一、缓存
定义:可以更快的读取数据的介质。一般用来存储临时数据,常用介质的是读取数据很快的内存。
缓存场景:
1、博客列表页
2、电商商品详情页
场景特点:缓存的地方,数据变动频率较少
1、数据库缓存
当把一次负责查询的结果直接存储到表里,比如多个条件的过滤查询结果,可避免重复进行复杂查询,提升效率。
CACHES = {
'default':{
'BACKEND':'django.core.cache.backends.db.DatabaseCache',
'LOCATION':'my_cache_table',
'TIMEOUT':300, #缓存保存时间,单位秒,默认值300
'OPTIONS':{
'MAX_ENTRIES':300,#缓存最大数据条数
'CULL_FREQUENCY':2,#缓存条数达到最大值时,删除1/x的缓存数据
}
}
}
终端执行python manage.py createcachetable
(1)整体缓存
方式1:视图函数
from django.views.decorators.cache import cache_page
@cache_page(30) # 单位s
def my_view(request):
pass
方式2:路由中
from django.views.decorators.cache import cache_page
urlpatterns = [
path('foo/',cache_page(60)(my_view))
]
(2)局部缓存
引入cache对象
方式1:使用caches[‘CACHE’配置key’](适合有多个缓存配置项的情况)
from django.core.cache import caches
cache1 = caches['myalias']
方式2:from django.core.cache import cache 相当于直接引入CACHES配置项中的’default’项
缓存api的使用:
1、存储缓存:cache.set(key,value,timeout)
- key:缓存的key,字符串类型
- value:python对象
- timeout:缓存时间s,默认为配置项中的TIMEOUT值
- 返回值:None
2、获取缓存:cache.get(key)
- key:缓存的key
- 返回值:为key的具体值,若没有值则返回None
3、存储缓存:cache.add(key,value) 只在key不存在时生效
- 返回值:True or False
4、存储缓存:cache.get_or_set(key,value,value) 若未获取到,则执行set
- 返回值:value
5、批量存储缓存:cache.set_many(dict,value)
- 返回值:插入不成功的key的数组
6、批量获取缓存:cache.get_many(key_list)
- 返回值:取到的key和value的字典
7、删除缓存:cache.delete(key)
- 返回值:None
8、批量删除缓存:cache.delete_many(key_list)
- 返回值:None
2、本地内存缓存
主要用于测试,使用频率不高
CACHES = {
'default':{
'BACKEND':'django.core.cache.backends.locmem.LocMemCache',
'LOCATION':'unique-snowflake',
}
3、文件系统缓存
缓存数据存储到本地文件中,不推荐用
CACHES = {
'default':{
'BACKEND':'django.core.cache.filebased.locmem.FileBasedCache',
'LOCATION':'文件夹路径',
}
4、浏览器缓存
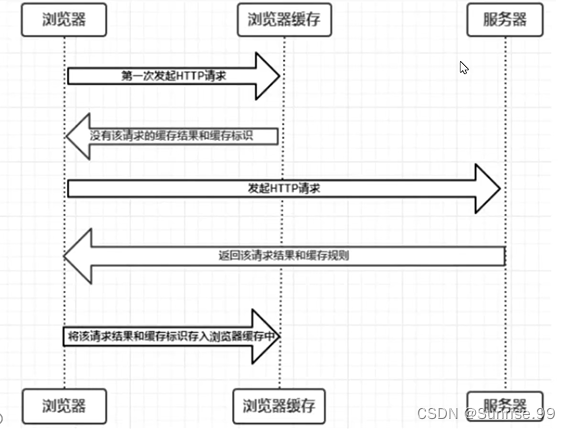

cache装饰器可以自动给浏览器添加响应头。


此方法只根据时间判断,不够严谨,故常用后者

二、中间件
以类的形式体现,是Django请求/响应处理的钩子框架,是一个轻量级的、低级的“插件”系统,用于全局改变Django的输入输出。每一个中间件负责做一些特定的功能。
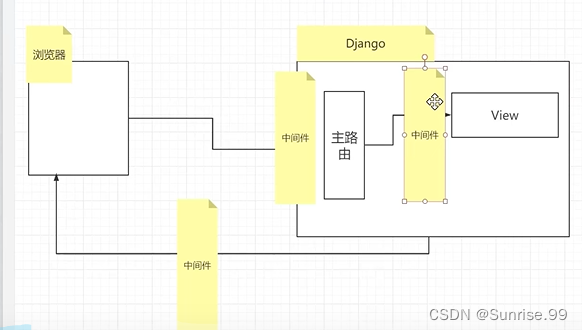
1、中间件编写
- 继承自
django.utils.deprecation.MiddlewareMixin类 - 必须实现下列五个方法中的一个或多个:
process_request(self,request)执行路由前被调用,在每个请求上调用,返回None或HttpResponse对象process_view(self,request,callback,callback_args,callback_kwargs)调用视图函数前被调用,在每个请求上调用,返回None或HttpResponse对象process_response(self,request,response)响应返回浏览器前被调用,在每个请求上调用,返回HttpResponse对象process_exception(self,request,exception)当处理过程中抛出异常时调用,返回一个HttpResponse对象process_template_response(self,request,response)在视图函数执行完毕且试图返回的对象中包含render的方法时被调用,需要返回实现了render方法的响应对象。
2、注册中间件
1、settings.py中注册自定义的中间件MIDDLEWARE= ['middleware.mymiddleware.MyMW',]
2、在项目目录下创建middleware文件夹
3、编写mymiddleware.py
from django.utils.deprecation import MiddlewareMixin
class MyMW(MiddlewareMixin):
def process_request(self,request):
print('MyMW precess_request doing -- ')
def process_view(self,request,callback,callback_args,callback_kwargs):
print('MyMW process_view doing -- ')
def process_response(self,request,response):
print('MyMW process_response doing -- ')
return response
进入视图函数前,按照中间件注册顺序执行;在视图函数之后,中间件按照逆序调用的。
3、练习
用中间件实现强制某个IP地址只能向/test开头的地址发送5次请求。
request.META['REMOTE_ADDR']可以得到远程客户端的IP地址。
request.path_info可以得到客户端访问的请求路由信息。
class VisitLimit(MiddlewareMixin):
visit_times={}
def process_request(self,request):
ip_address = request.META['REMOTE_ADDR']
path_url = request.path_info
if not re.match('^/test',path_url):
return None
times = self.visit_times.get(ip_address,0)
print('ip',ip_address,'已经访问',times)
self.visit_times[ip_address] = times + 1
return None if times < 5 else HttpResponse('您已经访问过'+str(times)+ '次,访问被禁止')
4、Django接收请求、直到响应出的全过程-面试题
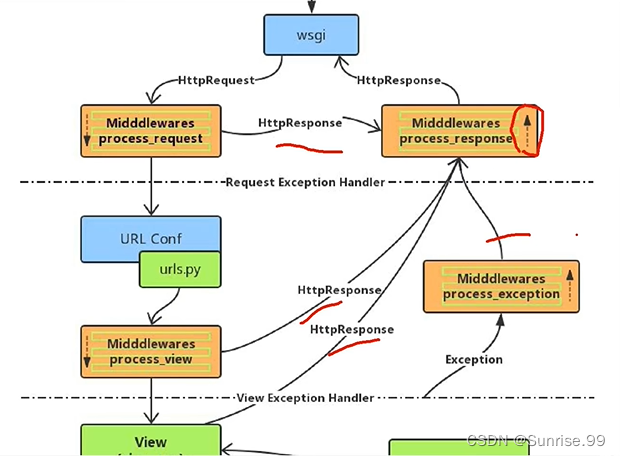
1、经历request中间件
2、urls / response中间件
3、经历view中间件
4、MTV层 / response中间件
5、有异常则经历exception异常捕获中间件 / response中间件
6、response中间件
5、CSRF - 跨站伪造请求攻击
(1)概念
某些恶意网站上包含链接、表单内容或JavaScript,他们会利用登陆过的用户在浏览器中的认证信息视图在你的网站上完成某些操作。
(2)Django处理csrf
Django采用‘对比暗号’机制,Cookies中存储暗号1,模板中的表单里藏着暗号2,用户只有在本网站下提交数据,暗号2才会随表单提交给服务器,diango对比两个暗号,对比成功,则认为是合法请求,否则是违法请求403响应码。
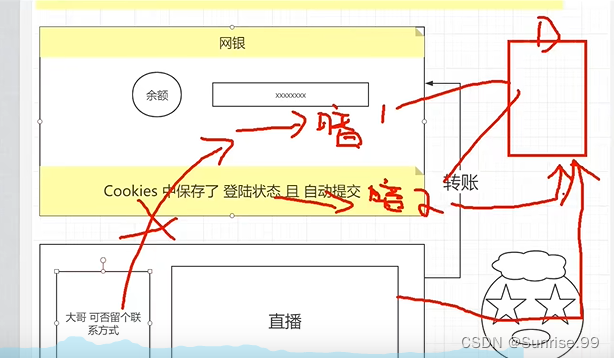
配置:
- settings中确定
MIDDLEWARE中django.middleware.csrf.CsrfViewMiddleware是否打开 - 模板中form标签下添加
{%csrf_token%}标签
特殊说明:如果某个视图不需要csrf保护,可以用装饰器from django.views.decorators.csrf import csrf_exempt
三、分页
web页面有大量数据需要显示,为了方便阅读在每个页中只显示部分数据。
1、Paginator对象
Django使用django.core.paginator模块的Paginator类来管理分页数据。
- 构造方法:
paginator = Paginator(object_list,per_page) - object_list :需要分页数据的对象列表
- per_page:每页数据个数
- 返回值:Paginator的对象
2、Paginator属性
- count:需要分页数据的对象总数
- num_pages:分页后的页面总数
- page_range:从1开始的range对象,用于记录当前码数
- per_page:每页数据的个数
3、Paginator方法
- 方法:
paginator对象.page(number) - 参数number:页码信息 从1开始
- 返回值:当前number页对应的页信息
- 如果提供的页码不存在,抛出
InvalidPage异常 - InvalidPage是总的异常基类,包含PageNotAnInteger(不是整数)和EmptyPage(该页面无对象)
4、page对象
page对象属性与方法:
- object_list:当前页上所有数据对象的列表
- number:当前页的序号,从1开始
- paginator:当前page对象绑定的Paginator对象
- has_next():如果有下一页返回True
- has_previous():如果有上一页返回True
- has_other_pages():如果有上一页或下一页返回True
- next_page_number():返回下一页的页码,不存在则抛出InvalidPage异常。
- previous_page_number():返回上一页的页码,不存在则抛出InvalidPage异常。
5、示例
分3页显示数组[‘a’,‘b’,‘c’,‘d’,‘e’]
def test_page(request):
# /test_page?page=4
page_num = request.GET.get('page',1)
all_data = ['a','b','c','d','e']
paginator = Paginator(all_data,2)
# 初始化具体页码的page对象
c_page = paginator.page(int(page_num))
return render(request,'test_page.html',locals())
<body>
{% for p in c_page %}
<p>
{{p}}
</p>
{% endfor %}
<!-- 上一页 -->
{% if c_page.has_previous %}
<a href="/test_page?page={{ c_page.previous_page_number }}">上一页</a>
{% else %}
上一页
{% endif %}
<!-- 是当前页显示成不可点 不是当前页显示成链接 -->
{% for p_num in paginator.page_range %}
{% if p_num == c_page.number %}
{{ p_num }}
{% else %}
<a href="/test_page?page={{p_num}}">{{p_num}}</a>
{% endif %}
{% endfor %}
<!-- 下一页 -->
{% if c_page.has_next %}
<a href="/test_page?page={{ c_page.next_page_number }}">下一页</a>
{% else %}
下一页
{% endif %}
</body>
四、生成csv文件
触发浏览器下载csv文件
import csv
with open('test_csv.csv','w',newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['a','b','c'])
writer.writerow(['d','e'])
- 响应Content-Type类型修改为text/csv。
- 响应会获得一个额外的Content-Disposition标头,其中包含CSV文件的名称。它将被浏览器用于开启“另存为”对话框。
import csv
from django.http import HttpResponse
from .models import Book
def make_csv_view(request):
response = HttpResponse(content_type = 'text/csv')
response['Content-Disposition'] = 'attachment;filename="mybook.csv"'
all_book = Book.objects.all()
writer = csv.writer(response)
writer.writerow(['id','title'])
for b in all_book:
writer.writerow([b.id,b.title])
return response
练习:结合分页功能,在test_page页面添加‘生成csv’的链接,在指定页中点击该链接,生成当前页的csv数据,供用户下载。




![[numpy算法复现]-第27节 Apriori算法原理(相关性)](https://img-blog.csdnimg.cn/img_convert/0aa0fa8ed14b9cbfaec4393467d4bd7a.png)