Document-Level event Extraction via human-like reading process

论文:2202.03092v1.pdf (arxiv.org)
代码:无
期刊/会议:ICASSP 2022
摘要
文档级事件抽取(DEE)特别困难,因为它提出了两个挑战:论元分散和多事件。第一个挑战意味着一个事件记录的论元可能存在于文档中的不同句子中,而第二个挑战反映了一个文档可能同时包含多个这样的事件记录。本文以人类的阅读认知为动机,提出了一种HRE (Human reading inspired Extractor for Document Events)方法,将DEE分解为粗略阅读和精细阅读两个迭代阶段。具体来说,第一个阶段浏览文档以检测事件的发生,第二个阶段用于抽取特定的事件论元。对于每个具体的事件角色,详细阅读从句子到字符分层工作,在句子中定位论元,从而解决了论元分散的问题。同时,对粗读进行多轮探索,发现未检测到的事件,从而解决多事件问题。实验结果表明,该方法优于现有的竞争方法。
关键词:自然语言处理,信息抽取,事件抽取,文档级事件抽取
1、简介
事件抽取(EE)旨在识别特定类型的事件,并从给定的文本中抽取相应的事件论元。尽管成功地[1,2,3,4,5,6,7]在句子中抽取事件,也就是句子级EE (SEE),但这些方法似乎在现实场景中妥协,因为事件通常是在句子中表达的。因此,SEE正在向文档级EE发展,即文档级EE (DEE)。
通常,DEE面临两个挑战,论元分散和多事件。如图1所示,第一个挑战表明,一个事件记录的事件论元可能存在于不同的句子中,因此无法从单个句子中抽取事件。第二种反映了文档可能同时包含多个这样的事件记录,这就要求对文档有一个整体的理解,并理解事件之间的相互依赖关系。迄今为止,大多数DEE方法[8,9,10,11]主要关注第一个挑战,而忽略了第二个挑战。虽然zheng等人[12] (2019)首次提出Doc2EDAG来同时解决这两个挑战,提出的面向实体的方法不能充分模拟多事件之间的依赖关系,导致最终性能不理想。

近年来,模拟人类的阅读认知过程来解决特定的自然语言处理(NLP)任务[13,14]已经实现了更好的效果。人类的阅读过程通常分为三个阶段[15,16,17]:pre-reading、careful reading和post-reading。在pre-reading过程中,人类读者对整个文档进行预览,形成对文档内容的一般认知。在careful reading中,人类读者会根据自己的阅读目的仔细阅读每句话,找到详细的信息。在post-reading中,对文档进行回顾,检查遗漏的细节并完成对文档的理解。从粗到细的多阶段阅读过程理解文档,这使得在整个文档中抽取事件事实变得有效。然而,到目前为止,很少有文献探讨DEE的阅读过程。
为了模拟上述思想,本文提出了一种名为HRE (Human Reading inspired Extractor for Document Events)的DEE方法,将人类的阅读过程重新格式化为粗读(rough reading) 和 精读(elaborate reading) 两个阶段。对于每个特定的事件类型,首先进行粗读以检测事件的发生。如果检测到事件,则应用精读以论元方式抽取完整的事件记录。具体来说,对于每个事件角色,精读首先定位对应的论元在哪个句子中,然后抽取出来。每个抽取的事件论元都由内存机制存储,该机制模拟了多事件之间的相互依赖关系,并使HRE能够意识到先前抽取的事件。在获得一个完整的事件记录后,HRE再次粗读文档,以检查相同事件类型的缺失事件,并且内存机制使它能够检测到与之前抽取的事件没有冗余的事件。如果感知到另一个事件发生,将再次应用精读,否则,HRE将通过上述相同的逻辑处理下一个事件类型,直到处理所有事件类型。通过对多个事件之间相互依赖关系的记忆机制建模,对粗读的多轮探索释放了多事件挑战。同时,对于每个事件角色,精读分别搜索与论元相关的句子,这样句子间的论元都能被定位,自然地解决了论元分散的问题。在最大DEE数据集[12]上的实验结果表明,HRE实现了一种新的最先进的性能。
2、方法
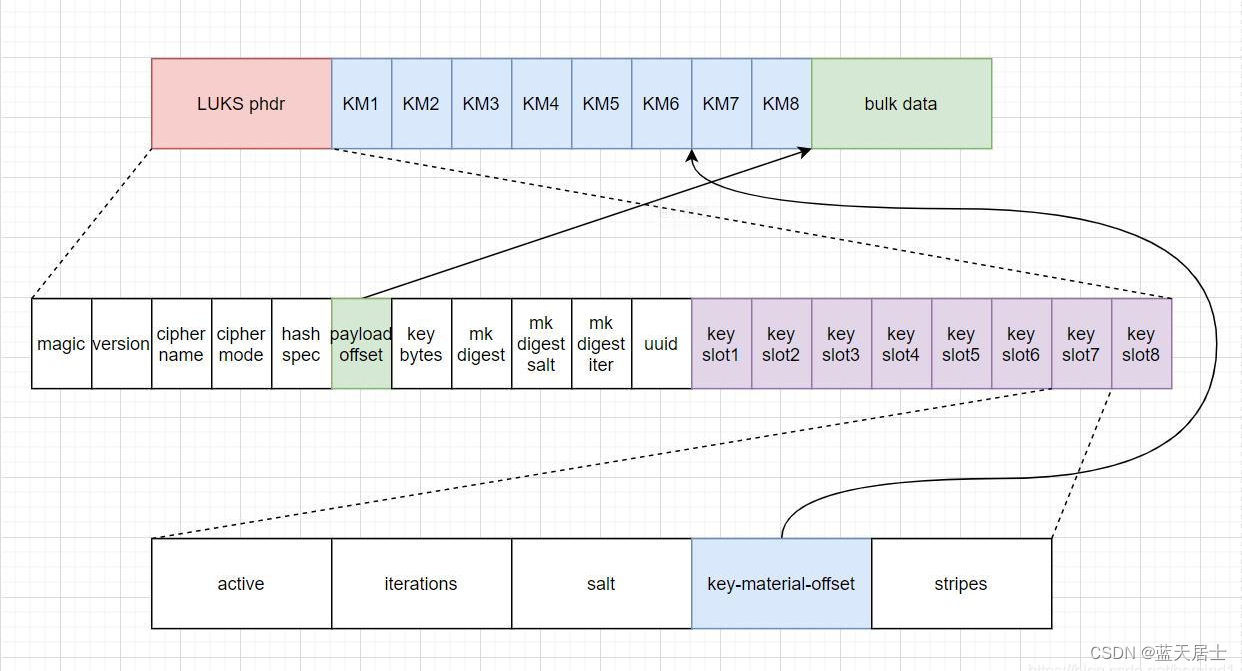
DEE的最终目标是抽取所有事件记录,并正确判断事件类型和论元。算法1展示了HRE的整体工作流程。请注意,内存机制被设计为在两个读取阶段工作,其中,对于每个事件类型,我们使用一个可训练的事件类型特定的嵌入
e
e
e_e
ee来初始化内存张量
m
e
m_e
me,并且通过附加以下抽取的事件论元来更新
m
e
m_e
me。内存张量对事件之间的相互依赖进行建模,使粗读能够区分丢失的事件和抽取的事件,并支持使用论元级上下文进行精读。

2.1 基础编码
给定一个包含 N N N个句子的文档 D D D,基本编码包括三个步骤来生成字符、句子和文档的上下文表示。首先,对每个句子 S j S_j Sj分别采用一个句子编码器,推导出每个句子中的字符表示为 S j = [ c j , 1 , c j , 2 , … , c j , n ] S_j = [c_{j,1}, c_{j,2},\ldots, c_{j,n}] Sj=[cj,1,cj,2,…,cj,n],其中 c j , k ∈ R d c_{j,k} \in \mathbb{R}^d cj,k∈Rd, n n n为 S j S_j Sj中的字符数, d d d为字符表示的维数。接下来,max-pooling应用于每个句子 S j S_j Sj,以获得原始句子表示 s j r s^r_j sjr,然后,使用文档编码器用于 [ s 1 r , s 2 r , … , s N r ] [s^r_1, s^r_2,\ldots, s^r_N] [s1r,s2r,…,sNr],得到文档感知的句子表示 s = [ s 1 , s 2 , … , s N ] , s j ∈ R d , s ∈ R N × d s = [s_1, s_2,\ldots, s_N], s_j \in \mathbb{R}^d, s\in \mathbb{R}^{N×d} s=[s1,s2,…,sN],sj∈Rd,s∈RN×d。最后,对 s s s应用max-pooling,生成文档表示 D ∈ R d D \in \mathbb{R}^d D∈Rd。
2.2 粗读
粗读可以检测事件的发生。正如算法1所示,粗读也用于检查缺失的事件,它需要内存来避免与之前抽取的事件进行冗余检测。具体来说,我们利用内存张量
m
e
m_e
me上的内存编码器来实现事件之间的信息流,并细化先前的
e
e
e类型事件,如下所示:
m
^
e
=
SumPooling
(
MemEnc
(
m
e
)
)
\hat m_e = \text{SumPooling}(\text{MemEnc}(m_e))
m^e=SumPooling(MemEnc(me))
其中
m
^
e
∈
R
d
\hat m^e∈\mathbb{R}^d
m^e∈Rd为汇总内存。当第一次对
e
e
e类型事件应用粗读时,
m
e
∈
R
(
1
)
×
d
m_e∈\mathbb{R}^{(1)×d}
me∈R(1)×d仅包含随机初始化的事件类型嵌入
e
e
e_e
ee;当应用粗读来检查缺失的事件时,
m
e
∈
R
(
1
+
l
m
)
×
d
m_e∈\mathbb{R}^{(1+l_m)×d}
me∈R(1+lm)×d包含
e
e
e_e
ee和
l
m
l_m
lm抽取的事件论元表示。
我们从文档中删除有关先前事件的信息,并计算文档中未抽取的
e
e
e类型事件发生的概率
p
e
p_e
pe,如下所示:
D
^
=
D
−
m
^
e
,
p
e
=
sigmoid
(
W
s
(
t
a
n
h
(
W
d
D
^
+
W
t
e
e
)
)
)
\hat D=D-\hat m_e,\\ p_e=\text{sigmoid}(W_s(tanh(W_d \hat D +W_t e_e)))
D^=D−m^e,pe=sigmoid(Ws(tanh(WdD^+Wtee)))
其中
D
∈
R
d
D∈\mathbb{R}^d
D∈Rd和
D
^
∈
R
d
\hat D∈\mathbb{R}^d
D^∈Rd分别是原始的和可感知冗余的文档表示,
W
s
,
W
d
,
W
t
W_s, W_d, W_t
Ws,Wd,Wt是可训练参数。如果
p
e
p_e
pe大于预定义的阈值,HRE会感知到一个未抽取的
e
e
e类型事件,然后利用精读来抽取论元,否则,HRE将处理下一个事件类型。
在训练过程中,我们使用二进制交叉熵损失对 p e p_e pe进行粗读,以检测事件的发生。由于在一个文档中使用了多次粗读,因此我们将每次粗读的所有损失相加为 L r r L_{rr} Lrr。
2.3 精读
在HRE检测到一个
e
e
e类型事件的发生后,详细的读取工作将按照预定义的事件角色顺序[12]逐个抽取具体的事件论元。对于每个事件角色,将构造一个查询来明确读取目标,该查询细化了当前事件角色和先前抽取的论元之间的相互依赖关系。具体来说,我们利用Memory-Encoder将先前的论元上下文表示注入到角色嵌入中,如下所示:
[
r
‾
e
i
;
m
‾
e
]
=
MemEncc
(
r
e
i
;
m
e
)
[\overline r_e^i;\overline m_e]=\text{MemEncc}(r_e^i;m_e)
[rei;me]=MemEncc(rei;me)
其中
[
⋅
;
⋅
]
[·;·]
[⋅;⋅]表示连接操作,
r
e
i
∈
R
1
×
d
r^i_e∈\mathbb{R}^{1×d}
rei∈R1×d是
e
e
e型事件的第
i
i
i个角色的可训练的角色特定嵌入,
m
e
∈
R
(
1
+
l
m
)
×
d
m_e∈ \mathbb{R}^{(1+l_m)×d}
me∈R(1+lm)×d是原始内存张量,MemEnc是等式1中使用的编码器。我们利用
r
‾
e
i
∈
R
1
×
d
\overline r^i_e∈\mathbb{R}^{1×d}
rei∈R1×d作为key来抽取当前事件角色的论元。
句子定位模块定位目标论元所在的句子。在一个句子中,共享相同事件角色的论元在某种程度上彼此语义相似,因此我们首先对先前抽取的论元信息进行过滤,如下所示:
g
=
sigmoid
(
W
l
(
[
m
^
e
;
s
j
]
)
)
,
s
^
j
=
s
j
−
s
j
∗
g
g=\text{sigmoid}(W_l([\hat m_e;s_j])),\\ \hat s_j=s_j - s_j *g
g=sigmoid(Wl([m^e;sj])),s^j=sj−sj∗g
其中
m
^
e
∈
R
d
\hat m_e∈\mathbb{R}^d
m^e∈Rd是等式1中相同的记忆概括,
s
j
∈
R
d
s_j∈\mathbb{R}^d
sj∈Rd是句子表示,“[·;·]”是产生
[
m
^
e
;
s
j
]
∈
R
2
d
[\hat m_e;s_j]∈\mathbb{R}^{2d}
[m^e;sj]∈R2d,
g
g
g为控制信息冗余的门。然后,HRE选择第
j
j
j句为:
z
s
=
Attention
(
r
‾
e
i
,
s
^
)
=
softmax
(
r
‾
e
i
s
^
T
d
)
,
j
=
argmax
(
z
s
)
z_s=\text{Attention}(\overline r_e^i,\hat s)=\text{softmax}(\frac{\overline r_e^i \hat s^T}{\sqrt{d}}),\\ j=\text{argmax}(z_s)
zs=Attention(rei,s^)=softmax(dreis^T),j=argmax(zs)
其中:
s
∈
R
N
×
d
s∈\mathbb{R}^{N×d}
s∈RN×d是文档中所有句子的冗余感知句子表示,
z
s
∈
R
N
×
1
z_s∈\mathbb{R}^{N×1}
zs∈RN×1是通过缩放的点积[18]注意力计算出的每个句子的相关性得分,并选择得分最高的句子进行相应的论元抽取。
在训练中,我们使用对 z s z_s zs的交叉熵损失来指导句子的位置,正确句索引作为标签。在一个文档中,我们将每个句子位置的所有损失相加为 L s l L_{sl} Lsl。
论元抽取模块的目的是抽取特定的事件论元并更新内存张量。对于一个事件角色,假设HRE决定从第
j
j
j句中抽取论元,将进行一些初步操作作为准备。首先,将查询嵌入
r
‾
e
i
\overline r_e^i
rei添加到每个字符表示
c
j
,
k
c_{j,k}
cj,k中,用事件相关知识丰富句子。然后在句子后面加上一个符号“[STOP]”,表示为对应的角色嵌入
r
e
i
r^i_e
rei,表示抽取的结束。这两个操作可以表述为:
S
^
j
=
[
c
j
,
1
+
r
‾
e
i
,
c
j
,
2
+
r
‾
e
i
,
…
,
c
j
,
n
+
r
‾
e
i
,
r
e
i
]
\hat S_j=[c_{j,1}+\overline r_e^i,c_{j,2}+\overline r_e^i,\ldots,c_{j,n}+\overline r_e^i,r_e^i]
S^j=[cj,1+rei,cj,2+rei,…,cj,n+rei,rei]
论元由一系列字符复制操作从json中抽取,如下所示:
v
0
=
r
‾
e
i
,
k
=
argmax
(
A
t
t
n
S
c
o
r
e
(
v
t
S
^
j
)
)
,
v
t
+
1
=
S
^
j
[
k
]
v_0=\overline r_e^i,\\ k=\text{argmax}(AttnScore(v_t \hat S_j)),\\ v_{t+1}=\hat S_j[k]
v0=rei,k=argmax(AttnScore(vtS^j)),vt+1=S^j[k]
第
j
j
j句中的第
k
k
k个字符被复制。
v
0
v_0
v0被初始化为
r
‾
e
i
\overline r_e^i
rei来定位目标论元的第一个字符,在每一个时间步
t
t
t中,得到最大分数的字符被复制并用作
v
t
+
1
v_{t+1}
vt+1。复制操作直到“[STOP]”被复制才会结束。假设复制字符
c
j
,
k
,
c
j
,
k
+
1
,
c
j
,
k
+
2
c_{j,k}, c_{j,k+1}, c_{j,k+2}
cj,k,cj,k+1,cj,k+2和“[STOP]”,对有效标记应用最大池化,导出参数表示
arg
r
e
i
∈
R
d
\text{arg}_{r_e^i}∈\mathbb{R}^d
argrei∈Rd为:
a
r
g
r
e
i
=
MaxPooling
(
[
c
j
,
k
;
c
j
,
k
+
1
;
c
j
,
k
+
2
]
)
arg_{r_e^i}=\text{MaxPooling}([c_{j,k};c_{j,k+1};c_{j,k+2}])
argrei=MaxPooling([cj,k;cj,k+1;cj,k+2])
在训练中,我们使用对
A
t
t
n
S
c
o
r
e
(
v
t
,
S
^
j
)
AttnScore(v_t, \hat S_j)
AttnScore(vt,S^j)的交叉熵损失来指导论元字符复制过程,其中,在每个时间步
t
t
t中,使用标准论元字符索引作为标签。我们将每个文档中的所有字符拷贝损失相加为
L
a
e
L_{ae}
Lae。
内存更新模块将每个抽取的论元附加到内存张量
m
e
m_e
me,使每个读取阶段都知道先前抽取的论元。由于单个实体的语义可能很少,我们将实体和相应的句子表示融合在一起,以如下方式更新内存:
m
e
=
[
m
e
;
(
arg
r
e
i
+
s
i
)
]
m_e=[m_e;(\arg_{r_e^i}+s_i)]
me=[me;(argrei+si)]
其中更新的内存张量
m
e
∈
R
(
l
m
+
2
)
×
d
m_e∈\mathbb{R}^{(l_m+2)×d}
me∈R(lm+2)×d包含
l
m
+
1
l_m+ 1
lm+1个论元,将在下一个读取阶段使用。
2.4 训练目标
我们将精读中粗读、句子定位和论点抽取的损失总和为 L a l l = λ 1 L r r + λ 2 L s l + λ 3 L a e L_{all} = λ_1L_{rr} + λ_2L_{sl} + λ_3L_{ae} Lall=λ1Lrr+λ2Lsl+λ3Lae,并共同优化。 λ 1 = 1.0 , λ 2 = 1.0 , λ 3 = 0.9 λ_1=1.0,λ_2=1.0,λ_3=0.9 λ1=1.0,λ2=1.0,λ3=0.9为平衡不同子任务的系数。
3、实验
3.1 实验设置
数据集和评估指标:中文金融文档级事件抽取数据集;Precision、Recall、F1-score。
实验细节:我们遵循Zheng等人(2019)[12]来设置超参数。我们将字符嵌入的维度设置为768,事件发生的粗读阈值设置为0.5。最大句子数和句子长度分别为64句和128句。句子编码器、文档编码器和记忆编码器采用Transformer编码器[18]。
Baseline:DCFEE、Doc2EDAG、GreedyDec、ArgSpan。
3.2 主要的实验结果


3.3 详细分析
消融实验:为了探究不同成分的贡献,我们分别对粗读和精读进行了分析。表2反映了:(1)删除等式2中的内存探索会导致最差的性能,因为HRE总是判断是否有缺失的事件,并从文档中检测先前抽取的事件。(2)在原句子表示上进行句子定位,而不是在冗余意识表示上进行句子定位,结果在F1上下降了1.9%。这证实了删除冗余信息的必要性。(3)查询是必不可少的,它细化了之前事件之间的相互依赖关系,因为消融实验对F1造成了2.4%的伤害。(4)在没有将查询添加到字符表示的情况下,结果降级显示了事件相关信息在论元抽取中的重要性。

计算成本分析。我们从两个方面讨论了HRE和Doc2EDAG之间的计算开销。(1)我们将推理速度作为时间计算成本,推理速度是指在模型推理过程中,模型每秒可以处理的文档数量。具体来说,HRE的推理速度为5.9Docs/s,而Doc2EDAG的推理速度为7.2Docs/s。(2)利用模型参数的数量来表示空间计算代价。其中HRE的参数量为70.5 m, Doc2EDAG的参数量为66.8M。虽然HRE的成本略高于Doc2EDAG,但我们认为HRE的额外成本是值得的,因为它在整体F1上比Doc2EDAG提高了2.3%,并且在DEE的两个挑战上表现出色。
3.4 实例分析

4、总结
在本文中,我们提出了针对DEE任务的HRE (Human Reading inspired Extractor for Document Events)。HRE包括两个阶段,粗读检测事件的发生,精读抽取具体的事件论元。据我们所知,我们率先探索了DEE的阅读认知过程,实验证明了其有效性。在未来,我们希望进一步将HRE应用于文档级关系抽取任务。