文章目录
- 一、对UDP协议的感性认识
- 简介
- 主要特点
- 二、UDP的报文结构
- 协议端格式概览
- 报文结构详解
- 源端口
- 目的端口
- 16位UDP报文长度
- 16位校验和
- 参考
一、对UDP协议的感性认识
简介
UDP,是User Datagram Protocol的简称,中文名是用户数据报协议,是OSI和TCP/IP协议族参考模型中的一种无连接的传输层模型。
UDP有不提供数据包分组、组装和不能对数据包进行排序的缺点,也就是说,当报文发送之后,是无法得知其是否安全完整到达的。UDP用来支持那些需要在计算机之间传输数据的网络应用。包括网络视频会议系统在内的众多的客户/服务器模式的网络应用都需要使用UDP协议。
UDP协议从问世至今已经被使用了很多年,虽然其最初的光彩已经被一些类似协议所掩盖,但即使在今天UDP仍然不失为一项非常实用和可行的网络传输层协议。许多应用只支持UDP,如:多媒体数据流,不产生任何额外的数据,即使知道有破坏的包也不进行重发。**当强调传输性能而不是传输的完整性时,如:音频和多媒体应用,UDP是最好的选择。**在数据传输时间很短,以至于此前的连接过程成为整个流量主体的情况下,UDP也是一个好的选择。
主要特点
无连接、不可靠传输、面向数据报、全双工。
其中在之间的网络编程之套接字 UDP一文中,我已就UDP的无连接、面向数据包、全双工做了解释。所以这里我们需要重点解决的问题就是如何理解UDP的不可靠传输。
要想理解这个特点,我们就需要剖析好UDP的报文结构以及内部的一些原理。
二、UDP的报文结构
协议端格式概览
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M4KO04uJ-1676885461888)(F:\typora插图\image-20230220165606281.png)]](https://img-blog.csdnimg.cn/ac78f15236c949eca0fc04023f80e155.png)
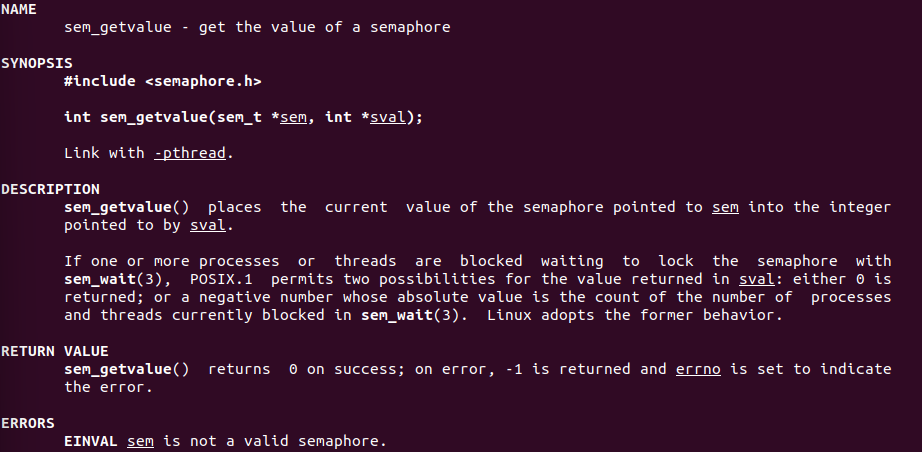
这里报头每个字段都是使用两个字节描述,也就是说UDP的报头是8个字节。
报文结构详解
源端口
我们已经知道一次完整的网络通信,有一个通信五元组:源ip、源端口、目的ip、目的端口、协议号(进程要封装、解析的数据报的数据格式)。
这里边,UDP的包头就体现了,源端口就是发送方的端口号。
目的端口
顾名思义,接收方的端口号。
16位UDP报文长度
这个字段表示的长度不是UDP载荷 的长度,而是整个UDP报文的长度。
216=65536,也就是说16位表示的范围是0~65535(长度是非负数),也就是说64kb(210=1kb,2^6*10kb=64kb)。但是我们日常生活的数据一般是很大的,如果来自上层即应用层的数据报,超过了64kb怎么办?
对此,我们有两种解决办法
1.我们首先要知道,应用层代码是程序员自己根据业务编写的。所以,我们可以在应用层的代码层面上,对应用层的数据进行手动分包,拆分成多个UDP数据包进行传输。
2.不使用UDP,使用TCP。TCP对数据报的长度没有限制。
很显然,我们自己手动分包会衍生出来很多问题,所以这种情况下,我们是不使用UDP的。
16位校验和
校验和的作用是为了验证传输的数据是否是正确的。
网络传输过程中,很可能会受到一些干扰,在这些干扰下,可能出现“比特翻转”的情况。(比特翻转即1变0,0变1).
为什么可能会收到一些干扰,因为最终这些信息都需要转换成光信号/电信号进行传输,很可能会受到一些物理环境影响,比如电场、磁场或者高能射线等。
一旦发生比特翻转,很可能带来致命的打击。
校验和就不能降低数据发生比特翻转的概率,但是它能够很大程度上告诉我们它已经翻转了,这个数据已经脏了,我们不能使用。
校验和是针对数据内容进行一些列的数学运算,得到一个比较短的结果。
如果传输前后数据内容一直,得到的校验结果一定;
如果数据变了,得到的校验结果大概率也变了。
注意:校验和一致,也不代表着中间没有发生比特翻转。理论上存在,但是工程上我们将这种特殊情况忽略不计。
以上便是关于校验和,我们需要重点理解的东西。下边我们简单说几个比较知名的计算校验和的算法。
1.CRC:循环冗余校验。特点是简单粗暴,但是校验效果不佳。每个字节循环累加,溢出的高位舍去。
2.MD5:有一系列公式进行复杂运算。特点是定长、冲突概率小、不可逆。这里的定长是指无论原始数据多长,得到的MD5值都是固定长(4/8Byte)。冲突概率小是因为原数据只要改变一个地方,MD5值都会变化很大,冲突的概率极小。不可逆是通过原始数据计算很容易,通过MD5还原成原始数据很难,理论上不可实现,计算量极大。
应用:校验和、作为哈希值的获取方式、加密
3.SHAI:与MD5类似,但是计算方法不同
参考
UDP简介