启示录
新约圣经启示录认为:恶魔其实本身是天使,但炽天使长路西法背叛了天堂,翅膀变成了黑色,坠落地狱,堕落成为恶魔。这些恶魔主宰著黑暗势力,阻碍人类与上帝沟通,无所不用其极。所以可以说天使和恶魔本来是一体的,只是命运不同。
随着eBPF技术在各种行业领域上的使用和普及,人们在享受着技术变革红利的同时,也遭受着无孔不入的恶意攻击,就像任何事物都有两面性一样。没有任何一项技术只有高高在上的优势,而没有弊端,只有更加清晰的刨析清楚eBPF的内核,才能推动它不断的进步,趋利避害,尽可能发挥正向的作用。
那么,eBPF是天使,亦或恶魔?

越来越严峻的Linux安全形势
根据安全分析机构ESG 云原生安全研究,88% 的网络安全专业人士表示,在过去 12 个月中,他们的云原生应用程序和基础设施遭受过攻击 。然而,许多旨在保护 Linux 的云安全解决方案可能很麻烦且具有破坏性,因为它们是从 Mac 或 Windows 操作系统上移植而来,这些方案有时会影响到Linux 系统的处理能力,甚至进行更改。
在Linux领域,很多安全公司都发布了自研的MDR、XDR、EDR产品,大多数方案是基于轻量级代理在静默收集遥测数据,同时最大限度地减少任何可能的性能影响,并将托管检测和响应扩展到系统的本地和云上,通常构建有基于规则的自动响应和分析功能,比如SanerNow、Automox、Cybereason、Syxsense Secure、Sangfor Endpoint Secure等等,大致有以下特点:
1. 从端点监视和收集可能暗示威胁的活动数据
2. 评估收集的数据以确定威胁模式
3. 自动响应已识别的威胁以消除或遏制它们,并通知安全人员
4. 使用取证和分析工具研究已识别的威胁并寻找可疑活动
目前在Linux环境下,对于EDR、XDR产品也提出更加严格的要求:
1. Linux 威胁和攻击媒介与 Windows/MacOS 对应物不同,需要单独构建策略。
2. Linux 通常是生产系统的基础,不能因为产品的中断或干扰会对业务产生负面影响。
3. 构建轻型Linux EDR传感器专为 Linux 构建和优化,对系统的影响降到最小。

基于Linux系统的云原生基础架构设施
云原生应用程序的组合是CI/CD持续集成和交付的 API、容器、VM 和无服务器功能的组合。保护这些应用程序、底层基础设施和协调其部署的自动化平台,需要重新审视威胁模型、获得组织一致性并利用有目的的控制。此外,随着安全性和 DevOps 不断融合,云安全控制正在得到整合。将孤立的方法发展为统一的策略,以保护云原生应用程序和平台是目前很多安全厂商发力的目标,也是甲方实实在在的需求。与此同时,更多的安全厂商正在尝试将云安全态势管理 (CSPM)、云工作负载保护 (CWP)、容器安全等方案,整合到集成的云安全套件中,从而增大自身安全产品在市场上的竞争力和话语权,也避免安全产品的碎片化。
云原生的基础设施包含CPU硬件,指令集,操作系统等,增强操作系统的高性能和安全性,也是目前eBPF技术正在深入的领域,所以eBPF自身的安全能力,也是检验该项技术是否有可持续发展的重要指标。
eBPF:恶魔面孔
eBPF (扩展的Berkeley数据包过滤器)席卷了Linux 世界。它于 2013 年首次推出以支持可编程网络,现在用于可观察性、安全性、网络等。许多大公司——包括 Meta、谷歌、微软和 Netflix——都致力于帮助开发和支持它,尤其是在云原生领域的重要性越来越高。注意:“eBPF”和“BPF”实际上是同义词,社区经常互换使用这些术语,部分原因是 eBPF 几乎完全取代了经典的 BPF 技术。
在过去的几年里,黑产组织一直在研究利用eBPF来开发并扩大Linux恶意软件方面的作用,安全研究人员则不停的修复漏洞,并试图提前感知预测0-day漏洞。最近,有一些eBPF相关的CVE报告示例频繁的出现在DEFCON和BlackHat等顶级安全会议上,也让人们更加的重视和担心eBPF的安全性,如下topic,后续我会逐步翻译验证,并同步分享出来:
- Evil eBPF In-Depth: Practical Abuses of an In-Kernel Bytecode Runtime
- Warping Reality - creating and countering the next generation of Linux rootkits using eBPF
- eBPF, I thought we were friends !
- With Friends Like eBPF, Who Needs Enemies?
- Fixing a Memory Forensics Blind Spot: Linux Kernel Tracing
现在让我们深入了解 eBPF机制,看看黑客是如何利用这些强大功能来达到攻击的目的。
-
bpf_probe_write_user
利用:eBPF 程序可以访问一组有限的辅助函数,这些函数内置于内核中。基于 eBPF 恶意利用的一个助手就是bpf_probe_write_user。此函数允许 eBPF 程序写入当前正在运行的进程的用户空间内存。恶意利用可以使用这种能力在系统调用期间修改进程的内存,例如bad-bpfsudo在读取时写入用户空间内存/etc/sudoers。它注入了一个额外code,允许特定用户使用该sudo命令。
限制:
(1)如果内存被换出或未标记为可写,该函数将失败。
(2)一条警告消息会打印到内核日志中,说明正在使用该函数。这是为了警告用户程序正在使用具有潜在危险的 eBPF 辅助函数 -
bpf_override_return
利用:另一个 eBPF 辅助函数bpf_override_return允许程序覆盖返回值。黑客可以利用它来阻止恶意利用行为。例如,如果你想运行kill -9 ,黑客可以将 kprobe 附加到适当的内核函数以处理 kill 信号,返回错误,并有效地阻止系统调用的发生。开源项目ebpfkit使用它来阻止可能导致发现控制 eBPF 程序的用户空间进程的操作。
限制:
(1)内核构建时打开选项:CONFIG_BPF_KPROBE_OVERRIDE
(2)目前仅支持 x86
(3)只能与 kprobes 一起使用 -
XDP 和 TC
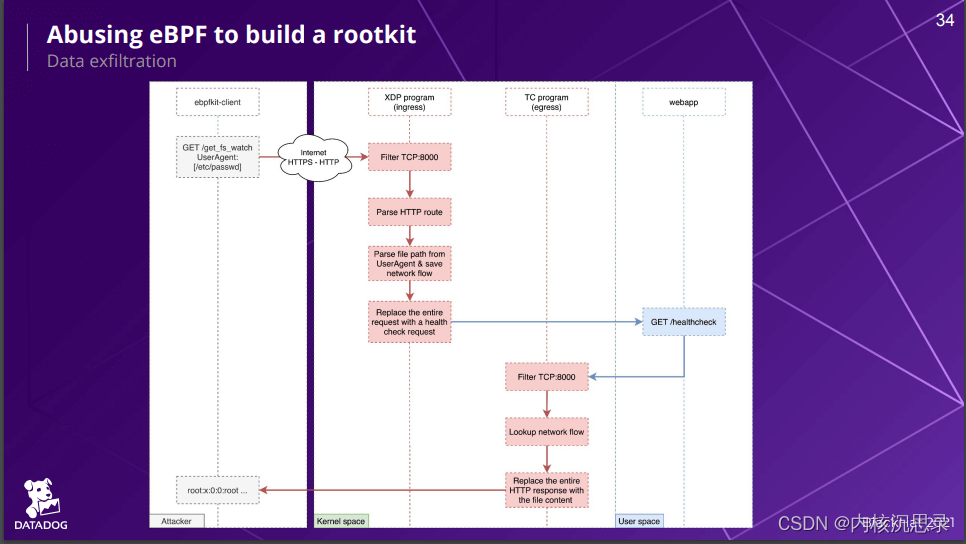
利用: ebpfkit利用 XDP 和 TC 进行隐式通信。下图来自 Blackhat 会议演讲PPT,其中 ebpfkit 的创建者(Guillaume Fournier、Sylvain Afchain 和 Sylvain Baubeau),在演讲中,他们概述了如何使用 XDP 和 TC 隐藏发送到 ebpfkit 的命令,主机上运行的 XDP 程序接收并处理请求。该程序将其识别为对主机上运行的恶意利用的请求,并将数据包修改为对主机上运行的 Web 应用程序的普通 HTTP 请求。在出口处,ebpfkit 使用 TC 程序捕获来自 web app 的响应,并使用来自 ebpfkit 的响应数据修改其输出。
限制:
(1)XDP 程序运行得太早,数据与进程或套接字无关,因此数据包周围几乎没有上下文
eBPF:天使面孔
eBPF 的核心是可以在 Linux 内核中类似虚拟机结构中运行的一种指令集架构(ISA),拥有寄存器、指令和堆栈等。为了使用 eBPF,用户可以创建 eBPF 程序并将它们附加到系统的适当位置,通常是在内核中。当与附加点相关的事件发生时,程序运行并有机会从系统读取数,将该数据返回给用户空间中的控制应用程序。总而言之,eBPF 允许用户动态安装在内核上下文中执行,但可从用户空间编排的代码。它有点像用户空间应用程序和 Linux 内核模块之间的混合体。
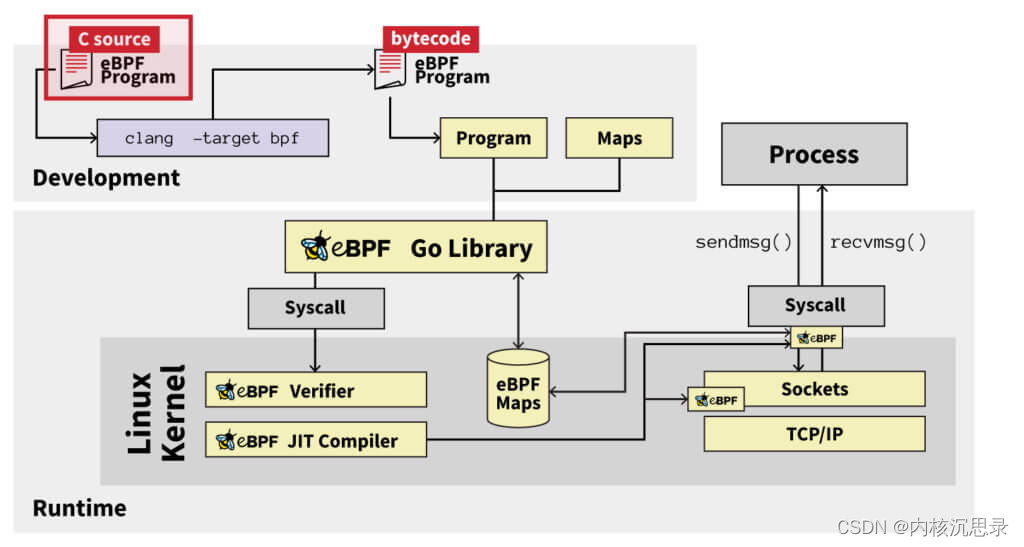
关于eBPF的基础知识无需赘述,网络上已经有太多丰富的教程和分析文章,个人建议初学者可以先从官方网站 上开始了解eBPF的前生今世,也可以直接在kernel源码具体实例中学习和验证。eBPF在为诸多Linux内核开发者提供便利的同时,也为恶意软件的开发者提供了新的利用领域,这也就是“天使恶魔”的混合体来源。
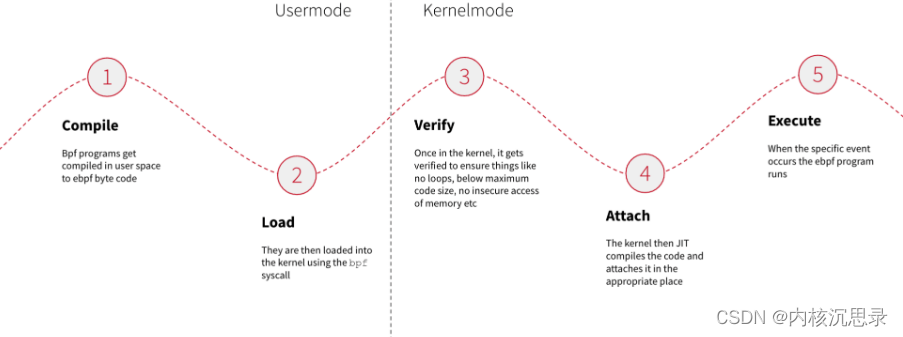
下图总结了 eBPF 程序的整个生命周期:
安全优势:
1. Socket filters
套接字过滤器是经典 BPF 的原始用例。套接字过滤器是一个可以附加到套接字的 eBPF 程序。然后该程序可以过滤该套接字的传入流量。Berkley Packet Filter 的名称暗示它是一种旨在过滤数据包数据的技术。这个功能甚至一直保留到现代 eBPF 中。
2. ByteCode
eBPF 程序通常以“受限”C 程序开始。受限意味着堆栈大小、程序大小、循环、可用函数等与普通 C 程序相比受到限制。C 代码被编译成 eBPF 字节码。
3. Verifier
在 eBPF 代码完全加载到内核之前,它会通过验证器运行。验证者的工作是确定 eBPF 程序是否可以安全运行。“安全”是指它不会陷入无限循环,没有不安全的内存操作,并且低于最大复杂度/代码大小。
安全策略:
1. 确保非特权 eBPF 被禁用。
如今,要安装 eBPF 程序,您通常需要 root——或至少需要 CAP_SYS_ADMIN 和/或 CAP_BPF。情况并非总是如此。围绕内核 4.4 引入了非特权 eBPF。请务必通过运行以下命令检查此配置选项:
#sysctl kernel.unprivileged_bpf_disabled
2. 禁用不需要的功能。管理员可以通过编程方式禁用诸如 kprobes 之类的东西:
#echo 0 > /sys/kernel/debug/kprobes/enabled
3. 在不支持 kprobes、基于 eBPF 的 TC 过滤器或完全支持 eBPF 的情况下构建内核(尽管这可能不是许多人的选择)
4. ONFIG_BPF_KPROBE_OVERRIDE除非绝对必要,否则不设置Ensure
安全检测:
从安全周期的角度来看,一场检测分为三个大阶段:事前(运行前)、事中(运行时)、事后(攻击后)。安全人员都希望可以在运行前通过一系列的静态分析方法来检测出异常,从而将问题扼杀在摇篮里。但现实往往事与愿违,更多的异常检测场景发生在运行时,这个时候就需要安全人员设计的产品模型具有很强的鉴白和鉴黑能力,这也是绝对了最终方案是否成功的基石。
从eBPF以及Linux Tracing的维度来看看具体方案:
1. 寻找加载的意外 kprobes:
#cat /sys/kernel/debug/kprobes/列表
ffffffff8ad687e0 r ip_local_out+0x0 [FTRACE]
ffffffff8ad687e0 k ip_local_out+0x0 [FTRACE]
2. 用bpftool列出系统中正在使用eBPF的程序
# bpftool prog
176: cgroup_skb tag 6deef7357e7b4530 gpl
loaded_at 2022-10-31T04:38:09-0700 uid 0
xlated 64B jited 54B memlock 4096B
185: kprobe tag a7ce508aab49e47f gpl
loaded_at 2022-10-31T10:03:16-0700 uid 0
xlated 112B jited 69B memlock 4096B map_ids 40
# bpftool perf
pid 543805 fd 22: prog_id 3610 kprobe func tcp_v4_connect offset 0
pid 543805 fd 23: prog_id 3610 kprobe func tcp_v6_connect offset 0
pid 543805 fd 25: prog_id 3611 kretprobe func tcp_v4_connect offset 0
pid 543805 fd 26: prog_id 3611 kretprobe func tcp_v6_connect offset 0
pid 543805 fd 28: prog_id 3612 kretprobe func inet_csk_accept offset 0
3. 查找加载的 XDP 程序。您会在输出中看到与此类似的一行
$ ip link show dev <interface>
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 220 tag 3b185187f1855c4c jited
4. 检查 bpffs(BPF 文件系统)中是否有任何pinned objects。
$ mount | grep bpf
…
bpf on /sys/fs/bpf type bpf (rw,nosuid,nodev,noexec,relatime,mode=700)
…
#ls -la /sys/fs/bpf/
5. 检查是否加载了任何 TC 程序
#tc filter show dev <device-name>
6. 监视系统日志中是否提及 BPF 帮助程序生成的警告消息
#dmesg -k | grep ‘bpf_probe_write_user’
尾声
总之,eBPF目前已经成了安全研究人员和黑客手中强大的工具,亦正亦邪,取决于使用者的选择。由于这种范式将过去实施恶意利用的方式和流程进行了转变,对于安全人员也提升了要求,需要研究和理解新兴威胁的前沿技术及利用。
随着不断地地分析并认识到了如何识别和检测eBPF的恶意滥用,我们未来将更深入地了解此类利用的原理、行为方式以及检测它的最佳方式,后续研究分析将持续分享。
eBPF双子座:天使or恶魔?由你决定!