内容概要
- 诊断工具介绍
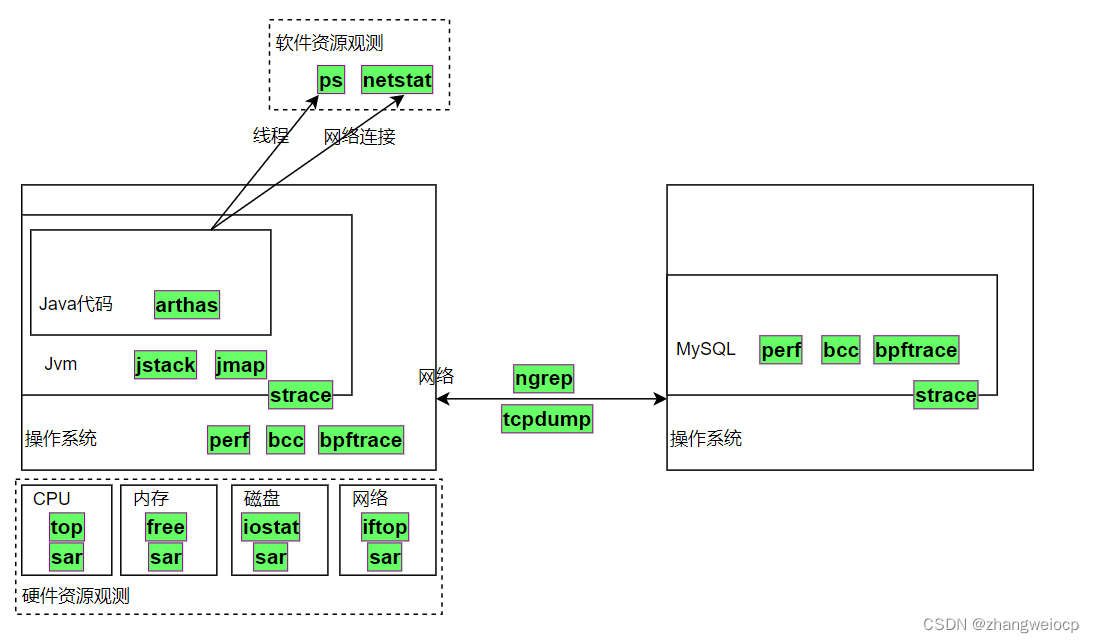
- 工具可用情况
- 偶现或已现问题诊断思路
硬件资源观测
top
top可以看整个系统cpu、内存的使用情况,以及在各个进程上的情况,如下:
$ top
top - 13:14:07 up 2 days, 6:38, 0 users, load average: 1.65, 0.59, 0.27
Tasks: 17 total, 3 running, 14 sleeping, 0 stopped, 0 zombie
%Cpu(s): 25.0 us, 0.0 sy, 0.0 ni, 74.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 12693.4 total, 12052.8 free, 271.6 used, 368.9 buff/cache
MiB Swap: 4096.0 total, 4096.0 free, 0.0 used. 12171.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3174 work 20 0 3860 104 0 R 100.0 0.0 1:40.75 stress
3175 work 20 0 3860 104 0 R 100.0 0.0 1:40.76 stress
1 root 20 0 900 492 428 S 0.0 0.0 0:00.11 init
10 work 20 0 10044 5140 3424 S 0.0 0.0 0:00.12 bash
3051 work 20 0 6393208 204364 20116 S 0.0 1.6 0:07.51 java
3173 work 20 0 3860 980 896 S 0.0 0.0 0:00.00 stress
3176 work 20 0 10888 3932 3348 R 0.0 0.0 0:00.02 top- 第一行是系统概要:当前时间,系统启动时长,系统用户数,系统负载1min/5min/15min
- 第二行是任务概要:总任务数,正在运行/睡眠/暂停/僵尸任务数
- 第三行cpu使用率:
us:非niced进程花费的cpu时间占比
sy:内核进程花费的cpu时间占比
ni:niced进程花费的cpu时间占比
id:内核空闲进程花费的cpu时间占比,一般来说CPU是无法空闲的,CPU空闲着,指的是在运行一个空闲程序的代码。
wa:等待磁盘io完成花费的cpu时间占比
hi:处理硬件中断花费的cpu时间占比
si:处理软件中断花费的cpu时间占比
st:被其它虚拟机偷取的cpu时间占比
- 第四行是内存使用率:
total:总内存大小(MB)
free:空闲内存大小(MB)
used:使用中的内存大小(MB)
buff/cache:用于文件缓存与系统缓存的内存大小(MB)
- 第五行是swap情况:
total:总swap文件大小
free:swap空闲大小
used:swap使用大小
avail Mem:可用内存大小,和swap无关,约等于上一行中free+buff/cache
下面的列表显示的就是各进程情况了,除此之外,top还是个交互式命令,可直接在这个界面输入指令使用其更多功能,如下:
| 指令 | 功能描述 |
| 1 | 查看1号cpu各核的cpu使用情况,类似mpstat |
| M | 进程按内存使用率倒序,同时按shift + m |
| P | 进程按cpu使用率倒序,同时按shift + p |
| H | 查看线程情况,同时按shift + h |
| c | 查看进程的完整命令行 |
| k | 杀死指定pid的进程 |
| h | 查看帮助 |
| q | 退出top |
注意,这里面的指令,很多都是开关式的,比如按1显示cpu各核使用率,再按1就显示整体cpu使用率了。
另外,如果你的电脑是8核的,top中进程的CPU%最高可以到800%,初次看到这种现象时,还很容易吓一跳呢!
iostat
iostat命令可以很方便的查看磁盘当前的IO情况,如下:
$ iostat -xz 1
avg-cpu: %user %nice %system %iowait %steal %idle
0.06 0.00 0.00 0.00 0.00 99.94
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 1.87 17854.96 3799.10 14930.26 42642.19 208548.03 26.82 7.10 0.37 1.04 0.20 0.28 522.73
avg-cpu: %user %nice %system %iowait %steal %idle
4.36 0.00 0.00 0.00 0.00 95.64
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 606.00 0.00 2616.00 8.63 0.04 0.06 0.00 0.06 0.06 3.40注意,和vmstat一样,第一次的输出结果是历史以来的统计值,一般可以忽略不计,如下:
- %util :磁盘使用率,Linux认为磁盘只能处理一个并发,但SSD或raid实际可以超过一个,所以100%也不一定代表满载。
- avgqu-sz:磁盘任务队列长度,大于磁盘的并发任务数则磁盘处于饱和状态。
- svctm:平均服务时间,不包括在磁盘队列中的等待时间。
- r_await,w_await:读写延迟时间(ms),磁盘队列等待时间+svctm,太大则磁盘饱和。
- r/s + w/s: 就是当前的IOPS。
- avgrq-sz:就是当前每秒平均吞吐量 单位是扇区(512b)。
iotop
iotop以进程的角度查看io情况,如下:
# -P表示只看进程整体的,不然iotop看的是每个线程的
# -o表示只看有io操作的进程,不然iotop会列出所有进程
$ sudo iotop -P -o
Total DISK READ: 3.84 K/s | Total DISK WRITE: 138.97 M/s
Current DISK READ: 3.84 K/s | Current DISK WRITE: 80.63 M/s
PID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
737183 be/4 root 3.84 K/s 0.00 B/s 0.00 % 88.89 % [kworker/u256:1+flush-8:0]
761496 be/4 work 0.00 B/s 138.96 M/s 0.00 % 79.09 % stress -d 1
876 be/4 work 0.00 B/s 7.68 K/s 0.00 % 0.00 % java -Xms256m -Xmx1g -Xss1m -XX:MaxMetaspaceSize=1g ...可以看到整个磁盘的当前读写速率,以及各个进程占用的比例。
iftop
iftop可以用来查看整个网卡以及各个连接的当前网速,如下:
$ sudo iftop -B -nNP
244KB 488KB 732KB 977KB 1.19MB
└──────────────────────────────┴──────────────────────────────┴───────────────────────────────┴──────────────────────────────┴───────────────────────────────
100.135.65.10:11111 => 100.135.95.10:29518 85.8KB 103KB 94.3KB
<= 2.95KB 3.54KB 3.25KB
100.135.65.10:11111 => 100.135.95.9:35981 170KB 103KB 94.3KB
<= 5.41KB 3.49KB 3.21KB
100.135.60.10:35172 => 100.135.24.54:3561 13.3KB 9.88KB 5.25KB
<= 58.6KB 60.6KB 32.4KB
100.134.60.10:43240 => 100.134.24.55:3560 9.83KB 5.52KB 3.09KB
<= 101KB 53.6KB 31.1KB
100.134.60.10:65932 => 100.154.24.55:3951 4.45KB 5.07KB 6.04KB
<= 35.0KB 39.8KB 47.4KB
10.134.60.10:58990 => 10.134.24.5:80 22.0KB 19.2KB 22.5KB
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
TX: cum: 10.9MB peak: 1.75MB rates: 611KB 438KB 557KB
RX: 6.49MB 453KB 360KB 296KB 332KB
TOTAL: 17.4MB 2.19MB 972KB 735KB 889KB另外,在nicstat、iftop命令不可用的情况下,也可以使用ifconfig + awk来查看网速,单位B/s,如下:
$ while sleep 1;do ifconfig;done|awk -v RS= 'match($0,/^(\w+):.*RX.*bytes ([0-9]+).*TX.*bytes ([0-9]+)/,a){eth=a[1];if(s[eth][1])print a[1],a[2]-s[eth][2],a[3]-s[eth][3];for(k in a)s[eth][k]=a[k]}'
eth0 294873 353037
lo 2229 2229
eth0 613730 666086
lo 17981 17981
eth0 317336 544921
lo 5544 5544
eth0 237694 516947
lo 2256 2256全能观测工具
sar
sar是一个几乎全能的观测工具,它可以观测CPU、内存、磁盘、网络等等,不像上面的命令,只是侧重某一方面,正因为它如此强大,掌握起来也要难得多,它的常见用法如下:
# cpu使用率
sar -u ALL 1
# 运行队列与负载
sar -q 1
# 中断次数
sar -I SUM 1
# 进程创建次数与线程上下文切换次数
sar -w 1
# 内存使用、脏页与slab
sar -r ALL 1
# 缺页与内存页扫描
sar -B 1
# 内存swap使用
sar -S 1 1
sar -W 1
# 磁盘IOPS
sar -dp 1
# 文件描述符与打开终端数
sar -v 1 1
# 网卡层使用率
sar -n DEV 1
# tcp层收包发包情况
sar -n TCP,ETCP 1
# socket使用情况
sar -n SOCK 1这只是列出了sar的一部分用法,实际上sar可以观测到非常多的内容,具体可以man sar查看。
dstat
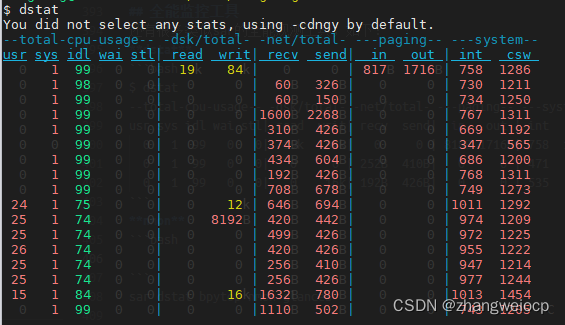
bpytop
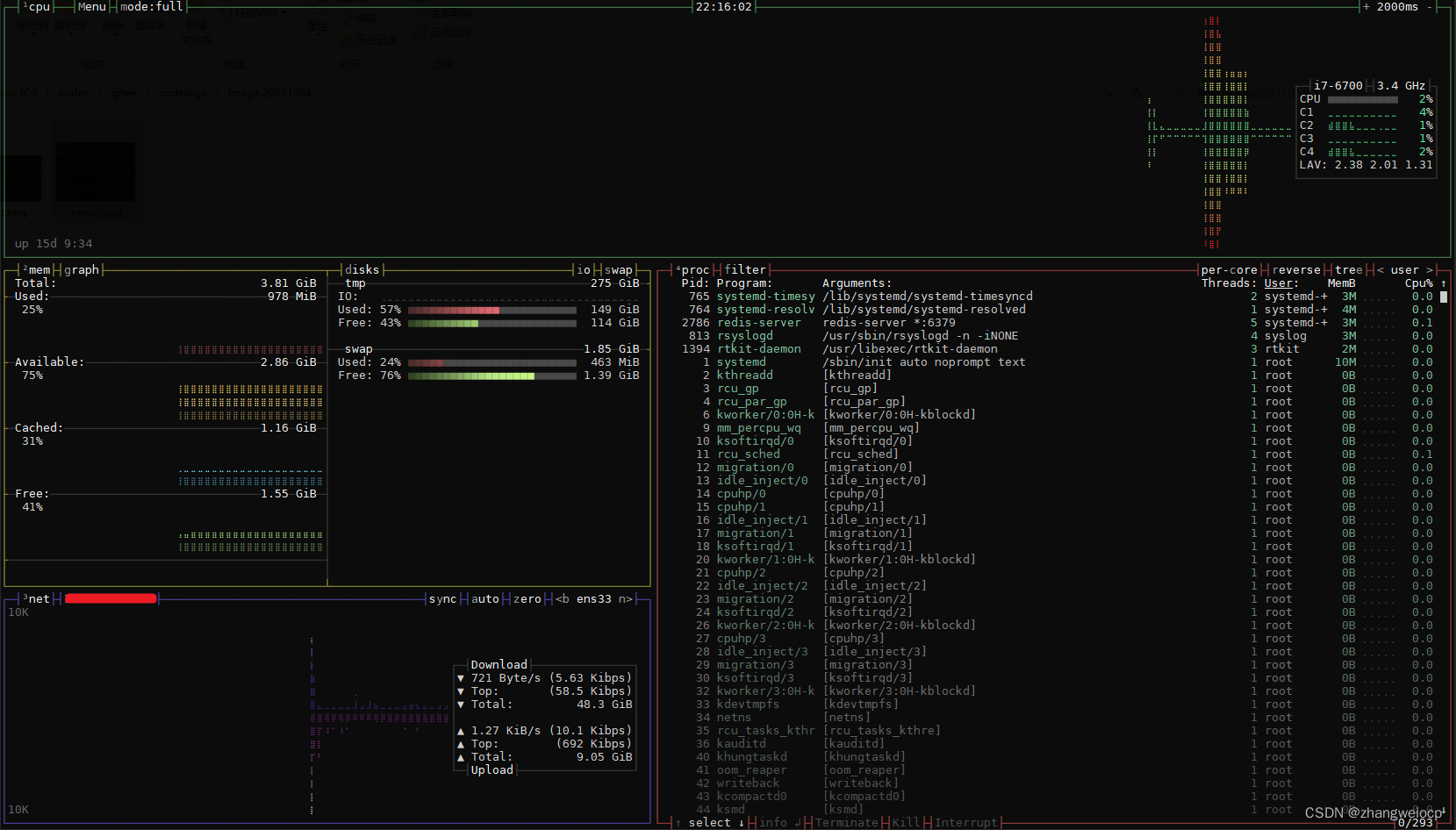
软件资源观测
线程
# 查看各java进程的线程数量
$ ps -o pid,nlwp -C java
PID NLWP
2121 21
# 查看java各线程CPU、内存使用情况
$ top -H -p `pgrep -n java`网络连接
netstat是用来查看网络连接信息的工具命令,具体来说,像在编程语言中可以通过创建socket来建立网络连接,而netstat就是用来查看这些socket信息的,如下:
# 查看所有的socket,-n代表不解析ip为主机名,-a表示all所有,-t代表tcp
$ netstat -nat
# 显示各状态socket数量,TIME_WAIT与CLOSE_WAIT数量太多,一般都不是好事情
$ netstat -nat | awk '/tcp/{print $6}'|sort|uniq -c
21 ESTABLISHED
3 TIME_WAIT
3 CLOSE_WAIT
2 LISTEN
# 查看LISTEN状态的socket,-l代表只显示LISTEN状态的
$ netstat -nlt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:8888 0.0.0.0:* LISTEN
tcp6 0 0 :::8888 :::* LISTEN
# 查看进程867的socket数量,-p显示出创建网络连接的进程号
$ netstat -natp|grep -w 867 -c
2
# 找到监听在8888端口的进程
$ netstat -nltp|grep -w 8888
tcp 0 0 0.0.0.0:8888 0.0.0.0:* LISTEN 867/ncat
tcp6 0 0 :::8888 :::* LISTEN 867/ncatjvm观测工具
jstack
jstack是JVM下的线程剖析工具,可以打印出当前时刻各线程的调用栈,这样就可以了解到jvm中各线程都在干什么了,如下:
$ jstack 3051
2021-11-07 21:55:06
Full thread dump OpenJDK 64-Bit Server VM (11.0.12+7 mixed mode):
Threads class SMR info:
_java_thread_list=0x00007f3380001f00, length=10, elements={
0x00007f33cc027800, 0x00007f33cc22f800, 0x00007f33cc233800, 0x00007f33cc24b800,
0x00007f33cc24d800, 0x00007f33cc24f800, 0x00007f33cc251800, 0x00007f33cc253800,
0x00007f33cc303000, 0x00007f3380001000
}
"main" 1 prio=5 os_prio=0 cpu=2188.06ms elapsed=1240974.04s tid=0x00007f33cc027800 nid=0xbec runnable [0x00007f33d1b68000]
java.lang.Thread.State: RUNNABLE
at java.io.FileInputStream.readBytes(java.base@11.0.12/Native Method)
at java.io.FileInputStream.read(java.base@11.0.12/FileInputStream.java:279)
at java.io.BufferedInputStream.read1(java.base@11.0.12/BufferedInputStream.java:290)
at java.io.BufferedInputStream.read(java.base@11.0.12/BufferedInputStream.java:351)
- locked <0x00000007423a5ba8> (a java.io.BufferedInputStream)
at sun.nio.cs.StreamDecoder.readBytes(java.base@11.0.12/StreamDecoder.java:284)
at sun.nio.cs.StreamDecoder.implRead(java.base@11.0.12/StreamDecoder.java:326)
at sun.nio.cs.StreamDecoder.read(java.base@11.0.12/StreamDecoder.java:178)
- locked <0x0000000745ad1cf0> (a java.io.InputStreamReader)
at java.io.InputStreamReader.read(java.base@11.0.12/InputStreamReader.java:181)
at java.io.Reader.read(java.base@11.0.12/Reader.java:189)
at java.util.Scanner.readInput(java.base@11.0.12/Scanner.java:882)
at java.util.Scanner.findWithinHorizon(java.base@11.0.12/Scanner.java:1796)
at java.util.Scanner.nextLine(java.base@11.0.12/Scanner.java:1649)
at com.example.clientserver.ClientServerApplication.getDemo(ClientServerApplication.java:57)
at com.example.clientserver.ClientServerApplication.run(ClientServerApplication.java:40)
at org.springframework.boot.SpringApplication.callRunner(SpringApplication.java:804)
at org.springframework.boot.SpringApplication.callRunners(SpringApplication.java:788)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:333)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1309)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1298)
at com.example.clientserver.ClientServerApplication.main(ClientServerApplication.java:27)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(java.base@11.0.12/Native Method)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke(java.base@11.0.12/NativeMethodAccessorImpl.java:62)
at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(java.base@11.0.12/DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(java.base@11.0.12/Method.java:566)
at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:49)
at org.springframework.boot.loader.Launcher.launch(Launcher.java:107)
at org.springframework.boot.loader.Launcher.launch(Launcher.java:58)
at org.springframework.boot.loader.JarLauncher.main(JarLauncher.java:88)
"Reference Handler" 2 daemon prio=10 os_prio=0 cpu=2.76ms elapsed=1240973.97s tid=0x00007f33cc22f800 nid=0xbf3 waiting on condition [0x00007f33a820a000]
java.lang.Thread.State: RUNNABLE
at java.lang.ref.Reference.waitForReferencePendingList(java.base@11.0.12/Native Method)
at java.lang.ref.Reference.processPendingReferences(java.base@11.0.12/Reference.java:241)
at java.lang.ref.Reference$ReferenceHandler.run(java.base@11.0.12/Reference.java:213)实例:找占用CPU较高问题代码
如果你发现你的java进程CPU占用一直都很高,可以用如下方法找到问题代码:
1,找出占用cpu的线程号pid
# -H表示看线程,其中312是java进程的pid
$ top -H -p 3122,转换线程号为16进制
# 其中62是从top中获取的高cpu的线程pid
$ printf "%x" 314
13a3,获取进程中所有线程栈,提取对应高cpu线程栈
$ jstack 312 | awk -v RS= '/0x13a/'通过这种方法,可以很容易找到类似大循环或死循环之类性能极差的代码。
实例:栈统计
一般来说,jstack配合top只能定位类似死循环这种非常严重的性能问题,由于cpu速度太快了,对于性能稍差但又不非常差的代码,单次jstack很难从线程栈中捕捉到问题代码。
因为性能稍差的代码可能只会比好代码多耗1ms的cpu时间,但这1ms就比我们的手速快多了,当执行jstack时线程早已执行到非问题代码了。
既然手动执行jstack不行,那就让脚本来,快速执行jstack多次,虽然问题代码对于人来说执行太快,但对于正常代码来说,它还是慢一些的,因此当我快速捕捉多次线程栈时,问题代码出现的次数肯定比正常代码出现的次数要多。
# 每0.2s执行一次jstack,并将线程栈数据保存到jstacklog.log
$ while sleep 0.2;do \
pid=$(pgrep -n java); \
[[ $pid ]] && jstack $pid; \
done > jstacklog.log
$ wc -l jstacklog.log
291121 jstacklog.log抓了这么多线程栈,如何分析呢?我们可以使用linux中的文本命令来处理,按线程栈分组计数即可,如下:
$ cat jstacklog.log \
|sed -E -e 's/0x[0-9a-z]+/0x00/g' -e '/^"/ s/[0-9]+/n/g' \
|awk -v RS="" 'gsub(/\n/,"\\n",$0)||1' \
|sort|uniq -c|sort -nr \
|sed 's/$/\n/;s/\\n/\n/g' \
|less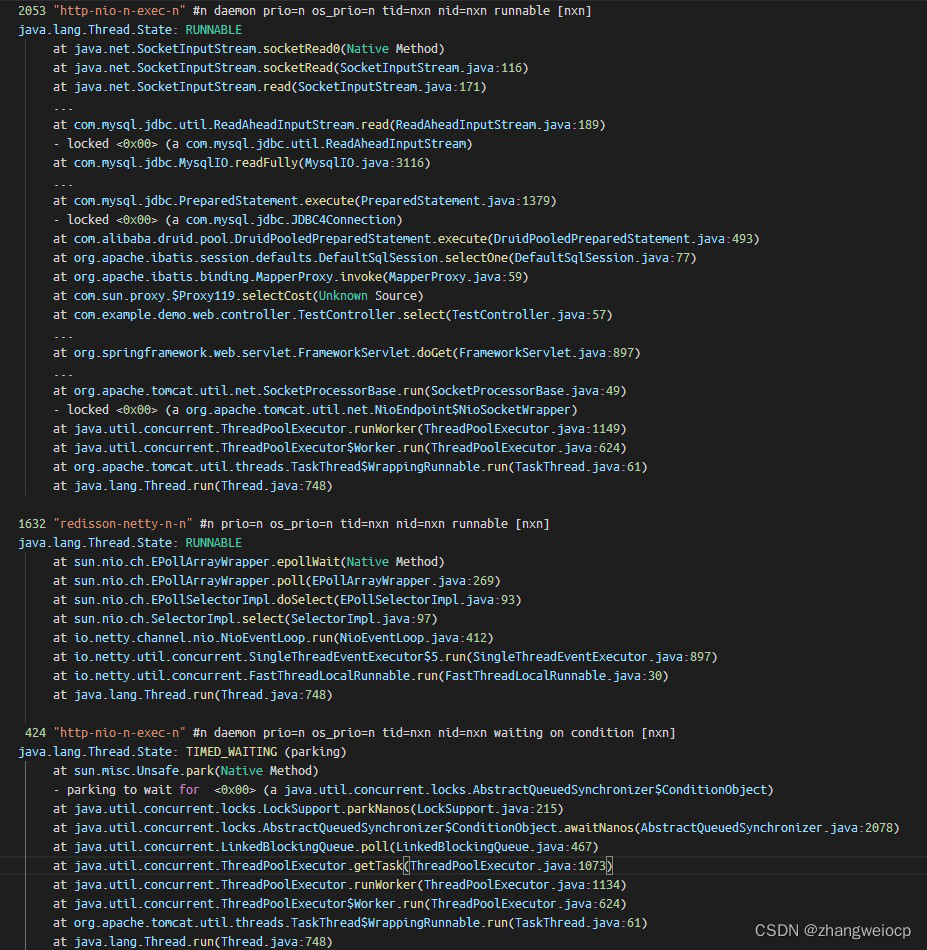
出现次数最多的线程栈,大概率就是性能不佳或阻塞住的代码,上图中com.example.demo.web.controller.TestController.select方法栈抓取到2053次,是因为我一直在压测这一个接口,所以它被抓出来最多。
实例:火焰图
可以发现,用文本命令分析线程栈并不直观,好在性能优化大师Brendan Gregg发明了火焰图,并开发了一套火焰图生成工具。
工具下载地址:https://github.com/brendangregg/FlameGraph
将jstack抓取的一批线程栈,生成一个火焰图,如下:
$ cat jstacklog.log \
| ./FlameGraph/stackcollapse-jstack.pl --no-include-tname \
| ./FlameGraph/flamegraph.pl --cp > jstacklog.svg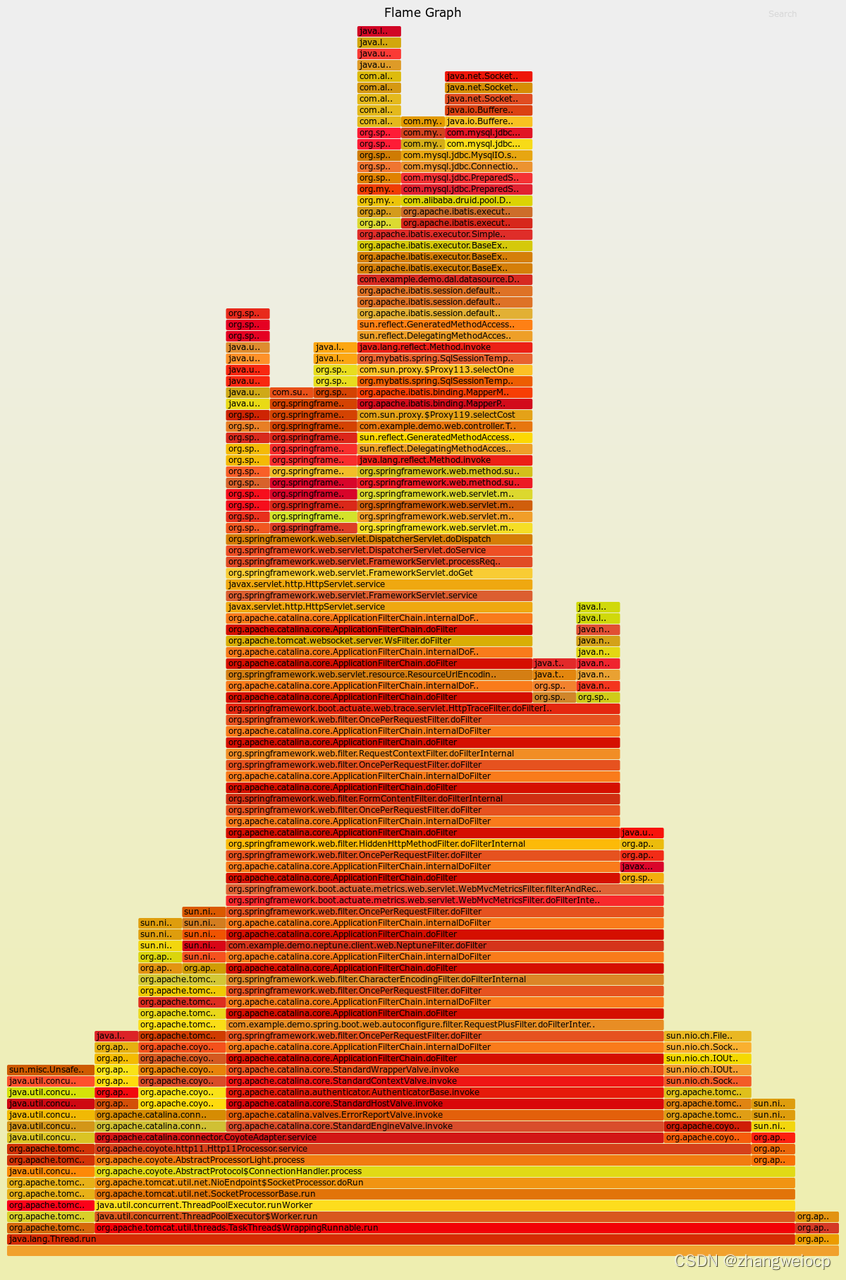
如上,生成的火焰图是svg文件,使用浏览器打开即可,在火焰图中,颜色并没有实际含义,它将相同的线程栈聚合在一起显示,因此,图中越宽的栈表示此栈在运行过程中,被抓取到的次数越多,也是我们需要重点优化的地方。
jmap
jmap是JVM下的内存剖析工具,用来分析或导出JVM堆数据,如下:
# 查看对象分布直方图,其中3051是java进程的pid
$ jmap -histo:live 3051 | head -n20
num instances bytes class name (module)
-------------------------------------------------------
1: 19462 1184576 [B (java.base@11.0.12)
2: 3955 469920 java.lang.Class (java.base@11.0.12)
3: 18032 432768 java.lang.String (java.base@11.0.12)
4: 11672 373504 java.util.concurrent.ConcurrentHashMap$Node (java.base@11.0.12)
5: 3131 198592 [Ljava.lang.Object; (java.base@11.0.12)
6: 5708 182656 java.util.HashMap$Node (java.base@11.0.12)
7: 1606 155728 [I (java.base@11.0.12)
8: 160 133376 [Ljava.util.concurrent.ConcurrentHashMap$Node; (java.base@11.0.12)
9: 1041 106328 [Ljava.util.HashMap$Node; (java.base@11.0.12)
10: 6216 99456 java.lang.Object (java.base@11.0.12)
11: 1477 70896 sun.util.locale.LocaleObjectCache$CacheEntry (java.base@11.0.12)
12: 1403 56120 java.util.LinkedHashMap$Entry (java.base@11.0.12)
13: 1322 52880 java.lang.ref.SoftReference (java.base@11.0.12)
14: 583 51304 java.lang.reflect.Method (java.base@11.0.12)
15: 999 47952 java.lang.invoke.MemberName (java.base@11.0.12)
16: 29 42624 [C (java.base@11.0.12)
17: 743 41608 java.util.LinkedHashMap (java.base@11.0.12)
18: 877 35080 java.lang.invoke.MethodType (java.base@11.0.12)也可以直接将整个堆内存转储为文件,如下:
$ jmap -dump:format=b,file=heap.hprof 3456
Heap dump file created
$ ls *.hprof
heap.hprof堆转储文件是二进制文件,没法直接查看,一般是配合mat(Memory Analysis Tool)等堆可视化工具来进行分析,如下:
mat打开hprof文件后,会看下如下一个概要界面。
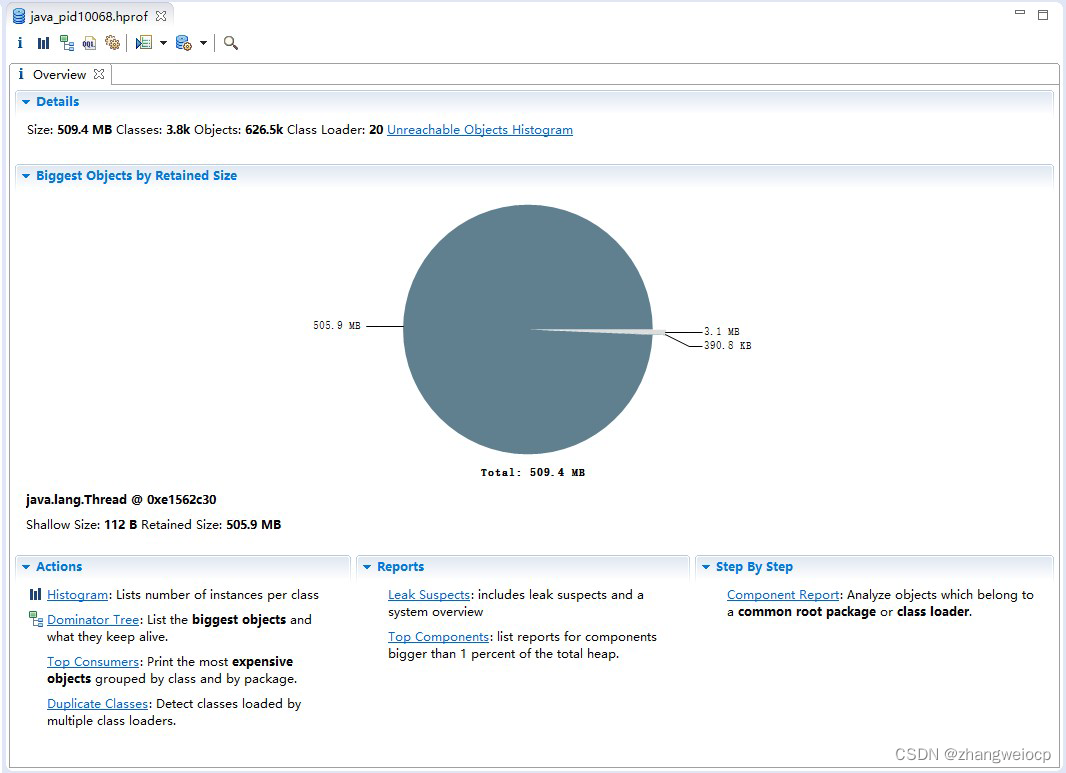
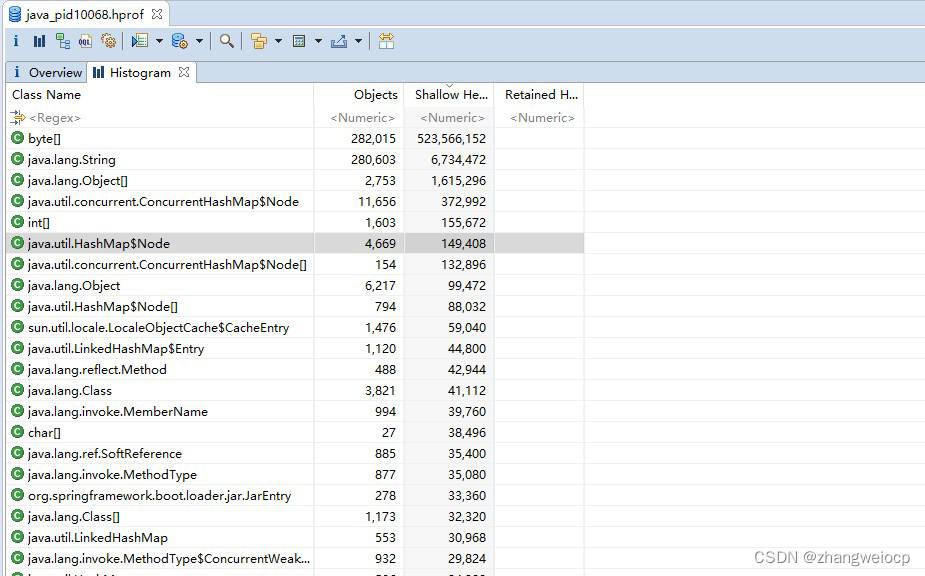
点击Histogram可以按类维度查询内存占用大小
点击Dominator Tree可以看到各对象总大小(Retained Heap,包含引用的子对象),以及所占内存比例,可以看到一个ArrayList对象占用99.31%,看来是个bug,找到创建ArrayList的代码,修改即可。
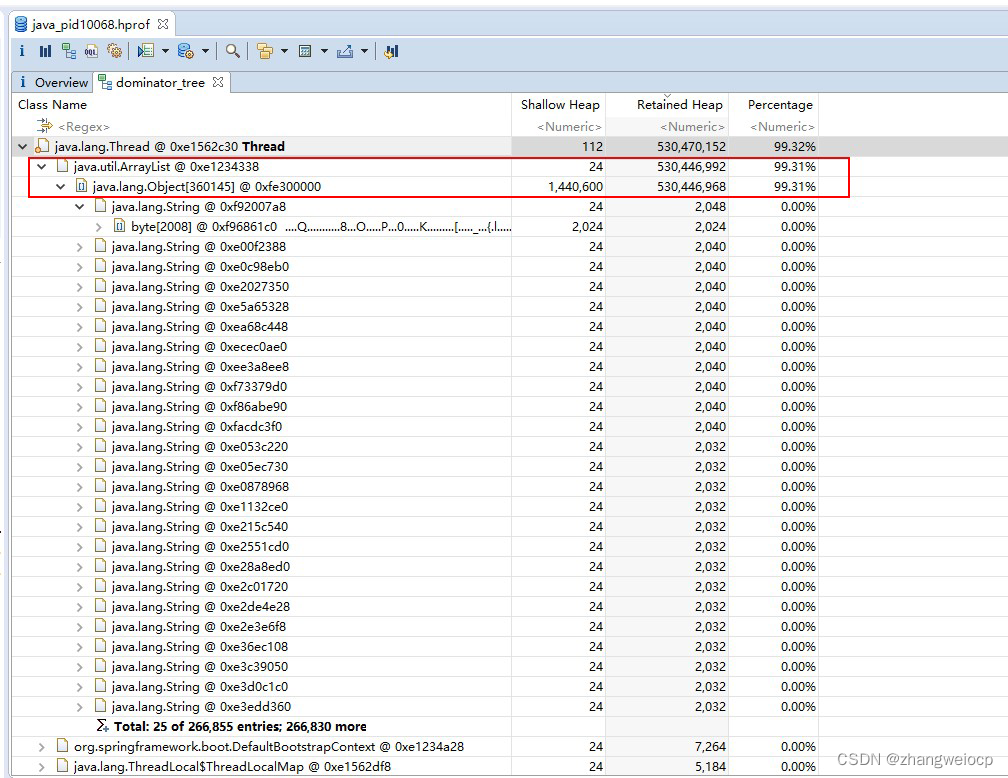 可以看到,使用jmap+mat很容易分析内存泄露bug,但需要注意的是,jmap执行时会让jvm暂停,对于高并发的服务,最好先将问题节点摘除流量后再操作。
可以看到,使用jmap+mat很容易分析内存泄露bug,但需要注意的是,jmap执行时会让jvm暂停,对于高并发的服务,最好先将问题节点摘除流量后再操作。
另外,可以在jvm上添加参数-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=./dump/,使得在发生内存溢出时,自动生成堆转储文件到dump目录。
mat下载地址:http://www.eclipse.org/mat/
arthas
arthas是java下的一款动态追踪工具,可以观测到java方法的调用参数、返回值等,除此之外,还提供了很多实用功能,如反编译、线程剖析、堆内存转储、火焰图等。
下载与使用
# 下载arthas
$ wget https://arthas.aliyun.com/download/3.4.6?mirror=aliyun -O arthas-packaging-3.4.6-bin.zip
# 解压
$ unzip arthas-packaging-3.4.6-bin.zip -d arthas && cd arthas/
# 进入arthas命令交互界面
$ java -jar arthas-boot.jar `pgrep -n java`
[INFO] arthas-boot version: 3.4.6
[INFO] arthas home: /home/work/arthas
[INFO] Try to attach process 3368243
[INFO] Attach process 3368243 success.
[INFO] arthas-client connect 127.0.0.1 3658
,---. ,------. ,--------.,--. ,--. ,---. ,---.
/ O \ | .--. ''--. .--'| '--' | / O \ ' .-'
| .-. || '--'.' | | | .--. || .-. |`. `-.
| | | || |\ \ | | | | | || | | |.-' |
`--' `--'`--' '--' `--' `--' `--'`--' `--'`-----'
wiki https://arthas.aliyun.com/doc
tutorials https://arthas.aliyun.com/doc/arthas-tutorials.html
version 3.4.6
pid 3368243
time 2021-11-13 13:35:49
# help可查看arthas提供了哪些命令
[arthas@3368243]$ help
# help watch可查看watch命令具体用法
[arthas@3368243]$ help watchwatch、trace与stack
在arthas中,使用watch、trace、stack命令可以观测方法调用情况,如下:
# watch观测执行的查询SQL,-x 3指定对象展开层级
[arthas@3368243]$ watch org.apache.ibatis.executor.statement.PreparedStatementHandler parameterize '{target.boundSql.sql,target.boundSql.parameterObject}' -x 3
method=org.apache.ibatis.executor.statement.PreparedStatementHandler.parameterize location=AtExit
ts=2021-11-13 14:50:34; [cost=0.071342ms] result=@ArrayList[
@String[select id,log_info,create_time,update_time,add_time from app_log where id=?],
@ParamMap[
@String[id]:@Long[41115],
@String[param1]:@Long[41115],
],
]
# watch观测耗时超过200ms的SQL
[arthas@3368243]$ watch com.mysql.jdbc.PreparedStatement execute '{target.toString()}' 'target.originalSql.contains("select") && #cost > 200' -x 2
Press Q or Ctrl+C to abort.
Affect(class count: 3 , method count: 1) cost in 123 ms, listenerId: 25
method=com.mysql.jdbc.PreparedStatement.execute location=AtExit
ts=2021-11-13 14:58:42; [cost=1001.558851ms] result=@ArrayList[
@String[com.mysql.jdbc.PreparedStatement@6283cfe6: select count(*) from app_log],
]
# trace追踪方法耗时,层层追踪,就可找到耗时根因,--skipJDKMethod false显示jdk方法耗时,默认不显示
[arthas@3368243]$ trace com.mysql.jdbc.PreparedStatement execute 'target.originalSql.contains("select") && #cost > 200' --skipJDKMethod false
Press Q or Ctrl+C to abort.
Affect(class count: 3 , method count: 1) cost in 191 ms, listenerId: 26
---ts=2021-11-13 15:00:40;thread_name=http-nio-8080-exec-47;id=76;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@5a2d131d
---[1001.465544ms] com.mysql.jdbc.PreparedStatement:execute()
+---[0.022119ms] com.mysql.jdbc.PreparedStatement:checkClosed() #1274
+---[0.016294ms] com.mysql.jdbc.MySQLConnection:getConnectionMutex() #57
+---[0.017862ms] com.mysql.jdbc.PreparedStatement:checkReadOnlySafeStatement() #1278
+---[0.008996ms] com.mysql.jdbc.PreparedStatement:createStreamingResultSet() #1294
+---[0.010783ms] com.mysql.jdbc.PreparedStatement:clearWarnings() #1296
+---[0.017843ms] com.mysql.jdbc.PreparedStatement:fillSendPacket() #1316
+---[0.008543ms] com.mysql.jdbc.MySQLConnection:getCatalog() #1320
+---[0.009293ms] java.lang.String:equals() #57
+---[0.008824ms] com.mysql.jdbc.MySQLConnection:getCacheResultSetMetadata() #1328
+---[0.009892ms] com.mysql.jdbc.MySQLConnection:useMaxRows() #1354
+---[1001.055229ms] com.mysql.jdbc.PreparedStatement:executeInternal() #1379
+---[0.02076ms] com.mysql.jdbc.ResultSetInternalMethods:reallyResult() #1388
+---[0.011517ms] com.mysql.jdbc.MySQLConnection:getCacheResultSetMetadata() #57
+---[0.00842ms] com.mysql.jdbc.ResultSetInternalMethods:getUpdateID() #1404
---[0.008112ms] com.mysql.jdbc.ResultSetInternalMethods:reallyResult() #1409
# stack追踪方法调用栈,找到耗时SQL来源
[arthas@3368243]$ stack com.mysql.jdbc.PreparedStatement execute 'target.originalSql.contains("select") && #cost > 200'
Press Q or Ctrl+C to abort.
Affect(class count: 3 , method count: 1) cost in 138 ms, listenerId: 27
ts=2021-11-13 15:01:55;thread_name=http-nio-8080-exec-5;id=2d;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@5a2d131d
@com.mysql.jdbc.PreparedStatement.execute()
at com.alibaba.druid.pool.DruidPooledPreparedStatement.execute(DruidPooledPreparedStatement.java:493)
at org.apache.ibatis.executor.statement.PreparedStatementHandler.query(PreparedStatementHandler.java:63)
at org.apache.ibatis.executor.statement.RoutingStatementHandler.query(RoutingStatementHandler.java:79)
at org.apache.ibatis.executor.SimpleExecutor.doQuery(SimpleExecutor.java:63)
at org.apache.ibatis.executor.BaseExecutor.queryFromDatabase(BaseExecutor.java:326)
at org.apache.ibatis.executor.BaseExecutor.query(BaseExecutor.java:156)
at org.apache.ibatis.executor.BaseExecutor.query(BaseExecutor.java:136)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:148)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:141)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectOne(DefaultSqlSession.java:77)
at sun.reflect.GeneratedMethodAccessor75.invoke(null:-1)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:433)
at com.sun.proxy.$Proxy113.selectOne(null:-1)
at org.mybatis.spring.SqlSessionTemplate.selectOne(SqlSessionTemplate.java:166)
at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:83)
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:59)
at com.sun.proxy.$Proxy119.selectCost(null:-1)
at com.demo.example.web.controller.TestController.select(TestController.java:57)可以看到watch、trace、stack命令中都可以指定条件表达式,只要满足ognl表达式语法即可,ognl完整语法很复杂,如下是一些经常使用的:

ognl
通过ognl命令,可直接查看静态变量的值,如下:
# 调用System.getProperty静态函数,查看jvm默认字符编码
[arthas@3368243]$ ognl '@System@getProperty("file.encoding")'
@String[UTF-8]
# 找到springboot类加载器
[arthas@3368243]$ classloader -t
+-BootstrapClassLoader
+-sun.misc.Launcher$ExtClassLoader@492691d7
+-sun.misc.Launcher$AppClassLoader@764c12b6
+-org.springframework.boot.loader.LaunchedURLClassLoader@4361bd48
# 获取springboot中所有的beanName,-c指定springboot的classloader的hash值
# 一般Spring项目,都会定义一个SpringUtil的,用于获取bean容器ApplicationContext
[arthas@3368243]$ ognl -c 4361bd48 '#context=@com.demo.example.web.SpringUtil@applicationContext, #context.beanFactory.beanDefinitionNames'
@String[][
@String[org.springframework.context.annotation.internalConfigurationAnnotationProcessor],
@String[org.springframework.context.annotation.internalAutowiredAnnotationProcessor],
@String[org.springframework.context.annotation.internalCommonAnnotationProcessor],
@String[testController],
@String[apiController],
@String[loginService],
...
]
# 获取springboot配置,如server.port是配置http服务端口的
[arthas@3368243]$ ognl -c 4361bd48 '#context=@com.demo.example.web.SpringUtil@applicationContext, #context.getEnvironment().getProperty("server.port")'
@String[8080]
# 查看server.port定义在哪个配置文件中
# 可以很容易看到,server.port定义在application-web.yml
[arthas@3368243]$ ognl -c 4361bd48 '#context=@com.demo.example.web.SpringUtil@applicationContext, #context.environment.propertySources.propertySourceList.{? containsProperty("server.port")}'
@ArrayList[
@ConfigurationPropertySourcesPropertySource[ConfigurationPropertySourcesPropertySource {name='configurationProperties'}],
@OriginTrackedMapPropertySource[OriginTrackedMapPropertySource {name='applicationConfig: [classpath:/application-web.yml]'}],
]
# 调用springboot中bean的方法,获取返回值
[arthas@3368243]$ ognl -c 4361bd48 '#context=@com.demo.example.web.SpringUtil@applicationContext, #context.getBean("demoMapper").queryOne(12)' -x 2
@ArrayList[
@HashMap[
@String[update_time]:@Timestamp[2021-11-09 18:38:13,000],
@String[create_time]:@Timestamp[2021-04-17 15:52:55,000],
@String[log_info]:@String[TbTRNsh2SixuFrkYLTeb25a6zklEZj0uWANKRMe],
@String[id]:@Long[12],
@String[add_time]:@Integer[61],
],
]
# 查看springboot自带tomcat的线程池的情况
[arthas@3368243]$ ognl -c 4361bd48 '#context=@com.demo.example.web.SpringUtil@applicationContext, #context.webServer.tomcat.server.services[0].connectors[0].protocolHandler.endpoint.executor'
@ThreadPoolExecutor[
sm=@StringManager[org.apache.tomcat.util.res.StringManager@16886f49],
submittedCount=@AtomicInteger[1],
threadRenewalDelay=@Long[1000],
workQueue=@TaskQueue[isEmpty=true;size=0],
mainLock=@ReentrantLock[java.util.concurrent.locks.ReentrantLock@69e9cf90[Unlocked]],
workers=@HashSet[isEmpty=false;size=10],
largestPoolSize=@Integer[49],
completedTaskCount=@Long[10176],
threadFactory=@TaskThreadFactory[org.apache.tomcat.util.threads.TaskThreadFactory@63c03c4f],
handler=@RejectHandler[org.apache.tomcat.util.threads.ThreadPoolExecutor$RejectHandler@3667e559],
keepAliveTime=@Long[60000000000],
allowCoreThreadTimeOut=@Boolean[false],
corePoolSize=@Integer[10],
maximumPoolSize=@Integer[8000],
]其它命令
arthas还提供了jvm大盘、线程剖析、堆转储、反编译、火焰图等功能,如下:
# 显示耗cpu较多的前4个线程
[arthas@3368243]$ thread -n 4
"C2 CompilerThread0" [Internal] cpuUsage=8.13% deltaTime=16ms time=46159ms
"C2 CompilerThread1" [Internal] cpuUsage=4.2% deltaTime=8ms time=47311ms
"C1 CompilerThread2" [Internal] cpuUsage=3.06% deltaTime=6ms time=17402ms
"http-nio-8080-exec-40" Id=111 cpuUsage=1.29% deltaTime=2ms time=624ms RUNNABLE (in native)
at java.net.SocketInputStream.socketRead0(Native Method)
...
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4113)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2570)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2731)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2818)
...
at com.demo.example.web.controller.TestController.select(TestController.java:57)
# 堆转储
[arthas@3368243]$ heapdump
Dumping heap to /tmp/heapdump2021-11-13-15-117226383240040009563.hprof ...
Heap dump file created
# cpu火焰图,容器环境下profiler start可能用不了,可用profiler start -e itimer替代
[arthas@3368243]$ profiler start
Started [cpu] profiling
[arthas@3368243]$ profiler stop
OK
profiler output file: /home/work/app/arthas-output/20211113-151208.svg
# dashboard就类似Linux下的top一样,可看jvm线程、堆内存的整体情况
[arthas@3368243]$ dashboard
# jvm就类似Linux下的ps一样,可以看jvm进程的一些基本信息,如:jvm参数、类加载、线程数、打开文件描述符数等
[arthas@3368243]$ jvm
# 反编译
[arthas@3368243]$ jad com.demo.example.web.controller.TestController可见,arthas已经不是一个单纯的动态追踪工具了,它把jvm下常用的诊断功能几乎全囊括了。
相关项目地址:
https://arthas.aliyun.com/doc/index.html
https://github.com/jvm-profiling-tools/async-profiler
系统调用观测
strace
strace是Linux中用来观测系统调用的工具,学过操作系统原理都知道,操作系统向应用程序暴露了一批系统调用接口,应用程序只能通过这些系统调用接口来访问操作系统,比如申请内存、文件或网络io操作等。
用法如下:
# -T 打印系统调用花费的时间
# -tt 打印系统调用的时间点
# -s 输出的最大长度,默认32,对于调用参数较长的场景,建议加大
# -f 是否追踪fork出来子进程的系统调用,由于服务端服务普通使用线程池,建议加上
# -p 指定追踪的进程pid
# -o 指定追踪日志输出到哪个文件,不指定则直接输出到终端
$ strace -T -tt -f -s 200 -p 87 -o strace.log实例:抓取实际发送的SQL
有些时候,我们会发现代码中完全没问题的SQL,却查不到数据,这极有可能是由于项目中一些底层框架改写了SQL,导致真实发送的SQL与代码中的SQL不一样。
遇到这种情况,先别急着扒底层框架代码,那样会比较花时间,毕竟程序员的时间很宝贵,不然要加更多班的,怎么快速确认是不是这个原因呢?
有两种方法,第一种是使用wireshark抓包,第二种就是本篇介绍的strace了,由于程序必然要通过网络io相关的系统调用,将SQL命令发送到数据库,因此我们只需要用strace追踪所有系统调用,然后grep出发送SQL的系统调用即可,如下:
$ strace -T -tt -f -s 200 -p 52 |& tee strace.log从图中可以清晰看到,mysql的jdbc驱动是通过sendto系统调用来发送SQL,通过recvfrom来获取返回结果,可以发现,由于SQL是字符串,strace自动帮我们识别出来了,而返回结果因为是二进制的,就不容易识别了,需要非常熟悉mysql协议才行。
另外,从上面其实也很容易看出SQL执行耗时,计算相同线程号的sendto与recvfrom之间的时间差即可。
内核观测工具
perf
perf是Linux官方维护的性能分析工具,它可以观测很多非常细非常硬核的指标,如IPC,cpu缓存命中率等,如下:
# ubuntu安装perf,包名和内核版本相关,可以直接输入perf命令会给出安装提示
sudo apt install linux-tools-5.4.0-74-generic linux-cloud-tools-5.4.0-74-generic
# cpu的上下文切换、cpu迁移、IPC、分支预测
sudo perf stat -a sleep 5
# cpu的IPC与缓存命中率
sudo perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles -a sleep 10
# cpu的1级数据缓存命中率
sudo perf stat -e L1-dcache-loads,L1-dcache-load-misses,L1-dcache-stores -a sleep 10
# 页表缓存TLB命中率
sudo perf stat -e dTLB-loads,dTLB-load-misses,dTLB-prefetch-misses -a sleep 10
# cpu的最后一级缓存命中率
sudo perf stat -e LLC-loads,LLC-load-misses,LLC-stores,LLC-prefetches -a sleep 10
# Count system calls by type for the specified PID, until Ctrl-C:
sudo perf stat -e 'syscalls:sys_enter_*' -p PID -I1000 2>&1 | awk '$2 != 0'
# Count system calls by type for the entire system, for 5 seconds:
sudo perf stat -e 'syscalls:sys_enter_*' -a sleep 5 2>&1| awk '$1 != 0'
# Count syscalls per-second system-wide:
sudo perf stat -e raw_syscalls:sys_enter -I 1000 -aoncpu火焰图
当然,它也可以用来抓取线程栈,并生成火焰图,如下:
# 抓取60s的线程栈,其中1892是mysql的进程pid
$ sudo perf record -F 99 -p 1892 -g sleep 60
[ perf record: Woken up 5 times to write data ]
[ perf record: Captured and wrote 1.509 MB perf.data (6938 samples) ]
# 生成火焰图
$ sudo perf script \
| ./FlameGraph/stackcollapse-perf.pl \
| ./FlameGraph/flamegraph.pl > mysqld_flamegraph.svg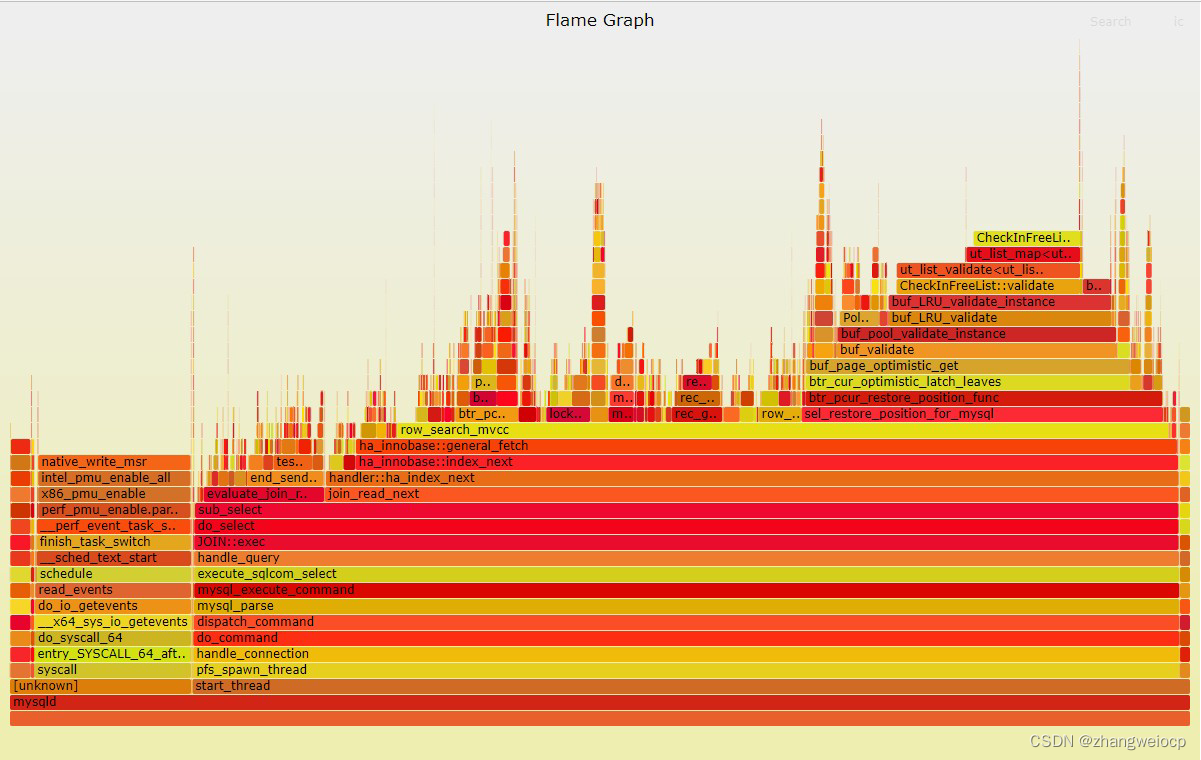
如上所示,使用perf生成的mysql的火焰图,perf抓取线程栈相比jstack的优点是,抓取精度比jstack更高,运行开销比jstack更小,并且还可以抓到Linux内核调用栈!
注:perf抓取线程栈,是顺着cpu上的栈寄存器找到当前线程的调用栈的,因此它只能抓到当前正在cpu上运行线程的线程栈,因此通过perf可以非常容易做oncpu分析,分析high cpu问题。
offcpu火焰图
线程在运行的过程中,要么在CPU上执行,要么被锁或io操作阻塞,从而离开CPU进去睡眠状态,待被解锁或io操作完成,线程会被唤醒而变成运行态。
如下:
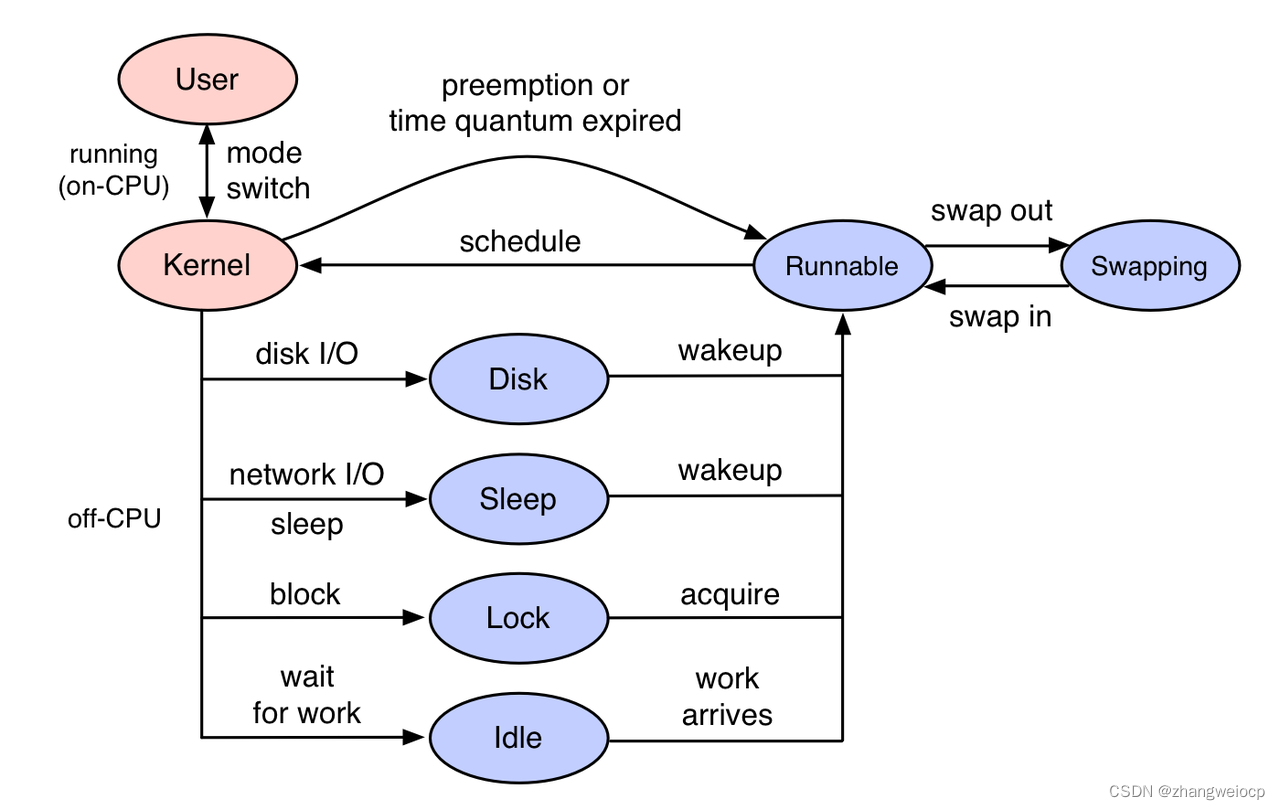
当线程在cpu上运行时,我们称其为oncpu,当线程阻塞而离开cpu后,称其为offcpu。
如果当线程在睡眠之前记录一下当前时间,然后被唤醒时记录当前线程栈与阻塞时间,再使用FlameGraph工具将线程栈绘制成一张火焰图,这样我们就得到了一张offcpu火焰图,火焰图宽的部分就是线程阻塞较多的点了,这就需要再介绍一下bcc工具了。
bcc
bcc是使用Linux ebpf机制实现的一套工具集,包含非常多的底层分析工具,如查看文件缓存命中率,tcp重传情况,mysql慢查询等等。
它还可以做offcpu分析,生成offcpu火焰图,如下:
# ubuntu安装bcc工具集
$ sudo apt install bpfcc-tools
# 使用root身份进入bash
$ sudo bash
# 获取jvm函数符号信息
$ ./FlameGraph/jmaps
# 抓取offcpu线程栈30s,83101是mysqld的进程pid
$ offcputime-bpfcc -df -p 83101 30 > offcpu_stack.out
# 生成offcpu火焰图
$ cat offcpu_stack.out \
| sed 's/;::/:::/g' \
| ./FlameGraph/flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us > offcpu_stack.svg
如上图,我绘制了一张mysql的offcpu火焰图,可以发现大多数线程的offcpu都是由锁引起的,另外,offcpu火焰图与oncpu火焰图稍有不同,oncpu火焰图宽度代表线程栈出现次数,而offcpu火焰图宽度代表线程栈阻塞时间。
bcc项目地址:https://github.com/iovisor/bcc
bpftrace
arthas只能追踪java程序,对于原生程序(如MySQL)就无能为力了,好在Linux生态提供了大量的机制以及配套工具,可用于追踪原生程序的调用,如perf、bpftrace、systemtap等,由于bpftrace使用难度较小,本篇主要介绍它的用法。
bpftrace是基于ebpf技术实现的动态追踪工具,它对ebpf技术进行封装,实现了一种脚本语言,就像上面介绍的arthas基于ognl一样,它实现的脚本语言类似于awk,封装了常见语句块,并提供内置变量与内置函数,如下:
$ sudo bpftrace -e 'BEGIN { printf("Hello, World!\n"); } '
Attaching 1 probe...
Hello, World!实例:在调用端追踪慢SQL
前面我们用strace追踪过mysql的jdbc驱动,它使用sendto与recvfrom系统调用来与mysql服务器通信,因此,我们在sendto调用时,计下时间点,然后在recvfrom结束时,计算时间之差,就可以得到相应SQL的耗时了,如下:
- 先找到
sendto与recvfrom系统调用在bpftrace中的追踪点,如下:
# 查找sendto|recvfrom系统调用的追踪点,可以看到sys_enter_开头的追踪点应该是进入时触发,sys_exit_开头的退出时触发
$ sudo bpftrace -l '*tracepoint:syscalls*' |grep -E 'sendto|recvfrom'
tracepoint:syscalls:sys_enter_sendto
tracepoint:syscalls:sys_exit_sendto
tracepoint:syscalls:sys_enter_recvfrom
tracepoint:syscalls:sys_exit_recvfrom
# 查看系统调用参数,方便我们编写脚本
$ sudo bpftrace -lv tracepoint:syscalls:sys_enter_sendto
tracepoint:syscalls:sys_enter_sendto
int __syscall_nr;
int fd;
void * buff;
size_t len;
unsigned int flags;
struct sockaddr * addr;
int addr_len;- 编写追踪脚本
trace_slowsql_from_syscall.bt,脚本代码如下:
#!/usr/local/bin/bpftrace
BEGIN {
printf("Tracing jdbc SQL slower than %d ms by sendto/recvfrom syscall\n", $1);
printf("%-10s %-6s %6s %s\n", "TIME(ms)", "PID", "MS", "QUERY");
}
tracepoint:syscalls:sys_enter_sendto /comm == "java"/ {
// mysql协议中,包开始的第5字节指示命令类型,3代表SQL查询
$com = *(((uint8 *) args->buff)+4);
if($com == (uint8)3){
@query[tid]=str(((uint8 *) args->buff)+5, (args->len)-5);
@start[tid]=nsecs;
}
}
tracepoint:syscalls:sys_exit_recvfrom /comm == "java" && @start[tid]/ {
$dur = (nsecs - @start[tid]) / 1000000;
if ($dur > $1) {
printf("%-10u %-6d %6d %s\n", elapsed / 1000000, pid, $dur, @query[tid]);
}
delete(@query[tid]);
delete(@start[tid]);其中,comm表示进程名称,tid表示线程号,@query[tid]与@start[tid]类似map,以tid为key的话,这个变量就像一个线程本地变量了。
3. 调用上面的脚本,可以看到各SQL执行耗时,如下:
$ sudo BPFTRACE_STRLEN=80 bpftrace trace_slowsql_from_syscall.bt
Attaching 3 probes...
Tracing jdbc SQL slower than 0 ms by sendto/recvfrom syscall
TIME(ms) PID MS QUERY
6398 3368243 125 select sleep(0.1)
16427 3368243 22 select id from app_log al order by id desc limit 1
16431 3368243 20 select id,log_info,create_time,update_time,add_time from app_log where id=11692
17492 3368243 21 select id,log_info,create_time,update_time,add_time from app_log where id=29214实例:在服务端追踪慢SQL
从调用端来追踪SQL耗时,会包含网络往返时间,为了得到更精确的SQL耗时,我们可以写一个追踪服务端mysql的脚本,来观测SQL耗时,如下:
- 确定mysqld服务进程的可执行文件与入口函数
$ which mysqld
/usr/local/mysql/bin/mysqld
# objdump可导出可执行文件的动态符号表,做几张mysqld的火焰图就可发现,dispatch_command是SQL处理的入口函数
# 另外,由于mysql是c++写的,方法名是编译器改写过的,这也是为啥下面脚本中要用*dispatch_command*模糊匹配
$ objdump -tT /usr/local/mysql/bin/mysqld | grep dispatch_command
00000000014efdf3 g F .text 000000000000252e _Z16dispatch_commandP3THDPK8COM_DATA19enum_server_command
00000000014efdf3 g DF .text 000000000000252e Base _Z16dispatch_commandP3THDPK8COM_DATA19enum_server_command- 使用uprobe追踪
dispatch_command的调用,如下:
#!/usr/bin/bpftrace
BEGIN{
printf("Tracing mysqld SQL slower than %d ms. Ctrl-C to end.\n", $1);
printf("%-10s %-6s %6s %s\n", "TIME(ms)", "PID", "MS", "QUERY");
}
uprobe:/usr/local/mysql/bin/mysqld:*dispatch_command*{
if (arg2 == (uint8)3) {
@query[tid] = str(*arg1);
@start[tid] = nsecs;
}
}
uretprobe:/usr/local/mysql/bin/mysqld:*dispatch_command* /@start[tid]/{
$dur = (nsecs - @start[tid]) / 1000000;
if ($dur > $1) {
printf("%-10u %-6d %6d %s\n", elapsed / 1000000, pid, $dur, @query[tid]);
}
delete(@query[tid]);
delete(@start[tid]);
}追踪脚本整体上与之前系统调用版本的类似,不过追踪点不一样而已。
实例:找出扫描大量行的SQL
众所周知,SQL执行时需要扫描数据,并且扫描的数据越多,SQL性能就会越差。
但对于一些中间情况,SQL扫描行数不多也不少,如2w条。且这2w条数据都在缓存中的话,SQL执行时间不会很长,导致没有记录在慢查询日志中,但如果这样的SQL并发量大起来的话,会非常耗费CPU。
对于mysql的话,扫描行的函数是row_search_mvcc,如果你经常抓取mysql栈的话,很容易发现这个函数,如下:
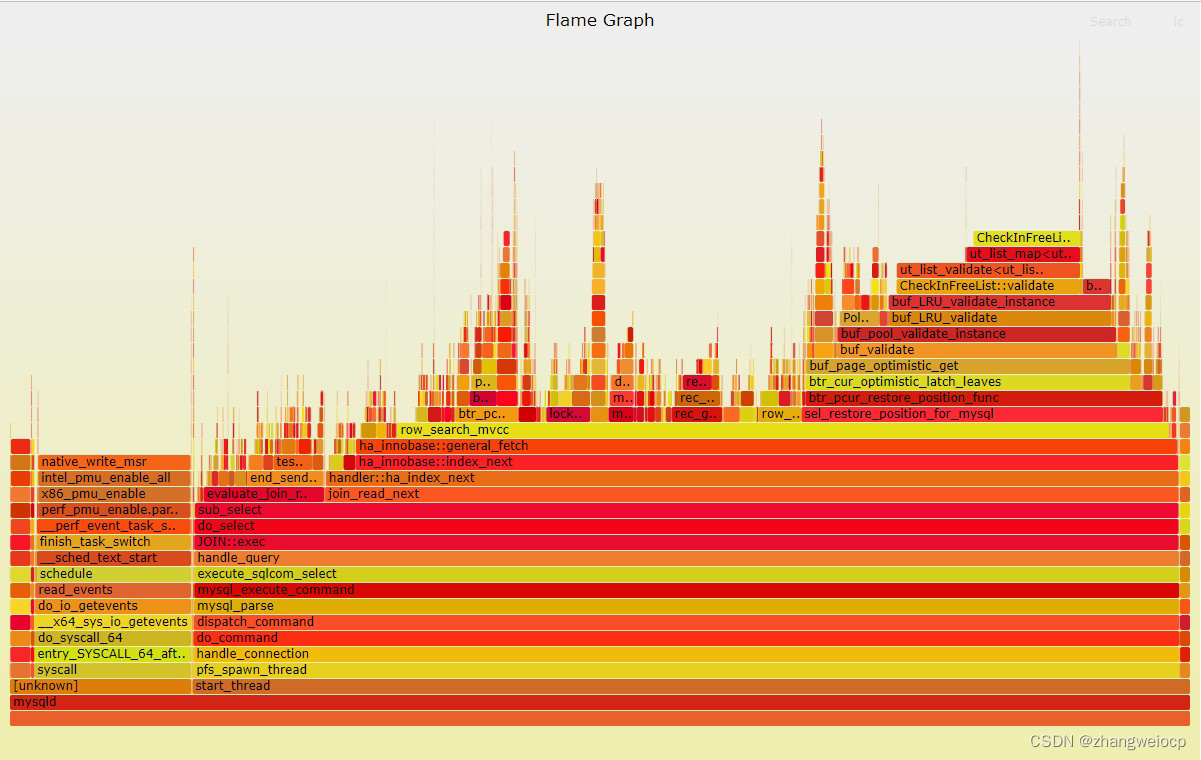
mysql每扫一行调用一次row_search_mvcc,如果在追踪脚本中追踪此函数,记录下调用次数,就可以观测SQL的扫描行数了,如下:
#!/usr/bin/bpftrace
BEGIN{
printf("Tracing mysqld SQL scan row than %d. Ctrl-C to end.\n", $1);
printf("%-10s %-6s %6s %10s %s\n", "TIME(ms)", "PID", "MS", "SCAN_NUM", "QUERY");
}
uprobe:/usr/local/mysql/bin/mysqld:*dispatch_command*{
$COM_QUERY = (uint8)3;
if (arg2 == $COM_QUERY) {
@query[tid] = str(*arg1);
@start[tid] = nsecs;
}
}
uprobe:/usr/local/mysql/bin/mysqld:*row_search_mvcc*{
@scan_num[tid]++;
}
uretprobe:/usr/local/mysql/bin/mysqld:*dispatch_command* /@start[tid]/{
$dur = (nsecs - @start[tid]) / 1000000;
if (@scan_num[tid] > $1) {
printf("%-10u %-6d %6d %10d %s\n", elapsed / 1000000, pid, $dur, @scan_num[tid], @query[tid]);
}
delete(@query[tid]);
delete(@start[tid]);
delete(@scan_num[tid]);
}脚本运行效果如下:
$ sudo BPFTRACE_STRLEN=80 bpftrace trace_mysql_scan.bt 200
Attaching 4 probes...
Tracing mysqld SQL scan row than 200. Ctrl-C to end.
TIME(ms) PID MS SCAN_NUM QUERY
150614 1892 4 300 select * from app_log limit 300
# 全表扫描,慢!
17489 1892 424 43717 select count(*) from app_log
# 大范围索引扫描,慢!
193013 1892 253 20000 select count(*) from app_log where id < 20000
# 深分页,会查询前20300条,取最后300条,慢!
213395 1892 209 20300 select * from app_log limit 20000,300
# 索引效果不佳,虽然只会查到一条数据,但扫描数据量不会少,慢!
430374 1892 186 15000 select * from app_log where id < 20000 and seq = 15000 limit 1 如上所示,app_log是我建的一张测试表,共43716条数据,其中id字段是自增主键,seq值与id值一样,但没有索引。
可以看到上面的几个场景,不管什么场景,只要扫描行数变大,耗时就会变长,但也都没有超过500毫秒的,原因是这个表很小,数据可以全部缓存在内存中。
可见,像bpftrace这样的动态追踪工具是非常强大的,而且比arthas更加灵活,arthas只能追踪单个函数,而bpftrace可以跨函数追踪。
bpftrace使用手册:https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md
抓包工具
ngrep
ngrep也是一款抓包工具,它将包数据以文本形式直接显示出来,对于简单场景的抓包,不需要wireshark配合,如下:
抓HTTP请求
ngrep -W byline port 8080抓取查询SQL
ngrep -W byline 'select' port 4578tcpdump
tcpdump是一个通用抓包工具,一般用它来抓网络包数据,然后再使用wireshark分析,如下:
抓取3961端口网络包
tcpdump tcp -i eth0 -s 0 -c 10000 and port 3764 -w ./target.capwireshark分析
将target.cap导入到wireshark分析。
查看某一具体sql的网络包交互情况,如下:
a. 先Decode相应端口使用MySQL协议解析:
b. 如下,输入mysql.query contains "5211117719406053",查看SQL中包含单号5211117719406053的数据包:
抓包如何判断是网络慢还是后端处理慢?
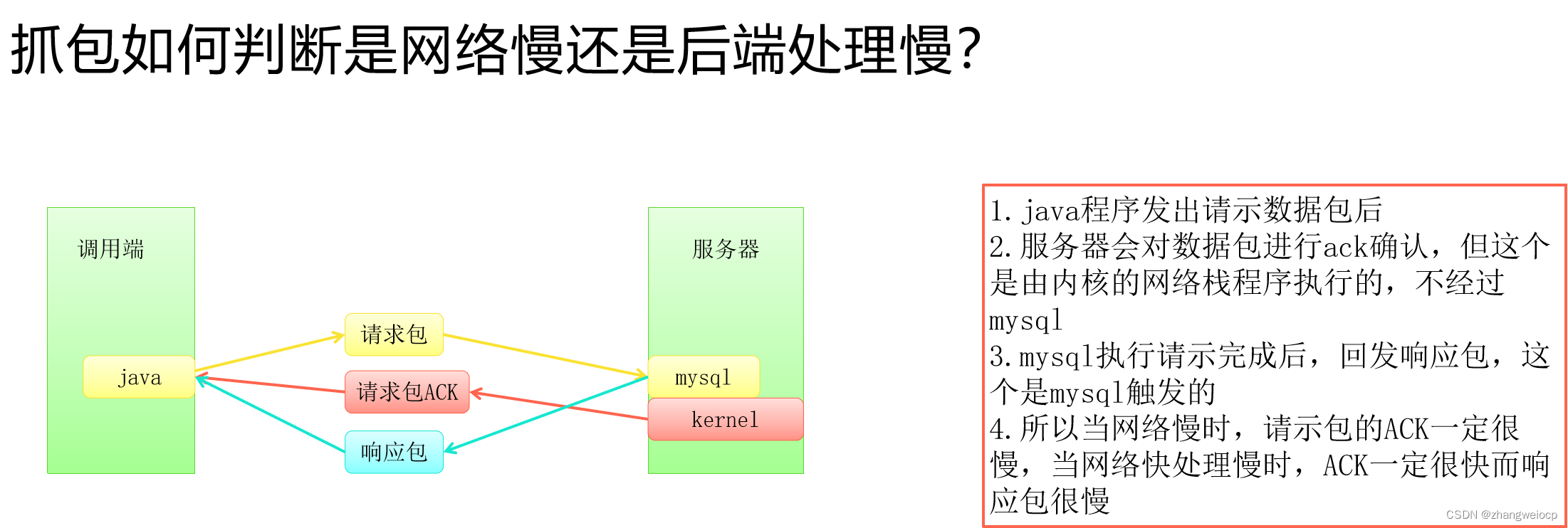
为方便分析耗时,一般建议在wireshark上再添加如下两列:
- tcpDelta = tcp.time_delta,表示在当前tcp连接中,当前包相对上一个包的时间差。
- ack_rtt = tcp.analysis.ack_rtt,表示tcp中的ack包,相对其数据包的时间差。
如下,找耗时最大的包:发现对于select t2.data as sapCustomerCode,t1.uniquecode as uniquecode from ...这条SQL,服务端回复ack很快,而在回复数据包时变慢,说明是慢在MySQL处理上,而非网络里,因为如果网络慢的话,ack应该也会变慢。
观测工具总结
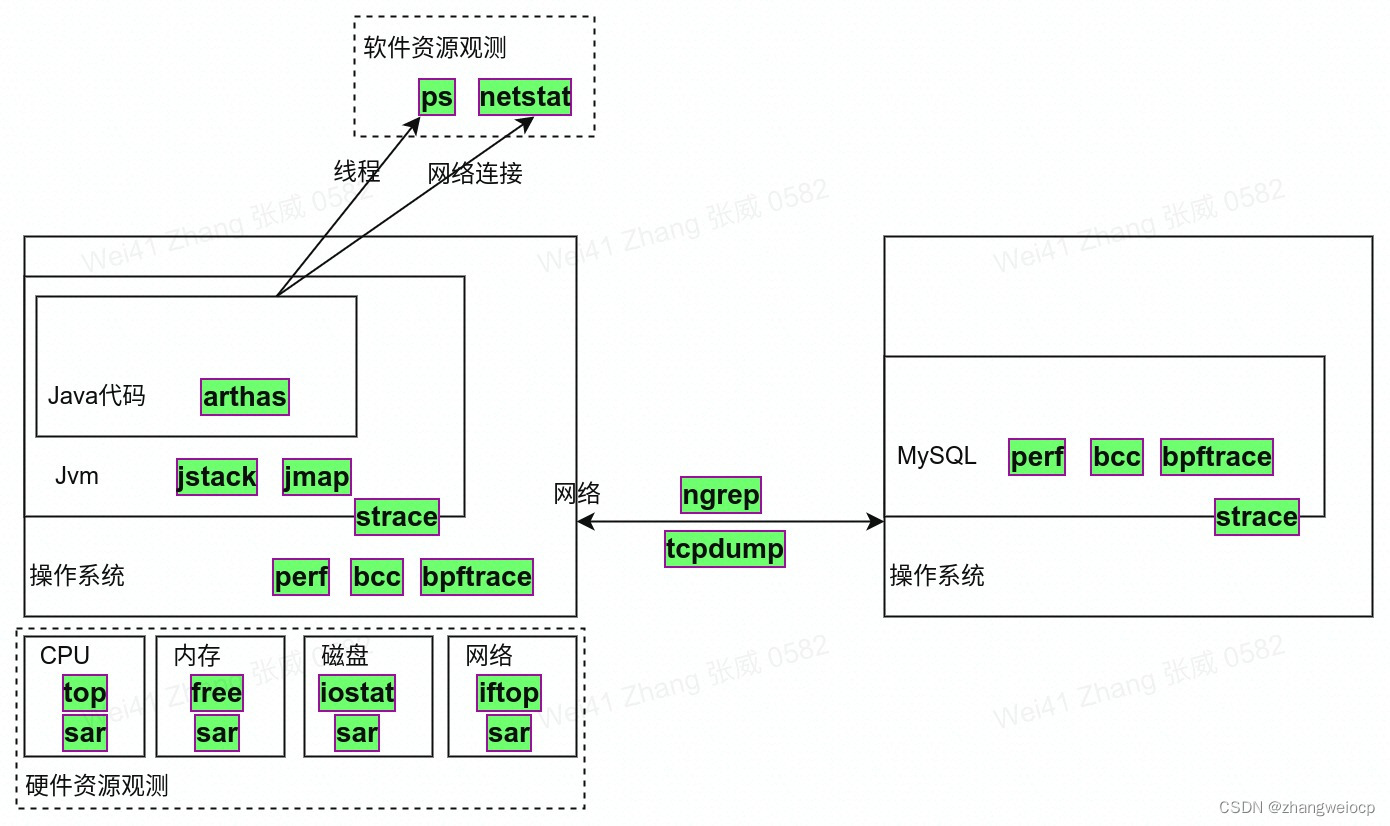
命令可用情况
由于应用系统一般部署在Neo容器环境中,权限这一块是受限的,在Neo环境中上述各工具命令的可用情况如下:
| 命令 | 是否可用 | 描述 |
| vmstat、mpstat、free | 可用 | |
| top、pidstat、iostat | 可用 | |
| iotop | 不可用 | 权限问题,执行会报错 |
| nicstat、iftop、sar、dstat | 可用 | |
| jstack、jmap、arthas | 可用 | |
| strace | 可用 | |
| ngrep、tcpdump | 可用 | |
| perf、bcc、bpftrace | 不可用 | 需要CAP_SYS_ADMIN权限,Neo没有授权此权限给业务容器 |
思考:问题偶现或已经发生过了,怎么办?
上面使用各种工具排查问题,都是建立在问题正在发生的场景下,如果问题偶然出现,或已经发生完了,由于问题现场已经消失,使用命令工具就不太好使了。
这种情况的问题排查,比较依赖于系统的建设,订单组这边为方便解决这种问题,分别在如下几个方面做了一些工作:
完善监控系统
完善各维度的监控系统,如:机器监控、线程池、连接池、JVM监控、数据库监控等。
机器监控
主要监控硬件资源,如CPU、内存等,监控数据由Neo提供,可以理解为top命令数据被采集下来了。
线程池监控
对于服务端程序来说,线程是最重要的软件资源之一,线程不够了,程序啥事都没法干了,这也是导致接口偶尔慢的主要原因之一。
连接池监控
对于服务端程序来说,数据库连接也是最重要的软件资源之一,连接不够了,会导致线程阻塞,这也是导致接口偶尔慢的主要原因之一。
JVM监控
jvm监控,主要监控堆内存使用情况,以及gc情况,由于gc的不确定性,gc也是导致接口偶尔慢的主要原因之一,而如果是oom这种问题,则会导致整个系统停摆。
数据库监控
业务监控
根据系统所支撑的业务流程,建设一些业务维度的监控面板。
短信预警
完善日志系统
日志有哪些?
nginx日志
如果你的服务前面有nginx,一定不要错过了nginx日志的检查。
access日志
像tomcat、resin等web服务器,都提供有接口访问日志功能,记录了请求时间、耗时等,强烈建议打开。
springboot开启方法,application.yml文件中添加如下配置:
server:
servlet:
context-path: "/"
tomcat:
accesslog:
enabled: true
directory: /home/work/logs/applogs/oc-search
file-date-format: .yyyy-MM-dd
pattern: '%h %l %u %t "%r" %s %b %Dms "%{Referer}i" "%{User-Agent}i" "%{X-Request-ID}i" "%{X-Forwarded-For}i"'resin开启方法,resin.xml中添加如下配置:
gc日志
对于有gc的服务,gc日志一定要配置上,加入如下JVM参数即可开启:
-XX:-OmitStackTraceInFastThrow
-Xloggc:/home/work/logs/applogs/gc-%t.log
-XX:+PrintClassHistogram
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC
-XX:+PrintGCDateStamps
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintAdaptiveSizePolicy
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/home/work/logs/applogs/dmesg
内核日志,一般建议排查问题没有思路时,常规性的看一下这个日志。
# 像丢包、警告、错误等情况,内核会记录下来
dmesg | tail -n100
# 如果你的进程莫名其妙挂掉了,很有可能是内存不足,内核杀死了你的服务进程
dmesg | grep -i kill应用日志
这个就是我们应用里面的slf4j、log4j等输出的日志了。
慢查询日志
日志格式规范
时间、日志级别、机器、线程、日志记录器名、trace_id、耗时、业务操作名、单号、异常堆栈等
注意以下场景:
1、打印异常时,将全部异常栈打印出来,而不要只打印message
// 不推荐,这样打印异常,会导致异常栈丢失,难以定位问题
log.error(e.getMessage);
// 推荐写法
log.error(orderId + "xxx处理失败", e);
// 不推荐,原始异常丢失
try{
...
}catch(Exception e){
throw new BizException("xxx处理失败");
}
// 推荐写法
try{
...
}catch(Exception e){
throw new BizException("xxx处理失败", e);
}2、nginx传递的X-REQUEST-ID,直接记录到日志中,便于追踪
String logId = request.getHeader("X-REQUEST-ID");
log.info("logId:{}, {}订单处理,耗时{}ms", logId, orderId, cost);
//最好通过日志的MDC机制,统一在日志框架中记录
MDC.put("traceId", logId);日志分析常见思路
查找异常值
查看日志是否有高耗时操作,或是否出现java异常。
关联分析
时间关联性:比如在某一时刻耗时请求增加,看看相同时间cpu、内存、gc的情况。
线程关联性:比如某一处理耗时增加,看看相同线程前后的日志是否有些不一样的case。
调用关联性:最常见的就是对比调用方与服务方相同trace_id的耗时情况,如果没有传递trace_id,也可思考数据本身的关联性,比如单号+时间这种,很多时候也能唯一确定一次调用。
分布情况
分析日志在时间、位置(机器,线程,接口,方法,错误码)、耗时上的分布。
挂脚本
arthas后台任务
arthas可以通过添加&符号,使命令运行在后台模式,因此只需要添加条件,一段时间检查结果即可。
# 添加后台任务,监测慢查询SQL
[arthas@3368243]$ watch com.mysql.jdbc.PreparedStatement execute '{target.toString()}' 'target.originalSql.contains("select") && #cost > 2000' -x 2 > slow_sql.log &
# 与shell类似,可以通过jobs查看后台任务
[arthas@3368243]$ jobs定时检测脚本
通过在机器上启动一些定时脚本,定时检测问题是否发生,如发生,则使用相关诊断命令并保存命令结果,如下:
# 当系统健康检查失败2次时,自动jstack
while sleep 1;do
res=$(curl 'http://localhost:8080/_health' --connect-timeout 2 --max-time 2 -sS 2>&1)
[[ $res =~ "ok" ]] && ((fail_num=0)) || ((fail_num++))
if [[ $fail_num -ge 2 ]];then
pid=$(pgrep -n java)
jstack $pid >> jstack.log 2>&1
fi
done编码规范
oom是魔鬼,系统一旦出现oom,会导致整个系统停摆,系统可用性迅速下降到接近0,为此,定下了2个专门的规范,尽量避免oom产生。

总结
如果一个偶现问题,分析下来没有思路了,考虑一下是否可以完善一下监控系统或添加更详细的日志,不要排查不出来,也不做进一步的辅助排查问题的尝试。
其它命令
vmstat
vmstat全名是虚拟内存统计信息命令,看起来好像是用来观测内存的,实际上cpu、内存、io资源它都能观测。
$ vmstat -w 1
procs -----------------------memory---------------------- ---swap-- -----io---- -system-- --------cpu--------
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 0 12531512 102680 274940 0 0 0 3 0 3 0 0 100 0 0
2 0 0 12531512 102680 274940 0 0 0 0 106 55 25 0 75 0 0
2 0 0 12531512 102680 274940 0 0 0 0 105 58 25 0 75 0 0
2 0 0 12531512 102680 274940 0 0 0 0 105 56 25 0 75 0 01s显示一次,第一行是系统启动以来的统计信息,一般可忽略不看,从第二行开始看即可。
- r:cpu运行队列长度,即有多少线程等待操作系统调度运行,这可看做是cpu的饱和度指标,长时间处于高值一般都有问题。
- b: 不可中断阻塞的线程数量,一般就是阻塞于io访问的线程数量。
- swpd: 内存交换到磁盘的内存大小,单位kB
- free:剩余内存大小,单位kB
- buff: 用于buff的内存大小,单位kB
- cache:用于文件页面缓存的内存大小,单位kB
- si:磁盘换入到内存的当前速度,单位kB/s
- so:内存换出到磁盘的当前速度,单位kB/s
- bi:每秒读取的磁盘块数量,单位blocks/s
- bo:每秒写入的磁盘块数量,单位blocks/s
- in:每秒中断数量
- cs:每秒线程上下文切换次数
- us:cpu用户态使用率
- sy:cpu内核态使用率
- id:cpu空闲率
- wa:等待I/O,线程被阻塞等待磁盘I/O时的CPU空闲时间占总时间的比例
- st:steal偷取,CPU在虚拟化环境下在其他租户上的开销
mpstat
mpstat是用来查看cpu上各个核的cpu使用率的,如下:
$ mpstat -P ALL 1
Linux 4.19.128-microsoft-standard (DESKTOP-GC9LLHC) 10/24/21 _x86_64_ (8 CPU)
12:39:37 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
12:39:38 all 24.57 0.00 0.00 0.00 0.00 1.72 0.00 0.00 0.00 73.71
12:39:38 0 0.00 0.00 0.00 0.00 0.00 12.28 0.00 0.00 0.00 87.72
12:39:38 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
12:39:38 2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
12:39:38 3 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:39:38 4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
12:39:38 5 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:39:38 6 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
12:39:38 7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00如上,可见3、5号核的cpu使用率基本满载,而其它核非常空闲,这一般是由于程序多线程设计上有问题,导致某部分线程非常忙,另一部分线程没事干,而mpstat就是用来观测是否有这种cpu核负载不均的问题的。
pidstat
pidstat基本和top功能是类似的,不过它是非交互式的命令,一般作为top的补充使用,如下:
# 默认查看活动进程的cpu使用情况,加-t可以查看线程的
$ pidstat 1
13:32:45 UID PID %usr %system %guest %wait %CPU CPU Command
13:32:46 1000 3051 0.00 1.00 0.00 0.00 1.00 1 java
13:32:46 1000 3241 100.00 0.00 0.00 0.00 100.00 7 stress
13:32:46 1000 3242 100.00 0.00 0.00 0.00 100.00 5 stress
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 1000 3051 0.00 0.33 0.00 0.00 0.33 - java
Average: 1000 3241 100.00 0.00 0.00 0.00 100.00 - stress
Average: 1000 3242 100.00 0.00 0.00 0.00 100.00 - stress
# -w可以看线程上下文切换情况
# cswch/s:自愿上下文切换,比如等待io或锁
# nvcswch/s:非自愿上下文切换,比如分给自己时间片用完了,一般需要关注这个,因为现在的程序大多是io密集型的,用完时间片的机会很少
$ pidstat -w 1
13:37:57 UID PID cswch/s nvcswch/s Command
13:37:58 1000 3299 1.00 0.00 pidstat
13:37:58 UID PID cswch/s nvcswch/s Command
13:37:59 0 8 1.00 0.00 init
13:37:59 1000 9 1.00 0.00 wsltermd
13:37:59 1000 3299 1.00 0.00 pidstat
# -v可以看运行进程的线程数与文件描述符数量
$ pidstat -v 1
01:41:34 PM UID PID threads fd-nr Command
01:41:35 PM 1000 876 95 177 java
# -r可以看运行进程的内存使用情况以及缺页情况
# minflt/s:轻微缺页,一般不用太关注
# majflt/s:严重缺页,一般意味着发生了swrap,量较大时需要关注
$ pidstat -r 1
02:07:24 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
02:07:25 PM 999 2786 2.00 0.00 52792 3140 0.08 redis-server
02:07:25 PM 1000 601098 1.00 0.00 13976 6296 0.16 sshd
# -d可以看某个进程的io使用情况
$ pidstat -d 1
14:12:06 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
14:12:07 1000 3051 0.00 80.00 0.00 0 java
14:12:07 1000 3404 0.00 0.00 0.00 79 stressfree
其实上面的vmstat、top已经可以看到内存使用情况了,free命令更纯粹一点,如下:
# 查看内存使用情况,-m以MB为单位,-g可以使其以GB为单位
$ free -m
total used free shared buff/cache available
Mem: 3907 1117 778 3 2012 2503
Swap: 1897 708 1189要特别注意里面的free、buff/cache以及available,如下:
- free:系统空闲内存,一般来说,随着使用时间越来越长,Linux中free会越来越小,原因是Linux会把访问的文件数据尽可能地缓存在内存中,以便下次读取时能快速返回
- buff/cache:就是文件缓存到内存中所占内存的大小
- available:系统真正的可用内存,约等于
free+buff/cache,所以系统内存是否足够,你应该看available的值。
df
df命令可以很容易的看到文件系统的空间使用情况,如下:
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 1.9G 0 1.9G 0% /dev
tmpfs 391M 2.7M 389M 1% /run
/dev/sda1 276G 150G 115G 57% /
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock/dev/sda1的Use%这一列可以看到磁盘使用了57%了。
nicstat
nicstat可以查看整个网卡的使用情况,如下:
$ nicstat -z 1
Time Int rKB/s wKB/s rPk/s wPk/s rAvs wAvs %Util Sat
22:35:22 ens33 38.09 7.13 32.03 6.77 1217.8 1078.4 0.03 0.00
22:35:22 lo 0.07 0.07 0.36 0.36 207.6 207.6 0.00 0.00
Time Int rKB/s wKB/s rPk/s wPk/s rAvs wAvs %Util Sat
22:35:23 ens33 0.27 0.56 3.99 4.99 69.50 114.0 0.00 0.00
Time Int rKB/s wKB/s rPk/s wPk/s rAvs wAvs %Util Sat
22:35:24 ens33 0.21 0.34 3.00 3.00 72.67 116.7 0.00 0.00
Time Int rKB/s wKB/s rPk/s wPk/s rAvs wAvs %Util Sat
22:35:25 ens33 0.28 0.33 4.00 3.00 70.50 111.3 0.00 0.00
Time Int rKB/s wKB/s rPk/s wPk/s rAvs wAvs %Util Sat
22:35:26 ens33 0.34 0.34 5.00 3.00 69.20 116.7 0.00 0.00
Time Int rKB/s wKB/s rPk/s wPk/s rAvs wAvs %Util Sat
22:35:27 ens33 0.28 0.33 4.00 3.00 70.50 111.3 0.00 0.00其中%Util就是网卡带宽的使用率了。
分享一个快速查找「占用CPU较高问题代码」的shell脚本:https://raw.githubusercontent.com/xiaoxi666/scripts/main/show-busy-java-threads。线上机器直接wget下载执行(sh show-busy-java-threads)即可。默认会输出占用CPU最高的5个线程,也可自行设置参数。思路也是让机器快速执行多条命令,代替人工操作。
PS:脚本源于开源项目GitHub - Wekoi/awesome-scripts: useful scripts for Linux op,里面还有不少其他好用的脚本,有需要的同学可参考使用。