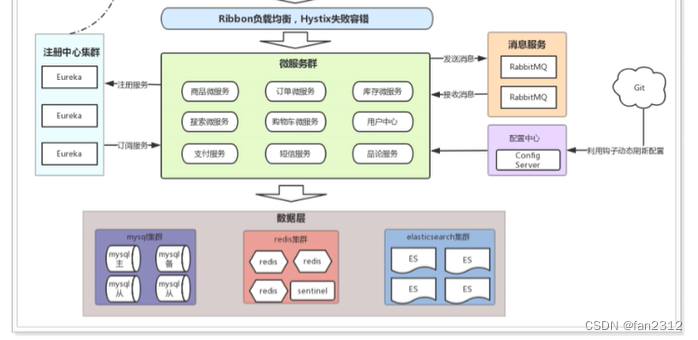
学习Flask之五、数据库
数据库有组织的存贮应用数据。根据需要应用发布查询追踪特定部分。网络应用最常用的数据库是基于关系模式的,也称为SQL数据库,引用结构化查询语句。但是近年来,面向文档和键值的数据库,非正式的统称为NoSQL数据库,成了流行的选择。
SQL 数据库
关系数据库将数据存贮在表里,在应用域内建模不同的实体。例如,订单管理应用的数据库可能用客户,产品,订单表。一个表有一个固定数量的列和可变数量的行。列定义数据的属性。例如,客户表的列可能有姓名,地址,手机号,等。每行定义一个实际的数据要素包含所有的列。表中有特殊的列称为主键,存贮表中各行的单一的标识。表中也可以有称为外键的列,它从相同或不同的表中引用主键。行与行之间的这种链接称为关系,是关系数据模型的基础。
Figure 5-1展示一个简单数据库的图,有两个表存贮用户和用户角色。连接两个表的连线表示两个表的关系。
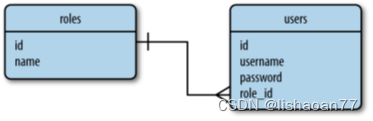
Figure 5-1. 关系数据库示例
在这个关系数据库图中,角色表存贮所有可能的用户角色,每个角色有唯一的id值--即表的主键。用户表包含用户的列表,每个用户也有唯一的id。除了id主键,角色表有姓名列和用户表有用户名和密码列。用户表中的role_id列是一个外键引用角色id,这样建每个用户的角色。从这个例子可以看到,关系数据库可以有效的存贮数据避免重复。重命名数据库中的用户角色很简单因为角色名存在于一个简单的位置。角色名后跟着改变的角色表,所有的用户有一个role_id引用改变的角色将更新。另一方面,将数据分割成多个表是复杂的。形成带有角色的用户的列表会有一个问题,因为用户和用户角色需要从两个表中读取,需要合并才能呈现。当需要时关系数据库引擎支持表之间的合并操作。
NoSQL数据库
不遵照前面描述的关系模型的数据库统称为NoSQL数据库。NoSQL数据库一个常见的组织使用集合而不是表,使用文档而不是记录。NoSQL数据库的设计使合并操作困难,所以大部分NoSQL数据库不支持合并操作。对于 Figure 5-1的NoSQL数据库结构,列出用户和它们的角色需要进行合并操作,通过读每个用户的role_id,然后从角色表中找到它。
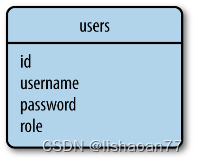
Figure 5-2. NoSQL 数据库示例
更合适的NoSQL数据库的设计见Figure 5-2。这是应用一种称为denormalization的操作的结果。它减少了表的数量但是多了数据的重复。这种结构的数据库的每一个用户都有明文的用户角色名。重命名一个角色是非常复杂的操作,需要更新大量的文档。但是NoSQL也并不是没有好处。有一定的数据重复可以使查询更快。直接列出用户和角色不需要合并操作。
选择SQL 还是NoSQL数据库?
SQL数据库擅长存贮结构化的数据,以有效的和紧凑的方式。这种数据库较长以保留一致性。非关系数据库放松了一致性的要求,结果有时会出现性能边界。 全面的分析和比较超出了本书的范围。对于小型和中型的应用,SQL和NoSQL的能力都是合适的,实际性能也相似。
Python数据库框架
Python有许多数据库引擎,有开源的也有商业的。Flask不限制使用什么数据库包,所以你可以使用MySQL, Postgres, SQLite, Redis, MongoDB,或 CouchDB,只要你喜欢。
因为这些不是足够的选择,还是一些数据库抽像层包如 SQLAlchemy或MongoEngine,它们允许你在更高一层用正常的python对象而不是数据库实体如表,文档或查询语言。 当选择数据库框架时还有一些要评估的因素:
易于使用
当直接比较数据库引擎和数据库抽像层时,每二组明显胜出。抽像层也称为 object-relational mappers(ORMs) 或object-document mappers (ODMs), 提供了高层的面向对象的操作到底层数据库指令的透明的转换。
性能
ORMs和ODMs的转换需要从对象域转换为数据库域,存在一定的开销。大部分情况下性能惩罚是可以忽略的,但并不总是这样。通常,ORMs 和ODMs的生产力超过了性能下降,所以完全抛开ORMs和ODMs不是很合理。合理的是选择数据库抽象层,能提供对数据库的可选的访问,当特定的操作需要通过原始数所库指令优化时。
移植性
需要考虑开发和生产平台的数据库。例如,如果你想将你的应用布局于云平台,你要找到这种服务有什么样的数据库选项。另一种移植方面适用于ORMs 和ODMs。虽然有些框架提供一个数据库引擎的抽像层,别的抽像更高并提供数据库引擎--用相同的面向对象的接口访问。最好的例子是SQLAlchemy ORM,支持关系数据库引擎包括流行的MySQL,Postgres,和SQLite。
Flask集成
选择与Flask集成的框架不是绝对要求的,但是这样中减少你自已写集成代码的工作。
Flask集成可以简化配置和操作,所以使用特殊设计的包作为Flask扩展是很好的选择。因为这些目的,本书选择的数据库框架是Flask-SQLAlchemy,是打包SQLAlchemy的Flask扩展。
用Flask-SQLAlchemy 管理数据库
Flask-SQLAlchemy是Flask扩展,可以简化SQLAlchemy在Flask应用内的使用。SQLAlchemy是强大的关系数据库框架,支持多种数据库后端。它提供高层的 ORM 和底层的访问数据库原生SQL的功能。像大部分其它的扩展一样,Flask-SQLAlchemy通过pip安装。
(venv) $ pip install flask-sqlalchemy
在Flask-SQLAlchemy, 数据库通过URL指明。Table 5-1 列出了三种最常见的数据库引擎的URLs格式。见http://www.aluoyun.cn/details.php? article_id=196
在这些URLs里, hostname指的是提供MySQL服务的服务器,可以是localhost或远程服务器。数据库服务器可以安装多种数据库,所以database指明所有的数据库名。对于需要授权的数据库, username和password是 用户的资格证书。SQLite数据库没有服务器,所以 hostname, username, 和password是忽略的。 database 是磁盘文件名。
应用数据数的URL必须以键SQLALCHEMY_DATABASE_URI在Flask配置对象里配置。另一个有用的选项是配置键SQLALCHEMY_COMMIT_ON_TEARDOWN,它可以设置为True 以使能自动化提交数据库的更改,在每次请求结束。其它配置信息见Flask-SQLAlchemy文档。
Example 5-1如何初始化为配置简单的SQLite数据库
Example 5-1. hello.py: 数据库配置
from flask.ext.sqlalchemy import SQLAlchemy
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] =\
'sqlite:///' + os.path.join(basedir, 'data.sqlite')
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
db = SQLAlchemy(app)
db对象实例化自SQLAlchemy类呈现数据库并提供访问 Flask-SQLAlchemy的所有功能。
模型定义
术语模型指应用使用的持久化实体。对于ORM上下文 ,模型是指属性与相应数据表配备的python类。实例化自Flask-SQLAlchemy的数据库提供了模型的基类以及帮助类和函数用于定义它们的结构。
Figure 5-1中的角色和用户表可以定义角色和用户模型,如Example 5-2所示。
Example 5-2. hello.py: Role and User model definition
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return '<Role %r>' % self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return '<User %r>' % self.username
__tablename__ 类变量定义数据库中表的名称。Flask SQLAlchemy 可以分配黙认的表名,如果忽略 __tablename__,但是黙认的名字并不遵循表名的使用习惯。所以最好明文指明表名。余下的类变量是模型属性,定义为db.Column类的实例。 给db.Column构造函数的第一个参数是数据库列的类型和模型属性。
Table 5-2列出了可用的列的类型,以及模型里使用的ptyhon类型。
见http://www.aluoyun.cn/details.php? article_id=197
db.Column余下的参数指明每个属性的配置选项。
Table 5-3 列出一些可用的选项。 见http://www.aluoyun.cn/details.php? article_id=198
虽然不是严格的需要,这两个模型包含了 __repr__() 方法来给它们可读的字符串呈现可以用于调试和测试目的。
关系
关系数据库通过关系建立不同表的行之间的关系。Figure 5-1中的关系图表达一种简单的用户与角色之间的关系。这是从角色到用户一对多的关系,因为一个角色可以对应多个用户,而一个用户只有一种角色。
Example 5-3 展示Figure 5-1的一对多的关系是如何在模型类里呈现的。
Example 5-3. hello.py: Relationships
class Role(db.Model):
# ...
users = db.relationship('User', backref='role')
class User(db.Model):
# ...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
如Figure 5-1所示,关系连接两行通过用户的外键。添加到用户模型的role_id列被定义为外键,这样建立关系。db.ForeignKey()的 'roles.id'参数指明列应被解释为从角色表中有id值的行。在角色模型中添加的用户属性呈现了面向对象的关系视图。给定角色类的实例,用户属性将返回与角色相关的用户的列表。db.relationship()的第一个参数指示关系的另一边是什么模型。这个模型可以用字符串提供,如果不没有定义类。db.relationship() 的 backref参数定义关系的相反的方向,通过增加角色属性到用户模型。这个属性可以用来代替role_id来访问用户模型的角色属性。这个属性可以用来代替role_id以访问角色模型作为对象代替外键。
大部分情况下 db.relationship()可以定位关系的外键,但是有时它不能确定哪一列用作外键。
例如,如果用户模型有两个或多个列定义为外键,则SQLAlchemy不知道用哪一个。当外键配置不清楚时,需要在db.relationship() 里增加参数。
Table 5-4列出了可以用来定义关系的一些常见的配置选项。
见http://www.aluoyun.cn/details.php? article_id=199
除了一对多的关系,还有另一些关系。一对一的关系可以表达前面的一对多的关系,但是由于db.relationship()的uselist选项设为False,所以“many”侧变为“one”侧。多对一的关系也可以表达为一对多的关系,如果保留表,或者它可以用外键表达,db.relationship()定义两侧为“many”。最复杂的关系是多对多,需要一个额外的表称为相关表。
你将在后面学习多对多的产系。
数据库操作
现在数据模型按Figure 5-1全面配置,已经可以使用了。学习如何使用这些模型的最好方法是用Python shell。下一节将带你尝试最常见的数据库操作。
创建表
要使用Flask-SQLAlchemy首先要基于模型类创建数据库。db.create_all()可以完成这项工作。
(venv) $ python hello.py shell
>>> from hello import db
>>> db.create_all()
如果你检查应用的目录,你会看到一个新的文件名为data.sqlite,配置项里给出的SQLite数据库名称。db.create_all()函数不会重新创建或更新数据表,如果数据库里已经存在。 这不是很方便,当模型被修改,需要对现有的数据库进行更改时。粗鲁的方法是先删除旧的表。
>>> db.drop_all()
>>> db.create_all()
不幸的是,这种方法会破坏旧数据库中的数据。更好的方案是按本章后面的方法更新数据库。
插入行
下面的例子创建一些用户和角色:
>>> from hello import Role, User
>>> admin_role = Role(name='Admin')
>>> mod_role = Role(name='Moderator')
>>> user_role = Role(name='User')
>>> user_john = User(username='john', role=admin_role)
>>> user_susan = User(username='susan', role=user_role)
>>> user_david = User(username='david', role=user_role)
模型的构建函数接受初始值作为模型属性的关键参数。注意,即便是使用模型属性,虽然它不是真实的数所库列,而是一对多关系的高水平呈现。这些新的对象的id属性不明文设置:
主键由Flask-SQLAlchemy管理。对象目前只在Python侧,它们还没有写入数据库。 因此它们的id值还没有分配:
>>> print(admin_role.id)
None
>>> print(mod_role.id)
None
>>> print(user_role.id)
None
通过数据库会话来管理数据库的变更,Flask SQLAlchemy提供为db.session。要准备写入数据库的对象,必须添加到会话:
>>> db.session.add(admin_role)
>>> db.session.add(mod_role)
>>> db.session.add(user_role)
>>> db.session.add(user_john)
>>> db.session.add(user_susan)
>>> db.session.add(user_david)
或更紧凑的:
>>> db.session.add_all([admin_role, mod_role, user_role,
... user_john, user_susan, user_david])
要将对象写入数据库,需要调用commit()方法来提交:
>>> db.session.commit()
现在再检查id属性;它们已经设置了:
>>> print(admin_role.id)
1
>>> print(mod_role.id)
2
>>> print(user_role.id)
3
db.session会话与Flask session对象无关。数据库会话也称为事务。数据库会话在保持数据库的一致性方面极为有用。 commit操作自动的将所有的对象写入数据库。如果在写会话的过程中出现意外,所有的会话都会抛去。 如果你总是在一个会话里提交相对的改变,你可以确何避免由于局部更新造成的数据库不一致。数据库会话也可以回退。如果调用db.session.rollback(),任何添加到数据库会话的对象将返回它们在数据库中的原有状态。
更改行
数据库会话中的add()方法可以用来更新模型。继续相同的 shell会话,下面的例子重命名 "Admin"角色为"Administrator"。
>>> admin_role.name = 'Administrator'
>>> db.session.add(admin_role)
>>> db.session.commit()
删除行
数据库会话也有delete()方法。下面的例子从数据库中删除"Moderator"角色。
>>> db.session.delete(mod_role)
>>> db.session.commit()
注意,删除,插入,更新只在数据会话提交后执行。
查询行
Flask-SQLAlchemy 使每一个模型类的查询对象可用。最基础的查询对象是返回表的所有实体:
>>> Role.query.all()
[<Role u'Administrator'>, <Role u'User'>]
>>> User.query.all()
[<User u'john'>, <User u'susan'>, <User u'david'>]
一个查询可以配置以进行更具体的数据库查找,通过使用过滤器。下面的例子找到分配角色为"User"的所有用户。
>>> User.query.filter_by(role=user_role).all()
[<User u'susan'>, <User u'david'>]
也可以检查原始的SQL查询,通过将 SQLAlchemy 产生的查询转换为查询字符串:
>>> str(User.query.filter_by(role=user_role))
'SELECT users.id AS users_id, users.username AS users_username,
users.role_id AS users_role_id FROM users WHERE :param_1 = users.role_id'
如果你退出shell会话,上面创建的对象将不会以python对象存在,而是继续以行存在于相应的数据表。如果你启动新的shell会话,你需要重新从数据库行创建python对象。下面的例子进行一次查询,加载具有角色为"User"的所有用户:
>>> user_role = Role.query.filter_by(name='User').first()
像filter_by()一样的过滤器调用于查询对象返回新的精细查询。可以在一个序列中调用多个过滤器直到查询已配置,如果需要。
Table 5-5 展示一些常见的过滤器。见http://www.aluoyun.cn/details.php? article_id=200
完整的列表见SQLAlchemy文档。
查询中使用了需要的过滤器之后,调用all()会使查询执行并返回列表形式的结果,但是也有别的方法触发查询执行。Table 5-6展示了其它查询执行方法。 见http://www.aluoyun.cn/details.php? article_id=201
关系的作用类似于查询。下面的例子从两端查询roles和users之间的一对多的关系:
>>> users = user_role.users
>>> users
[<User u'susan'>, <User u'david'>]
>>> users[0].role
<Role u'User'>
这里的user_role.users查询有个小问题。不明文的查询运行当user_role.users表达式发布意图调用all()返回用户的列表。因为这个查询对象是隐藏的,不能用额外的查询过滤器提炼它。在这个特例里,请求用户列表按字母顺序返回是有用的。在Example 5-4里,关系的配置用 lazy = 'dynamic'参数配置以请求查询不会自动执行。
Example 5-4. app/models.py: Dynamic relationships
class Role(db.Model):
# ...
users = db.relationship('User', backref='role', lazy='dynamic')
# ...
With the relationship configured in this way, user_role.users returns a query that
hasn’t executed yet, so filters can be added to it:
>>> user_role.users.order_by(User.username).all()
[<User u'david'>, <User u'susan'>]
>>> user_role.users.count()
2
在View函数中使用数据库
上一节描述的数据库操作可以直接在view函数中使用。
Example 5-5显示新版本的主页路由它记录用户输入的名字放在数据库里。
Example 5-5. hello.py: 在view函数里使用数据库
@app.route('/', methods=['GET', 'POST'])
def index():
form = NameForm()
if form.validate_on_submit():
user = User.query.filter_by(username=form.name.data).first()
if user is None:
user = User(username = form.name.data)
db.session.add(user)
session['known'] = False
else:
session['known'] = True
session['name'] = form.name.data
form.name.data = ''
return redirect(url_for('index'))
return render_template('index.html',
form = form, name = session.get('name'),
known = session.get('known', False))
这个改版的应用中,每次提交name应用都在数据库中检查它,使用filter_by() 查询过滤器。 known变量写入用户 session以便重定向后信息可以发送到模板,从而用它来定制欢迎。注意,为了应用工作,数据库表必须在python shell中创建,如前所述。新版的相关模板在Example 5-6里展示。这个模板使用known参数为欢迎增加第二行使known 和new users不同。
Example 5-6. templates/index.html
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
{% block title %}Flasky{% endblock %}
{% block page_content %}
<div class="page-header">
<h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}!</h1>
{% if not known %}
<p>Pleased to meet you!</p>
{% else %}
<p>Happy to see you again!</p>
{% endif %}
</div>
{{ wtf.quick_form(form) }}
{% endblock %}
If yo
集成Python Shell
每次在会话开始时导入数据库实例和模型是很烦人的工作。为了避免重复导入,Flask-Script的shell命令可以配置以自动导入一定的对象。为了增加对象到导入列表shell命令需要用make_context回调函数注册。这在Example 5-7里展示。
Example 5-7. hello.py: Adding a shell context
from flask.ext.script import Shell
def make_shell_context():
return dict(app=app, db=db, User=User, Role=Role)
manager.add_command("shell", Shell(make_context=make_shell_context))
make_shell_context()函数注册应用和数据库实例以及模型以便它们自动的导入到shell:
$ python hello.py shell
>>> app
<Flask 'app'>
>>> db
<SQLAlchemy engine='sqlite:home/flask/flasky/data.sqlite'>
>>> User
<class 'app.User'>
用Flask-Migrate进行数据库迁移
随着应用开发的发展,你会发现你的数据库模型需要修改,这时候数据库也要更新。
Flask-SQLAlchemy只有在数据表不存在时创建它们,所以更新表的方法只能是破坏旧的表,但这样会使数据库中的数据消失。更好的方案是使用数据库迁移框架。与源码版本控制的方法一样跟踪源码文件的变更,数据库迁移框架跟踪数据库schema的变更,然后将变更施加于数据库。SQLAlchemy的领导开发者已经写好了迁移框架称为Alembic,但不是直接使用Alembic,Flask应用可以使用 Flask-Migrate扩展,一个轻量级的Alembic 容器与Flask-Script集成以通过 Flask-Script命令提供所有的操作。
创建迁移目录
要开始工作,必须先在虚拟环境中安装Flask-Migrate。
(venv) $ pip install flask-migrate
Example 5-8 展示如何安装扩展。
Example 5-8. hello.py: Flask-Migrate configuration
from flask.ext.migrate import Migrate, MigrateCommand
# ...
migrate = Migrate(app, db)
manager.add_command('db', MigrateCommand)
要执行数据库迁移命令, Flask-Migrate暴露MigrateCommand类与Flask-Script的 manager对象邦定。本例的命令用db邦定的。在数据迁移维护前,有必要创建一个迁移目录,使用init子命令:
(venv) $ python hello.py db init
Creating directory /home/flask/flasky/migrations...done
Creating directory /home/flask/flasky/migrations/versions...done
Generating /home/flask/flasky/migrations/alembic.ini...done
Generating /home/flask/flasky/migrations/env.py...done
Generating /home/flask/flasky/migrations/env.pyc...done
Generating /home/flask/flasky/migrations/README...done
Generating /home/flask/flasky/migrations/script.py.mako...done
Please edit configuration/connection/logging settings in
'/home/flask/flasky/migrations/alembic.ini' before proceeding.
这个命令创建一个迁移目录,所有的迁移脚本都放在这个目录里。数据库迁移目录里的文件必须总是添加到版本控制里与应用的其它部分一起。
创建迁移脚本
在Alembic里,数据库迁移由迁移脚本呈现。这个脚本有两个函数称为upgrade()和 downgrade()。upgrade()函数应用数据库变更,是迁移的一部分。而downgrade()函数删除它们。由于有能力增加和删除变更,Alembic可以重新配置数据库到变更历史中的任一点。
Alembic migrations或以手工创建或使用revision和migrate命令自动创建。手工迁移创建一个迁移的骨架脚本用空的upgrade() 和downgrade() 函数,需要操作人员使用Alembic的操作对象的指令实施。而自动迁移,为 upgrade() 和downgrade()产生代码通过查找模型定义的不同以及数据库的当前状态。
自动迁移并不总是正确的,可能会失去一些细节。自动产生的迁移脚本需要审核。迁移子命令产生一个自动迁移脚本。
(venv) $ python hello.py db migrate -m "initial migration"
INFO [alembic.migration] Context impl SQLiteImpl.
INFO [alembic.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate] Detected added table 'roles'
INFO [alembic.autogenerate] Detected added table 'users'
INFO [alembic.autogenerate.compare] Detected added index
'ix_users_username' on '['username']'
Generating /home/flask/flasky/migrations/versions/1bc
594146bb5_initial_migration.py...done
更新数据库
一旦迁移脚本被审核和接受,就可以通过db upgrade命令应用于数据库。
(venv) $ python hello.py db upgrade
INFO [alembic.migration] Context impl SQLiteImpl.
INFO [alembic.migration] Will assume non-transactional DDL.
INFO [alembic.migration] Running upgrade None -> 1bc594146bb5, initial migration
对于首次迁移,这等价于db.create_all()。但是后面的迁移,upgrade命令应用表的更新而不影响表的内容。
如果你克隆了Git目录,删除data.sqlite数据库文件,然后运行Flask-Migrate的更新子命令以重新产生数据库,通过迁移框架。数据库设计和使用的主题很重要,关于这个主题需要用一本书来写。
你应把本章作为概述;更深入的主题将在后面讨论。下一章专门讲电子邮件的发送。