文章目录
- 前言
- 题目介绍
- 人数分布预测
- 首先建立字母词典,加上时间特征
- 数据预处理
- 训练和预测函数
- 保存模型函数
- 位置编码
- 模型及其参数设置
- 模型训练以及训练曲线可视化
- 预测人数分布
- 难度分类预测
- 总结
前言
2023美赛选了C题,应该很多人会选,一看就好做,一看拿奖也难,没事,注重过程就好。
题目介绍
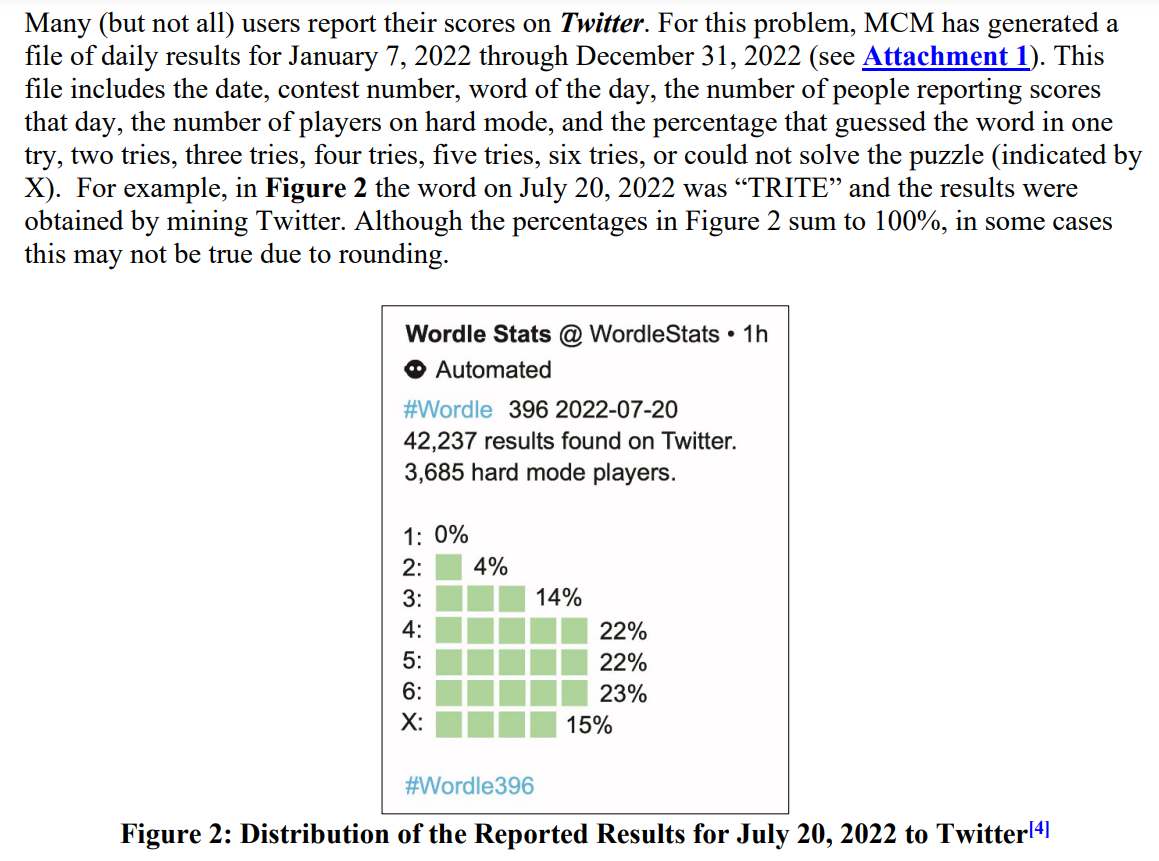
能点开这篇博客的应该都知道题目吧…(随便截点题目意思意思)


这里主要对于二三问,对于这个单词困难模式下的的人数分布百分比预测以及对这个单词的难度分类的预测。
首先看到他给的数据是这样的
第二问中有让我们预测EERIE这个单词的1-7try人数的百分比,因此思路很简单:单词特征作为输入,人数百分比作为输出,可以看作一个回归问题。
第三问中有让我们预测EERIE这个单词的难度等级,那么首先需要对所有单词进行难度划分,然后得到难度标签,最后也是单词特征作为输入,单词难度作为输出,看作一个分类问题。
人数分布预测
这个问题,思路很简单,难点就是将单词向量化来表示,如何寻找合适、有效的特征就是预测能不能做好的关键,并且还需要将时间考虑进去,因为问题里说对未来的某个时间的单词进行预测。
因为找特征,确实是令人头大,预测选择采用深度学习,将字母向量表示通过BiLSTM编码为单词的向量表示,然后进行分布的预测,这样就不用找特征了。
当然我们第一问也找了些特征,顺便一起放进去了
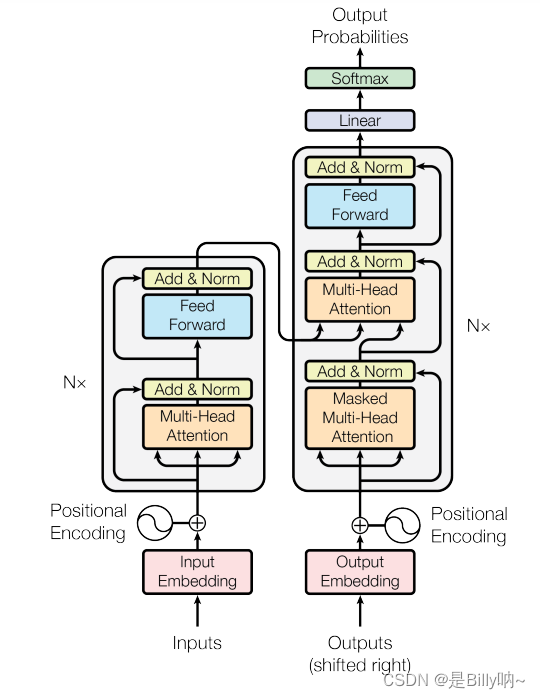
这里因为还需要考虑时间,我直接灵机一动,Transformer不就有个位置编码吗,它那里每句话中每个词加上位置编码表示词的序列位置,我这里就是每个词的特征加入位置编码,用于表示每个词的出现时间不同。
ok,因此我们的模型图如下:
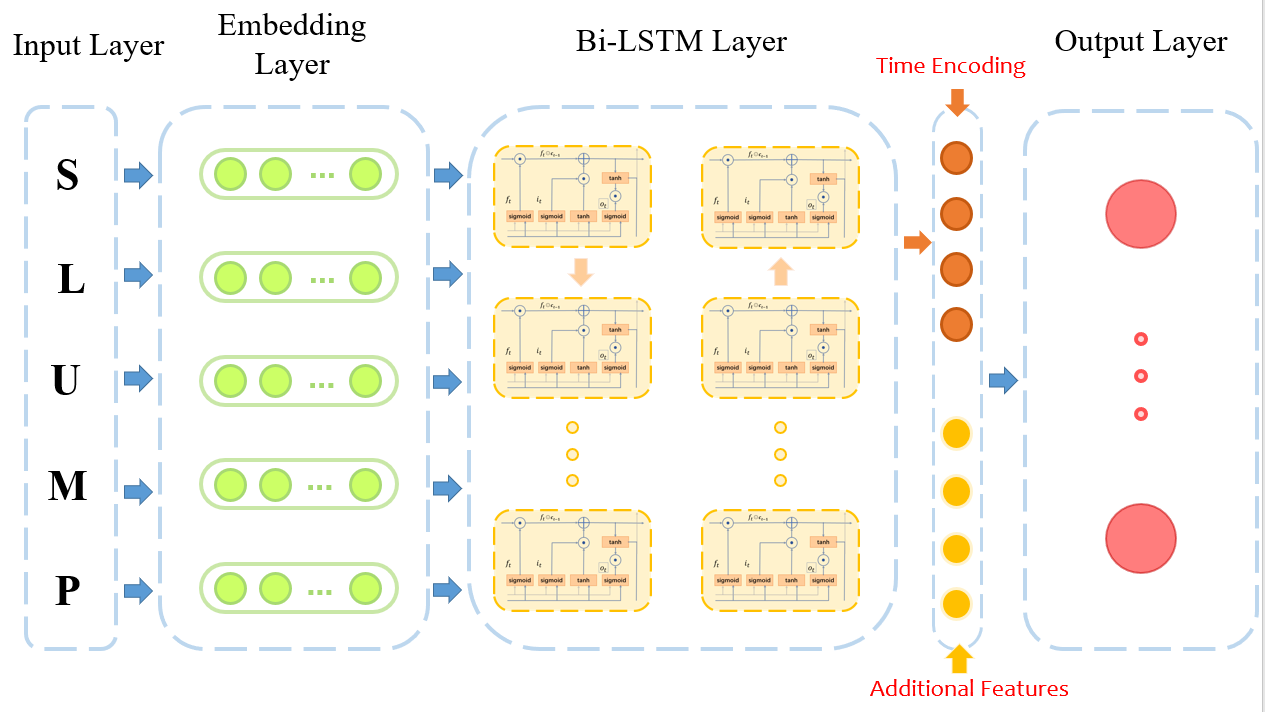
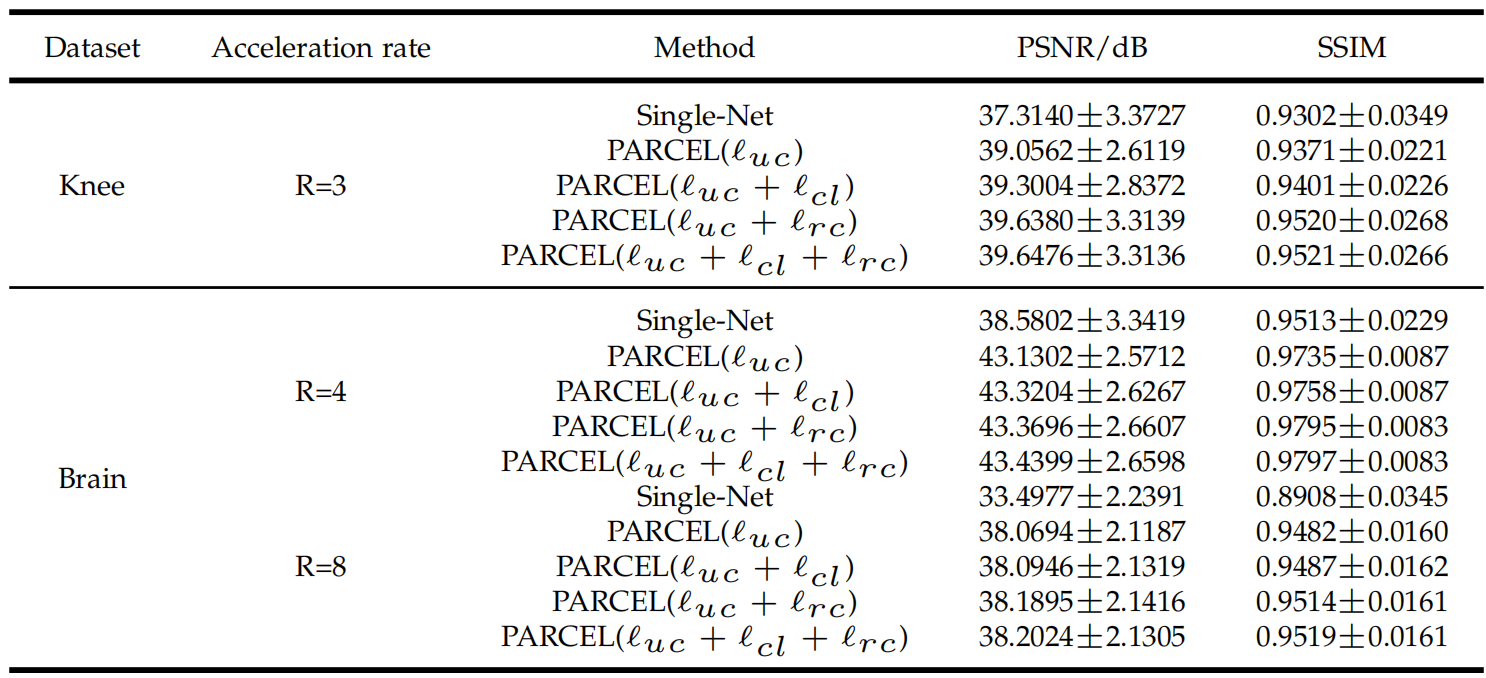
这里输出层经过softmax得到0-1之间的分布,然后进行分布的损失计算,损失函数使用MSELoss,就是均方误差最小,进行回归训练。
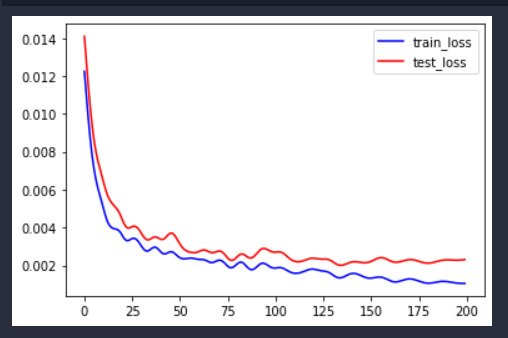
看得出训练误差能够不断减小。
先给出数据集部分展示:
wordle4.0.csv:
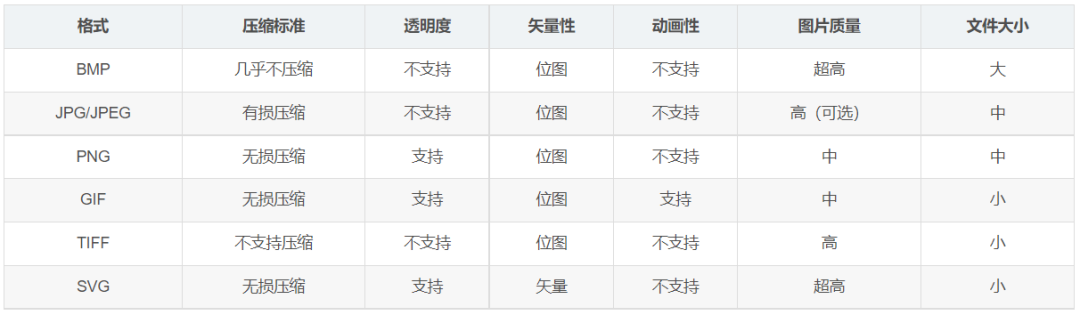
Date,Contest number,Word,Number of reported results,Number in hard mode,1 try,2 tries,3 tries,4 tries,5 tries,6 tries,7 or more tries (X),hard rate,commonality,letter_utilization,type_num,first_type,vowel_num,repeat_num
2022/1/7,202,slump,80630,1362,1,3,23,39,24,9,1,0.016891976,0.0221816151464392,0.2097406223034364,2,4,1,0
2022/1/8,203,crank,101503,1763,1,5,23,31,24,14,2,0.017368945,0.0746155017511801,0.3107710268514289,4,3,1,0
2022/1/9,204,gorge,91477,1913,1,3,13,27,30,22,4,0.02091236,0.0466981371503984,0.2672453174965737,4,3,2,1
cluster.csv:
Date,Contest number,Word,Number of reported results,Number in hard mode,1 try,2 tries,3 tries,4 tries,5 tries,6 tries,7 or more tries (X),hard rate,commonality,letter_utilization,commonality.1,letter_utilization.1,commonality.1.1,letter_utilization.1.1,w2v_tsne1,w2v_tsne2,dbscan,k++
2022/1/7,202.0,slump,80630.0,1362.0,1.0,3.0,23.0,39.0,24.0,9.0,1.0,0.016891976,0.0221816151464392,0.2097406223034364,0.0221816151464392,0.2097406223034364,0.0221816151464392,0.2097406223034364,2.337936,-1.1862806,-1,4
2022/1/8,203.0,crank,101503.0,1763.0,1.0,5.0,23.0,31.0,24.0,14.0,2.0,0.017368945,0.0746155017511801,0.3107710268514289,0.0746155017511801,0.3107710268514289,0.0746155017511801,0.3107710268514289,-9.112271,-1.1925219,-1,3
2022/1/9,204.0,gorge,91477.0,1913.0,1.0,3.0,13.0,27.0,30.0,22.0,4.0,0.02091236,0.0466981371503984,0.2672453174965737,0.0466981371503984,0.2672453174965737,0.0466981371503984,0.2672453174965737,-4.010186,9.088285,-1,2
代码实现:
首先建立字母词典,加上时间特征
import pandas as pd
import numpy as np
data = pd.read_csv("wordle_4.0.csv")
word = data["Word"].values
dic = {}
ww = []
for w in word:
ww.extend(list(w))
ww = set(ww)
i = 0
for w in ww:
dic[i] = w
dic[w] = i
i += 1
# 加上时间位置,之后在位置编码取出对应的位置编码
data["date"] = data.index.values
数据预处理
将单词向量化,且取出每个单词额外抽取的特征。
因为单词固定5个字母长度,而且也就只有26个字母,因此处理起来会简单一些。
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
import random
import math
import os
seed = 1314
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed) # CPU
torch.cuda.manual_seed(seed) # GPU
torch.cuda.manual_seed_all(seed) # All GPU
os.environ['PYTHONHASHSEED'] = str(seed) # 禁止hash随机化
torch.backends.cudnn.deterministic = True # 确保每次返回的卷积算法是确定的
torch.backends.cudnn.benchmark = False # True的话会自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题。False保证实验结果可复现
import torch.utils.data.dataloader as dataloader
from torch.utils.data import TensorDataset
import torch.nn as nn
from torch.autograd import Variable
from sklearn.model_selection import train_test_split
data_addition = pd.read_csv("cluster.csv")
data_addition = data_addition[["w2v_tsne1","w2v_tsne2"]]
data_word = data[["Word", "date", "commonality", "letter_utilization", "type_num", "vowel_num", "repeat_num"]]
data_word = pd.concat([data_word, data_addition], axis=1)
data_word = data_word.values
data_label = data[["1 try","2 tries","3 tries","4 tries","5 tries","6 tries","7 or more tries (X)"]] * 0.01
X_train, X_test, y_train, y_test = train_test_split(data_word, data_label, test_size=0.2, random_state=42)
# device = 'cpu'
def char2vec(data):
data_vec = np.zeros((data.shape[0], 5))
i = 0
for word in data:
data_vec[i] = np.array([dic[w] for w in list(word)])
i += 1
return data_vec
x_train_vec = char2vec(X_train[:, 0])
x_test_vec = char2vec(X_test[:, 0])
y_label_train = y_train.values
y_label_test = y_test.values
def get_dataloader(data, X, label):
print(X[0])
train_data = torch.from_numpy(data).to(torch.float32).to(device)
train_label = torch.from_numpy(label).to(torch.float32).to(device)
X = torch.from_numpy(X.astype(np.float32)).to(torch.float32).to(device)
train_data = torch.cat((train_data, X), dim=-1)
dataset = TensorDataset(train_data, train_label)
train_loader = dataloader.DataLoader(dataset=dataset, shuffle=False, batch_size=16) #
return train_loader
train_loader = get_dataloader(x_train_vec, X_train[:, 1:], y_label_train)
test_loader = get_dataloader(x_test_vec, X_test[:, 1:], y_label_test)
训练和预测函数
def run_epoch(model, train_iterator, optimzer, loss_fn): # 训练模型
'''
:param model:模型
:param train_iterator:训练数据的迭代器
:param optimzer: 优化器
:param loss_fn: 损失函数
'''
losses = []
model.train()
for i, batch in enumerate(train_iterator):
if torch.cuda.is_available():
input = batch[0].cuda()
label = batch[1]
else:
input = batch[0]
label = batch[1]
pred = model(input) # 预测
loss = loss_fn(pred, label) # 计算损失值
loss.backward() # 误差反向传播
losses.append(loss.cpu().data.numpy()) # 记录误差
optimzer.step() # 优化一次
return np.mean(losses)
def evaluate_model(model, dev_iterator, loss_fn): # 评价模型
'''
:param model:模型
:param dev_iterator:待评价的数据
:return:评价(准确率)
'''
losses = []
model.eval()
for i, batch in enumerate(dev_iterator):
if torch.cuda.is_available():
input = batch[0].cuda()
label = batch[1]
else:
input = batch[0]
label = batch[1]
y_pred = model(input) # 预测
loss = loss_fn(y_pred, label).cpu().data.numpy() # 计算损失值
losses.append(loss)
return np.mean(losses)
保存模型函数
每次选择训练测试集损失最小的模型保存
def save_model(model):
model_name = "lstm.net" # 模型名称
with open(model_name, 'wb') as f:
torch.save(model.state_dict(), f) # 将模型参数写入文件,model即为已经实例化训练好的model
位置编码
用于单词时间的位置表示,可以参考transformer的一些理解以及逐层架构剖析与pytorch代码实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
# d_model:词嵌入维度
# dropout:置零比率
# max_len:每个句子最大的长度
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(0)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(1000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
return Variable(self.pe[:, x], requires_grad=False).squeeze()
模型及其参数设置
class my_config():
embedding_size = 16 # 词向量大小
hidden_size = 20 # 隐藏层大小
num_layers = 2 # 网络层数
dropout = 0.1 # 遗忘程度
output_size = 7 # 输出大小
lr = 0.0001 # 学习率
epoch = 200 # 训练次数
use_add = True # 使用额外特征
use_date = True # 使用位置编码
config = my_config()
class myLSTM(nn.Module):
def __init__(self, config):
super(myLSTM, self).__init__() # 初始化
self.vocab_size = 26
self.config = config
self.embeddings = nn.Embedding(self.vocab_size, self.config.embedding_size) # 配置嵌入层,计算出词向量
self.lstm = nn.LSTM(
input_size=self.config.embedding_size, # 输入大小为转化后的词向量
hidden_size=self.config.hidden_size, # 隐藏层大小
num_layers=self.config.num_layers, # 堆叠层数,有几层隐藏层就有几层
dropout=self.config.dropout, # 遗忘门参数
bidirectional=True # 双向LSTM
)
self.dropout = nn.Dropout(self.config.dropout)
self.fc_word = nn.Linear(
self.config.num_layers * self.config.hidden_size * 2, # 因为双向所有要*2
self.config.hidden_size
)
self.fc_add = nn.Linear(X_train.shape[1]-2, self.config.hidden_size)
self.fc = nn.Linear(self.config.hidden_size * 2, self.config.output_size)
self.noisy_flag = 0
self.pos = PositionalEncoding(self.config.hidden_size)
if self.config.use_add != True:
self.fc_word = nn.Linear(
self.config.num_layers * self.config.hidden_size * 2, # 因为双向所有要*2
self.config.output_size
)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
seq = x[:, :5].type(torch.cuda.LongTensor)
time = x[:, 5].type(torch.cuda.LongTensor)
pos_embed = self.pos(time)
addfeature = x[:, 6:].type(torch.cuda.FloatTensor)
# if self.noisy_flag == 0:
# data_mean = [0.075763,0.283814,2.222841,1.788301,0.295265]
# for i in range(len(data_mean)):
# p = (torch.randint(low=4, high=10, size=(16,1)) / 100 * data_mean[i]).to(device)
# addfeature[:, i] += p[:, 0]
# self.noisy_flag = 1
embedded = self.embeddings(seq)
embedded = embedded.permute(1, 0, 2)
lstm_out, (h_n, c_n) = self.lstm(embedded)
feature = self.dropout(h_n)
# 这里将所有隐藏层进行拼接来得出输出结果,没有使用模型的输出
feature_map = torch.cat([feature[i, :, :] for i in range(feature.shape[0])], dim=-1)
if self.config.use_add != True:
out = self.fc_word(feature_map)
else:
out1 = self.fc_word(feature_map)
if self.config.use_date:
out1 = out1 + pos_embed
out2 = self.fc_add(addfeature)
out1 = torch.relu(out1)
out2 = torch.relu(out2)
out = torch.cat((out1, out2), dim=-1)
out = self.fc(out)
return self.softmax(out)
模型训练以及训练曲线可视化
model = myLSTM(config).to(device)
optimzer = torch.optim.Adam(model.parameters(), lr=config.lr, weight_decay=2e-5) # 优化器
loss_fn = nn.MSELoss()
# loss_fn = nn.KLDivLoss(reduction='batchmean', log_target=True)
train_losses = []
test_losses = []
best_loss = 100
for i in range(config.epoch):
print(f'epoch:{i + 1}')
model.train()
run_epoch(model, train_loader, optimzer, loss_fn)
# 训练一次后评估一下模型
model.eval()
train_loss = evaluate_model(model, train_loader, loss_fn)
test_loss = evaluate_model(model, test_loader, loss_fn)
if best_loss > test_loss:
best_loss = test_loss
save_model(model)
print('#' * 20)
print('train_loss:{:.4f}'.format(train_loss))
print('test_acc:{:.4f}'.format(test_loss))
train_losses.append(train_loss)
test_losses.append(test_loss)
print("best_loss", best_loss)
import matplotlib.pyplot as plt
x = [i for i in range(len(train_losses))]
fig = plt.figure()
plt.plot(x, train_losses, label="train_loss", color="blue")
plt.plot(x, test_losses, label="test_loss", color="red")
plt.legend()
plt.show()
至此,我们可以选择最优模型来预测EERIE的人数分布:
预测人数分布
def pred():
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = myLSTM(config).to(device) # 因为我们保存的模型参数,因此原来的刚实例化的模型我们需要将参数填进去以此作为我们能够进行预测的模型
model.load_state_dict(torch.load("0.0018655956_lstm.net")) # 将保存好的文件中的参数载入model。
model.eval()
print(evaluate_model(model, test_loader, loss_fn))
# EERIE
# ,,,,,,,,,,,,,,,,,,,-0.46785906,-1.4528121,-1,4
word = torch.tensor([[23, 23, 13, 1, 23, 418, 0.06580884219075174, 0.40309628952845034, 1, 5, 3, -0.46785906,-1.4528121]])
pred_y = model(word)
torch.save(model.embeddings.weight.data, "lstm_embed.pt")
return pred_y
result = pred()[0]
得到的结果就是我们问题中的结果了。
个人感觉,这个模型应该还是有点竞争力的,模型得到词向量直接预测,和得到词向量后加上我们前面提取的特征丰富词向量,其实结果差不太多,提升就只有一奈奈,但是当加入时间信息,即得到词向量后每个词加入时间位置编码,模型的训练集损失下架了很多,大概下降了有10-15%左右,所以说,这个时间信息是很重要的,如何解释呢?可能就是后面人们掌握到这个游戏的窍门了,也可能这个题目出的词和时间有种莫名的关系等等。
难度分类预测
最开始,还没想到用深度学习的时候,在想着聚类什么什么,后来第二问做了,发现原来想法真是格局小了,我直接把第二问模型,输出维度改改,损失函数改成分类用的交叉熵损失函数,不是就结束了吗?
总结
美赛熬夜确实难受,唯一让我欣慰的是模型图画的还是蛮漂亮的(多亏了队友)