- 视频教程:哔哩哔哩网站:黑马大数据Hadoop入门视频教程
- 教程资源:https://pan.baidu.com/s/1WYgyI3KgbzKzFD639lA-_g 提取码: 6666
- 【P001-P017】大数据Hadoop教程-学习笔记01【大数据导论与Linux基础】
- 【P018-P037】大数据Hadoop教程-学习笔记02【Apache Hadoop、HDFS】
- 【P038-P050】大数据Hadoop教程-学习笔记03【Hadoop MapReduce与Hadoop YARN】
- 【P051-P068】大数据Hadoop教程-学习笔记04【数据仓库基础与Apache Hive入门】
- 【P069-P083】大数据Hadoop教程-学习笔记05【Apache Hive DML语句与函数使用】
- 【P084-P096】大数据Hadoop教程-学习笔记06【Hadoop生态综合案例:陌陌聊天数据分析】
目录
01【Apache Hadoop概述】
P018【01-课程内容大纲-学习目标】
P019【02-Apache Hadoop介绍、发展简史、现状】
P020【03-Apache Hadoop特性优点、国内外应用】
P021【04-Apache Hadoop发行版本、架构变迁】
02【Apache Hadoop集群搭建】
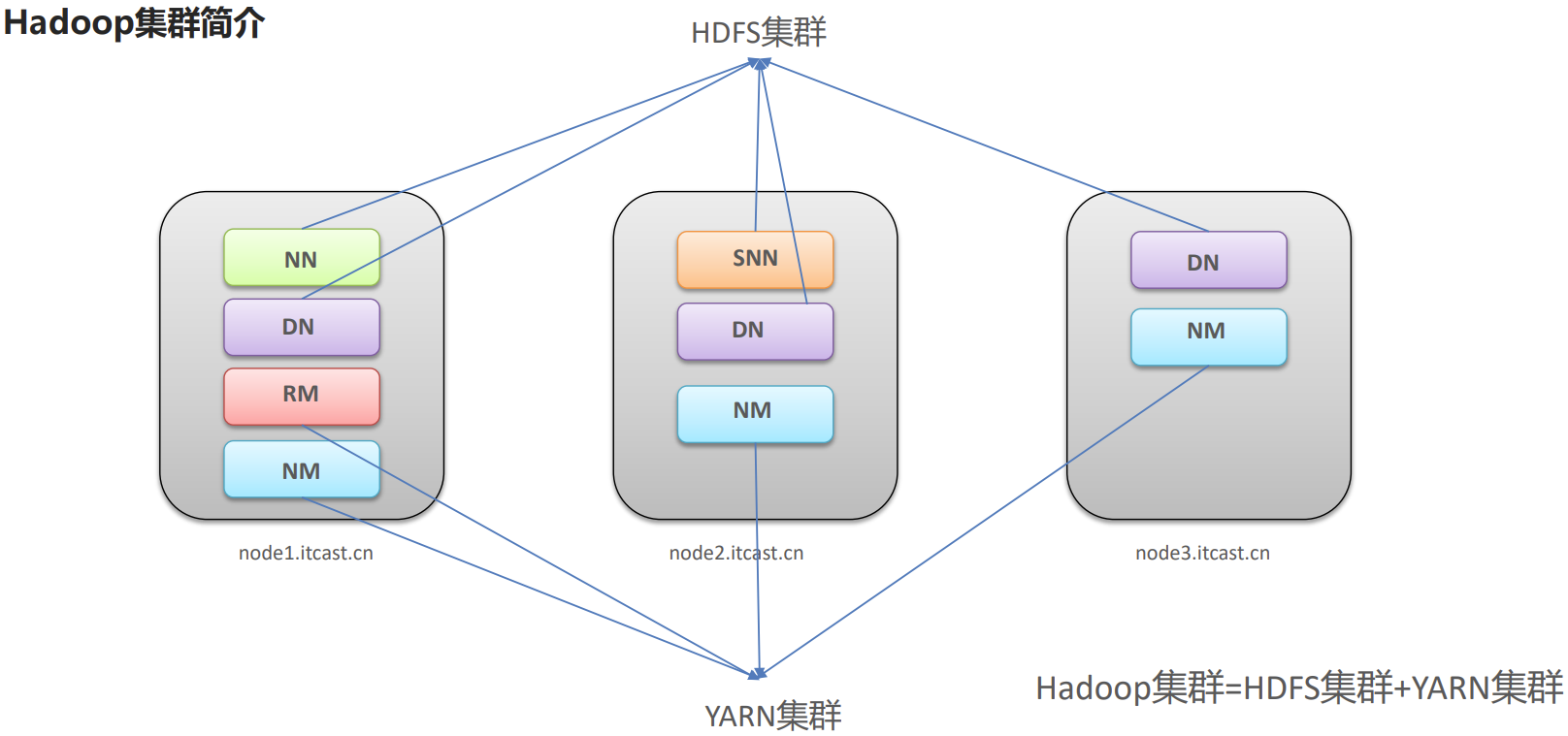
P022【05-Apache Hadoop安装部署--集群组成介绍】
P023【06-Apache Hadoop安装部署--服务器基础环境设置】jdk环境安装
P024【07-Apache Hadoop安装部署--安装包结构】
P025【08-Apache Hadoop安装部署--修改配置文件、同步安装包与环境变量】
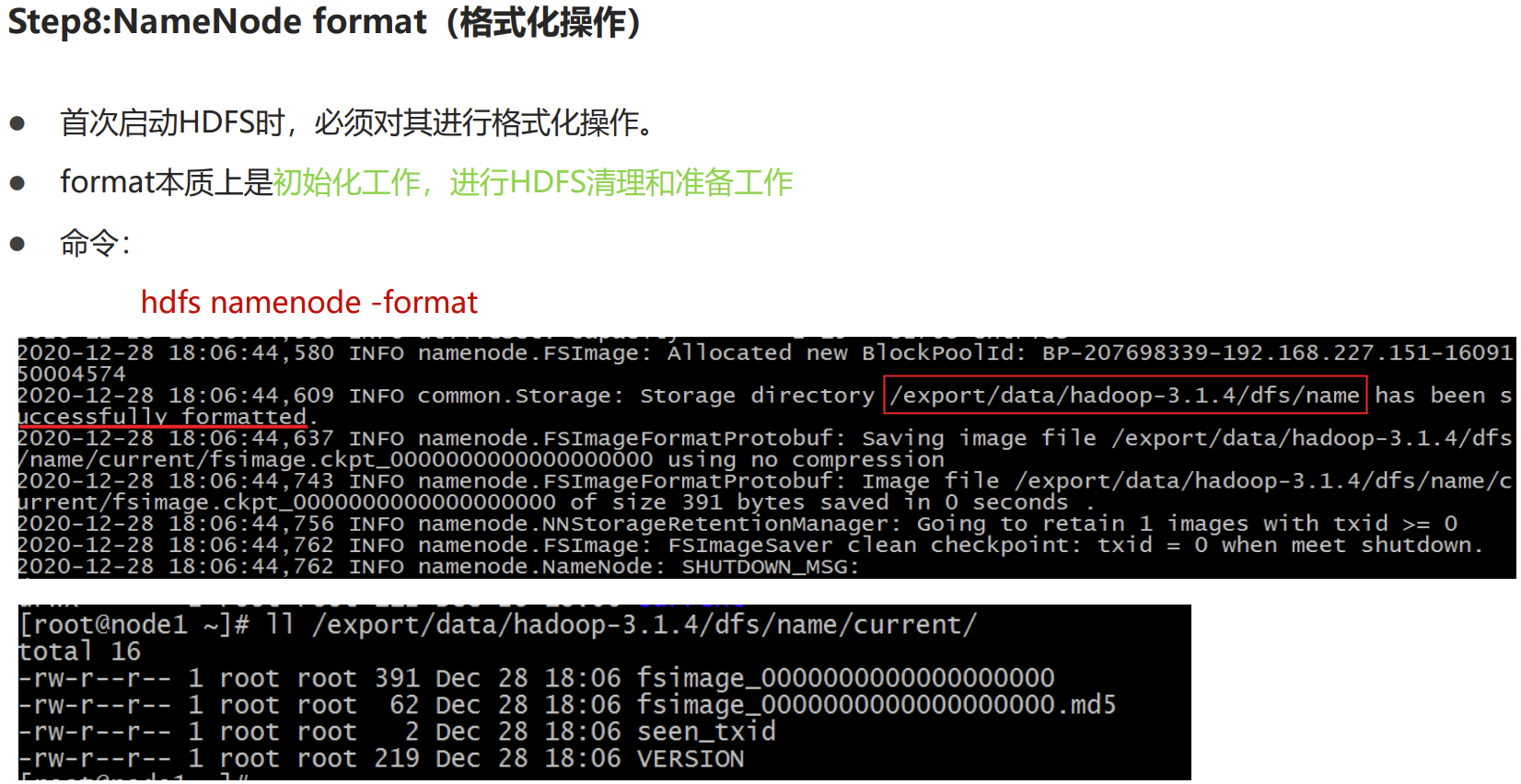
P026【09-Apache Hadoop安装部署--format初始化操作】
P027【10-Apache Hadoop安装部署--集群启停命令、Web UI页面】
P028【11-Apache Hadoop安装部署--初体验】
03【DFS分布式文件系统基础】
P029【12-传统文件系统在大数据时代面临的挑战】
P030【13-场景互动:分布式存储系统的核心属性及功能作用】
P031【14-HDFS简介、设计目标与应用场景】
P032【15-HDFS重要特性解读】
04【HDFS shell操作】
P033【16-HDFS shell命令行解释说明】
P034【17-HDFS shell命令行常用操作】
05【HDFS工作流程与机制】
P035【18-HDFS工作流程与机制--各角色职责介绍与梳理】
P036【19-HDFS工作流程与机制--写数据流程--pipeline、ack、副本策略】
P037【20-HDFS工作流程与机制--写数据流程--梳理】
01【Apache Hadoop概述】
P018【01-课程内容大纲-学习目标】
目录
- Apache Hadoop概述
- Apache Hadoop集群搭建
- HDFS分布式文件系统基础
- HDFS Shell操作
- HDFS读写文件基本流程
学习目标
- 了解Hadoop发展历史、现状
- 掌握Hadoop集群架构、角色
- 掌握Hadoop集群分布式安装部署
- 理解分布式存储的概念与实现
- 掌握HDFS分块存储、副本机制等特性
- 学会shell操作HDFS
- 掌握HDFS读写文件基本流程
P019【02-Apache Hadoop介绍、发展简史、现状】
Hadoop官网:http://hadoop.apache.org/


P020【03-Apache Hadoop特性优点、国内外应用】
Hadoop成功的魅力——通用性、简单性
P021【04-Apache Hadoop发行版本、架构变迁】
Hadoop发行版本
- Apache开源社区版本
- http://hadoop.apache.org/
- 商业发行版本
- Cloudera:https://www.cloudera.com/products/open-source/apache-hadoop.html
- Hortonworks:https://www.cloudera.com/products/hdp.html
- 本课程中使用的是Apache版的Hadoop,版本号为:3.3.0 H
02【Apache Hadoop集群搭建】
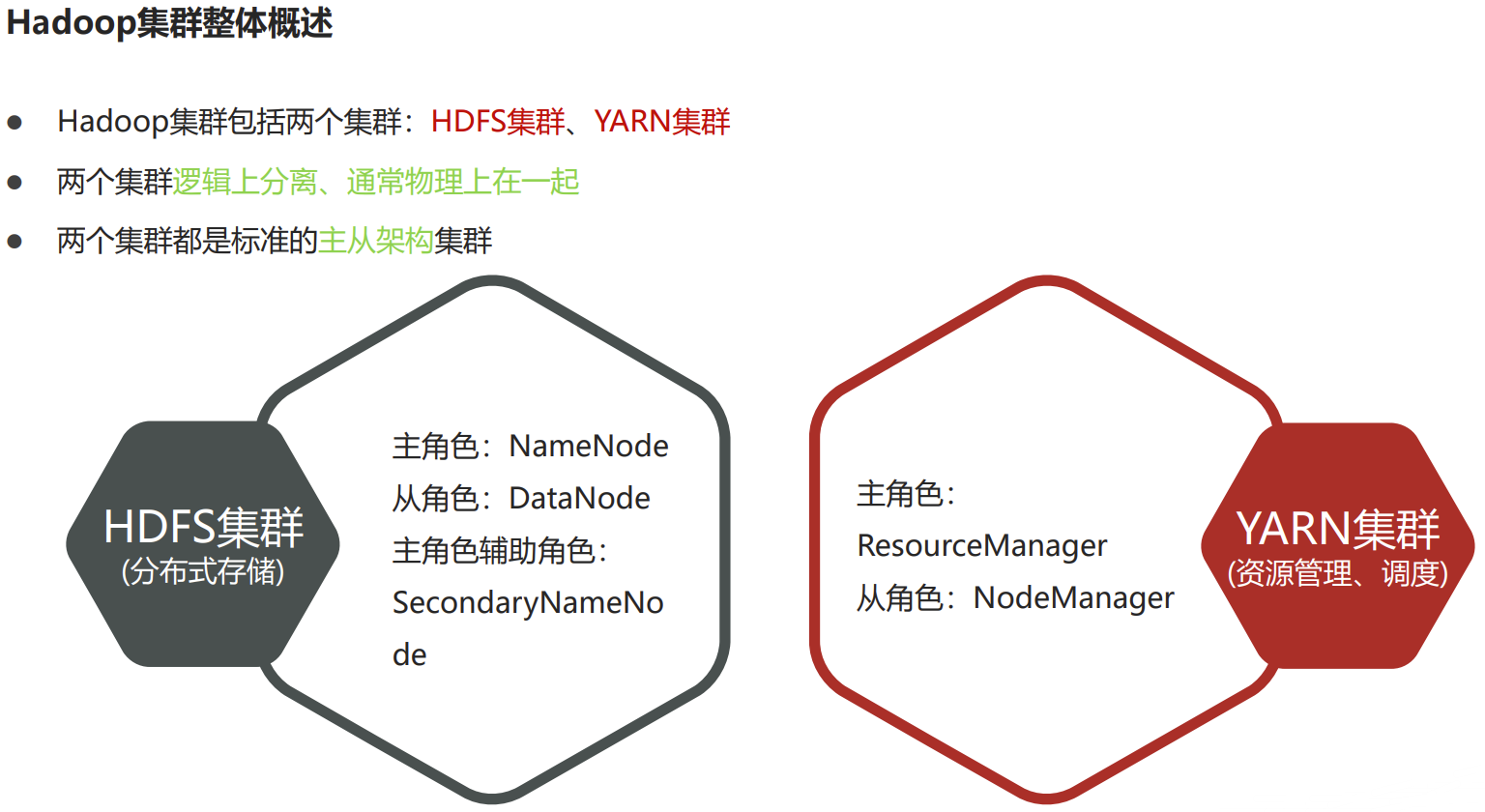
P022【05-Apache Hadoop安装部署--集群组成介绍】
P023【06-Apache Hadoop安装部署--服务器基础环境设置】jdk环境安装
Hadoop由Java语言编写,其运行需要Java语言提供支撑。

安装配置jdk1.8
#解压安装包
tar zxvf jdk-8u65-linux-x64.tar.gz
#配置环境变量
vim /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
#验证是否安装成功
java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)
#别忘了scp给其他两台机器哦
scp -r /export/server/jdk1.8.0_241/ root@node2:/export/server/
scp -r /export/server/jdk1.8.0_241/ root@node3:/export/server/
#环境变量也需要拷贝一份
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
#让三台机器加载环境变量
source /etc/profileP024【07-Apache Hadoop安装部署--安装包结构】
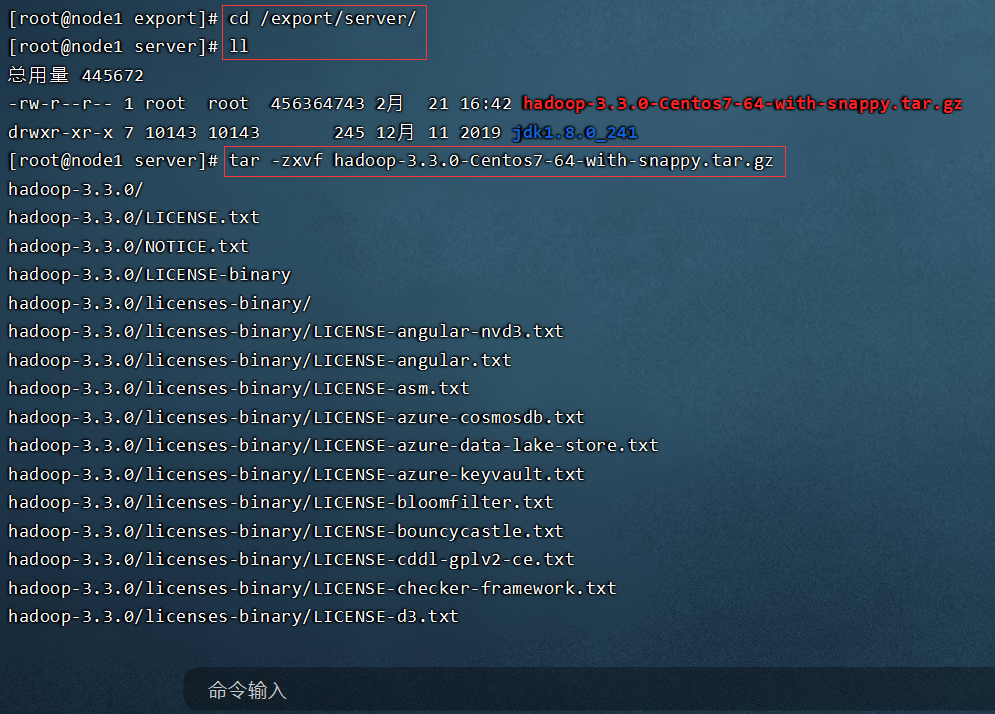
P025【08-Apache Hadoop安装部署--修改配置文件、同步安装包与环境变量】
配置文件概述
- 官网文档:https://hadoop.apache.org/docs/r3.3.0/
- 第一类1个:hadoop-env.sh
- 第二类4个:xxxx-site.xml,site表示的是用户定义的配置,会覆盖default中的默认配置。
- core-site.xml:核心模块配置
- hdfs-site.xml:hdfs文件系统模块配置
- mapred-site.xml:MapReduce模块配置
- yarn-site.xml:yarn模块配置
- 第三类1个:workers
- 所有的配置文件目录:/export/server/hadoop-3.3.0/etc/hadoop
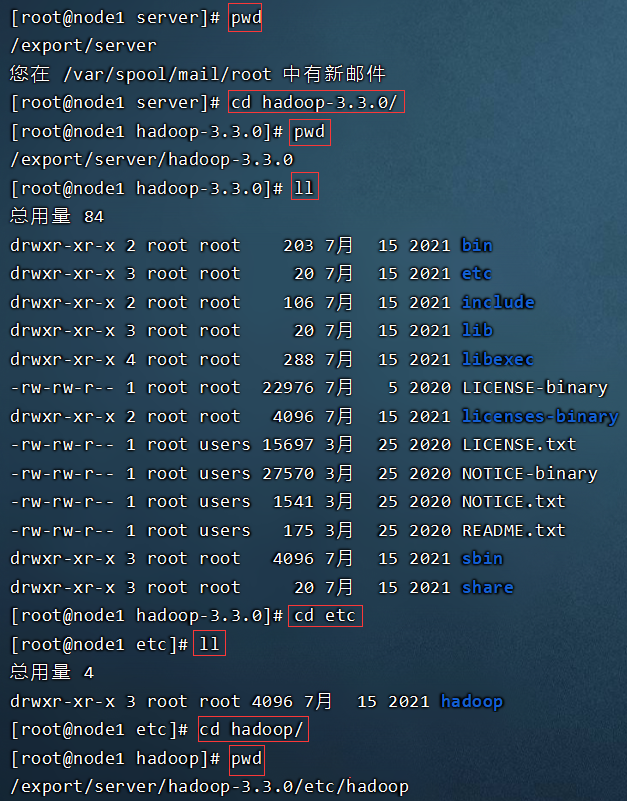
scp /etc/profile node2:/etc/
P026【09-Apache Hadoop安装部署--format初始化操作】
P027【10-Apache Hadoop安装部署--集群启停命令、Web UI页面】
直接使用快照,恢复到第二个快照状态。
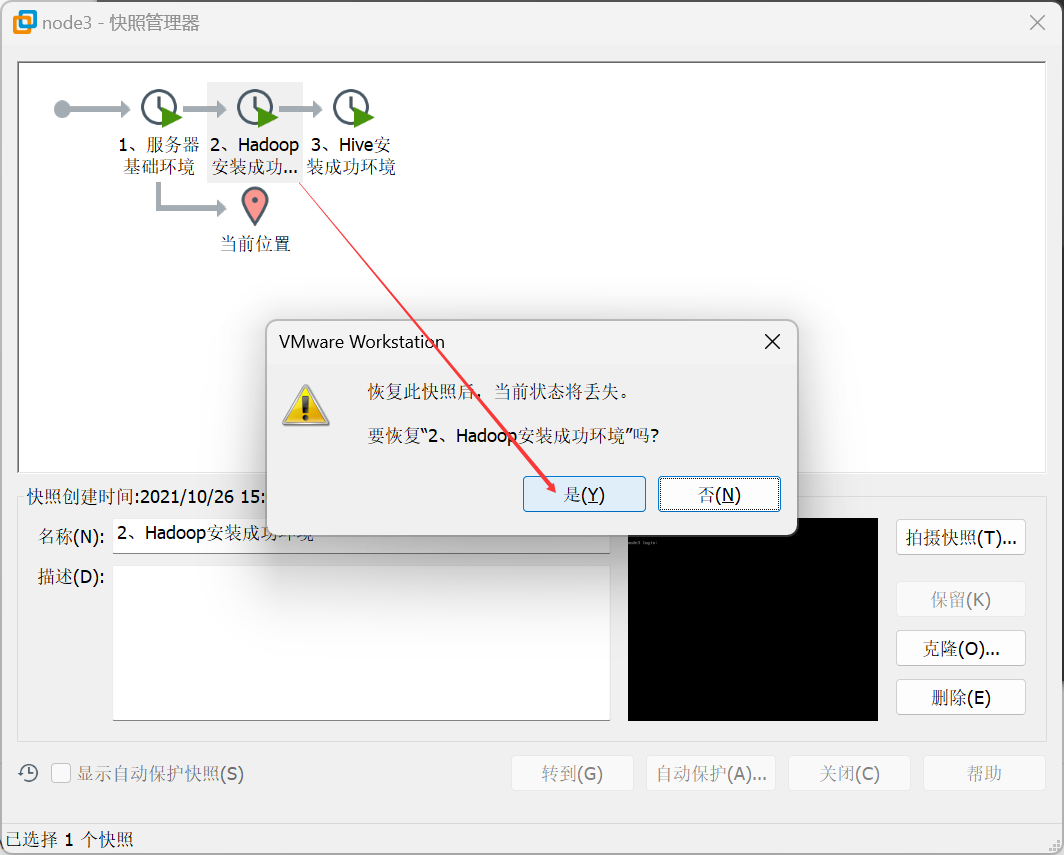
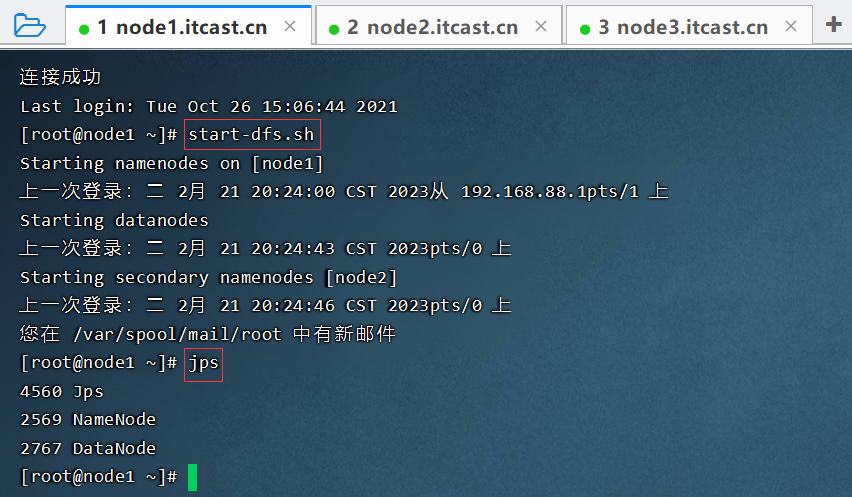
启动完毕之后可以使用jps命令查看进程是否启动成功。
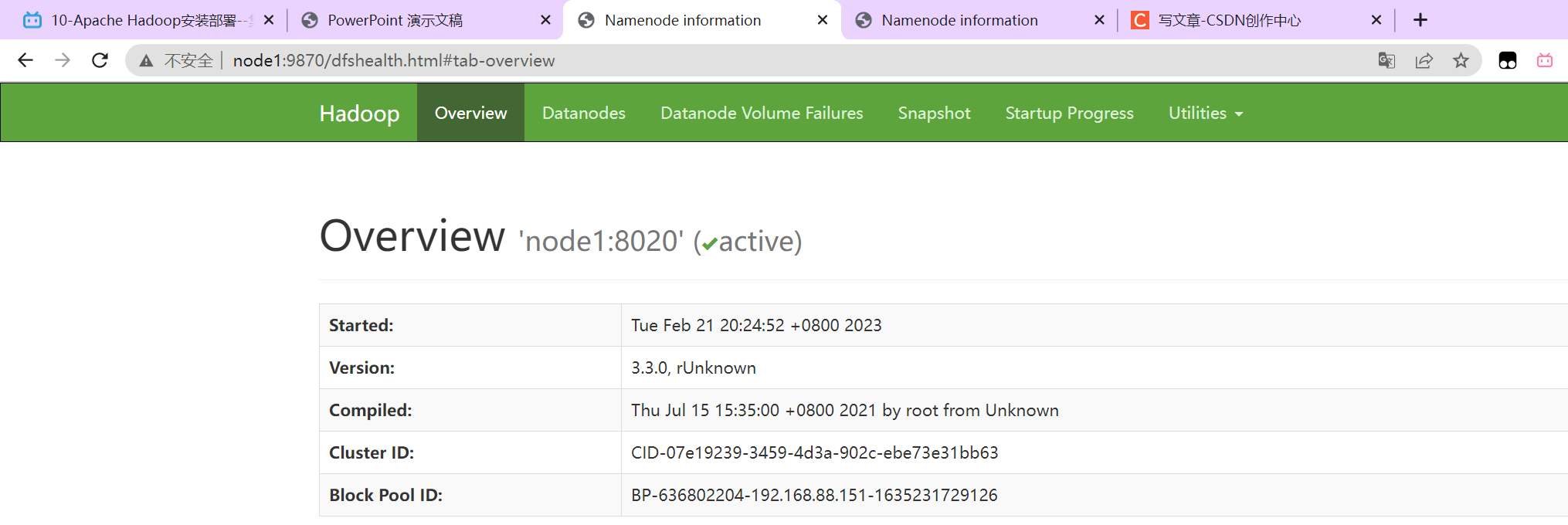
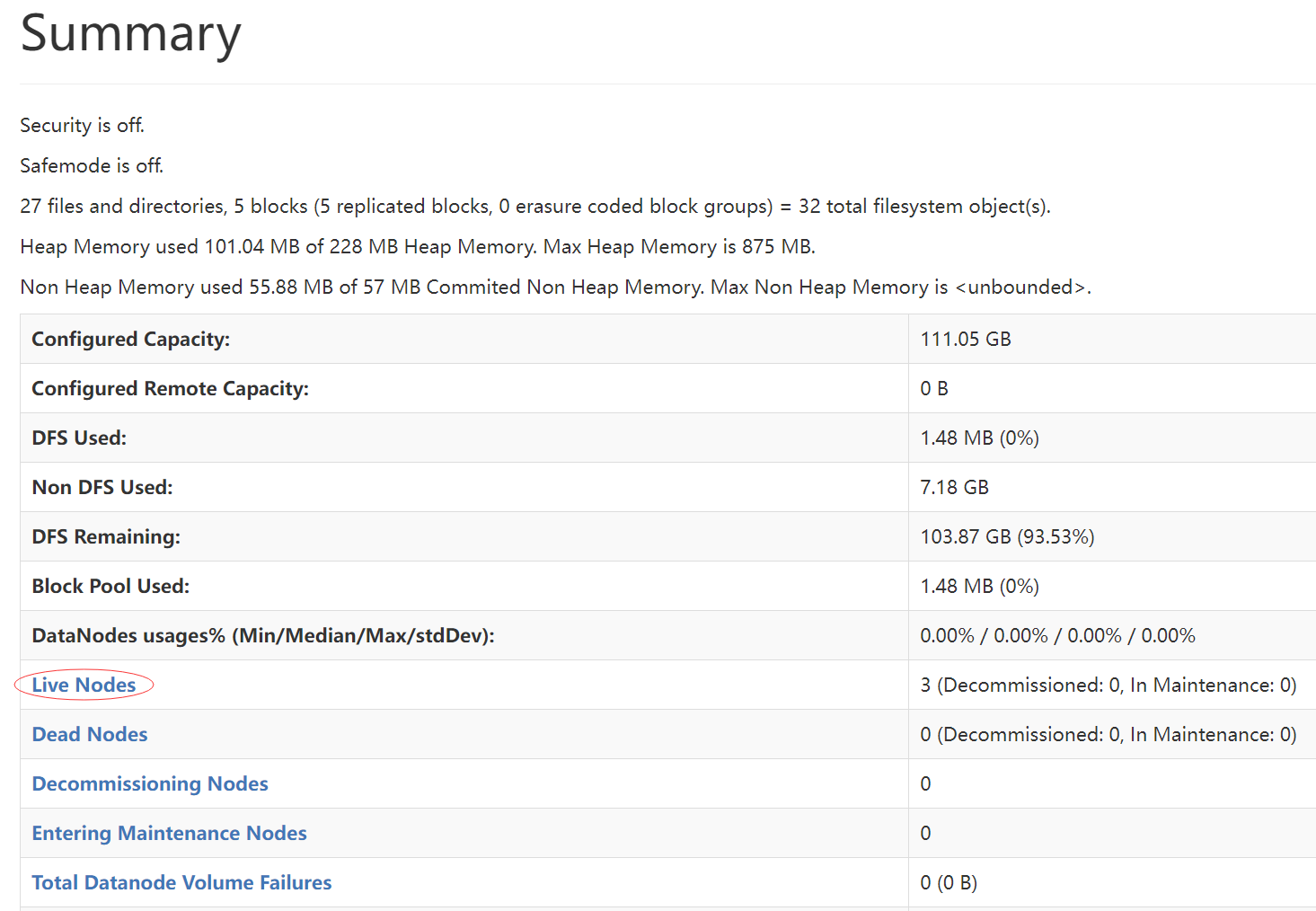
HDFS集群
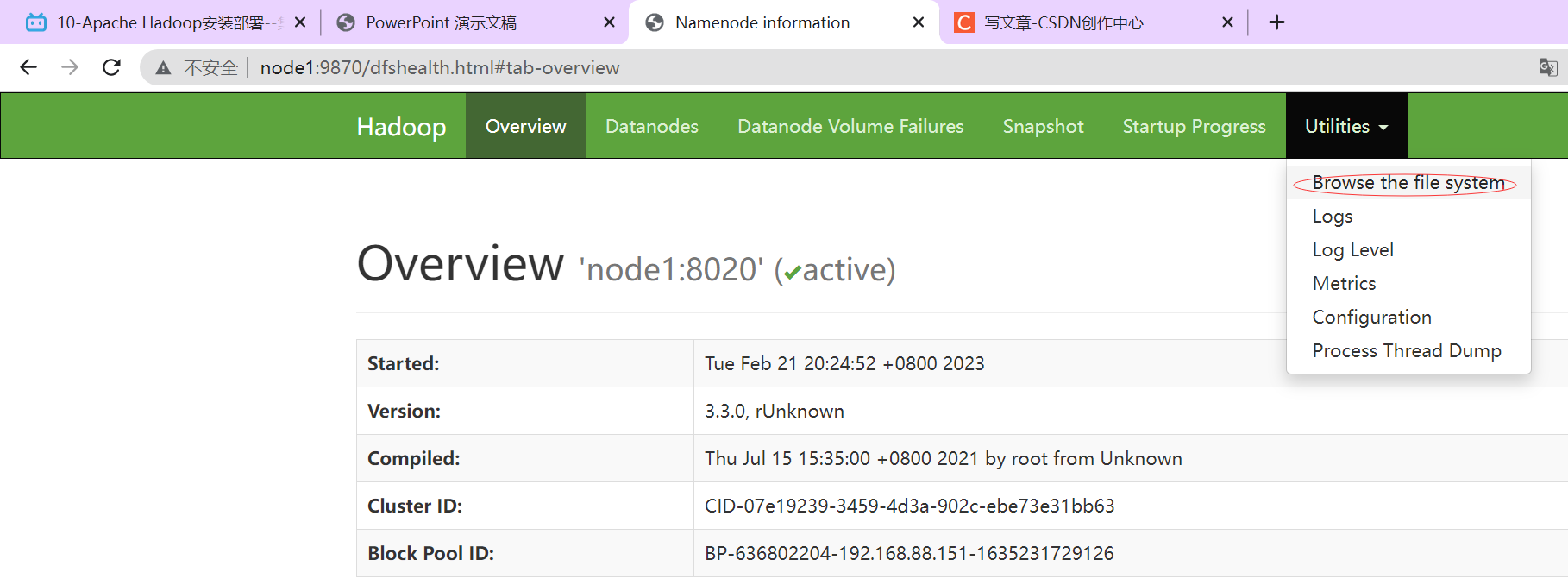
http://node1:9870/dfshealth.html#tab-overview HDFS页面
浏览文件系统:Browse the file system。
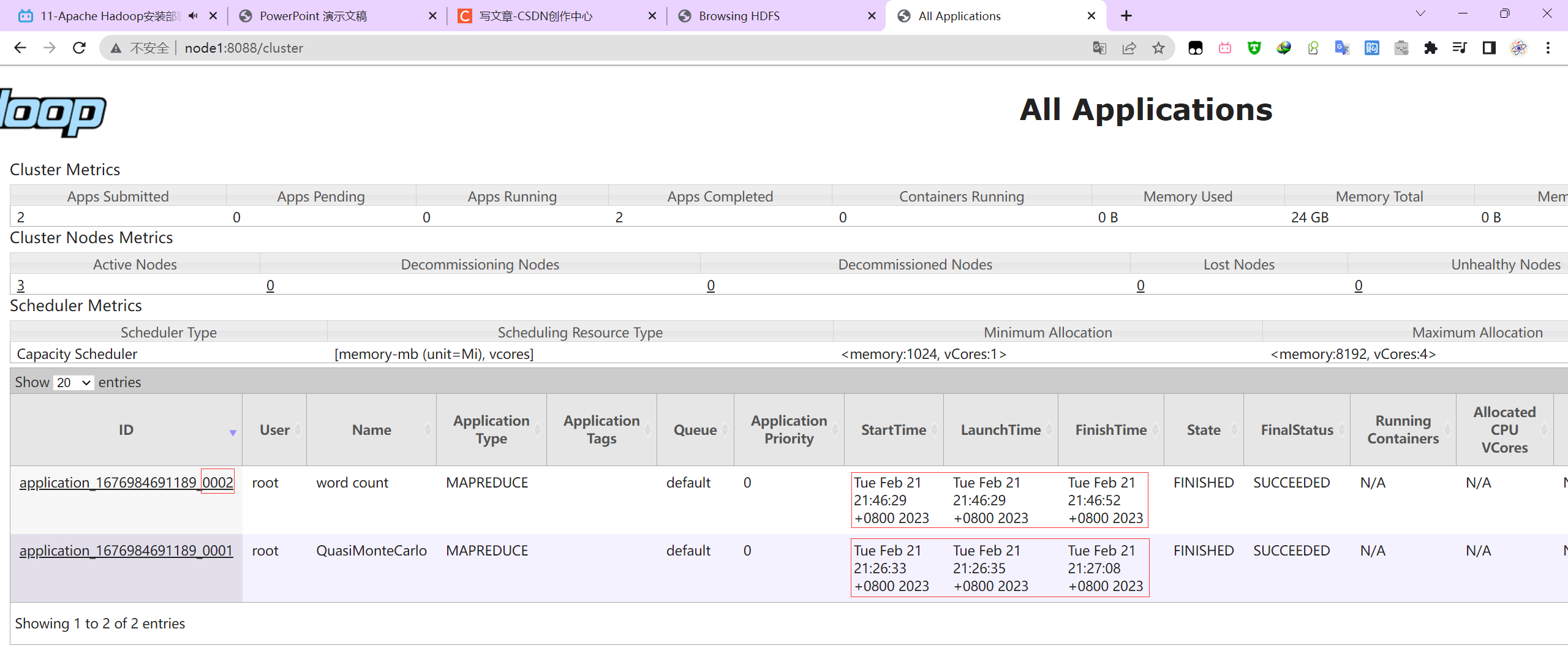
YARN集群
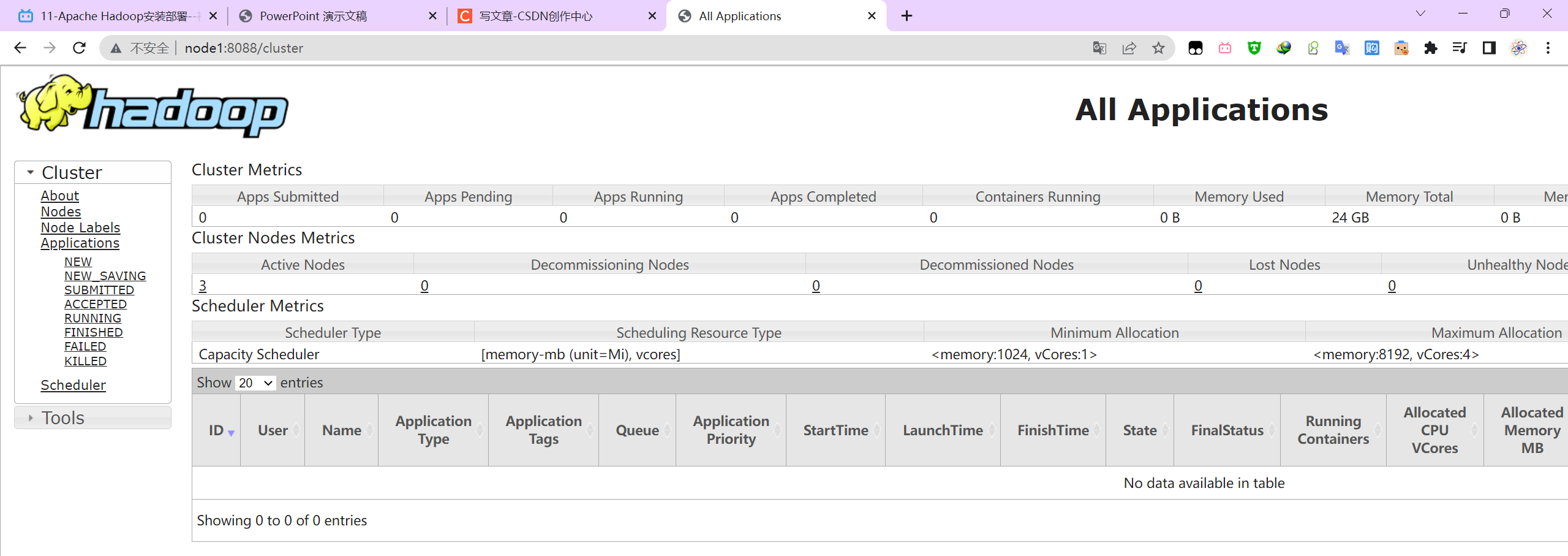
http://node1:8088/cluster
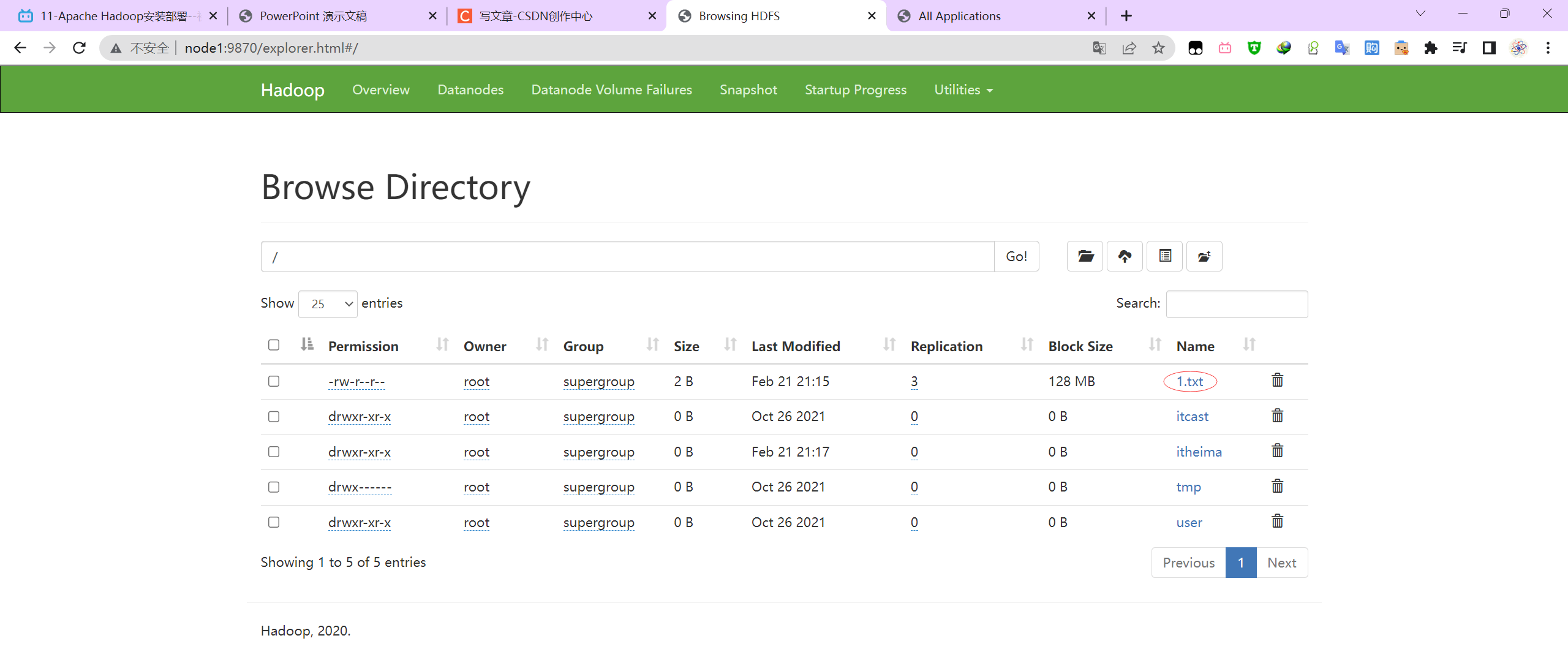
P028【11-Apache Hadoop安装部署--初体验】
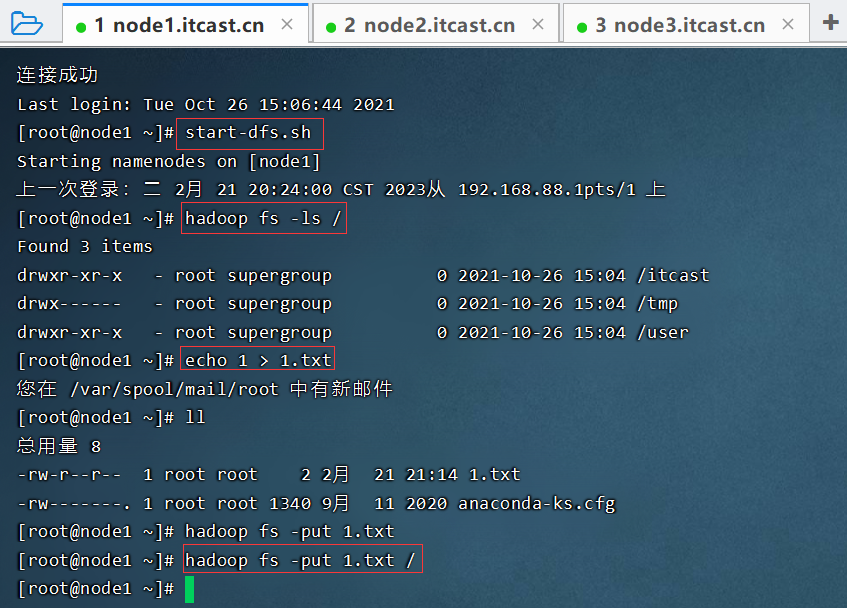
上传文件
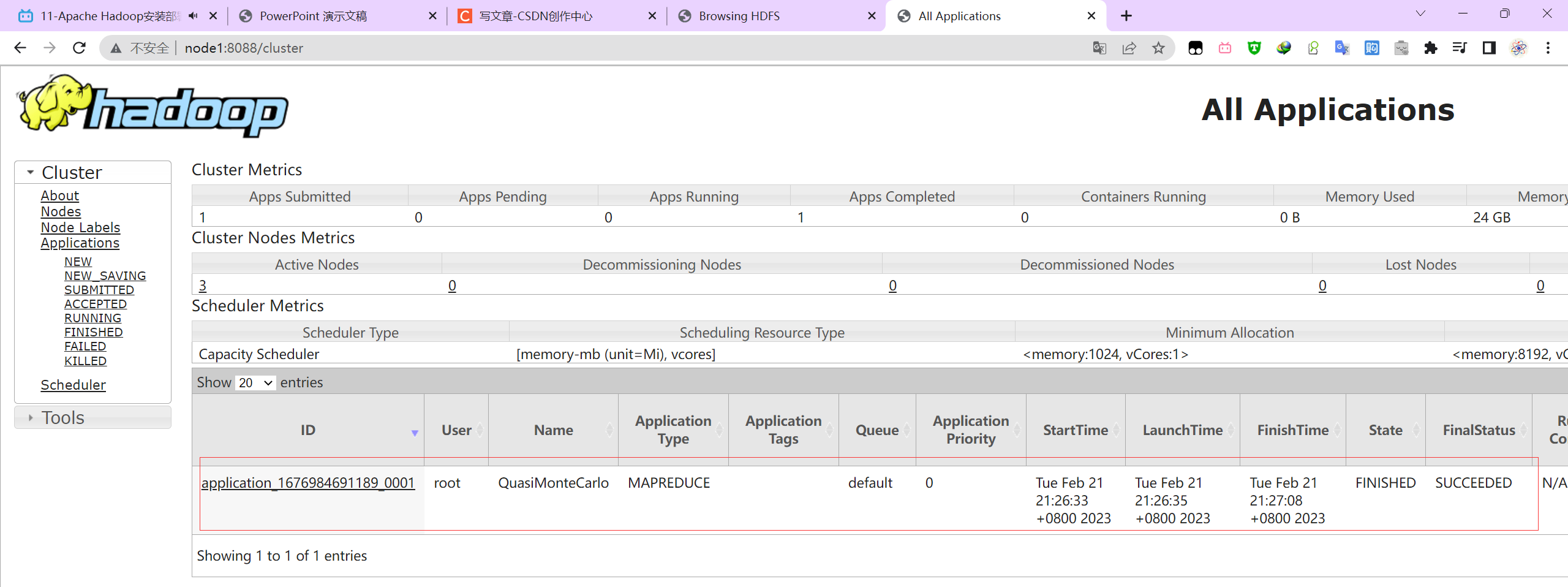
计算圆周率pi
cd /export/server/hadoop-3.3.0/
cd share/hadoop/
cd mapreduce/
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2

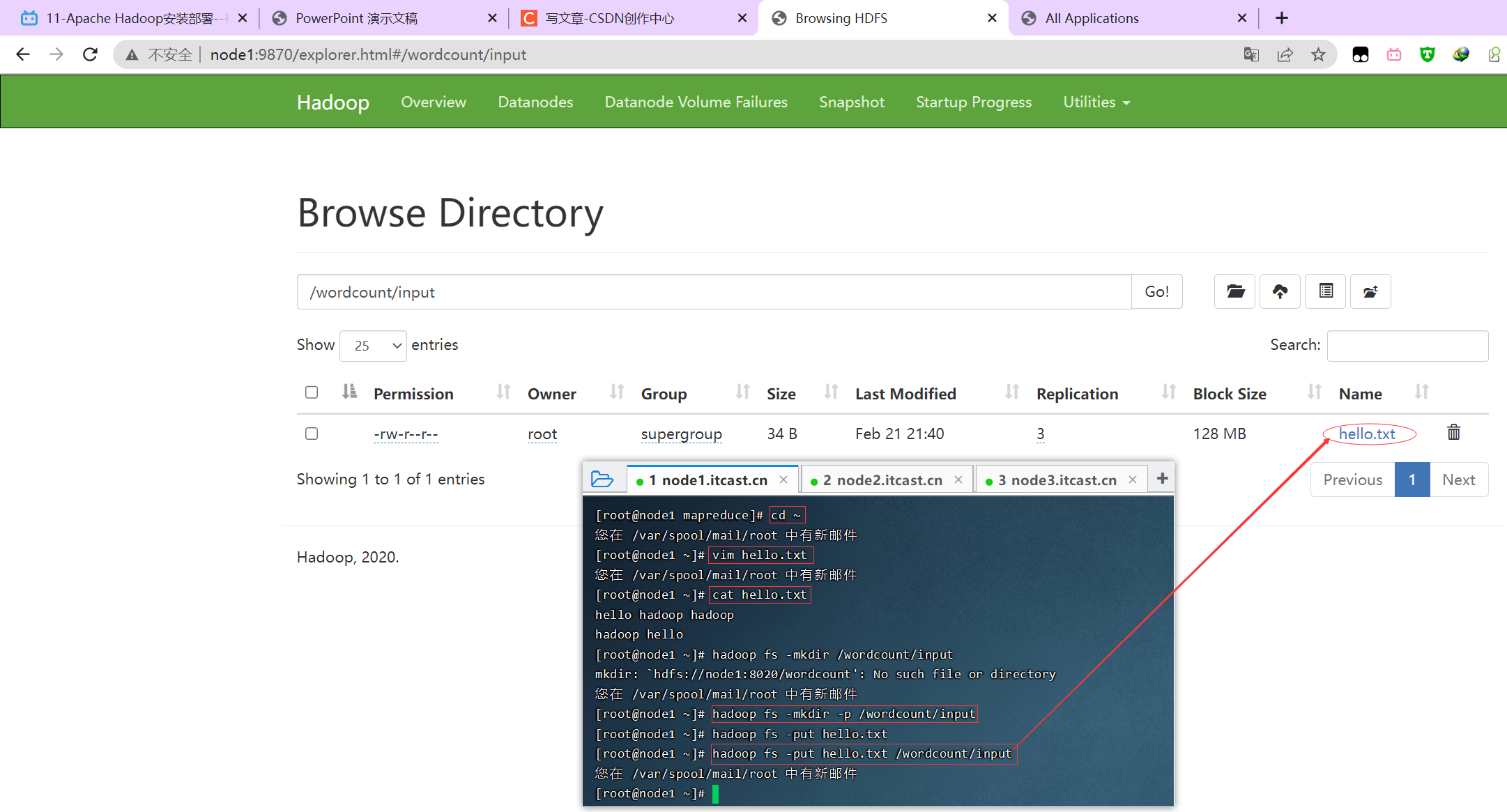
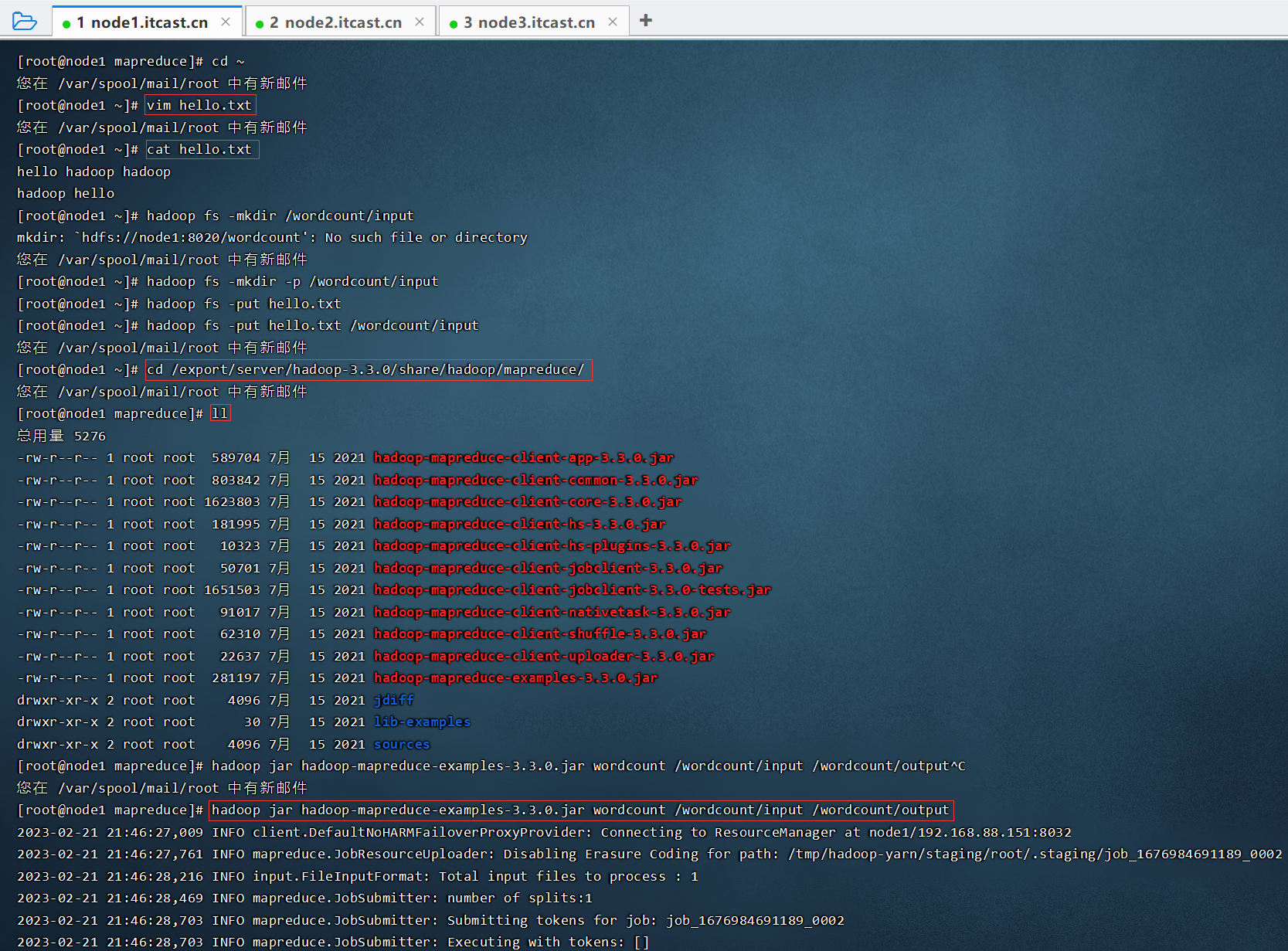
单词统计
hello hadoop hadoop
hadoop hellovim hello.txt
cat hello.txt
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put hello.txt /wordcount/input
cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
03【DFS分布式文件系统基础】
P029【12-传统文件系统在大数据时代面临的挑战】
大数据要考虑的问题:吞吐量、性能、安全性、效率。
P030【13-场景互动:分布式存储系统的核心属性及功能作用】
分布式存储系统核心属性
- 分布式存储
- 元数据记录
- 分块存储
- 副本机制
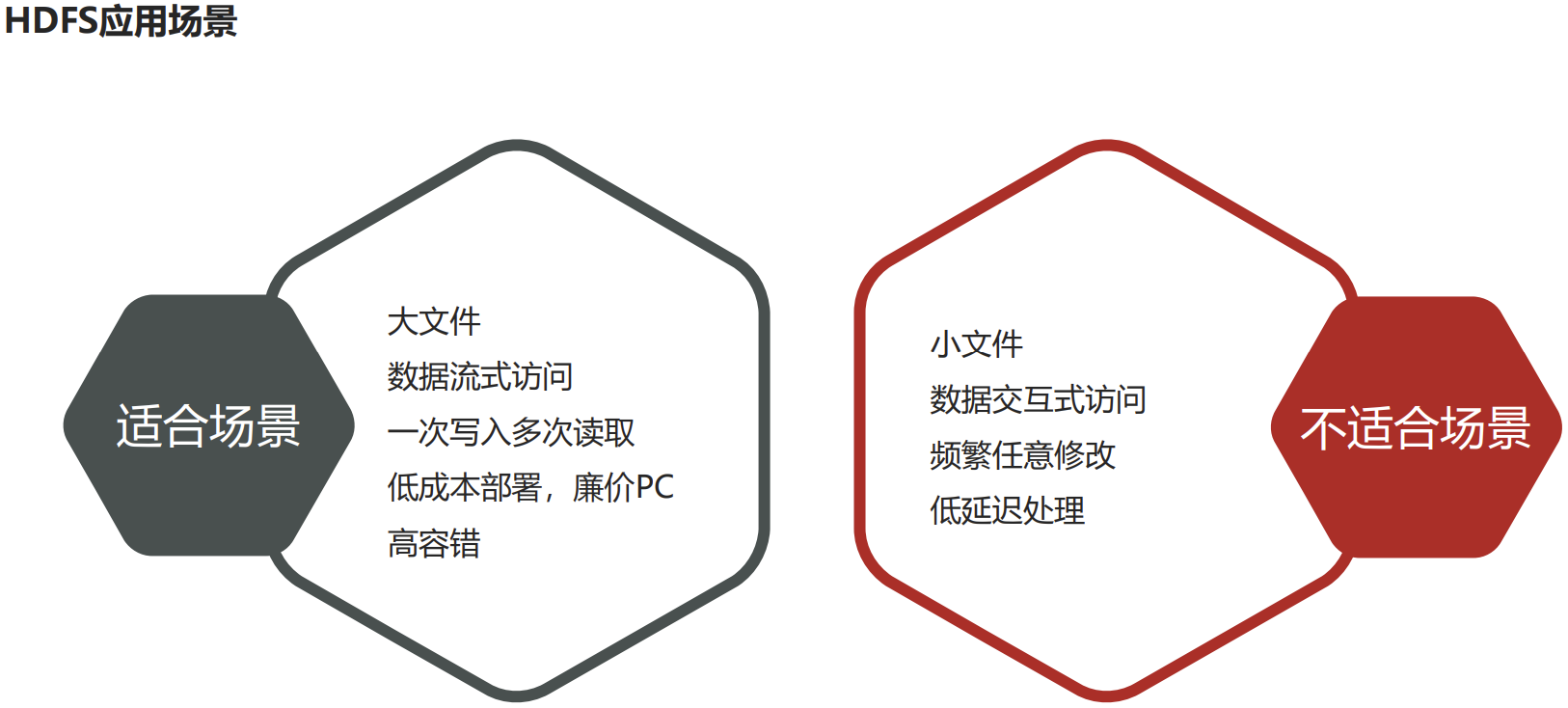
P031【14-HDFS简介、设计目标与应用场景】
HDFS简介
- HDFS(Hadoop Distributed File System ),意为:Hadoop分布式文件系统。
- HDFS是Apache Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。也可以说大数据首先要解决的问题就是海量数据的存储问题。
- HDFS使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。
P032【15-HDFS重要特性解读】
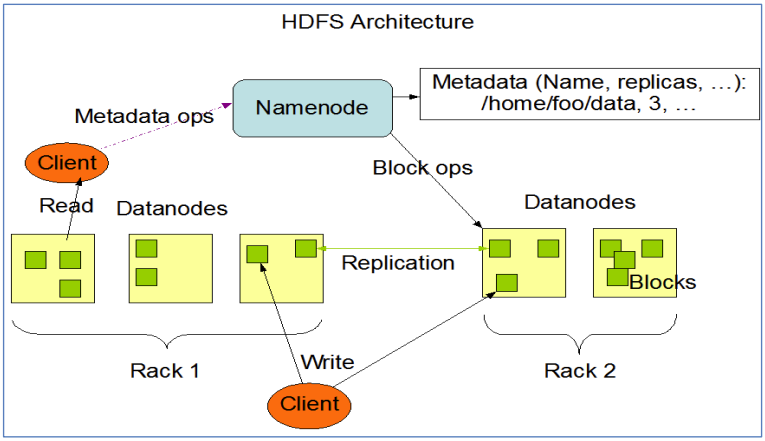
HDFS特性整体概括
- 主从架构
- 分块存储
- 副本机制
- 元数据记录
- 抽象统一的目录树结构(namespace)
04【HDFS shell操作】
P033【16-HDFS shell命令行解释说明】
hadoop fs -ls file:/// 查看本地文件系统。
start-all.sh
hadoop fs -ls hdfs://node1:8020/
cat /export/server/hadoop-3.3.0/etc/hadoop/core-site.xml 查看core-site.xml文件内容。

P034【17-HDFS shell命令行常用操作】
hadoop fs -put anaconda-ks.cfg
hadoop fs -put 2.txt /
hadoop fs -put file:///root/2.txt hdfs://node1:8020/itheima
[root@node1 ~]# hadoop fs -put anaconda-ks.cfg
您在 /var/spool/mail/root 中有新邮件
[root@node1 ~]# hadoop fs -put anaconda-ks.cfg /
[root@node1 ~]# hadoop fs -ls /
Found 7 items
-rw-r--r-- 3 root supergroup 2 2023-02-21 21:15 /1.txt
-rw-r--r-- 3 root supergroup 1340 2023-02-22 10:49 /anaconda-ks.cfg
drwxr-xr-x - root supergroup 0 2021-10-26 15:04 /itcast
drwxr-xr-x - root supergroup 0 2023-02-21 21:17 /itheima
drwx------ - root supergroup 0 2021-10-26 15:04 /tmp
drwxr-xr-x - root supergroup 0 2021-10-26 15:04 /user
drwxr-xr-x - root supergroup 0 2023-02-21 21:46 /wordcount
您在 /var/spool/mail/root 中有新邮件
[root@node1 ~]# hadoop fs -ls -h /
Found 7 items
-rw-r--r-- 3 root supergroup 2 2023-02-21 21:15 /1.txt
-rw-r--r-- 3 root supergroup 1.3 K 2023-02-22 10:49 /anaconda-ks.cfg
drwxr-xr-x - root supergroup 0 2021-10-26 15:04 /itcast
drwxr-xr-x - root supergroup 0 2023-02-21 21:17 /itheima
drwx------ - root supergroup 0 2021-10-26 15:04 /tmp
drwxr-xr-x - root supergroup 0 2021-10-26 15:04 /user
drwxr-xr-x - root supergroup 0 2023-02-21 21:46 /wordcount
[root@node1 ~]# ll
总用量 12
-rw-r--r-- 1 root root 2 2月 21 21:14 1.txt
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
-rw-r--r-- 1 root root 34 2月 21 21:36 hello.txt
您在 /var/spool/mail/root 中有新邮件
[root@node1 ~]# hadoop fs -get hdfs://node1:8020/itheima/2.txt file://root/
您在 /var/spool/mail/root 中有新邮件
[root@node1 ~]# hadoop fs -get /itheima/2.txt ./666.txt
[root@node1 ~]# ll
总用量 16
-rw-r--r-- 1 root root 2 2月 21 21:14 1.txt
-rw-r--r-- 1 root root 4 2月 22 11:03 666.txt
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
-rw-r--r-- 1 root root 34 2月 21 21:36 hello.txt
[root@node1 ~]# 连接成功
Last login: Tue Feb 21 20:24:03 2023 from 192.168.88.1
[root@node2 ~]# hadoop fs -ls /
Found 7 items
-rw-r--r-- 3 root supergroup 2 2023-02-21 21:15 /1.txt
-rw-r--r-- 3 root supergroup 1340 2023-02-22 10:49 /anaconda-ks.cfg
drwxr-xr-x - root supergroup 0 2021-10-26 15:04 /itcast
drwxr-xr-x - root supergroup 0 2023-02-21 21:17 /itheima
drwx------ - root supergroup 0 2021-10-26 15:04 /tmp
drwxr-xr-x - root supergroup 0 2021-10-26 15:04 /user
drwxr-xr-x - root supergroup 0 2023-02-21 21:46 /wordcount
您在 /var/spool/mail/root 中有新邮件
[root@node2 ~]# ll
总用量 4
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
您在 /var/spool/mail/root 中有新邮件
[root@node2 ~]# echo 222 > 2.txt
[root@node2 ~]# hadoop fs -put 2.txt /
[root@node2 ~]# hadoop fs -put file:///root/2.txt hdfs://node1:8020/itheima
您在 /var/spool/mail/root 中有新邮件
[root@node2 ~]# ^C
[root@node2 ~]# hadoop fs -cat /itheima/2.txt
222
您在 /var/spool/mail/root 中有新邮件
[root@node2 ~]# hadoop fs -tail /itheima/2.txt
222
[root@node2 ~]# ll
总用量 8
-rw-r--r-- 1 root root 4 2月 22 10:53 2.txt
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
您在 /var/spool/mail/root 中有新邮件
[root@node2 ~]# echo 1 > 1.txt
[root@node2 ~]# echo 2 > 2.txt
[root@node2 ~]# echo 3 > 3.txt
[root@node2 ~]# cat 1.txt
1
[root@node2 ~]# hadoop fs -put 1.txt /
put: `/1.txt': File exists
您在 /var/spool/mail/root 中有新邮件
[root@node2 ~]# echo 111 > 111.txt
[root@node2 ~]# hadoop fs -put 111.txt /
[root@node2 ~]# hadoop fs -cat /111.txt
111
您在 /var/spool/mail/root 中有新邮件
[root@node2 ~]# hadoop fs -cat /111.txt
[root@node2 ~]hadoop fs -cat /1.txt
1
[root@node2 ~]# hadoop fs -appendToFile 2.txt 11.txt /1.txt
appendToFile: /root/11.txt
[root@node2 ~]# hadoop fs -cat /1.txt
1
2
[root@node2 ~]# hadoop fs -appendToFile 2.txt 11.txt /1.txt
追加命令:用于小文件合并。
HDFS shell其他命令,命令官方指导文档:
https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/FileSystemShell.html
05【HDFS工作流程与机制】
P035【18-HDFS工作流程与机制--各角色职责介绍与梳理】
- 主角色:namenode,需要大内存。
- NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
- NameNode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
- 从角色:datanode,需要大磁盘。
- DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
- DataNode的数量决定了HDFS集群的整体数据存储能力。通过和NameNode配合维护着数据块。
- 主角色辅助角色: secondarynamenode
- SecondaryNameNode充当NameNode的辅助节点,但不能替代NameNode。
- 主要是帮助主角色进行元数据文件的合并动作,可以通俗的理解为主角色的“秘书”。记住了:SNN是用来辅助合并数据的。
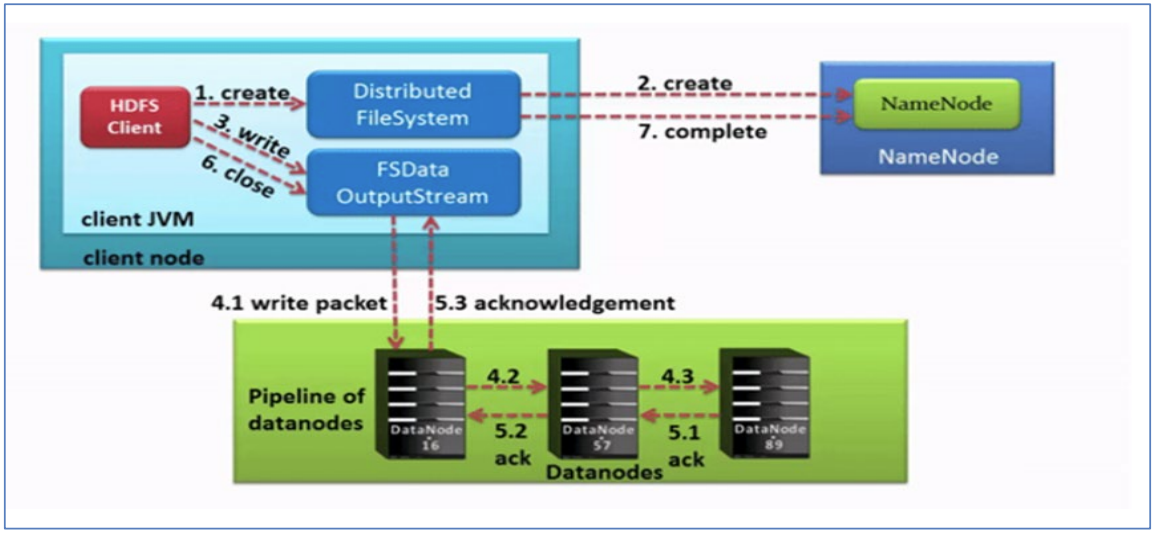
P036【19-HDFS工作流程与机制--写数据流程--pipeline、ack、副本策略】
核心概念--Pipeline管道
- Pipeline,中文翻译为管道。这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
- 客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。
核心概念--ACK应答响应
- ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
- 在HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全。
核心概念--默认3副本存储策略
- 默认副本存储策略是由BlockPlacementPolicyDefault指定。