大家好,我是微学AI,今天给大家介绍一下LSTM网络,主要运用于解决序列问题。
一、LSTM网络简单介绍
LSTM又称为:长短期记忆网络,它是一种特殊的 RNN。LSTM网络主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。对于相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
引入LSTM网络的原因:由于 RNN 网络主要问题是长期依赖,即隐藏状态在时间上传递过程中可能会丢失之前的信息。为了解决这个问题,引入了长短时记忆网络 (LSTM) 和门控循环单元 (GRU)。这两种网络结构在隐藏层中增加了门控机制,能够更好地控制信息的传递。

其中符号及表示意思如下:
 LSTM中有三个门:
LSTM中有三个门:
(1)遗忘门f:决定上一个时刻的记忆单元状态需要遗忘多少信息,保留多少信息到当前记忆单元状态。
(2)输入门i:控制当前时刻输入信息候选状态有多少信息需要保存到当前记忆单元状态。
(3)输出门o:控制当前时刻的记忆单元状态有多少信息需要输出给外部状态。
形象的例子让我们更好的理解LSTM的原理:
假设你是一个梦想远大的学生,你想通过学习一门课程获得更多的知识。在学习过程中,LSTM模型帮助你,它就像是一个老师,它的遗忘门就像是老师的提醒,它让你挑出不用的知识,以保持你对重要知识的清晰记忆。它的输入门就像是老师的指导,它会重新审视你学习过的知识,按照自己的逻辑把知识结合起来,进化出更多有用的知识。最后,它的输出门就像老师的监督,它会确保你学习到了有用的知识,不要浪费时间去学习无用的知识。
二、LSTM网络运用-预测上证指数走势
# 使用LSTM预测沪市指数
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from pandas import DataFrame
from pandas import concat
from itertools import chain
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 转化为可以用于监督学习的数据
def get_train_set(data_set, timesteps_in, timesteps_out=1):
train_data_set = np.array(data_set)
reframed_train_data_set = np.array(series_to_supervised(train_data_set, timesteps_in, timesteps_out).values)
train_x, train_y = reframed_train_data_set[:, :-timesteps_out], reframed_train_data_set[:, -timesteps_out:]
# 将数据集重构为符合LSTM要求的数据格式,即 [样本数,时间步,特征]
train_x = train_x.reshape((train_x.shape[0], timesteps_in, 1))
return train_x, train_y
"""
将时间序列数据转换为适用于监督学习的数据
给定输入、输出序列的长度
data: 观察序列
n_in: 观测数据input(X)的步长,范围[1, len(data)], 默认为1
n_out: 观测数据output(y)的步长, 范围为[0, len(data)-1], 默认为1
dropnan: 是否删除NaN行
返回值:适用于监督学习的 DataFrame
"""
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
print(data.shape)
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]
# 预测序列 (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]
# 拼接到一起
agg = concat(cols, axis=1)
agg.columns = names
# 去掉NaN行
if dropnan:
agg.dropna(inplace=True)
return agg
# 使用LSTM进行预测
def lstm_model(source_data_set, train_x, label_y, input_epochs, input_batch_size, timesteps_out):
model = Sequential()
# 第一层, 隐藏层神经元节点个数为128, 返回整个序列
model.add(LSTM(128, return_sequences=True, activation='tanh', input_shape=(train_x.shape[1], train_x.shape[2])))
# 第二层,隐藏层神经元节点个数为128, 只返回序列最后一个输出
model.add(LSTM(128, return_sequences=False))
model.add(Dropout(0.5))
# 第三层 因为是回归问题所以使用linear
model.add(Dense(timesteps_out, activation='linear'))
model.compile(loss='mean_squared_error', optimizer='adam')
# LSTM训练 input_epochs次数
res = model.fit(train_x, label_y, epochs=input_epochs, batch_size=input_batch_size, verbose=2, shuffle=False)
# 模型预测
train_predict = model.predict(train_x)
#test_data_list = list(chain(*test_data))
train_predict_list = list(chain(*train_predict))
plt.plot(res.history['loss'], label='train')
plt.show()
#print(model.summary())
plot_img(source_data_set, train_predict)
# 呈现原始数据,训练结果,验证结果,预测结果
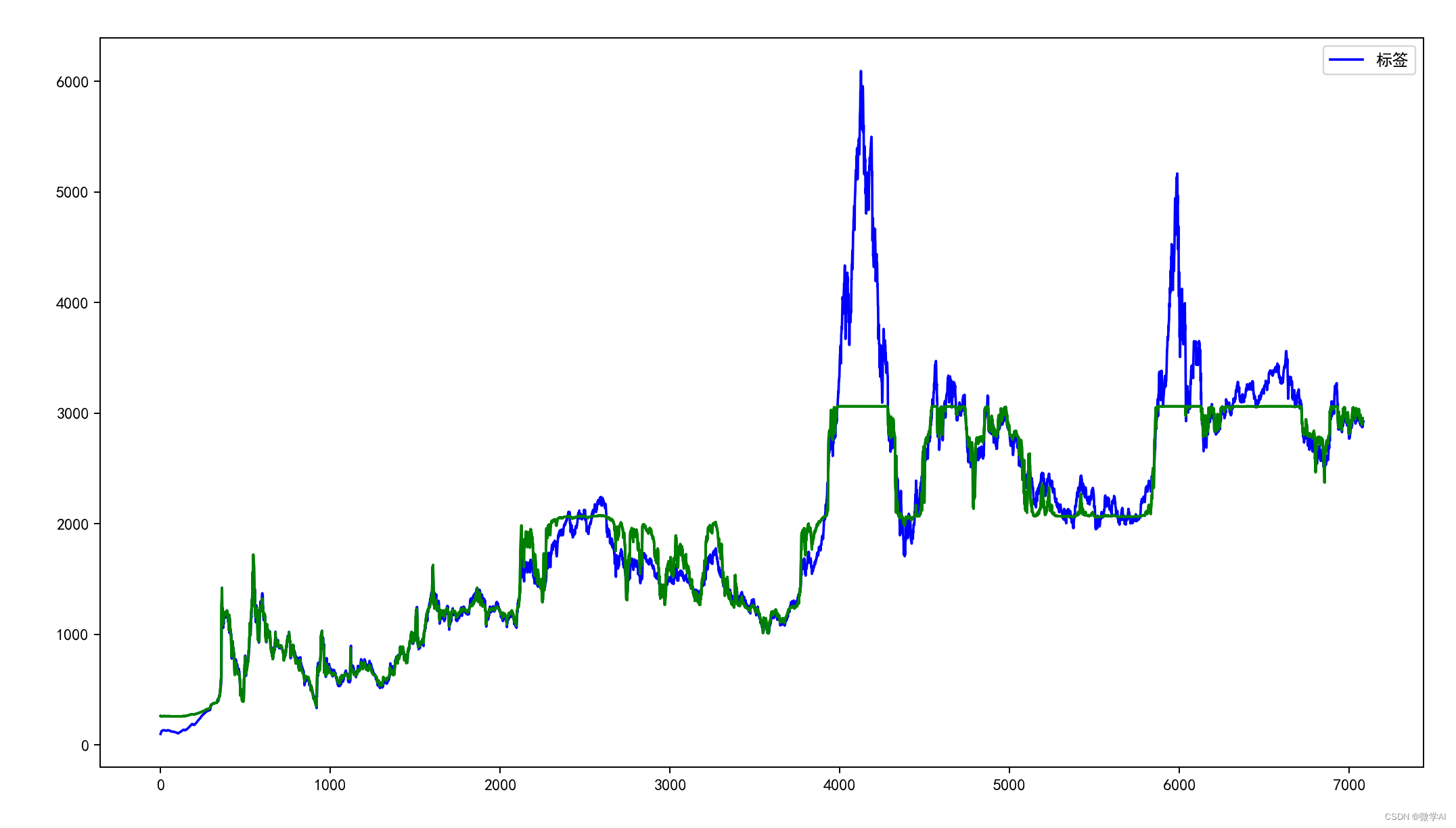
def plot_img(source_data_set, train_predict):
plt.figure(figsize=(24, 8))
# 原始数据蓝色
plt.plot(source_data_set[:, -1], c='b',label = '标签')
# 训练数据绿色
plt.plot([x for x in train_predict], c='g')
plt.legend()
plt.show()
# 设置观测数据input(X)的步长(时间步),epochs,batch_size
timesteps_in = 3
timesteps_out = 3
epochs = 1000
batch_size = 100
data = pd.read_csv('./shanghai_index_1990_12_19_to_2019_12_11.csv')
data_set = data[['Price']].values.astype('float64')
# 转化为可以用于监督学习的数据
train_x, label_y = get_train_set(data_set, timesteps_in=timesteps_in, timesteps_out=timesteps_out)
print(train_x, label_y )
print(train_x.shape)
print(train_x.shape[1], train_x.shape[2])
# 使用LSTM进行训练、预测
lstm_model(data_set, train_x, label_y, epochs, batch_size, timesteps_out=timesteps_out)运行结果: