来源:投稿 作者:175
编辑:学姐
往期内容:
从零实现深度学习框架1:RNN从理论到实战(理论篇)
从零实现深度学习框架2:RNN从理论到实战(实战篇)
从零实现深度学习框架3:再探多层双向RNN的实现
从零实现深度学习框架:Seq2Seq从理论到实战【理论篇】
从零实现深度学习框架:Seq2Seq从理论到实战【实战篇】(本篇)
引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不使用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
在上篇文章中了解seq2seq的理论知识,作为实战,本文为完成机器翻译任务来实现seq2seq模型来。
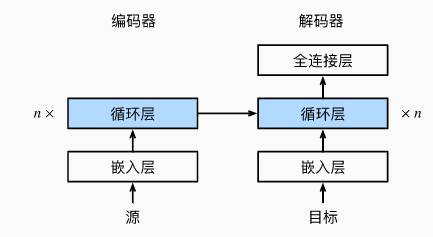
编码器-解码器架构

正如我们前面所讨论的,编码器-解码器架构可以处理输入和输出都是可变长度的序列。编码器接受变成序列作为输入,并将其转换为定长的编码向量。解码器将定长的编码向量映射成变长的序列。
编码器
class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X) -> Tensor:
raise NotImplementedError
我们定义一个编码器基类,编码器的具体实现可以是RNN、CNN或Transformer等。
这里我们基于RNN实现编码器。
class RNNEncoder(Encoder):
'''用RNN实现编码器'''
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(RNNEncoder, self).__init__(**kwargs)
# 嵌入层 获取输入序列中每个单词的嵌入向量
self.embedding = nn.Embedding(vocab_size, embed_size)
# 基于GRU实现
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
def forward(self, X) -> Tensor:
'''
Args:
X: 形状 (batch_size, num_steps)
Returns:
'''
X = self.embedding(X) # X 的形状 (batch_size, num_steps, embed_size)
X = X.permute((1, 0, 2)) # (num_steps, batch_size, embed_size)
output, state = self.rnn(X)
return output, state
下面我们实例化上述编码器进行测试。并给定一个小批量的输入序列,批大小为4,时间步长度为7。
encoder = RNNEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
encoder.eval()
X = Tensor.zeros((4, 7), dtype=numpy.int32)
output, state = encoder(X)
print(output.shape)
(7, 4, 16)
在完成所有时间步之后,最后一层的隐藏状态输出是一个向量,其形状为(时间步长,批大小,隐藏单元数)。
解码器
在解码器的接口中,增加一个init_state函数,用于从编码器的输出中提取编码后的状态。
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs):
raise NotImplementedError
def forward(self, X, state) -> Tuple[Tensor, Tensor]:
raise NotImplementedError
基于RNN实现的解码器如下:
class RNNDecoder(Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=.0, **kwargs):
super(RNNDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
# embed_size + num_hiddens 为了处理拼接后的维度,见forward函数中的注释
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, batch_first=False, dropout=dropout)
# 将隐状态转换为词典大小维度
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs):
return enc_outputs[1] # 得到编码器输出中的state
def forward(self, X, state) -> Tuple[Tensor, Tensor]:
X = self.embedding(X).permute((1, 0, 2)) # (num_steps, batch_size, embed_size)
# 将最顶层的上下文向量广播成与X相同的时间步,其他维度上只复制1次(保持不变)
# 形状 (num_layers, batch_size, num_hiddens ) => (num_steps, batch_size, num_hiddens)
context = state[-1].repeat((X.shape[0], 1, 1))
# 为了每个解码时间步都能看到上下文,拼接context与X
# (num_steps, batch_size, embed_size) + (num_steps, batch_size, num_hiddens)
# => (num_steps, batch_size, embed_size + num_hiddens)
concat_context = F.cat((X, context), 2)
output, state = self.rnn(concat_context, state)
output = self.dense(output).permute((1, 0, 2)) # (batch_size, num_steps, vocab_size)
return output, state
为了在解码器的每个时间步都能看到上下文信息,上下文向量与解码器的输入进行了拼接。
下面,我们用与前面提到的编码器中相同的超参数来实例化解码器。 如我们所见,解码器的输出形状变为(批大小,时间步长,词表大小), 其中最后一个维度存储预测的单词概率分布。
decoder = RNNDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
print(output.shape, state.shape)
(4, 7, 10) (2, 4, 16)
合并编码器和解码器
class EncoderDecoder(nn.Module):
'''合并编码器和解码器'''
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X) -> Tensor:
enc_outputs = self.encoder(enc_X)
dec_state = self.decoder.init_state(enc_outputs)
return self.decoder(dec_X, dec_state)
合并编码器和解码器很简单,只要传入实例化好的编码器和解码器即可。在forward中从编码器的输出中抽取上下文向量,与解码器的输入同时传入解码器。
数据集与预处理
本小节介绍一下如何处理机器翻译的数据集。为了能更好的看到效果,这里采用中英翻译数据集。
数据集下载:https://download.csdn.net/download/yjw123456/86247212
我们先来看一下数据是长什么样的:
anyone can do that. 任何人都可以做到。
How about another piece of cake? 要不要再來一塊蛋糕?
She married him. 她嫁给了他。
I don't like learning irregular verbs. 我不喜欢学习不规则动词。
It's a whole new ball game for me. 這對我來說是個全新的球類遊戲。
He's sleeping like a baby. 他正睡着,像个婴儿一样。
He can play both tennis and baseball. 他既会打网球,又会打棒球。
We should cancel the hike. 我們應該取消這次遠足。
He is good at dealing with children. 他擅長應付小孩子。
观察数据集,我们需要进行预处理。包括分词,这里对中文语句以字为单位进行切分。
加载数据
首先来加载数据:
def read_nmt(file_path='../data/en-cn/train_mini.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
def cht_to_chs(sent):
# pip install hanziconv
# 繁体转换为简体
sent = HanziConv.toSimplified(sent)
sent.encode("utf-8")
return sent
同时由于中文是繁体,所以这里进行一个简繁转换。
raw_text = cht_to_chs(read_nmt())
print(raw_text[:74])
Anyone can do that. 任何人都可以做到。
How about another piece of cake? 要不要再来一块蛋糕?
预处理
看起来不错,下面我们来实现预处理。 例如,我们用空格代替不间断空格(non-breaking space), 使用小写字母替换大写字母,并在单词和标点符号之间插入空格。
def process_nmt(text):
"""预处理“英文-中文”数据集"""
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格,并全部转换为小写
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
同时也对上面得到的原始数据进行测试:
text = process_nmt(raw_text)
print(text[:76])
anyone can do that . 任何人都可以做到。
how about another piece of cake ? 要不要再来一块蛋糕?
注意到,这里只是对英文中的空白符和符号进行了处理,并没有处理中文的。因为中文可以直接按字拆分,这在Python中也很好实现。
词元化
下面实现分词代码:
def tokenize_nmt(text, num_examples=None):
"""词元化“英文-中文”数据数据集"""
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' ')) # 英文按空格切分
target.append([char for char in parts[1]]) # 中文按字切分
return source, target
在上面代码运行结果的基础上进行分词,为了简单,这里指定样本数为6:
from pprint import pprint
source, target = tokenize_nmt(text, 6)
pprint(source)
pprint(target)
[['anyone', 'can', 'do', 'that', '.'],
['how', 'about', 'another', 'piece', 'of', 'cake', '?'],
['she', 'married', 'him', '.'],
['i', "don't", 'like', 'learning', 'irregular', 'verbs', '.'],
["it's", 'a', 'whole', 'new', 'ball', 'game', 'for', 'me', '.'],
["he's", 'sleeping', 'like', 'a', 'baby', '.'],
['he', 'can', 'play', 'both', 'tennis', 'and', 'baseball', '.']]
[['任', '何', '人', '都', '可', '以', '做', '到', '。'],
['要', '不', '要', '再', '来', '一', '块', '蛋', '糕', '?'],
['她', '嫁', '给', '了', '他', '。'],
['我', '不', '喜', '欢', '学', '习', '不', '规', '则', '动', '词', '。'],
['这', '对', '我', '来', '说', '是', '个', '全', '新', '的', '球', '类', '游', '戏', '。'],
['他', '正', '睡', '着', ',', '像', '个', '婴', '儿', '一', '样', '。'],
['他', '既', '会', '打', '网', '球', ',', '又', '会', '打', '棒', '球', '。']]
构建词表
由于机器翻译数据集由语言对组成,因此我们需要分别为源语言和目标语言构建两个词表。
src_vocab = Vocabulary.build(source, min_freq=min_freq, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN])
print(len(src_vocab))
print(src_vocab.token(0))
print(src_vocab.token(1))
42
<unk>
<pad>
我们直接调用之前实现好的词表类构建即可。这里分别输出了ID为0和1的单词。
截断与填充
语言模型中的序列样本有一个固定的长度,该固定的长度就是时间步数。而在机器翻译中,每个样本都是由源和目标组成的序列对,其中每个文本序列可能具有不同的长度。
为了提高计算效率,我们需要通过截断(truncation)和填充(padding)方式实现一次只处理一个小批量的文本序列,并且每个小批量中的序列都应该具有相同的长度num_steps。那么当某个文本序列的长度小于num_steps时,我们将在其末尾添加填充符<pad>,直到达到num_steps;反之,如果某个文本序列的长度超过num_steps,我们则需要截断它,只取前num_step个单词。
这样,每个文本序列将具有相同的长度,以便以相同形状的小批量进行加载。
下面定义截断或填充函数:
def truncate_pad(line, max_len, padding_token):
"""截断或填充文本序列"""
if len(line) > max_len:
return line[:max_len] # 截断
return line + [padding_token] * (max_len - len(line)) # 填充
print(truncate_pad(src_vocab[source[0]], 10, src_vocab[PAD_TOKEN]))
[4, 5, 6, 7, 8, 1, 1, 1, 1, 1]
我们知道该语句为:['anyone', 'can', 'do', 'that', '.'],它的长度为5,后面填充了5个填充符。
批量化
现在我们定义一个函数,可以将文本序列转换成小批量数据集用于训练。 我们将特定的“”单词添加到所有序列的末尾, 用于表示序列的结束。 当模型通过一个单词接一个单词地生成序列进行预测时, 生成的“”单词说明完成了序列输出工作。
def build_array_nmt(lines, vocab, max_len=None):
if not max_len:
max_len = max(len(x) for x in lines)
"""将机器翻译的文本序列转换成小批量"""
lines = [vocab[l] for l in lines]
lines = [l + [vocab[EOS_TOKEN]] for l in lines]
return np.array([truncate_pad(l, max_len, vocab[PAD_TOKEN]) for l in lines])
然后我们设定序列最大长度为10,构建这6个序列样本批量化的结果:
src_array = build_array_nmt(source, src_vocab, 10)
print(src_array)
[[ 4 5 6 7 8 3 1 1 1 1]
[ 9 10 11 12 13 14 15 3 1 1]
[16 17 18 8 3 1 1 1 1 1]
[19 20 21 22 23 24 8 3 1 1]
[25 26 27 28 29 30 31 32 8 3]
[33 34 21 26 35 8 3 1 1 1]
[36 5 37 38 39 40 41 8 3 1]]
定义机器翻译数据集
class NMTDataset(Dataset):
def __init__(self, data):
self.data = np.array(data)
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
@staticmethod
def collate_fn(examples):
src = [Tensor(ex[0]) for ex in examples]
tgt = [Tensor(ex[1]) for ex in examples]
# 这里只是转换为Tensor向量
src = pad_sequence(src)
tgt = pad_sequence(tgt)
return src, tgt
该数据集同时保存了源于目标样本数据。
加载数据集
下面定义一个函数来返回数据加载器和源语言以及目标语言词表。
def load_dataset_nmt(data_path, batch_size=32, min_freq=1, max_len=20):
# 读取原始文本
raw_text = read_nmt(data_path)
# 处理英文符号
text = process_nmt(raw_text)
# 中英文分词
source, target = tokenize_nmt(text)
# 构建源和目标词表
src_vocab = Vocabulary.build(source, min_freq=min_freq, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN])
tgt_vocab = Vocabulary.build(target, min_freq=min_freq, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN])
print(f'Source vocabulary size:{len(src_vocab)}, Target vocabulary size: {len(tgt_vocab)}')
# 转换成批数据
src_array = build_array_nmt(source, src_vocab, max_len)
tgt_array = build_array_nmt(target, tgt_vocab, max_len)
# 构建数据集
dataset = NMTDataset([(src, tgt) for src, tgt in zip(src_array, tgt_array)])
# 数据加载器
data_loader = DataLoader(dataset, batch_size=batch_size, collate_fn=dataset.collate_fn, shuffle=True)
# 返回加载器和两个词表
return data_loader, src_vocab, tgt_vocab
train_dataset, src_vocab, tgt_vocab = load_dataset_nmt('../data/en-cn/train_mini.txt')
for X, Y in train_dataset:
print('X:', X.shape)
print('Y:', Y.shape)
break
Source vocabulary size: 1476, Target vocabulary size: 1445
X: (32, 20)
Y: (32, 20)
至此,数据集处理好了,我们可以喂给模型进行训练了。但在此之前,还需要先定义训练用的损失函数。
损失函数
编码器和解码器架构已经实现好了,接下来可以开始训练。但在训练之前需要先定义好损失函数。在每个时间步,解码器预测了输出单词的概率分布。类似于语言模型,可以用softmax来获得分布,并通过交叉熵损失函数来进行优化。
但由于批次内不同样本的长度不同,我们添加了填充单词到短序列中,这样不同长度的序列可以通过相同形状的小批量加载。但是我们应该将填充单词的预测排除到损失函数的计算之外。
class MaskedSoftmaxCELoss(CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, padding_value):
self.reduction = 'none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(pred, label)
label_valid = label != padding_value
# with no_grad():
# num_tokens = label_valid.sum().item()
# weighted_loss = (unweighted_loss * label_valid).sum() / float(num_tokens)
weighted_loss = (unweighted_loss * label_valid).sum()
return weighted_loss
训练

在训练阶段,如上图所示, 特定的序列开始单词(<bos>)和 原始的输出序列(不包括序列结束单词<eos>) 拼接在一起作为解码器的输入。 这被称为强制教学(teacher forcing), 因为原始的输出序列(单词的标签)被送入解码器。 而在推理阶段,通常将来自上一个时间步的预测得到的单词作为解码器的当前输入。
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
net.to(device)
optimizer = SGD(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = Animator(xlabel='epoch', ylabel='loss', xlim=[10, num_epochs])
for epoch in tqdm(range(num_epochs)):
timer = Timer()
metric = Accumulator(2) # 训练损失总和,单词数量
for batch in data_iter:
optimizer.zero_grad()
X, Y = [x.to(device) for x in batch]
bos = Tensor([tgt_vocab[BOS_TOKEN]] * Y.shape[0], device=device).reshape((-1, 1))
dec_input = F.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input)
Y = Y.view(-1)
output_dim = Y_hat.shape[-1]
Y_hat = Y_hat.view(-1, output_dim)
l = loss(Y_hat, Y, tgt_vocab[PAD_TOKEN])
l.sum().backward()
num_tokens = (Y != 0).sum()
optimizer.step()
with no_grad():
metric.add(l.sum().item(), num_tokens.item())
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
下面,就可以执行训练操作了:
# 参数定义
embed_size = 64
num_hiddens = 128
num_layers = 2
dropout = 0.1
batch_size = 128
num_steps = 20
lr = 0.0005
num_epochs = 1000
min_freq = 1
device = cuda.get_device("cuda:0" if cuda.is_available() else "cpu")
# 加载数据集
train_iter, src_vocab, tgt_vocab = load_dataset_nmt('../data/en-cn/train_mini.txt', batch_size=batch_size,
min_freq=min_freq, max_len=num_steps)
# 构建编码器
encoder = RNNEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
# 构建解码器
decoder = RNNDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
# 编码器-解码器
net = EncoderDecoder(encoder, decoder)
# 训练
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
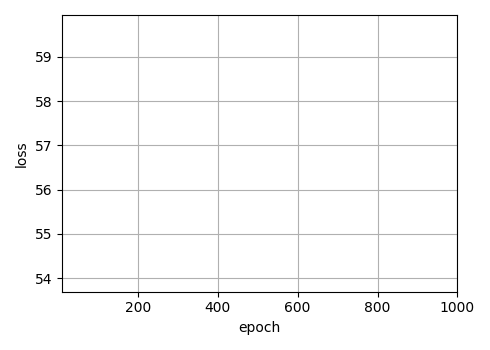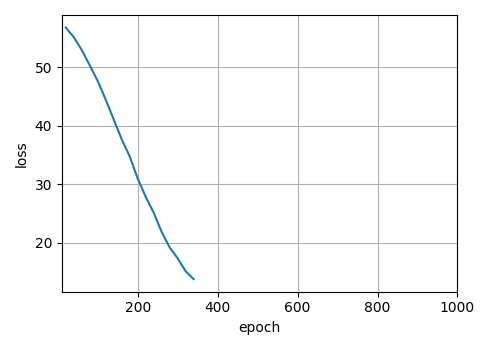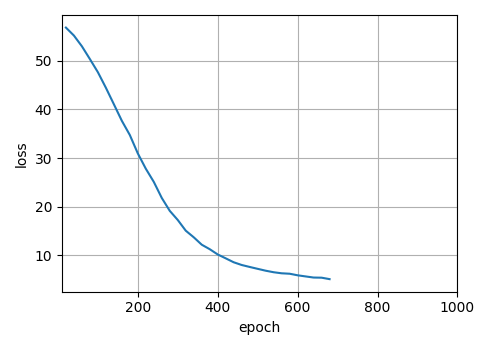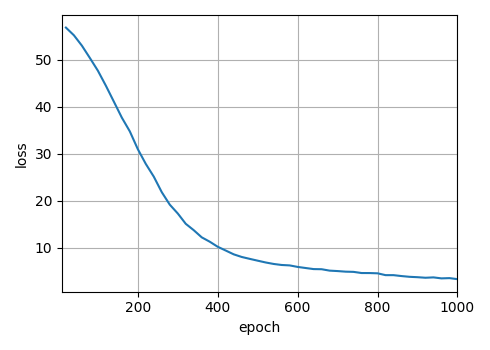
经过漫长的训练,最终损失降到了个位数,但是损失看不出来模型的好坏。在机器翻译中,常用的评价指标是BLEU得分。下篇文章就来学习下这个评价指标。
完整代码
https://github.com/nlp-greyfoss/metagrad
参考
Dive Into Deep Learning Speech and Language Processing
关注下方卡片《学姐带你玩AI》🚀🚀🚀
后台回复“500”
180+条AI必读论文讲解视频&代码数据集免费领
码字不易,欢迎大家点赞评论收藏!