导语
民间一直有个传闻......「听说某站的小哥哥小姐姐颜值都很高哦!」
(不是颜值高才能加入,是优秀的人恰好颜值高)
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。
木木子当然不负众望,今天就火速带你们走进某站,看看那些超高颜值的主播们的大比拼,谁
才是你心目中的第一呢?
深度解析的那些高颜值主播们。快看!满眼全是高颜值主播,爱了爱了鸭!

今天小编就用 Python实现人脸识别检测, 对某平台美女主播照片进行评分排名啦~看看那些主播
们,真的是高颜值主播嘛??

正文
本次文章主要内容:
一. 采集主播照片 二. 对于照片进行人脸识别检测, 进行打分 三. 评分排名。
人脸检测识别, 进行颜值评分 使用百度云API接口。
1. 注册一个百度云账号 2. 创建应用 --> 领取免费资源 3. 点击技术文档 4. Access Token获取一、环境准备
1)运行环境
开发环境:Python3、Pycharm社区版、requests、tqdm、部分自带的模块安装Python即可
使用。
相对应的安装包/安装教程/激活码/使用教程/学习资料/工具插件 可以直接找我厚台获取2)模块安装
第三方库的安装方式如下:
一般安装:pip install +模块名
镜像源安装:pip install -i https://pypi.douban.com/simple/+模块名(还有很多国内镜像源 这里是豆瓣的 用习惯了。其他的镜像源可以去看下之前的文章都有的)
模块安装问题可以详细的找我给大家讲一下的哈,之前其实也有的文章写了几个点的。
二、爬虫的基本思路
1)数据来源分析
1. 明确需求: 采集的网站是那个?采集的数据是那个? 主播照片/主播昵称。
2. 分析:主播照片/主播昵称 在什么地方可以获得。
通过开发者工具<浏览器自带工具>进行抓包<数据包>分析
打开开发者工具: F12 / 鼠标右键点击检查选择network1》定位找到单张图片url地址 。
2》通过图片url地址中, 一段参数, 去搜索查询所对应数据包 - 点击第二页 --> XHR --> 第一个
数据包, 通过搜索抓包分析得到的数据包:
https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&callback=getLiveListJso npCallback&page=2 包含主播昵称 / 照片三、代码实现步骤
1. 发送请求, 模拟浏览器对于url地址发送请求 。
请求链接: https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&callback=getLiveListJsonpCallback&page=22. 获取数据, 获取服务器返回响应数据 开发者工具: response 。
3. 解析数据, 提取我们想要的数据内容 照片url / 昵称 。
4. 保存数据, 把图片数据保存本地文件夹。
四、代码实现
主程序——
"""
# 导入数据请求模块 --> 第三方模块, 需要安装 pip install requests
import requests
import base64
import os
import time
from tqdm import tqdm
def score(file):
"""
定义函数
:param file: 文件路径
:return:
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=AK&client_secret=SK'
response = requests.get(host, headers=headers)
access_token = response.json()['access_token']
# 读取一张图片数据
img_content = open(file, mode='rb').read()
base_data = base64.b64encode(img_content)
request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
params = {
# 图片数据
"image": base_data,
"image_type": "BASE64",
"face_field": "beauty"
}
request_url = request_url + "?access_token=" + access_token
headers_1 = {'content-type': 'application/json'}
json_data = requests.post(request_url, data=params, headers=headers_1).json()
try:
num = json_data['result']['face_list'][0]['beauty']
return num
except:
return '识别失败'
info_list = []
# 对于所有照片进行颜值检测 --> 获取文件路径/文件名字
files = os.listdir('img\\')
print('正在做颜值评分, 请稍后.....')
for file in tqdm(files):
# 延时请求慢点
time.sleep(0.5)
# 完整的路径
filename = 'img\\' + file
# 切片
name = file[:-4]
result = score(file=filename)
if result != '识别失败':
dit = {
'主播': name,
'颜值': result
}
# 列表添加元素
info_list.append(dit)
info_list.sort(key=lambda x:x['颜值'], reverse=True)
i = 1
for info in info_list:
print(f'颜值排名第{i}的是{info["主播"]}, 颜值评分是{info["颜值"]}')
i += 1
# """
# 1. 发送请求, 模拟浏览器对于url地址发送请求
# 伪装模拟 --> headers 请求头
# 字典数据类型, 要构建完整键值对
# <Response [200]> 响应对象, 表示请求成功
# """
# # 请求链接
# url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=2'
# # 模拟浏览器
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
# }
# # 发送请求
# response = requests.get(url=url, headers=headers)
# """
# 2. 获取数据, 获取服务器返回响应数据
# 开发者工具: response
# - requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
# 原因: 获取数据不是完整json数据格式
# 解决:
# 1. 获取文本数据, 查看数据返回效果
# 2.
# - 通过正则表达式提取数据
# - 删掉 请求链接 里面参数 Callback
#
# 3. 解析数据, 提取我们想要的数据内容
# 照片url / 昵称
# response.json() --> 字典数据类型
# 根据键值对取值 --> 根据冒号左边的内容[键], 提取冒号右边的内容[值]
# """
# # for循环遍历, 一个一个提取列表里面元素
# for index in response.json()['data']['datas']:
# # 提取照片
# img_url = index['screenshot']
# # 提取昵称
# name = index['nick']
# print(name, img_url)
# """
# 4. 保存数据 --> 需要对图片链接发送请求, 获取二进制<图片>数据
# 'img\\'<文件夹> + name<文件名> + '.jpg'<文件格式>, mode='wb'<二进制保存>
# """
# # 获取图片二进制数据
# img_content = requests.get(url=img_url, headers=headers).content
# # 保存数据
# with open('img\\' + name + '.jpg', mode='wb') as f:
# f.write(img_content) 五、效果展示
五、效果展示
1)数据下载

2)保存数据
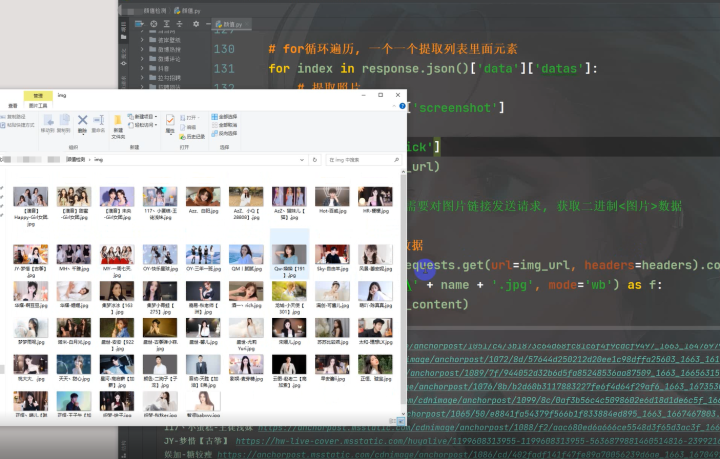
3)人脸检测
图片数据下载之后进行人脸检测排名,第一步调用api接口。
登录百度云账号——控制台——人脸识别。
下一步创建应用。
下一步实名免费领取,具体怎么使用可以去技术文档查看即可,不会的可以找我拿视频教程一
步一步来哈。
4)颜值排名
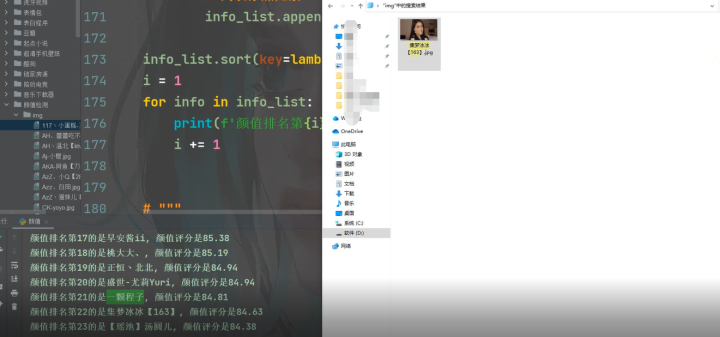
5)排名前三主播


总结
好啦,大家觉得排名前三的女主播颜值谁最好看呢?你能打多少分啦,这颜值是你的款蛮~
高颜值主播强势来袭,赶紧为你喜欢的高颜值小哥哥小姐姐打call吧。
今天的内容就写到这里正式结束啦,下一期我们再见,goodby!
🎯完整的免费源码领取处:找我吖!文末公众hao可自行领取,滴滴我也可!
🔨推荐往期文章——
项目1.8 Wifi破解免费
Python编程零基础如何逆袭成为爬虫实战高手之《WIFI破解》(甩万能钥匙十条街)爆赞爆赞~
项目1.9 爬虫+数据分析实战:全球疫情最新消息、淘宝爬虫、秒杀脚本
【Python合集系列】爬虫有什么用,网友纷纷给出自己的答案,王老师,我..我想学那个..爬虫。可以嘛?“(代码免费分享)
项目1.2 Python爬虫合集系列
【Python爬虫系列】为什么我喜欢python?来看看这些让人爱不释手的原因吧,购物网站大盘点,看过这些python做的项目,我立马入坑了…(神奇 | 爱了,爱了)
项目1.0 2.14 情人节快乐玫瑰合集
【Python表白代码】 2.14“Valentine‘s Day”“没别的意思 就是借着特殊日子说声喜欢你”你在哪儿?我去见你~(各种玫瑰源码合集)
🎄文章汇总——
汇总合集 Python—2022 |已有文章汇总 | 持续更新,直接看这篇就够了
(更多内容+源码都在✨文章汇总哦!!欢迎阅读喜欢的文章🎉~






![[python入门㊿] - python如何打断点](https://img-blog.csdnimg.cn/480466a9a71a40bca002d88a47dd6cd8.png)