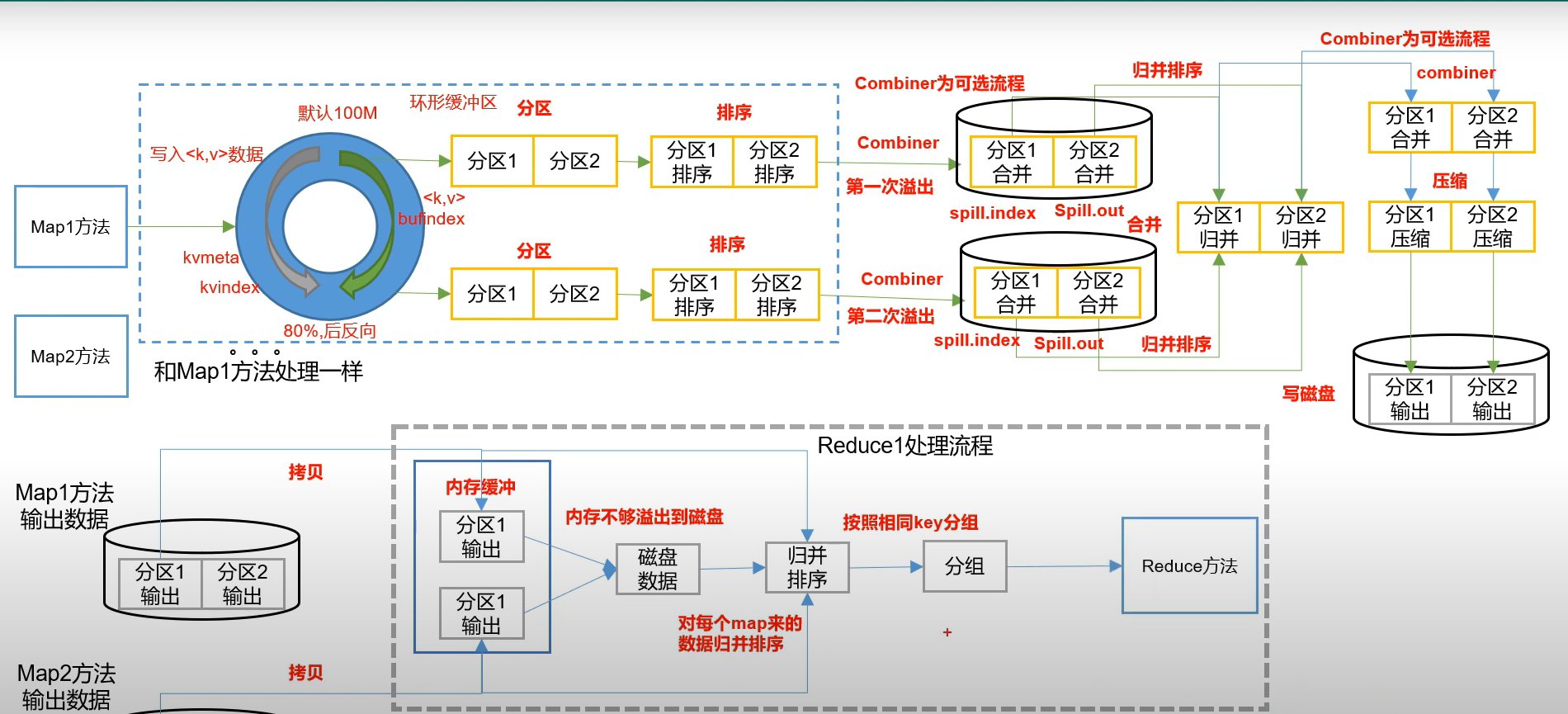
1.MapTask工作机制

以上内容我们之前文章或多或少介绍过,就已网络上比较流行的该图进行理解学习吧
MapTask分为五大阶段
- Read阶段
- Map阶段
- Collect阶段
- 溢写阶段
- Merge阶段
2.ReduceTask工作机制

ReduceTask分为三大阶段
- Copy阶段
- Sort阶段
- Reduce阶段
3.ReduceTask并行度决定机制
MapTask并行度由切片个数决定,切片个数由输入文件和切片规则决定,ReduceTask与MapTask的并发数决定不同,可以直接设置
job.setNumReduceTasks(4);
4.ReduceTask注意事项
- ReduceTask=0,表示没有Reduce阶段,输出文件数与Map阶段输出个数一致
- ReduceTask默认值1,所以输出文件是一个
- 如果数据分布不均匀,就有可能Reduce阶段产生数据倾斜
- ReduceTask数量并不是任意设置,要考虑业务需求,当需要计算全局汇总结果,就只能有1个ReduceTask
- 具体多少个ReduceTask,需要根据集群性能而定
- 如果分区数不是1,但是ReduceTask为1,不会执行分区过程,在MapTask源码中,分区前提是先判断ReduceNum个数是否大于1,不大于1肯定不执行分区
5.Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称为Shuffle
欢迎关注公众号算法小生与我沟通交流