文章目录
- 1.自定义排序方法
- 2.常用作自定义排序的函数、方法
- 3.列表、元组、字符串自定义排序方法
- 3.1.当列表、元组中元素为字符串的排序规则
- 3.2.三者采用str.lower方法实现自定义排序
- 3.2.三者采用len函数实现自定义排序
1.自定义排序方法
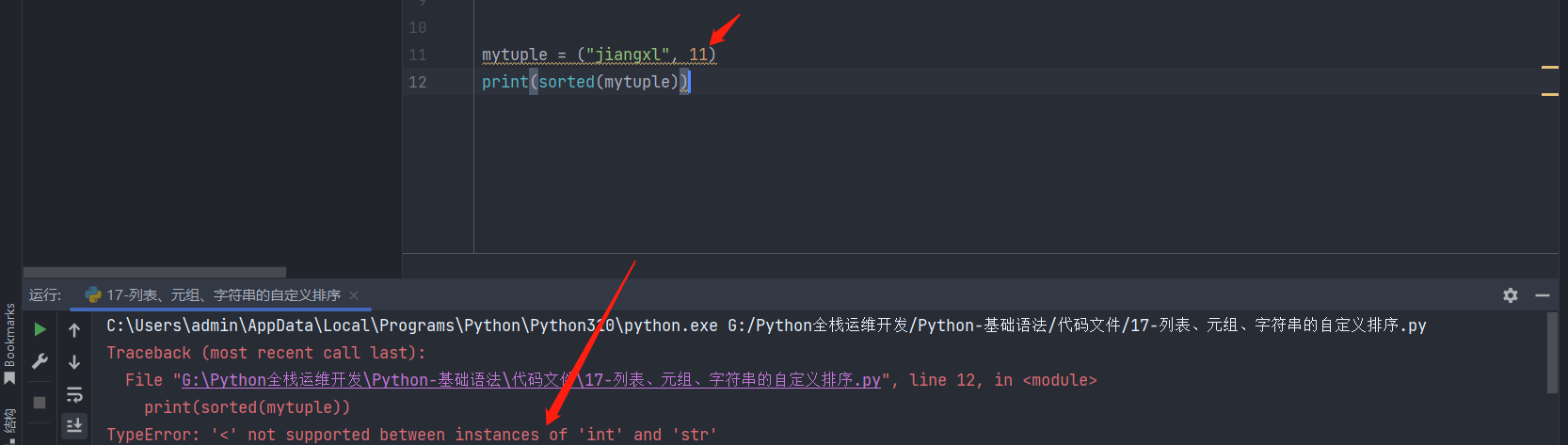
列表、元组、字符串都可以进行排序,列表和元组进行排序时,如果有元素是字符串时,列表、元组中的所有元素都需要用引号引起来,例如:mytuple = ("jiangxl", "11"),否则将会抛出错误,如下所示,调用sorted函数排序时,不明确要对字符串排序还是数字排序,从而就会抛出异常,如果都加上引号了,sorted函数就认为是对字符串进行排序。
在前面我们使用的都是sorted函数默认的排序规则,在调用sorted函数时,还可以指定参数key = 函数名 或者 key = 类名.方法名指定某个函数或者是类中的方法,然后分别调用指定的函数或者方法对字符串中的所有字符、列表元组中的所有元素进行计算,然后根据函数或者方法的返回值进行排序,排序完成后再逆推出原始字符,从而实现自定义的排序规则。
如下图所示,这是字符串排序过程中,调用sorted函数时指定了
key = str.lower参数,str是字符串的类,lower是str类中的函数,在类中的函数就被称为方法,调用sorted函数时指定了参数key,就相当于自定义排序方法了,根据指定的函数或者方法对字符串中的所有字符、列表元组中的所有元素进行计算,将返回的结果再进行排序,最后再根据排序的返回值逆推出原始值。看下图,字符串
DBeFac在排序过程中,调用sorted函数时指定了key = str.lower参数,此时字符串中的所有字符都会使用str.lower这个方法进行的处理并得到一个返回值dbefac,然后根据str.lower方法得到的返回值进行排序,排序完成后还需要根据返回值逆推出实际原始值,也就是通过str.lower方法处理之前的原始值,最后将排序输出到控制台。

简单来说,自定义排序就是在调用sorted函数时指定参数key,在key中声明一个函数或者方法,然后通过这个函数对字符串、列表、元组中的每个元素进行处理并得到一个返回值,然后对这个返回值进行排序,排序后再逆推出返回值的原始值,最终将排序结果输出到屏幕。
2.常用作自定义排序的函数、方法
在自定义排序时常用的函数或者方法有:
str.lower方法- 在上面讲解自定义排序方法实,图中的案例在调用sorted函数时指定参数
key = str.lower,str.lower方法是将指定的字符转换成小写字母,后续进行排序时,就是对转换后的小写字母的ordinal value值进行比较排序。
- 在上面讲解自定义排序方法实,图中的案例在调用sorted函数时指定参数
len函数len函数主要在列表、元组自定义排序时使用,通过len函数可以计算一个字符串的长度,我们可以通过len函数计算出一个元素的长度,然后根据元素的长度进行排序。
1)str.lower方法的使用
print(str.lower("ABCefDj"))
#输出结果:abcefdj
2)len函数的使用
print(len("ABCefDj"))
#输出结果:7
3.列表、元组、字符串自定义排序方法
3.1.当列表、元组中元素为字符串的排序规则
字符的排序是根据其ordinal value值作为依据的,字符的ordinal value值是一个整数,排序的默认情况下是从 小到大。
当列表的元素都是字符串时,按照字符串排序有一定的复杂性,但是也不难,过程分为如下几步:
- 首先将列表中的字符串元素看成是一个子串,子串的特性是依据子串中的第一个字符,但是字符串元素又不会只依据第一个字符,和字符串比较很相似,可以结合着学习。
- 排序过程中会根据每个元素中字符串的第一个字符的ordinal value值进行排序,如果多个字符串的第一个字符的ordinal value值相同,相当于并列了,但是也要分出个高低,此时就会根据字符串中第二个字符的ordinal value值进行排序,只要分出个大于小,然后根据从小到的顺序进行排序。
主要是理解列表中元素全都是字符串时,它的一个排序规则,当然只要是进行列表的排序,要么纯数字,要么纯字符串,如果纯数字那么就很好排序的,只要涉及到了字符串,无论列表中的元素是字符串还是数字,数字也会被看成字符串,数字也有对应的ordinal value值,此时都需要依据字符串中字符的ordinal value值进行排序,首先比较字符串中第一个字符的ordinal value值,如果字符串与字符串之间的第一个字符ordinal value值相等,那么就看第二个字符的ordinal value值,直到比较出谁大谁小,最后按照从小到大的顺序排序。
采用str.lower方法自定义排序,排序的规则还是一样的,只不过使用str.lower方法后,会对原始的字符串进行处理,处理之后的排序顺序又是另外一个样子,因为str.lower方法会将大写的字符转换成小的字符,小写字符的ordinal value值要比大写字符的ordinal value值大,从而肯定会和不加str.lower方法的默认排序结果有所不同。
如下图所示,有一个列表:
["jiangxl", "Book", "baidu", "csdn", "123", "67896"],要使用自定义排序规则,方法是str.lower,首先会通过str.lower方法将列表中大写字母的字符全部转换成小写,如图中第二层所示,Book被转换成小写的book,转换之后该元素的排序就发生了很大的变量,因为其的第一个字符的ordinal value值也随之增大了。字符由大写转换成小写,就是str.lower方法处理的结果,然后按照这个返回结果去排序,每个字符串取第一个字符的ordinal value值进行比较与排序,book和baidu元素的第一个字符都相同,那么就按照第二个字符的ordinal value值进行比较,ordinal value值是数字,得到每个元素对应的ordinal value值之后,就可以进行排序了。
按照ordinal value值排序完之后,结果就是下图中的第四层,这些字符串还是str.lower方法的返回值,还需要通过逆推将其转换成原始字符串,最终的排序结果就如下图中的第五层所示。
接下来我们会去实现这个排序。另外元组中的元素是字符串时,也是这种排序规则,并且如果也用str.lower自定义排序,过程也是如上所示,没有任何区别。

本小结只是说了列表和元素中字符串的排序规则,那么字符串中的字符是如何排序的?前面已经讲过了,这里在重复一遍,字符串中的每个字符的个数拥有都是1个,只要根据其的ordinal value值进行排序即可。
3.2.三者采用str.lower方法实现自定义排序
1)列表采用str.lower方法实现自定义排序
#列表采用str.lower函数实现自定义排序
#升序
mylist = ["jiangxl", "Book", "baidu", "csdn", "123", "67896"]
print(sorted(mylist, key=str.lower))
#输出结果:['123', '67896', 'baidu', 'Book', 'csdn', 'jiangxl'] 排序过程已在上面详细讲了
#降序
print(sorted(mylist, key=str, reverse=True))
#输出结果:['jiangxl', 'csdn', 'baidu', 'Book', '67896', '123']
也可以参照下图每个元素的字符ordinal value值,去分析谁应该在前,谁应该在后。

2)元素采用str.lower方法实现自定义排序
效果和列表一样。
#元组采用str.lower函数实现自定义排序
#升序
mytuple = ("Jiangxl", "Kubernetes", "Jenkins")
print(sorted(mytuple, key=str.lower))
#输出结果:['Jenkins', 'Jiangxl', 'Kubernetes']
#降序
print(sorted(mytuple, key=str.lower, reverse=True))
#输出结果:['Kubernetes', 'Jiangxl', 'Jenkins']
3)字符串采用str.lower方法实现自定义排序
字符串中每个字符的个数都是一个,直接根据这个字符的ordinal value值进行排序。
#字符串采用str.lower函数实现自定义排序
#升序
mystr = "jiangxl"
print(sorted(mystr, key=str.lower))
#输出结果:['a', 'g', 'i', 'j', 'l', 'n', 'x']
#降序
print(sorted(mystr, key=str.lower, reverse=True))
#输出结果:['x', 'n', 'l', 'j', 'i', 'g', 'a']
列表、元组、字符串通过str.lower方法排序的结果。

3.2.三者采用len函数实现自定义排序
首先根据len函数计算出每个元素的长度,然后根据返回的值进行排序,返回值都是一个整数,默认从小到大排序,排序完成后在按照逆推的方法获取原始字符串,最终输出控制台。

1)列表采用len函数实现自定义排序
#列表采用len函数实现自定义排序
#升序
mylist = ["jiangxl", "Book", "baidu", "csdn", "123", "67896"]
print(sorted(mylist, key = len))
#输出结果:['123', 'Book', 'csdn', 'baidu', '67896', 'jiangxl']
'''
jiangxl元素通过len计算出的长度为7,Book元素的长度为4,baidu元素的长度为5,csdn元素的长度为4,123元素的长度为3,67896元素的长度为5
从小到大依次是 3 4 4 5 5 7
逆推回的原始值就是 ['123', 'Book', 'csdn', 'baidu', '67896', 'jiangxl']
'''
#降序
print(sorted(mylist, key=len, reverse=True))
#输出结果:['jiangxl', 'baidu', '67896', 'Book', 'csdn', '123']

2)元组采用len函数实现自定义排序
#元组采用len函数实现自定义排序
#升序
mytuple = ("Jiangxl", "Kubernetes", "Jenkins")
print(sorted(mytuple, key=len))
#输出结果:['Jiangxl', 'Jenkins', 'Kubernetes']
#降序
print(sorted(mytuple, key=len, reverse=True))
#输出结果;['Kubernetes', 'Jiangxl', 'Jenkins']

3)字符串采用len函数实现自定义排序
字符串使用len函数排序的意义不大,因为字符串中的每个字符长度都为1,如下所示。
mystr = "jiangxl"
print(sorted(mystr, key=len))
print(sorted(mystr, key=len, reverse=True))
#输出结果:['j', 'i', 'a', 'n', 'g', 'x', 'l']
#意义不大,将每个字符按照书序一次列了出来,无论升序还是倒序,顺序都不变。