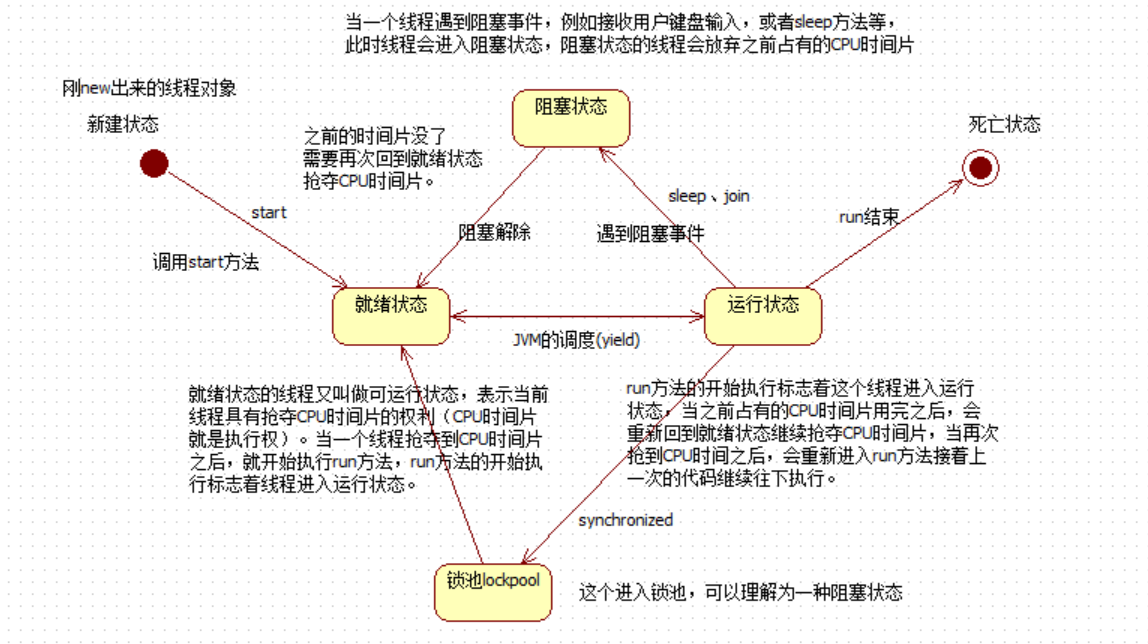
如图1所示, 主要由三部分组成:定向矩形框检测器、边界点检测网络和识别网络。
定向矩形框检测器:应用 RPN,主干配备有 ResNet-50,以生成水平文本建议。然后通过预测每个提案(矩形框)的中心点、高度、宽度和方向,生成每个提案的定向矩形框。
边界点检测网络(BPDN):回归每个定向矩形框的边界点。
识别网络:利用预测的边界点,将特征图矫正为常规图,供识别网络使用。
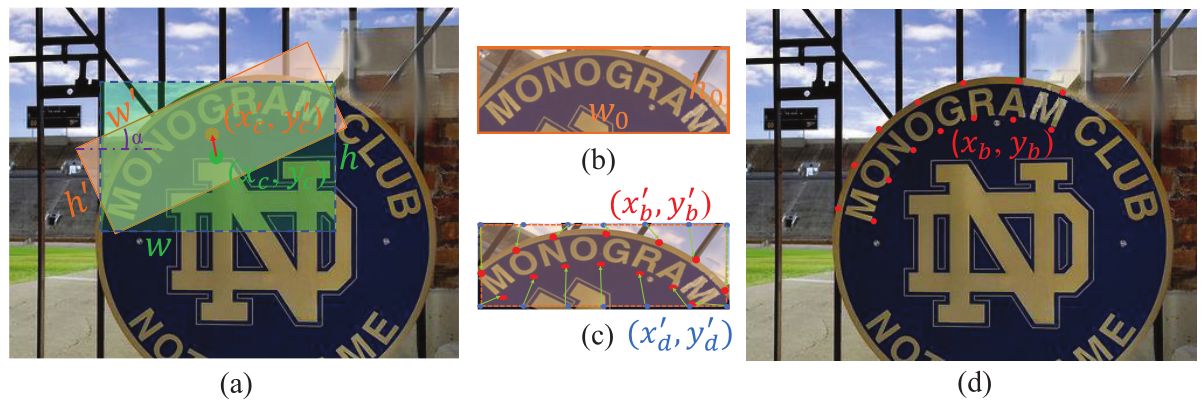
图2
图2(a)中,BPDN 可以预测每个水平建议的边界点,但受到各种方向和形状的文本实例的影响,包含了更多的背景噪声和更强的变形。为了缓解这种影响,预测每个建议的定向矩形框(图2(a)中红色边框)。具体细节:预测其中心点(绿点),高度(h),宽度(w)和方向(绿点-->红点的那个箭头)。然后沿着方向重新计算宽()、高(
),最后画出的红色矩形框就为定向矩形框,红点为定向矩形框的中心。然后通过 RotateRolAlign(图1) 将特征图转换为水平图,称为最小矩形框,如图2(b)。图2(c)表示从均匀分布在最小矩形框的上下两侧的一组默认点回归到边界点。图2(d)将边界点与原始图像对齐。
3.1 Boundary Point Detection Network(BPDN)
BPDN 由四个堆叠的 3X3 卷积层和一个完全连接层组成。受 RPN 的启发,建议基于默认锚点(默认点)进行回归。预定义一组默认点供边界点参考,如图2(c)。默认点在最小矩形框的长边均匀分布,每条长边 K 个点,共 2K 个点。用这 2K 个默认点通过坐标偏移得到 2K 个边界点。
BPDN 模块会给 2K 个默认点预测 4K 个向量来作为 2K 个边界点的坐标偏移。有了坐标偏移(Δx, Δy),那么边界点()就可以表示为(图3中红色的点):
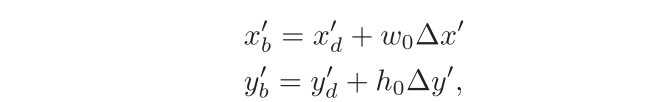
其中,()为默认点,图3中蓝色的点。
和
为最小矩形框的宽和高。
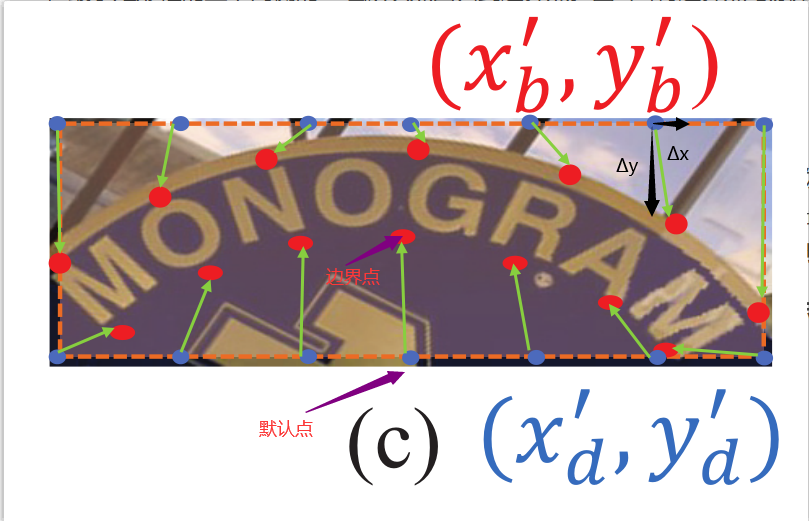
图3,图2中的c图放大后
为了与原始特征一致,我们使用如下公式
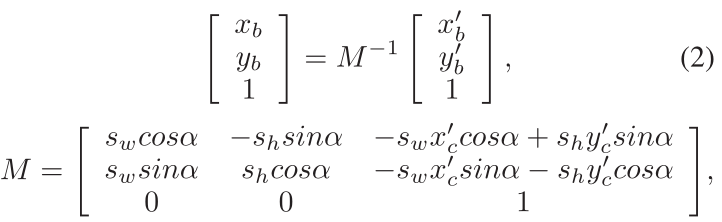
将变换为水平特征图(图2中c)中的边界点() 还原为原始的边界点 (
)(图2中d)。(
) 是定向矩形框的中心点。
和
分别等于
和
。
和
为最小矩形框的宽和高,
和
为定向矩形框的宽和高。α 是从 x 轴的正方向到平行与定向矩形框的长边的角度。
3.2 Recognition Network
CRNN 是第一种通过将 CRNN 和 RNN 结合在端到端网络中,将文本识别视为序列到序列问题的方法。识别分支的架构如图4所示。
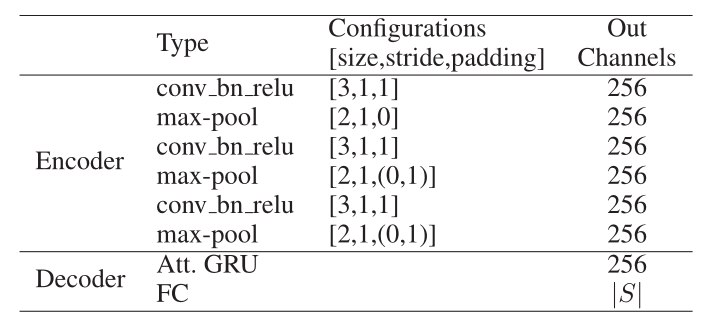
图4 ,识别分支的架构由三个堆叠的卷积层组成。“Att.GRU”代表GRU解码器和
一个完全连接层。|s| 表示解码字符数,实验中设置为63,对应数字(0, 9), 英文
字符(a/z, A/Z)和序列结束符。
首先,将矫正后的特征输入编码器提取更高级的特征序列 。然后采用基于注意力的解码器将
转化为符号序列
,其中
是标签序列的长度。在步骤
,解码器根据编码器输出
,内部状态
和上一步骤中预测的结果
来预测字符。在当前步骤中,解码器通过其注意力机制计算注意力权重
的向量来开始。然后,根据下面公式加权特征
。
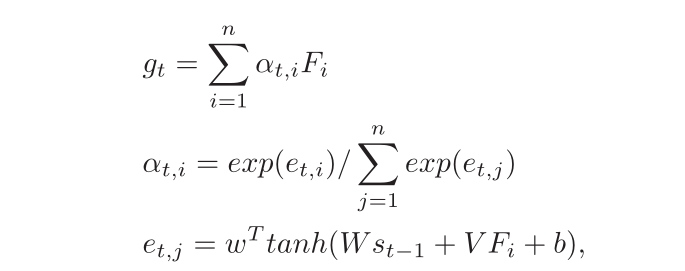
其中 都是可训练的权重。
将 和
作为输入,RNN 通过 下面公式 计算输出向量
和新的状态向量
,其中
是
和
的独热嵌入的连级。
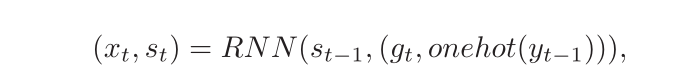
在我们的方法中,GRU 被用作 RNN 单位。最后,通过
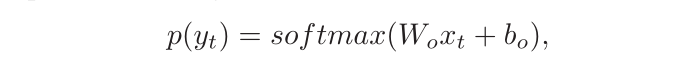
预测当前步骤符号的分布,其中 和
是可学习的参数。
3.3 Loss Functions
目标函数的损失由四个部分组成,
![]()
其中 是 RPN 的损失,
是从轴对齐矩形建议回归到定向矩形框的损失(获得定向矩形框的损失)。
是边界点的损失,计算为平滑-L1 损失。
为识别损失。
计算如下,其中
是第 i 个预测边界点(默认点),其关联的目标边界点是
。
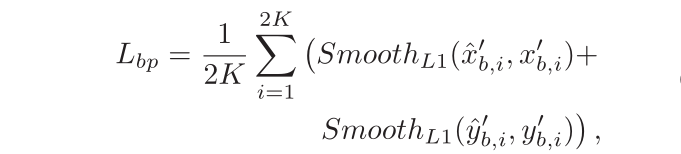
在识别网络中,识别损失可以表示为
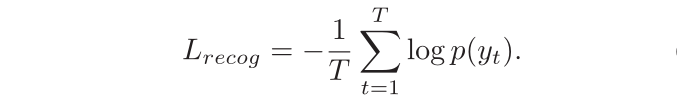
4、实验及结果
略