简单介绍一下需求
-
能支持文件的上传,下载
-
要能根据关键字,搜索出文件,要求要能搜索到文件里的文字,文件类型要支持 word,pdf,txt
文件上传,下载比较简单,要能检索到文件里的文字,并且要尽量精确,这种情况下很多东西就需要考虑进去了。这种情况下,我决定使用 Elasticsearch 来实现。
因为准备找工作刷牛客的原因,发现很多面试官都问到了 Elasticsearch,再加上那时候我连 Elasticsearch 是什么东西都不知道,所以就决定尝试一下新东西。不得不说 Elasticsearch 版本更新的是真的快,前几天才使用了 7.9.1,结果 25 号就出来了 7.9.2 版本。
Elasticsearch 简介
Elasticsearch 是一个开源的搜索文献的引擎,大概含义就是你通过 Rest 请求告诉它关键字,他给你返回对应的内容,就这么简单。
Elasticsearch 封装了 Lucene,Lucene 是 apache 软件基金会一个开放源代码的全文检索引擎工具包。Lucene 的调用比较复杂,所以 Elasticsearch 就再次封装了一层,并且提供了分布式存储等一些比较高级的功能。
基于 Elasticsearch 有很多的插件,我这次用到的主要有两个,一个是 kibana,一个是 Elasticsearch-head。
-
kibana 主要用来构建请求,它提供了很多自动补全的功能。
-
Elasticsearch-head 主要用来可视化 Elasticsearch。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能。
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
开发环境
首先安装 Elasticsearch,Elasticsearch-head,kibana,三个东西都是开箱即用,双击运行 。需要注意的是 kibana 的版本要和 Elasticsearch 的版本对应。
Elasticsearch-head 是 Elasticsearch 的可视化界面,Elasticsearch 是基于 Rest 风格的 API 来操作的,有了可视化界面,就不用每次都使用 Get 操作来查询了,能提升开发效率。
Elasticsearch-head 是使用 node.js 开发的,在安装过程中可能会遇到跨域的问题:Elasticsearch 的默认端口是 9200,而 Elasticsearch-head 的默认端口是 9100,需要改一下配置文件,具体怎么改就不详细说啦,毕竟有万能的搜索引擎。
Elasticsearch 安装完成之后,访问端口,就会出现以下界面。
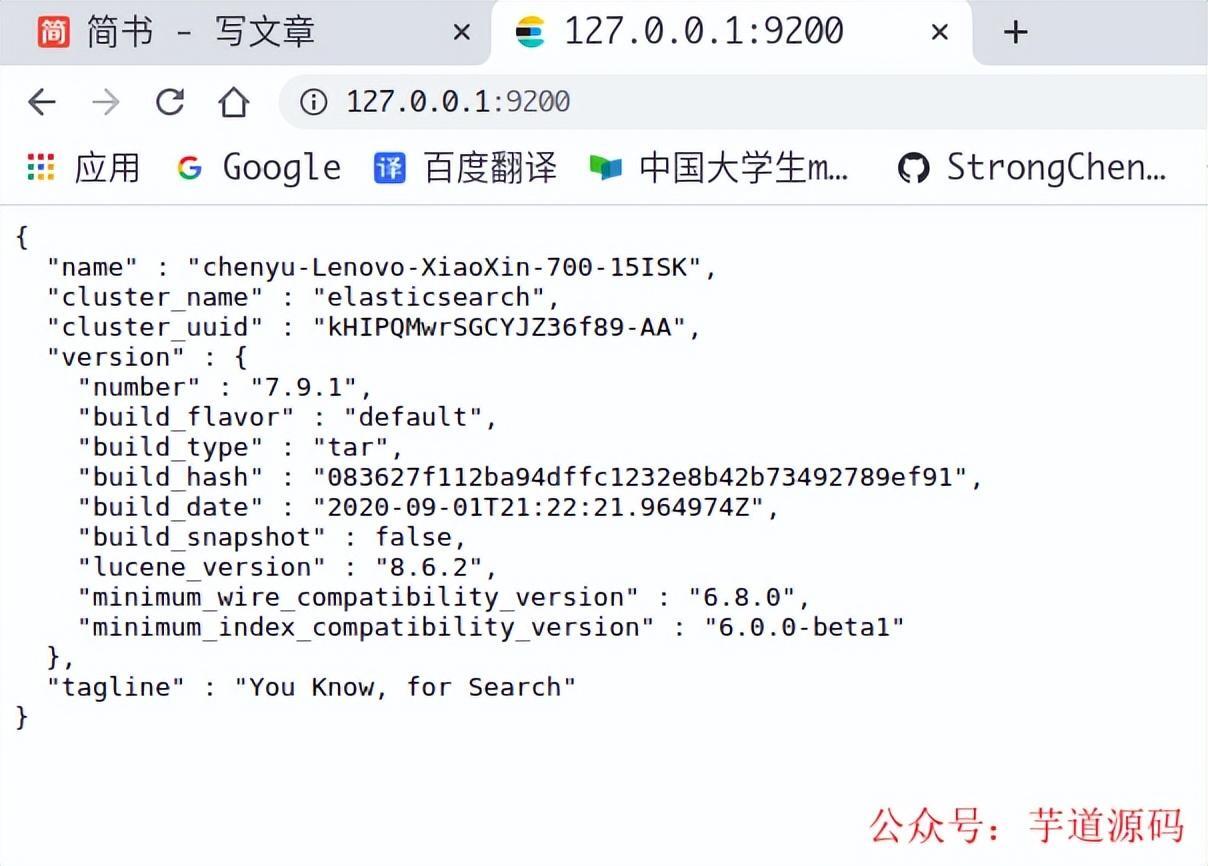
Elasticsearch 主页面
基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
项目地址:https://github.com/YunaiV/onemall
核心问题
有两个需要解决的核心问题,文件上传和输入关键词查询。
文件上传
首先对于 txt 这种纯文本的形式来说,比较简单,直接将里面的内容传入即可。但是对于 pdf,word 这两种特殊格式,文件中除了文字之外有很多无关的信息,比如图片,pdf 中的标签等这些信息。这就要求对文件进行预处理。
Elasticsearch5.x 以后提供了名为 ingest node 的功能,ingest node 可以对输入的文档进行预处理。如图,PUT 请求进入后会先判断有没有 pipline,如果有的话会进入 Ingest Node 进行处理,之后才会正式被处理。
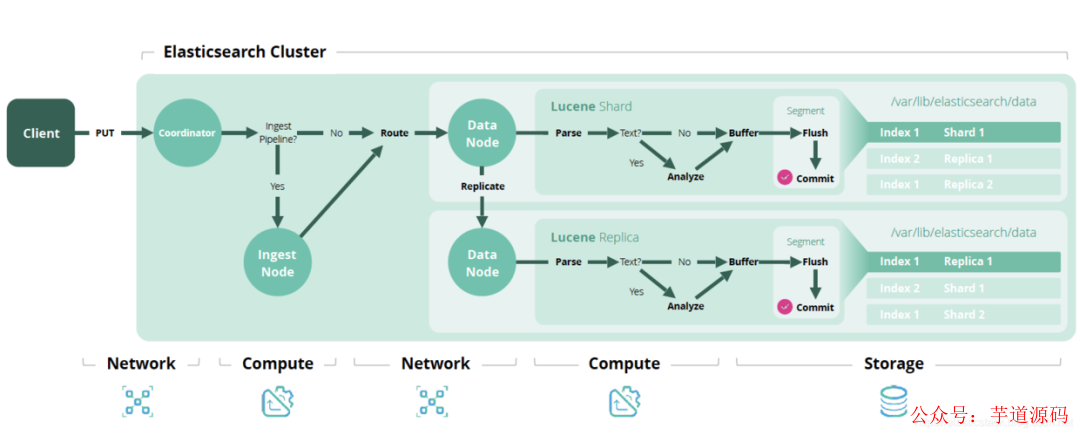
引用自 Elastic 中国社区官方博客
Ingest Attachment Processor Plugin 是一个文本抽取插件,本质上是利用了 Elasticsearch 的 ingest node 功能,提供了关键的预处理器 attachment。在安装目录下运行以下命令即可安装。
./bin/elasticsearch-plugin install ingest-attachment复制代码
定义文本抽取管道
PUT /_ingest/pipeline/attachment{"description": "Extract attachment information","processors": [{"attachment": {"field": "content","ignore_missing": true}},{"remove": {"field": "content"}}]}
复制代码
在 attachment 中指定要过滤的字段为 content,所以写入 Elasticsearch 时需要将文档内容放在 content 字段。
运行结果如图:
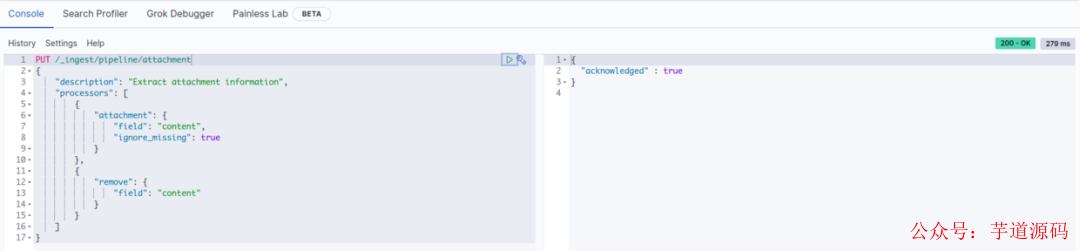
定义文本抽取管道
建立文档结构映射
文本文件通过预处理器上传后以何种形式存储,我们需要建立文档结构映射来定义。PUT 定义文档结构映射的时候就会自动创建索引,所以我们先创建一个 docwrite 的索引,用于测试。
PUT /docwrite{"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word"},"type":{"type": "keyword"},"attachment": {"properties": {"content":{"type": "text","analyzer": "ik_smart"}}}}}}
复制代码
在 ElasticSearch 中增加了 attachment 字段,这个字段是 attachment 命名 pipeline 抽取文档附件中文本后自动附加的字段。这是一个嵌套字段,其包含多个子字段,包括抽取文本 content 和一些文档信息元数据。
同是对文件的名字 name 指定分析器 analyzer 为 ik_max_word,以让 ElasticSearch 在建立全文索引时对它们进行中文分词。

建立文档结构
测试
经过上面两步,我们进行简单的测试。因为 ElasticSearch 是基于 JSON 格式的文档数据库,所以附件文档在插入 ElasticSearch 之前必须进行 Base64 编码。先通过下面的网站将一个 pdf 文件转化为 base64 的文本。PDF to Base64
测试文档如图:

测试文档
然后通过以下请求上传上去,我找了一个很大的 pdf 文件。需要指定的是我们刚创建的 pipeline,结果如图所示。
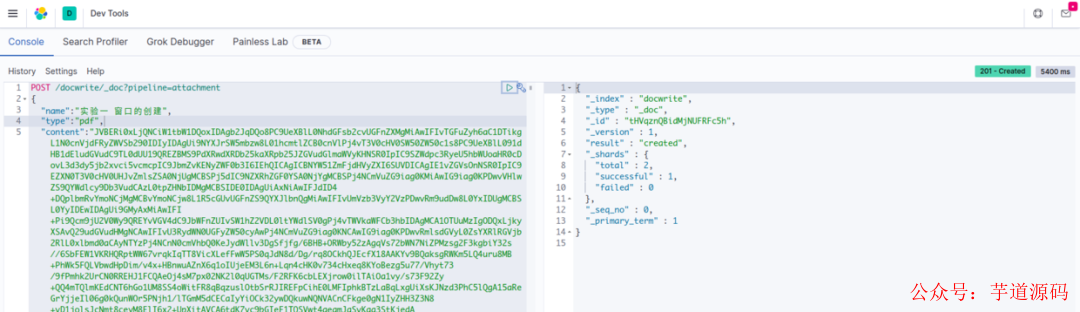
文件上传测试
原来的索引有个 type 类型,新版本后面会被弃用,默认的版本都是_doc
然后我们通过 GET 操作看看我们的文档是否上传成功。可以看到已经被解析成功。
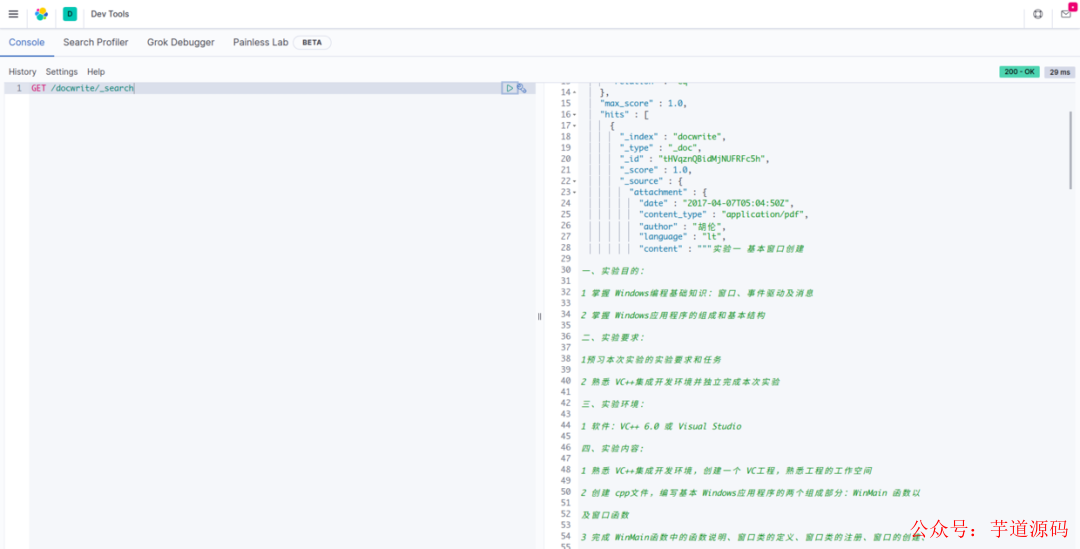
文件上传结果查看
如果不指定 pipline 的话,就会出现无法解析的情况。
没有指定 pipeline 的情况
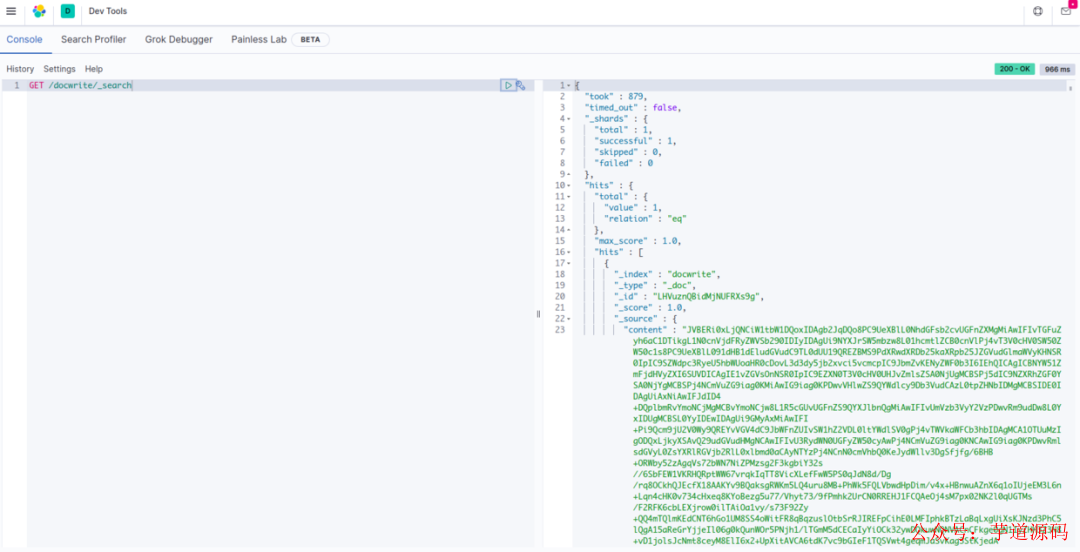
根据结果我们看到,我们的 PDF 文件已经通过我们自行定义的 pipline,然后才正式进入索引数据库 docwrite。
关键字查询
关键字查询即对输入的文字,能进行一定的分词处理。比如说对于“数据库计算机网络我的电脑”这一串词来说,要能将其分为“数据库”,“计算机网络”,“我的电脑”三个关键词,然后分别根据关键字查询。
Elasticsearch 自带了分词器,支持所有的 Unicode 字符,但是它只会做最大的划分,比如对于进口红酒这四个字,会被分为“进”,“口”,“红”,“酒”这四个字,这样查询出来的结果就会包括“进口”,“口红”,“红酒”。
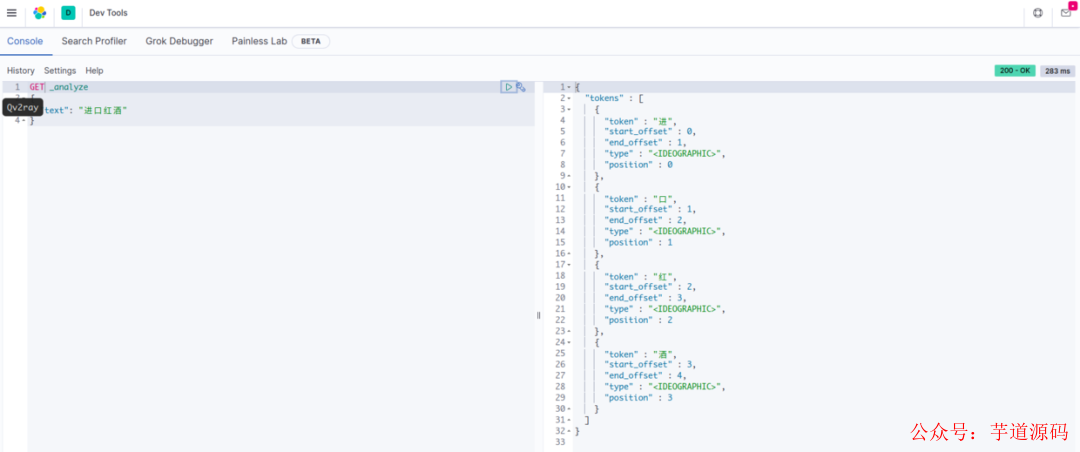
默认分词器
这并不是我们想要的结果。我们想要的结果是,只分为“进口”,“红酒”这两段,然后查询相应的结果。这就需要使用支持中文的分词器了。
ik 分词器
ik 分词器是开源社区比较流行的中文分词插件,我们首先安装 ik 分词器,注意以下代码不能直接使用。
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/...这里找你的版本
复制代码
ik 分词器包括两种模式。
-
ik_max_word 会把中文尽可能地拆分。
-
ik_smart 会根据常用的习惯进行划分,比如"进口红酒”会被划分为“进口”,“红酒”。
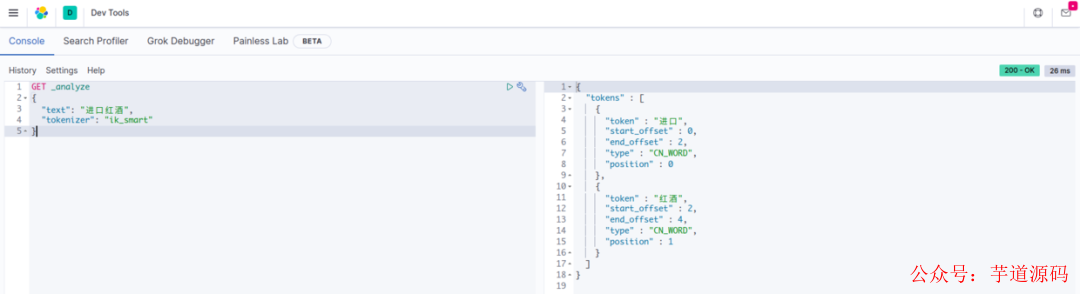
ik_smart 模式
我们使用在查询时,指定 ik 分词器进行查询文档,比如对于插入的测试文档,我们使用 ik_smart 模式搜索,结果如图。
GET /docwrite/_search{"query": {"match": {"attachment.content": {"query": "实验一","analyzer": "ik_smart"}}}}
复制代码
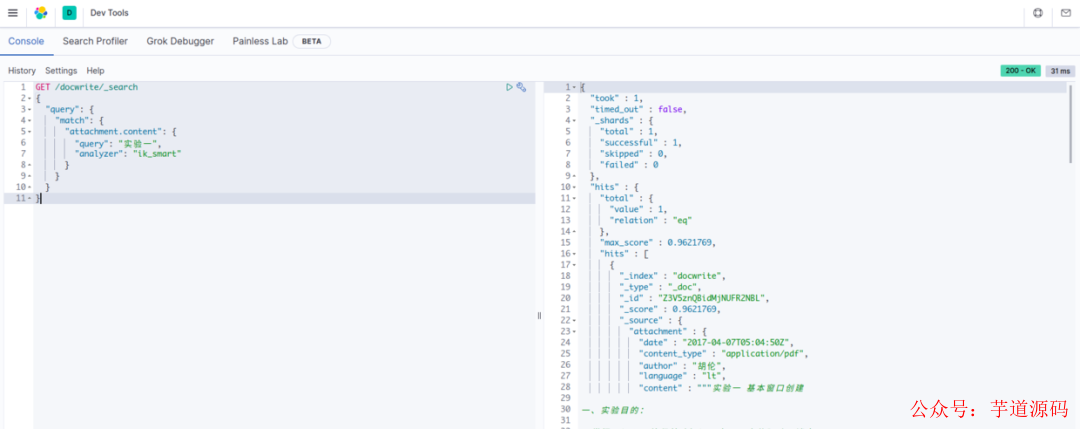
搜索文章
我们可以指定 Elasticsearch 中的高亮,来为筛选到的文字添加标签。这样的话文字前后都会被添加上标签。如图。
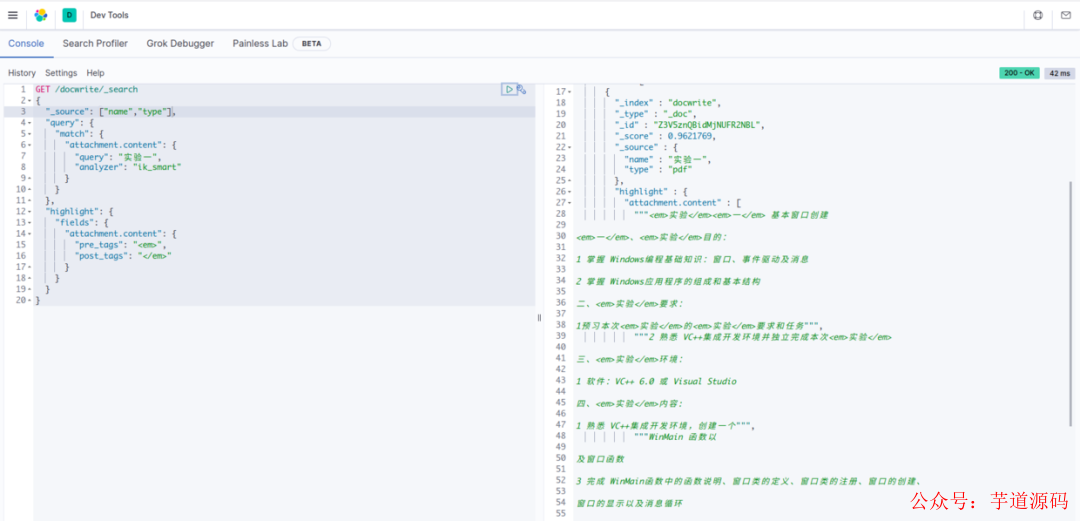
highlight 效果
编码
编码使用 Idea+maven 的开发环境,首先导入依赖,依赖一定要与 Elasticsearch 的版本相对应。
导入依赖
Elstacisearch 对于 Java 来说有两个 API,我们使用的封装的比较完善的高级 API。<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.9.1</version> </dependency>
文件上传
先建立一个与上文对应的 fileObj 对象
public class FileObj {String id; //用于存储文件idString name; //文件名String type; //文件的type,pdf,word,or txtString content; //文件转化成base64编码后所有的内容。}
复制代码
首先根据上文所诉,我们要先将文件以字节数组的形式读入,然后转化成 Base64 编码。
public FileObj readFile(String path) throws IOException {//读文件File file = new File(path);FileObj fileObj = new FileObj();fileObj.setName(file.getName());fileObj.setType(file.getName().substring(file.getName().lastIndexOf(".") + 1));byte[] bytes = getContent(file);//将文件内容转化为base64编码String base64 = Base64.getEncoder().encodeToString(bytes);fileObj.setContent(base64);return fileObj;}
复制代码
java.util.Base64 已经提供了现成的函数 Base64.getEncoder().encodeToString 供我们使用。
接下来就可以使用 Elasticsearch 的 API 将文件上传了。
上传需要使用 IndexRequest 对象,使用 FastJson 将 fileObj 转化为 Json 后,上传。需要使用 indexRequest.setPipeline 函数指定我们上文中定义的 pipline。这样文件就会通过 pipline 进行预处理,然后进入 fileindex 索引中。
public void upload(FileObj file) throws IOException {IndexRequest indexRequest = new IndexRequest("fileindex");//上传同时,使用attachment pipline进行提取文件indexRequest.source(JSON.toJSONString(file), XContentType.JSON);indexRequest.setPipeline("attatchment");IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println(indexResponse);}
复制代码
文件查询
文件查询需要使用 SearchRequest 对象,首先我要指定对我们的关键字使用 ik 分词器的 ik_smart 模式分词
SearchSourceBuilder srb = new SearchSourceBuilder();srb.query(QueryBuilders.matchQuery("attachment.content", keyword).analyzer("ik_smart"));searchRequest.source(srb);
复制代码
之后我们就可以通过返回的 Response 对象获取每一个 hits,之后获取返回的内容。
Iterator<SearchHit> iterator = hits.iterator();int count = 0;while (iterator.hasNext()) {SearchHit hit = iterator.next();}
复制代码
Elasticsearh 一个非常强大的功能是文件的高亮(highlight)功能,所以我们可以设置一个 highlighter,对查询到的文本进行高亮操作。
HighlightBuilder highlightBuilder = new HighlightBuilder();HighlightBuilder.Field highlightContent = new HighlightBuilder.Field("attachment.content");highlightContent.highlighterType();highlightBuilder.field(highlightContent);highlightBuilder.preTags("<em>");highlightBuilder.postTags("</em>");srb.highlighter(highlightBuilder);
复制代码
我设置了前置<em></em>标签对对查询的结果进行包裹。这样查询到的结果中就会包含对应的结果。
多文件测试
简单的 demo 写好了,但是效果怎么样还需要使用多个文件进行测试。这是我的一个测试文件夹,里面下面放了各种类型的文件。
将这个文件夹里面的全部文件上传之后,使用 elestacisearch``-head 可视化界面查看导入的文件。
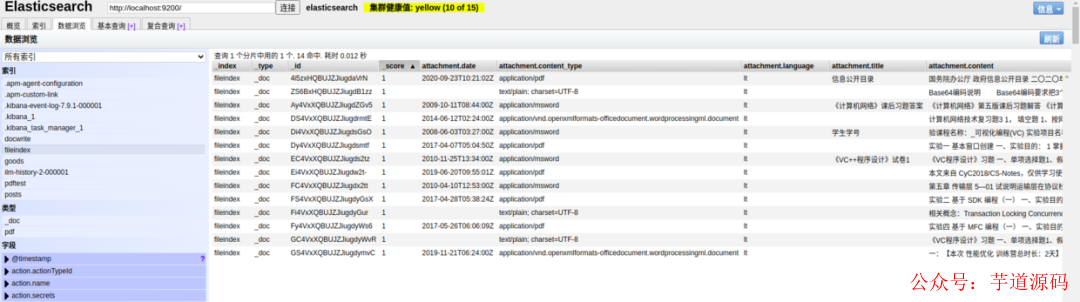
导入的文件
搜索代码:
/** * 这部分会根据输入的关键字去查询数据库中的信息,然后返回对应的结果 * @throws IOException */ @Test public void fileSearchTest() throws IOException { ElasticOperation elo = eloFactory.generate(); elo.search("数据库国务院计算机网络"); }
运行我们的 demo,查询的结果如图所示。
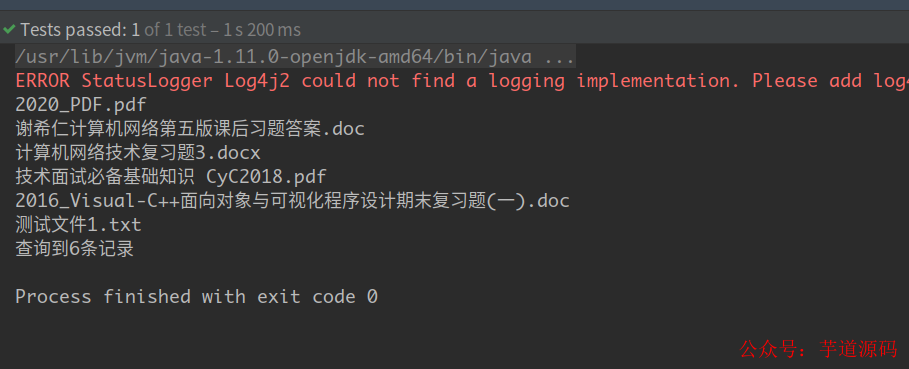
搜索结果
还存在的一些问题
1. 文件长度问题
通过测试发现,对于文本内容超过 10 万字的文件,elasticsearch 只保留 10w 字,后面的就被截断了,这就需要进一步了解 Elasticsearch 对 10w 字以上的文本的支持。
2. 编码上的一些问题
我的代码中,是将文件全部读入内存之后,在进行一系列的处理 ,毫无疑问,必定会带来问题,比如假如是一个超出内存的超大文件,或者是若干个大文件,在实际生产环境中,文件上传就会占用服务器的相当一大部分内存和带宽,这就要根据具体的需求,做进一步的优化。
![洛谷千题详解 | P1012 [NOIP1998 提高组] 拼数【C++、Java语言】](https://img-blog.csdnimg.cn/b5f590683bb94312b6a460f8bb018bb8.png)