一、前置知识
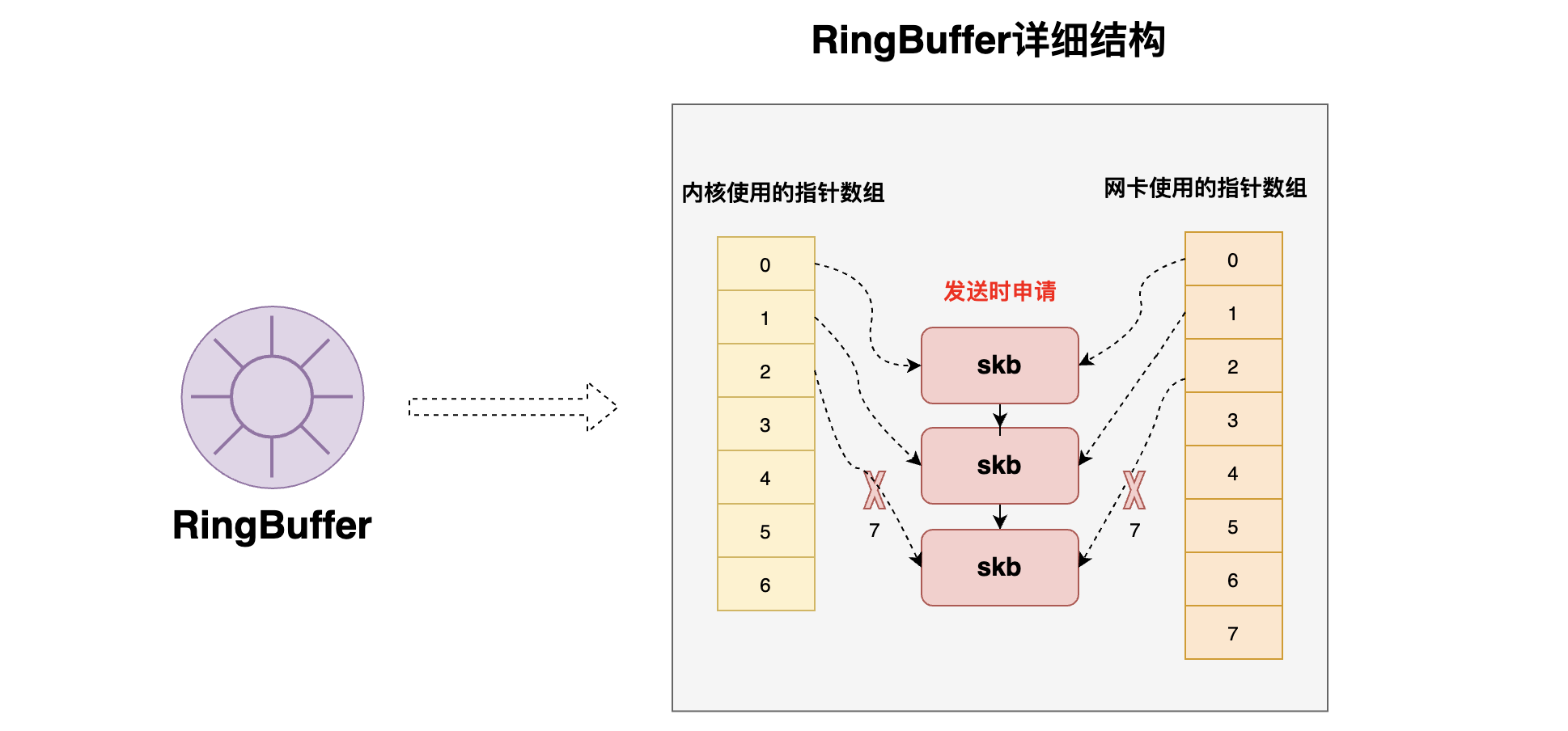
1、RingBuffer结构详解
关于RingBuffer网上有很多说法,有的人说RingBuffer是系统启动时就预先申请好的一个环形数组,有的人说RingBuffer是在接收或发送数据时才动态申请的一个环形数组,那么到底RingBuffer的结构是怎么样的呢?由下图可以看到
- 从宏观上讲RingBuffer可以笼统的称为【环形数组】
- 从RingBuffer的详细结构上来说,其实一个RingBuffer中包含了【两个环形数组】,这两个【环形数组】是系统启动时就预先分配好的
- 当有数据要接收或者发送时,当数据到达RingBuffer之前便会封装为一个个skb(比如:发送数据时,当数据到达【传输层】,此时就会将【socket发送队列】里的待发送的数据封装为一个个skb(也就是将socket发送队列里的数据copy一份,用skb封装)),此时该skb就是【动态申请】的内存空间。当skb到达RingBuffer的时候,此时会将数组的对应空位置指向这个待发送的skb
- 发送或接收数据都会将要发送的数据封装为一个个skb结构(也就是一个结构体),然后在接收 / 发送链路上都是对这个封装好的skb进行操作,而不是直接操作数据
- 关于【内核使用的指针数组】和【网卡使用的指针数据】
- 【内核使用的指针数组】是内核程序(包括ksoftirqd线程)所使用的数组(比如:内存程序会将skb放入到RingBuffer,此时指的RingBuffer就是RingBuffer中的【内核使用的指针数组】)
- 【网卡使用的指针数据】是网卡发送数据时所使用到的数组(比如:网卡发送数据时会从RingBuffer中获取要发送的数据,此时的RingBuffer指的就是【网卡使用的指针数据】中取skb来进行发送)
所以说,要说RingBuffer是预先分配的内存还是发送时动态分配的内存,需要对RingBuffer有充分的理解,不可人云亦云。

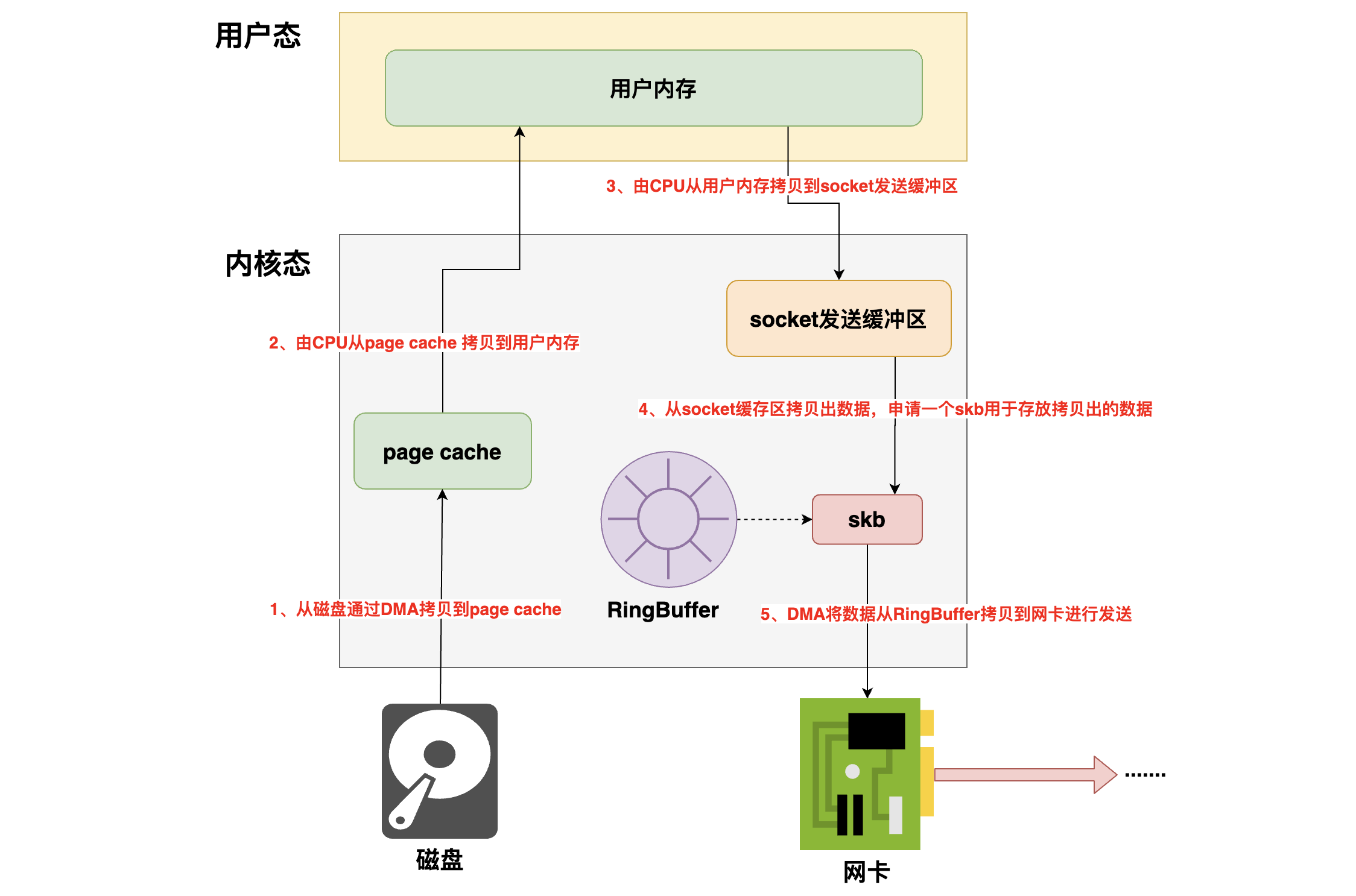
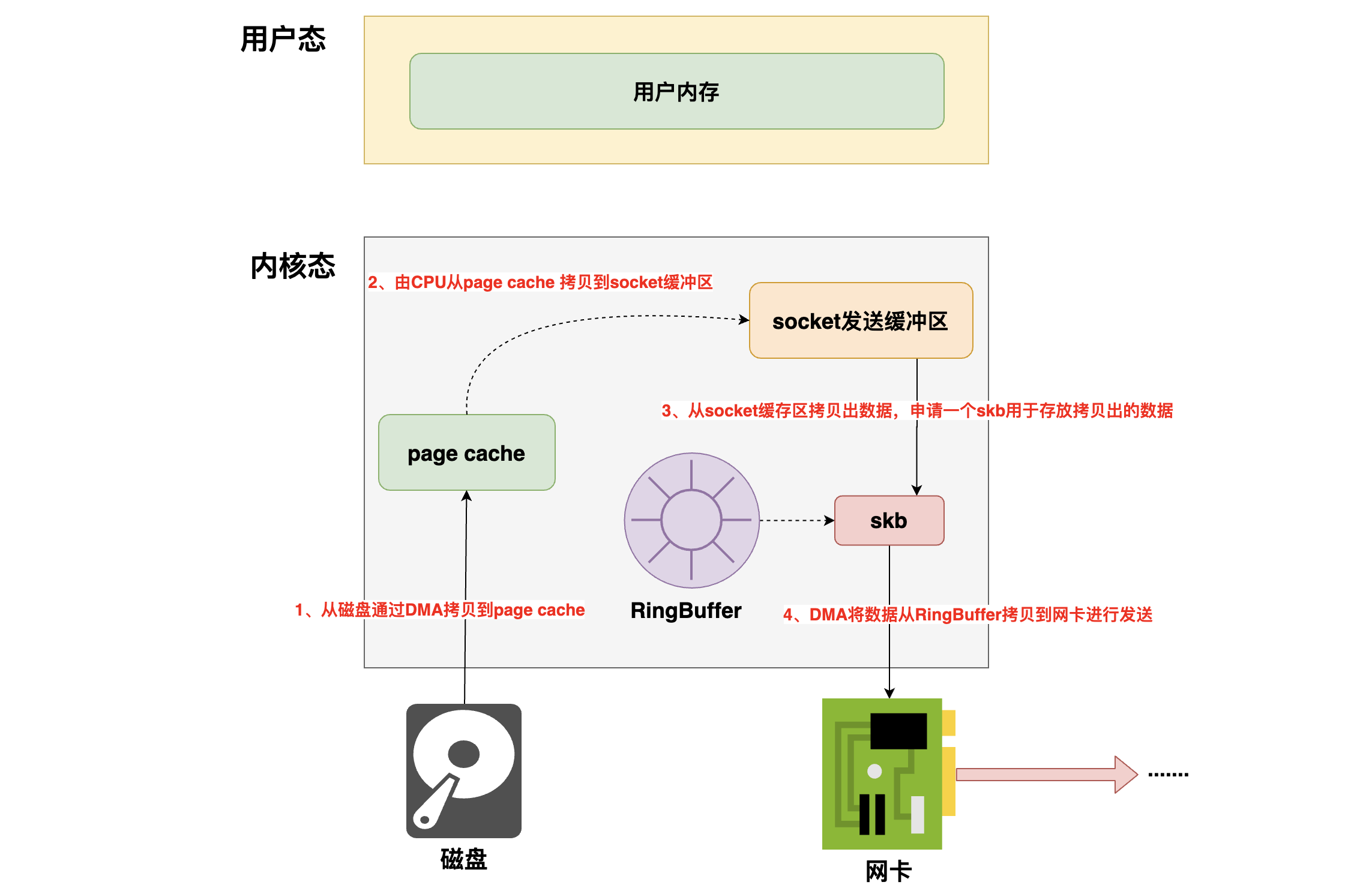
2、传统的数据发送与接收内存拷贝
- 首先由DMA先将要发送的数据从磁盘拷贝到操作系统的page cache中
- 然后由CPU将page cache中的数据拷贝到用户内存中
- 然后再由CPU将数据从用户内存中拷贝到socket缓冲区
- 然后再从socket发送缓冲区中拷贝出数据,然后申请一个skb,将数据挂在这个skb上
- skb的全称叫做
sk_buff,sk_buff缓冲区,是一个维护网络帧结构的双向链表,链表中的每一个元素都是一个网络帧。虽然 TCP/IP 协议栈分了好几层,但上下不同层之间的传递,实际上只需要操作这个数据结构中的指针,而无需进行数据复制。 - 这里是经过协议栈时做的操作,skb构建完成后就会将这个skb传递给传输层,网络层,直到最后的网卡队列的RingBuffer里都是在对这个skb进行操作
- skb的全称叫做
- 最后由DMA将数据(skb)从RingBuffer中取出送到网卡进行发送
可以看到这里第2步和第3步的拷贝明显有点多余了,能不能省掉呢?能,sendfile就是这么干的。
3、sendfile内存拷贝
- 首先由DMA先将要发送的数据从磁盘拷贝到操作系统的page cache中
- 然后由CPU将page cache中的数据直接拷贝到socket发送缓冲区(这里数据不会到达用户内存了)
- 然后再从socket发送缓冲区中拷贝出数据,然后申请一个skb,将数据挂在这个skb上
- 这里是经过协议栈时做的操作,skb构建完成后就会将这个skb传递给传输层,网络层,直到最后的网卡队列的RingBuffer里都是在对这个skb进行操作
- 最后由DMA将数据(skb)从RingBuffer中取出送到网卡进行发送
通过上面的两种发送数据时拷贝的对比,可以看出sendfile相比与传统的方式,一次数据发送流程中,少了一次【CPU拷贝】,两次【态的切换】,在需要发送的数据较大的情况下,这里便是性能的提升点。
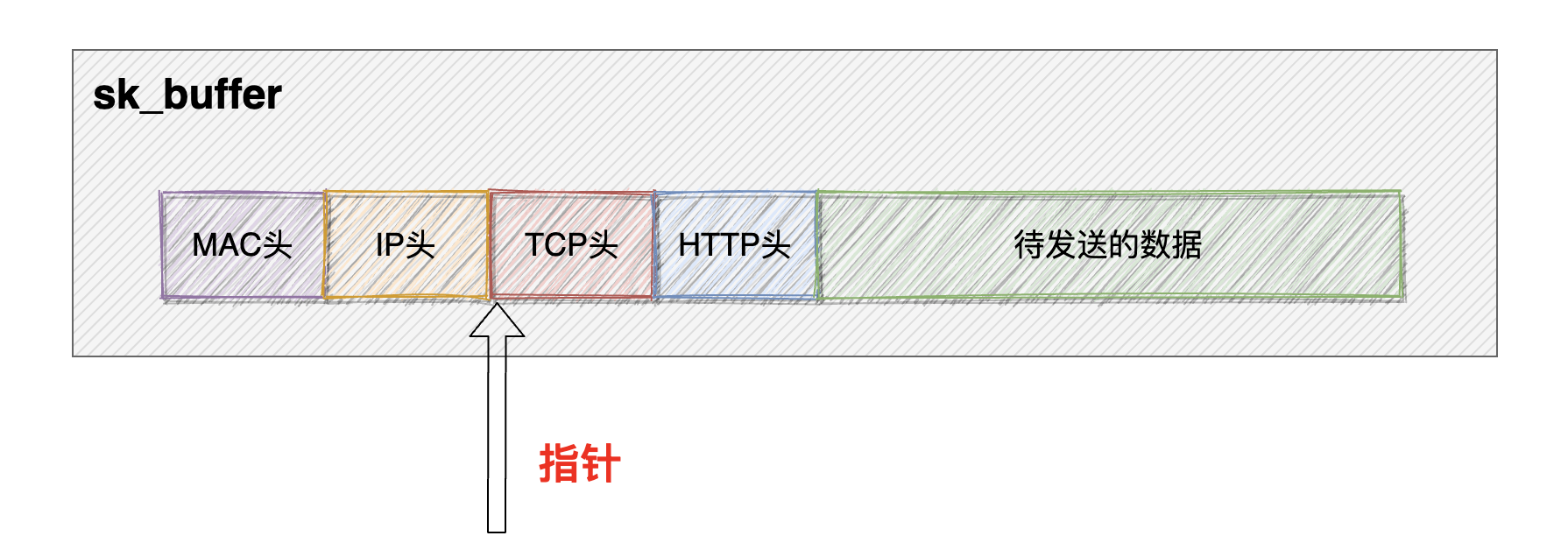
4、sk_buffer结构(skb)
sk_buffer简称skb,sk_buffer是Linux网络模块中的核心结构体各个层用到的数据包都存在这个结构体里。 skb内部其实包含了网络协议中所有的 header。比如在设置 TCP HEADER的时候,只是把指针指向 sk_buffer的合适位置。后面再设置 IP HEADER的时候,在把指针移动一下就行,避免频繁的内存申请和拷贝,效率很高。
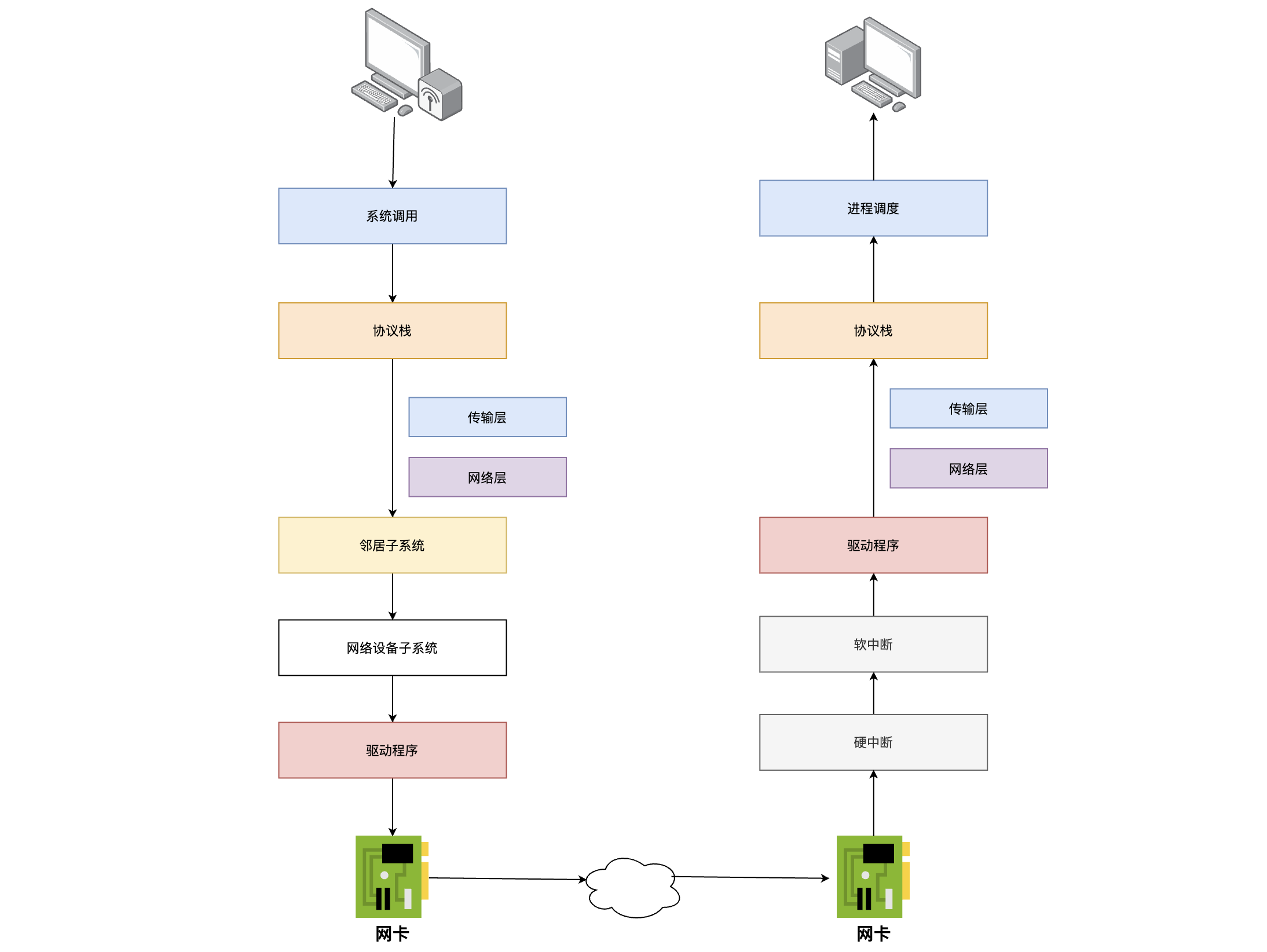
二、内核发送网络包流程
1、内核发送网络包简单流程
先上一个发送网络包的简单流程,以便于理解内核发送网络包的整体脉络!!!
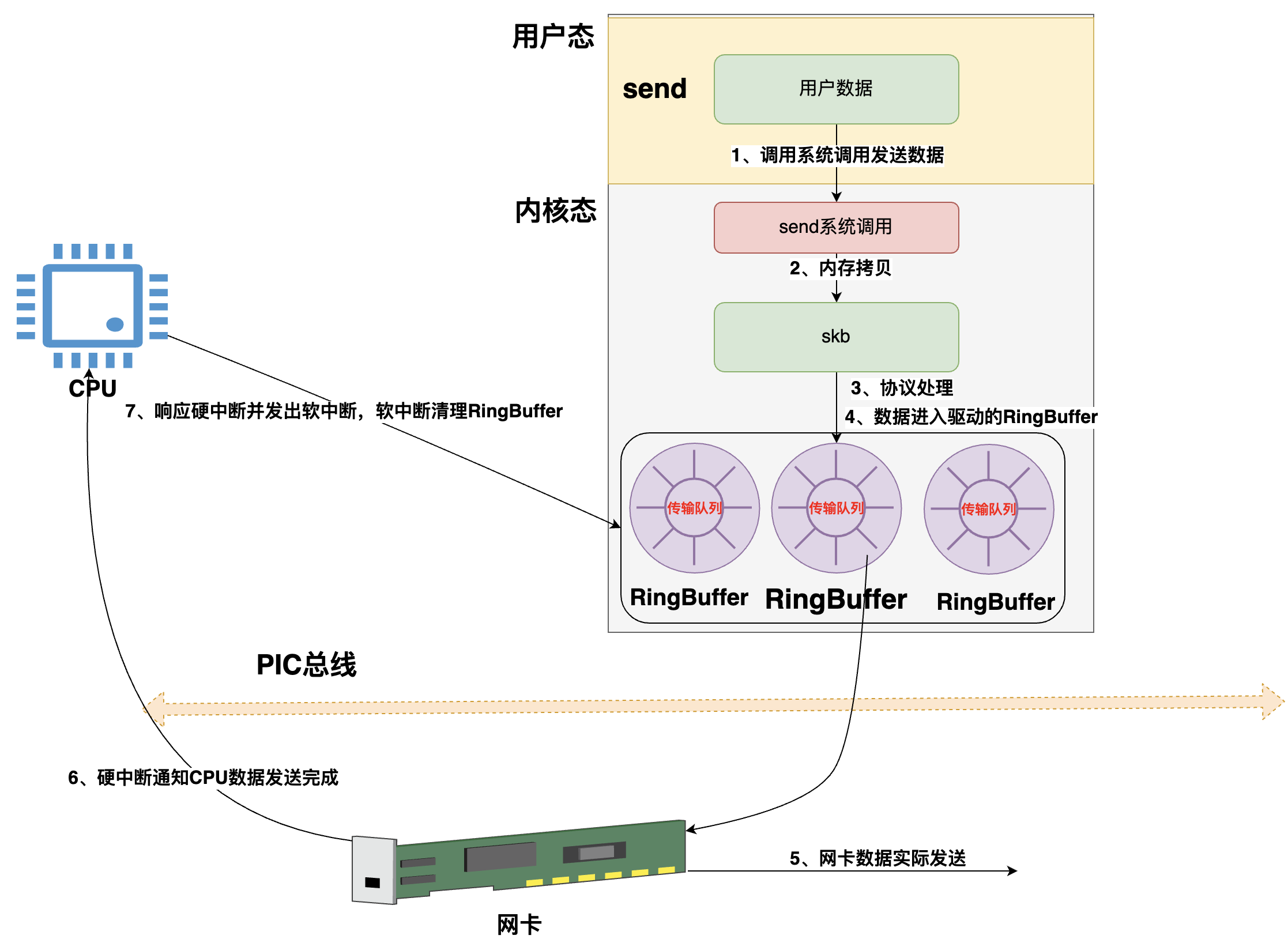
- 首先是在应用程序里调用【send方法】来将数据发送出去,此时便会触发【系统调用】来发送数据
- 将用户数据从【用户空间】拷贝到【内核空间】,并将数据封装为一个个【skb结构】(skb可以简单理解为一个封装待发送数据的数据结构,在内存层面待发送的数据都是以skb来表示并传递的)
- skb进入协议栈进行处理(分别经过传输层、网络层)
- 然后skb会被传送到网卡【
传输队列RingBuffer】里(网卡有多个队列,那么就有多个RingBuffer,并且每个队列对应一个发送队列一个接收队列) - 网卡将RingBuffer里面的数据真实的发送到网络上
- 当网卡发送完数据后,网卡会向CPU发出一个数据发送完毕的【硬中断】
- CPU响应该硬中断,找到硬中断处理函数,在硬中断处理函数里会发出软中断,然后由【内核线程ksoftirqd】去响应并处理软中断,【内核线程ksoftirqd】找到该软中断对应的处理函数(网卡驱动启动时注册的),然后进行调用,在处理函数中会清理RingBuffer
2、内核发送数据流程详解
以一个极简的伪代码表示我们在日常开发中如何发送数据包的,以便于理解内核发送数据包的整个流程
int main(){
// 创建一个socket对象,返回内核中socket的文件描述符(也就是内核socket对象的句柄)
fd = socket(fd,...);
// 该socket绑定IP和端口
bing(fd,....);
// socket监听端口
listen(fd,....);
// 等待客户端连接,用户连接后会在内核中创建代表该客户端的socket对象并且返回该socket的文件描述符cfd
cfd = accept(fd,...);
// 客户端连接后,处理用户请求
dosomething();
// 向客户端发送数据, cfd表示该客户端的socket对象的文件描述符,buf表示要发送的数据
// 【内核发送数据包流程就体现在这里】
send(cfd, buf, sizeof(buf), 0);
}
如果是用Java里的NIO来编写的话,大致代码流程如下:
public static void main() throws Exception {
// 创建服务端的socketchannel
ServerSocketChannel ssc = ServerSocketChannel.open();
// 设置这个ServerSocketChannel为阻塞(当有客户端连接请求并且和客户端建立连接成功后,下面的accept才继续向下执行)
ssc.configureBlocking(true);
// 阻塞接收客户端连接,客户端连接成功后会返回sc
SocketChannel sc = ssc.accept();
// 设置该客户端为阻塞的,方便演示
sc.configureBlocking(true);
// 申请一个byteBuffer
ByteBuffer buffer = ByteBuffer.allocate(16);
// 填充要发送的数据到byteBuffer中
buffer.put("hello world.".getBytes());
// 向该客户端发送数据,此时的发送过程就由内核来处理了
int write = sc.write(buffer);
}
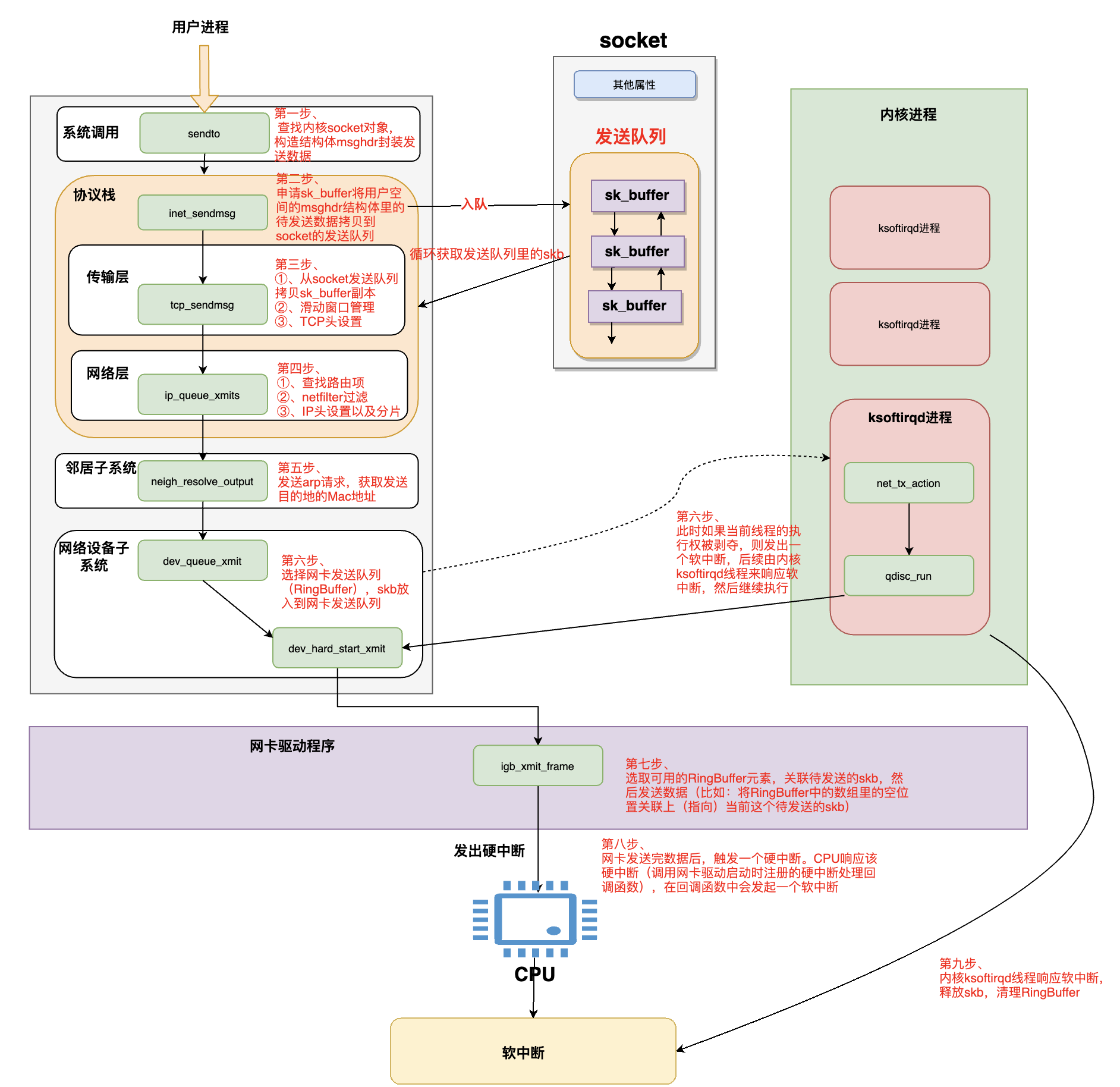
-
用户进程调用send方法开始发送数据,最终会调用到内核的
sendto方法 -
在【sendto方法】里会根据传入的【socket句柄】找到【内核中的socket对象】(比如:Java nio里通过Java的socket对象找到内核中对应的socket对象),
内核socket对象里记录着各种协议栈的函数地址。然后构造出struct msghdr对象,将用户空间中待发送的数据全部封装在这个struct msghdr结构体中。然后调用内核协议栈函数inet_sendmsg,发送流程进入内核协议栈处理。在进入到内核协议栈之后,内核会找到Socket上的具体协议的发送函数。在发送函数里会创建内核数据结构sk_buffer,将struct msghdr结构体中的发送数据拷贝到sk_buffer中。调用tcp_write_queue_tail函数获取Socket发送队列中的队尾元素,将新创建的sk_buffer添加到【内核socket对象的发送队列尾部】。发送流程走到这里,数据终于才从用户空间拷贝到内核空间了。但是此时能不能继续发送数据还得通过条件判断!- 【socket对象的发送队列】其实就是由
sk_buffer组成的一个双向链表 - 注意此时如果不满足发送条件(比如数据没有达到TCP滑动时间窗口的一半),则用户进程将数据拷贝到【socket的发送队列】里他的工作就算做完了,此时【内核socket对象的发送队列】里的数据会等到合适的时机进行发送
- 这里的满足条件是:socket发送缓冲区中未发送的数据是否已经超过TCP最大窗口的一半了,若满足则继续调用传输层
tcp_write_xmit函数进行处理,反之用户进程将数据拷贝到【socket发送队列】就算完了
- 【socket对象的发送队列】其实就是由
-
调用传输层(也就是调用传输层的实现方法,不要想的太神秘),在传输层的方法里会将【socket发送队列里的skb】拷贝一个skb副本(这里为什么要拷贝呢???),此处对【skb副本】还会进行如下处理:
- TCP滑动时间窗口管理、拥塞控制
- 给副本skb数据设置上TCP头
- **为什么不直接使用
Socket发送队列中的sk_buffer而是需要拷贝一份呢?**因为TCP协议是支持丢包重传的(可靠的传输协议),在没有收到对端的ACK之前,这个sk_buffer是不能删除的。内核每次调用网卡发送数据的时候,实际上传递的是sk_buffer的拷贝副本,当网卡把数据发送出去后,sk_buffer拷贝副本会被释放。当收到对端的ACK之后,Socket发送队列中的sk_buffer才会被真正删除。
-
调用网络层(也就是在传输层的实现方法里调用网络层的实现方法),将skb由传输层传递给网络层进行处理(其实就是调用方法然后通过方法参数传递skb而已),网络层主要会进行如下处理:
- 查找路由项,从本机路由表里通过目标IP查找路由项(总得知道要发到哪儿吧)
- 执行
netfilter过滤(比如:我们可以用iptables设置一些过滤规则,以过滤一些某些IP发来的或发送给某些IP的数据包) - 给待发送的skb数据设置IP头(这就是我们经常说的类似于一层层包快递)
- 此时,如果该skb的数据大小超过了【MTU】那么还会将该skb进行【分片处理】(也就是将skb数据拆分为多个skb,使得每个skb的大小都小于 MTU)。所以这里也是一个性能优化点,比如QQ会尽量控制一个skb的大小小于MTU,以节省skb分片的消耗,以及当skb被分为多个片后,只要其中一个片传输失败了,那么该skb的所有的分片都需要重传
-
调用到【邻居子系统】,该步主要是发送【ARP请求】,获取Mac地址
邻居子系统位于内核协议栈中的网络层和网络接口层之间,用于发送ARP请求获取MAC地址,然后将sk_buffer中的指针移动到MAC头位置,填充MAC头。- 经过【邻居子系统】的处理,现在
sk_buffer中已经封装了一个完整的数据帧,随后内核将【sk_buffer】交给网络设备子系统进行处理
-
调用到【网络设备子系统】,该步主要是选择网卡发送队列(网卡可能有多个队列),然后将skb放入到网卡的发送队列。这一步有可能会中断,然后将执行的进程由【用户进程】变为【内核进程】:
- 如果满足条件,则由用户进程继续向下执行,调用图示的
dev_hard_start_xmit方法继续执行 - 如果不满足条件,则会触发一个软中断,后续由响应该软中断的【内核ksoftirqd线程】来调用
dev_hard_start_xmit方法继续执行 - 这里可以看到【用户进程并不是调用完send就阻塞住了】,然后将一切工作交给内核线程帮忙处理。而是这个用户进程由用户态切换到了内核态然后继续执行的。我们常说的【Java中无法直接操作内核空间或硬件(比如控制鼠标)】,这个不是说我们的这个Java进程一旦要访问内核空间了就会将这个进程给park掉,然后委托操作系统进程进行处理。而是说虽然我们Java程序中没有办法直接访问内核空间(需要调用内核提供的接口),但是我们的进程可以执行内核代码呀,运行内核相关代码的时候可以由我们的进程进行运行呀。。。
- 如果满足条件,则由用户进程继续向下执行,调用图示的
-
调用到网卡驱动程序,选取可用的
RingBuffer位置(也就是RingBuffer中的数组里选取可用的位置),关联该位置和skb。然后【网卡驱动程序】通过DMA方式将数据通过【物理网卡】发送出去 -
当数据发送完毕后会触发一个【硬中断】,CPU响应该硬中断,吊起网卡驱动启动时向内核注册的该硬中断对应的处理函数,执行处理函数,在处理函数中最终会发起一个【软中断】
-
【内核线程ksoftirqd】响应并处理该软中断,该线程会吊起网卡启动时注册的【该类型的软中断】(有很多类型的软中断,他们都对应不同的处理函数)的处理函数,执行处理函数,在处理函数中会执行如下操作:
-
释放掉RingBuffer中的数组对skb的引用(注意:此时RingBuffer里的数组虽然放弃了对skb的引用,但是该skb并不会被立即清除,因为TCP有重传机制,必须要保证收到了对方的ack应答后再彻底删除该skb,如果没有收到对方的ack,那么传输层还可以重传该skb)
-
清理RingBuffer(以便于下次使用)
-
性能开销分析
- 应用程序调用send方法时,线程会从【用户态切换到内核态】,这里有一次上下文切换的开销
- sendto方法会构建
struct msghdr结构体,将要发送的数据都封装到struct msghdr结构体里,并且最终将struct msghdr结构体里的数据拷贝封装为一个个的【sk_buffer对象】并且将这个【sk_buffer对象】挂到socket的发送队列的尾部,这里有一次数据拷贝的开销(数据从用户空间拷贝到内核空间) - 到达协议栈后(比如传输层的
tcp_sendmsg函数),会将【socket发送队列】里的【sk_buffer对象】拷贝一个副本(为了保证TCP的可靠传输(也就是失败重传)),并将这个副本sk_buffer对象向后传递,这里有一次内核空间的拷贝开销 - 在网络层,如果
sk_buffer对象的大小超过了MTU,则还会将【sk_buffer对象】进行拆分,拆分为多个大小小于MTU的【sk_buffer对象】(将原来的sk_buffer里的数据拷贝到小的sk_buffer对象里) - 在第六步,选择网卡发送队列RingBuffer时,如果用户线程内核态
CPU quota用尽时会触发NET_TX_SOFTIRQ类型软中断,内核线程响应软中断的开销,并且由内核线程来继续调用dev_hard_start_xmit函数 - 在【网络设备子系统】中将
sk_buffer挂到网卡发送队列RingBuffer中时,此时只是操作RingBuffer里的对应的指针,将RingBuffer里的空闲位置的指针指向待发送的sk_buffer即可,这里没有拷贝开销 - 网卡发送完数据,向
CPU发送硬中断,CPU响应硬中断的开销。以及在硬中断中发送NET_RX_SOFTIRQ软中断执行具体的RingBuffer内存清理动作。内核响应软中断的开销。
所以,在网络数据发送流程中,一共发送了【一次上下文太态的切换】,两次数据拷贝(一次用户空间到内核空间,一次内核空间到内核空间的拷贝),如果skb大于MTU的话还有数据切分开销,两次硬中断和两次软中断开销
三、跨机网络通信总流程

![洛谷千题详解 | P1012 [NOIP1998 提高组] 拼数【C++、Java语言】](https://img-blog.csdnimg.cn/b5f590683bb94312b6a460f8bb018bb8.png)