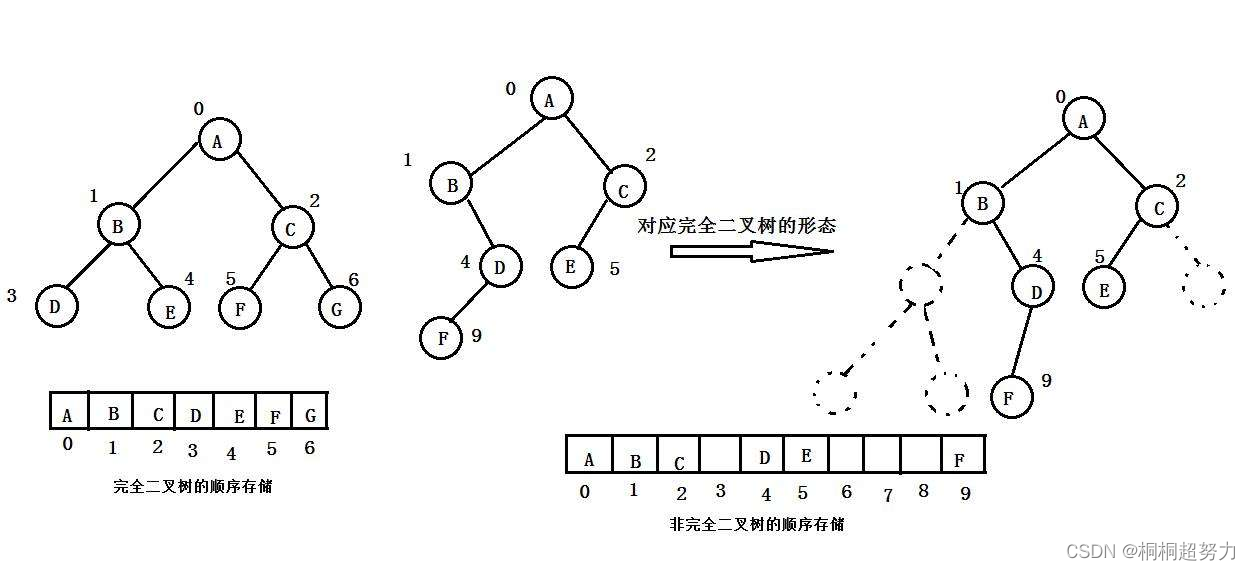
目录
- 1. OCT 图像分类
- 2. OCT图像数据集
- 3. OCT图像预处理
- 4. 特征提取
- 5. 实验结果及分析
github地址: https://github.com/aishangcengloua/OCT_Classification
1. OCT 图像分类
视网膜光学相干断层扫描(OCT)是一种成像技术,用于捕获活体患者视网膜的高分辨率横截面。每年大约进行3000万次OCT扫描,对这些图像的分析和解释占用了大量时间。OCT被眼科医生大量使用以获得眼睛视网膜的高分辨率图像,同时也可用于诊断许多视网膜相关的眼病,因此OCT图像对医学图像处理任务中十分重要。
2. OCT图像数据集
OCT图像数据集包括训练集和测试集,均有4类图像分别是CNV、DME、DRUSEN和NORMAL,训练集共有84495张图片,测试集共有1000张图片,图像均标记为疾病类型-患者ID-该患者的图像编号。4种类别情况如图1所示。图中,最左侧为脉络膜新生血管(CNV),具有新生血管膜(白色箭头)和相关的视网膜下液(箭头);左中为糖尿病性黄斑水肿(DME)与视网膜增厚相关的视网膜内液(箭头);中右为早期AMD,存在多个玻璃疣(箭头);最右侧具有保留的中心凹轮廓且没有任何视网膜液及水肿的正常视网膜(NORMAL)。

3. OCT图像预处理
OCT图像中含有大量的噪声以及许多无关区域,即背景区域有很多,因此对OCT图像的处理的目的就是对OCT图像进行去噪,将前景区域对齐并裁剪,舍弃背景区域。预处理的流程图如图2所示。

- 高斯滤波:高斯滤波的优点可以集中在高斯函数的特点上来看。首先,二维高斯函数是旋转对称的,在各个方向上平滑程度相同,不会改变原图像的边缘走向。第二,高斯函数是单值函数,高斯卷积核的锚点为极值,在所有方向上单调递减,锚点像素不会受到距离锚点较远的像素影响过大,保证了特征点和边缘的特性。第三,在频域上,滤波过程中不会被高频信号污染。

- 图像二值化:使用阈值过滤填充后的图像,使用平均值作为阈值,对图像进行二值化处理,得到二值图像。这是为了找到粗略的前景区域。
- 中值滤波、轮廓填充:中值滤波基本原理是把数字图像或数字序列中一点的值用该点的一个邻域中各点值的中值代替,让周围的像素值接近的真实值,从而消除孤立的噪声点。其对脉冲噪声有良好的滤除作用,特别是在滤除噪声的同时,能够保护信号的边缘,使之不被模糊。在本次任务中,使用中值滤波的方法对二值图像进行处理,可以去除视网膜内脱落的黑点。而轮廓填充是为了去除由于前面二值化得到的小区域,此次先是找到二值化图像中的所有区域轮廓,随后对每个轮廓的面积进行统计,然后对具有最大面积的区域进行白色填充作为感兴趣区域。

- 形态学开闭操作:图像依次经过腐蚀、膨胀处理后的过程。图像被腐蚀后,去除了噪声,但是也压缩了图像;接着对腐蚀过的图像进行膨胀处理,可以去除噪声,并保留原有图像,通过形态学开运算的方法,设置合适大小的卷积核,去除视网膜外脱落的白点。然后对图像进行闭操作,扩张图片。

- 图像数据拟合:此步骤是对图像的中间和底部的数据点集进行线性拟合或者二阶多项式拟合,该过程主要参考了[4],是为了后续的前景区域的对齐和裁剪,剔除背景区域,这样有利于特征提取。
- 图像对齐、归一化、裁剪:将前景区域对齐到一个相对统一的形态学位置来归一化视网膜。根据拟合曲线将图像的每一列移动一定距离,使视网膜变平。然后对前景区域进行裁剪,提出背景区域。
OCT图像经过上述预处理流程的结果如图6所示。图中的A-F表示上述的预处理流程。

4. 特征提取
在对OCT数据集的所有照片进行预处理得到前景区域之后,就要对OCT图像进行特征提取,本次任务我使用了深度学习框架来提取特征,我选择的是ResNet50框架。我使用PyTorch加载ResNet50的预训练模型,该预训练模型参数在大型数据集ImageNet[5]上训练得到,我使用OCT数据集的训练集对ResNet50进行微调10个Epoch,并在ResNet50中插入PDBL[6]模块,PDBL可参考论文或者代码。使用交叉熵损失函数和SGD优化器训练网络主干,学习率为1e-3,权值衰减率为1e-4,动量为0.9,批次大小为20,所有的图像都将resize至224×224再输入网络。
5. 实验结果及分析
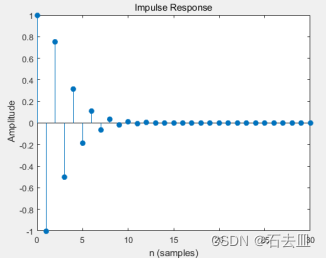
使用OCT数据集的训练集微调ResNet50的训练过程入图7(左)所示,训练10个Epochs的损失和准确率如图8所示。训练过程中会保留微调后的模型参数,在微调完成之后,加载微调后的模型参数训练PDBL模块,同时要保存ResNet50+PDBL的模型参数,在全部训练过程完成之后,加载ResNet50+PDBL模型对OCT数据集的测试集进行预测验证模型性能,结果如图7(右)所示。


结合图7(左)和图8,可以发现在微调ResNet50过程中,模型损失一直在下降,同时准确率一直在上升,最低和最高分别达到0.0179和0.99381,这说明ResNet50的模型适应能力很强,适合用于OCT图像的分类,这得益于ImageNet的大规模数据训练出的预训练模型。图7(右)是在ResNet50基础上插入了PDBL模块后的训练和测试,可以发现在测试集上准确率达到了0.996,F1分数达到了0.996,这要比只使用ResNet50的结果要高一点点。这说明在模型框架中插入PDBL模块有利于提升模型的性能,原因在后续博客会详细讲解。虽然我们在测试集上得到一个非常高的分类准确率,但是仍有一些不足,比如在OCT图像预处理过程中并不能100%的确定前景区域,有时会单纯截取到背景区域作为感兴趣区域,这是不利于模型训练的。
[1] Zhang X, Zhou X, Lin M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6848-6856.
[2] Tan M, Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks[C]//International conference on machine learning. PMLR, 2019: 6105-6114.
[3] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[4] https://github.com/hhyx/OCT-classification
[5] https://image-net.org/
[6] Han C, Lin J, Mai J, et al. Multi-layer pseudo-supervision for histopathology tissue semantic segmentation using patch-level classification labels[J]. Medical Image Analysis, 2022: 102487.


![[numpy算法复现]-第27节 Apriori算法原理(相关性)](https://img-blog.csdnimg.cn/img_convert/0aa0fa8ed14b9cbfaec4393467d4bd7a.png)