1、Spark是什么?
类似与Hadoop的MapReduce的计算框架,基于map和reduce实现分布式计算,对比MapReduce可有效减少落盘次数,增加效率.
任务之间通信交互不需要落盘,仅在shuffle时需要重新将数据排序分区落盘.
Spark的缓存功能更加高效,特别是在SparkSQL中,一般是以列式存储形式存储在内存中
Spark中最基本的数据处理模型:RDD
Spark RDD
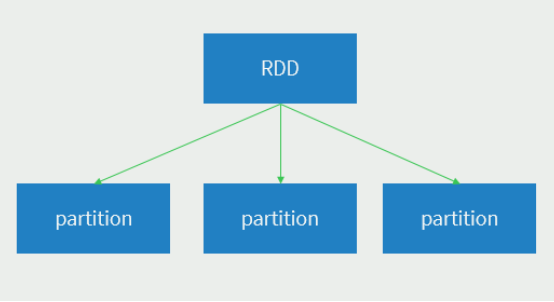
数据集: RDD封装了计算逻辑并不保存数据
分布式: 数据存储在大数据集群不同节点并由一个主节点进行控制
可分区并行计算: 可处理计算不同分区数据
Spark运行结构
数据转化成RDD,之后的计算逻辑存储于driver.
当遇到需要落盘,action的操作时,会将多个任务分发到executors.
其他非RDD的代码逻辑都在driver计算.

2、Spark的使用场景
2.1、Spark 模块

大数据分析统计,实时数据处理
2.2、Spark计算词的个数
File:[hello,word,hello,world blibli,hello,word]
读取文件转成RDD类型后可以直接操作文本内容:
file=spark.textfile(“文件路径”)
转换成RDD最基本的数据类型file.flatMap(_.split(“,”))
hello word hello world rrsp hello word.map(word=>(word,1))
(hello,1) (word,1) (hello,1) (world,1) (rrsp,1) (hello,1) (word,1).reduceByKey(_+_).foreach(println)
(hello,3) (word,3)(rrsp,1)(world,1)
易用性 => 编写简单,支持80种以上的高级算子,支持多种语言,数据源丰富,可部署在多种集群中
2.3、Spark Streaming
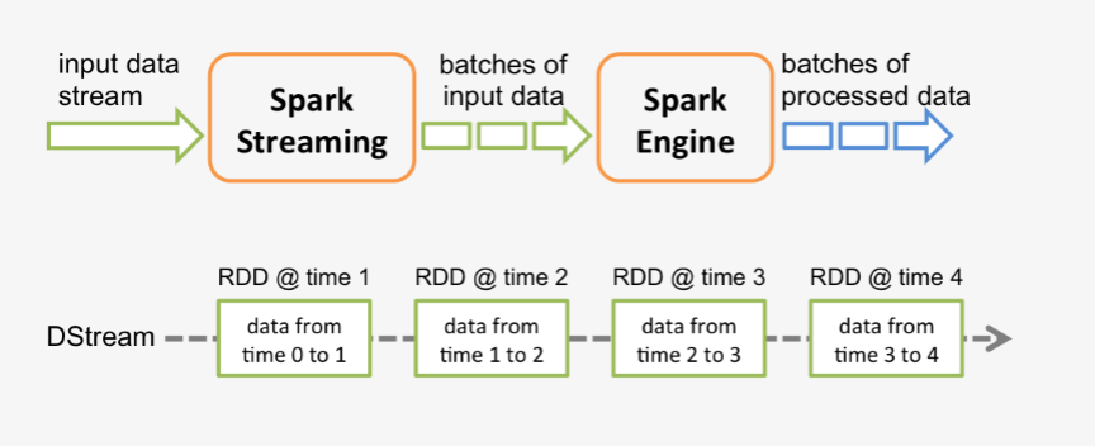
Spark Streaming处理乱序问题
Event time :事件发生的时间;
Processing time :处理事件数据的服务器时间
两种结果:
Spark Streaming 拉取到的一批数据,可能包含多个时间区间的数据;
一个 batch 中包含多个时间区间的数据, 加入我们的区间粒度是5分钟, 那么一个batch钟有可能包含 0~5 时间区间中的部分数据, 也有可能包含 5~10 时间区间中的部分数据, 这个很好处理,我们先对时间进行向下5分钟取整,然后使用取整后的时间分为多组, 然后计算出来指标.
同一个时间的数据可能出现在多个 batch 中.
需要在两个batch中计算出指标, 然后进行累计, 这个累计的过程, 你可以在内存中保存状态,把这个状态放在持久化存储中, 比如每次都在 redis, 或者 hbase 中进行累计.
3、Spark特点
● 快
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
● 易用(算法多)
MR只支持一种计算算法,Spark支持多种算法。Spark支持Java、Python、R和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的 shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
● 通用
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark 统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
● 兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用 Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
4、Spark的配置
spark.driver.memory 4g --Driver的内存
spark.executor.instances 20 --总的executors数
spark.executor.cores 2 --每个executor的核数
spark.executor.memory 6G --每个executor的内存
spark.reducer.maxSizeInFlight --每次能够拉取多少数据
5、Spark 的几种运行模式
1.local 本地模式(单机)–开发测试使用;分为local单线程和local-cluster多线程
2.standalone 独立集群模式–开发测试使用;典型的Mater/slave模式
3.standalone-HA 高可用模式–生产环境使用;基于standalone模式,使用zk搭建高可用,避免Master是有单点故障的
4.on yarn 集群模式–生产环境使用;运行在yarn集群之上,由yarn负责资源管理,Spark负责任务调度和计算,
好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
5.on mesos 集群模式–国内使用较少;运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算
6.on cloud 集群模式–中小公司未来会更多的使用云服务,比如AWS的EC2,使用这个模式能很方便的访问Amazon的S3