vector的优点
- 下标随机访问
vector的底层是一段连续的物理空间,所以支持随机访问 - 尾插尾删效率高
跟数组类似,我们能够很轻易的找到最后一个元素,并完成各种操作 - cpu高速缓存命中率高
因为系统在底层拿空间的时候,是拿一段进cpu,不是只拿单独一个,会提前往后多拿一点,vector的物理地址是连续的,所以我们再拿到数据的时候,cpu访问后面的数据会更快
vector的缺点
- 前面部分的插入删除数据效率低
如果我们要在前面或中间插入或者删除数据,我们不能直接删,我们需要挪动数据,去覆盖或者增加一段空间,这样我们挪动数据的效率就是O(N) - 扩容有消耗,可能存在一定的空间浪费
正常情况下我们vector的扩容机制是一旦达到当前空间的capacity(容量)那么我们扩容原空间的1.5倍或者2倍数(vs一般是1.5倍而g++是2倍),这样扩容就有可能导致空间浪费,而且频繁扩容也会影响效率
list的优点
- 按需申请释放,不需要扩容
list是一个带头双向循环链表,那么链表就是一个个独立的空间链接起的,需要多少,就new多少,不存在空间浪费 - 任意位置的插入删除效率高(对比vector)
因为list是双向循环链表,我们需要插入新的元素只需要改变原数据的next与prev(下一个和上一个),所以我们的插入删除效率是O(1)
list的缺点
- 不支持下标随机访问
因为我们list是链表,我们存放数据的物理地址并不是连续的,所以我们也就不能支持随机访问 - cpu高速缓存命中率低
还是跟它的物理空间地址不连续有关,cpu提前存的一段数据,可能跟下一个数据完全没有联系,因为它们空间不连续,所以也就命中率低
vector与list就是一个互补的关系
迭代器的差别
既然list是不支持随机访问,那么我们该怎么去访问数据呢?我们肯定不能直接去访问底层的next与prev,我们还是使用迭代器,那么这个迭代器与vector和string的迭代器有何差别呢?
迭代器有什么价值?
- 封装底层实现,不暴露底层的实现细节
- 提供统一的访问方式,降低使用成本
iterator:
- 内嵌类型(int double)
- 行为像指针一样的封装后的类型

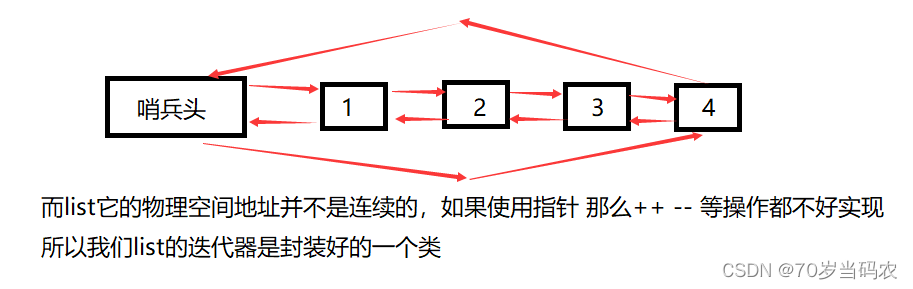
参考list迭代器模拟底层代码:
template<class T, class Ref, class Ptr>
struct __list_iterator
{
typedef list_node<T> node;
typedef __list_iterator<T, Ref, Ptr> Self;
node* _pnode;
__list_iterator(node* p)
:_pnode(p)
{}
Ptr operator->()
{
return &_pnode->_data;
}
Ref operator*()
{
return _pnode->_data;
}
Self& operator++()
{
_pnode = _pnode->_next;
return *this;
}
Self operator++(int)
{
Self tmp(*this);
_pnode = _pnode->_next;
return tmp;
}
Self& operator--()
{
_pnode = _pnode->_prev;
return *this;
}
Self operator--(int)
{
Self tmp(*this);
_pnode = _pnode->_prev;
return tmp;
}
bool operator!=(const Self& it) const
{
return _pnode != it._pnode;
}
bool operator==(const Self& it) const
{
return _pnode == it._pnode;
}
};
template<class T, class Ref, class Ptr>这里使用三个模板参数是为了区分普通迭代器与const迭代器
同一个类模板实例化出的两个类型
typedef __list_iterator<T, T&, T*> iterator;
typedef __list_iterator<T, const T&, const T*> const_iterator;
为什么const迭代器要这样子实例两个类型,不是在普通迭代器前面加上const?








![[技术经理]01 程序员最优的成长之路是什么?](https://img-blog.csdnimg.cn/281245e6005049b38ff0636a68bb19f5.jpeg#pic_center)