主题建模:Top2Vec(理论篇)
Top2Vec 是一种用于 主题建模 和 语义搜索 的算法。它自动检测文本中出现的主题,并生成联合嵌入的主题、文档和词向量。
算法基于的假设:许多语义相似的文档都可以由一个潜在的主题表示。首先,创建文档和词向量的联合嵌入。一旦文档和单词被嵌入到向量空间中,算法的目标就是找到密集的文档簇,然后找到是哪些单词将这些文档聚集在一起。每个密集区域即为一个主题,将文档聚拢到密集区域的词就是主题词。
1.联合嵌入
使用 Doc2Vec 或 Universal Sentence Encoder 或 BERT Sentence Transformer 创建文档和词向量的联合嵌入。
文档将被放置在靠近其他类似文档和靠近最有区别的词的地方。

2.降维
使用 UMAP 为文档向量的降维。高维空间中的文档向量非常稀疏,降维有助于找到密集区域。每个点都代表了一个文档向量。

3.聚类
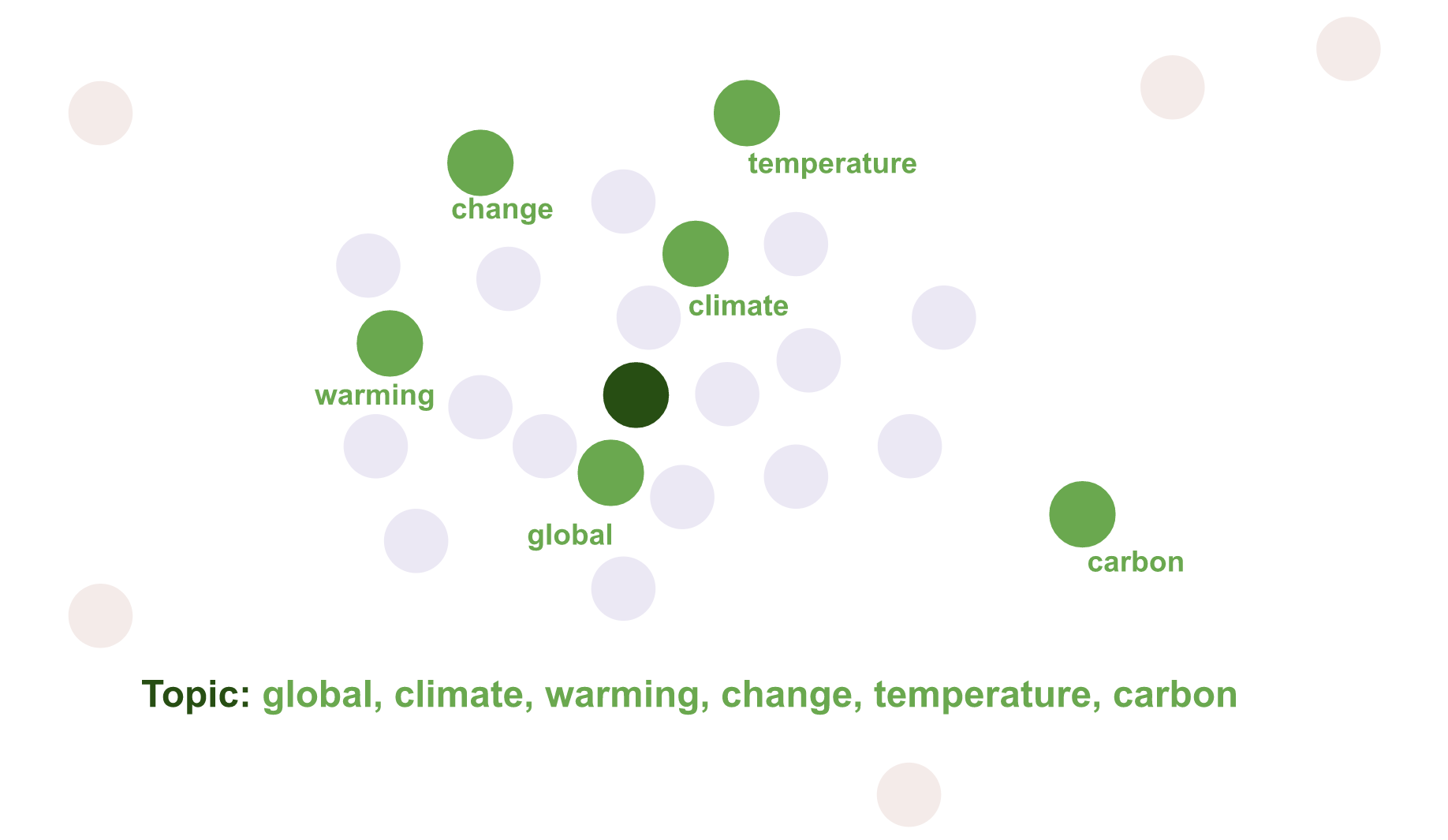
使用 HDBSCAN 查找文档的密集区域。彩色区域是文档的密集区域。红点是不属于特定集群的异常值。

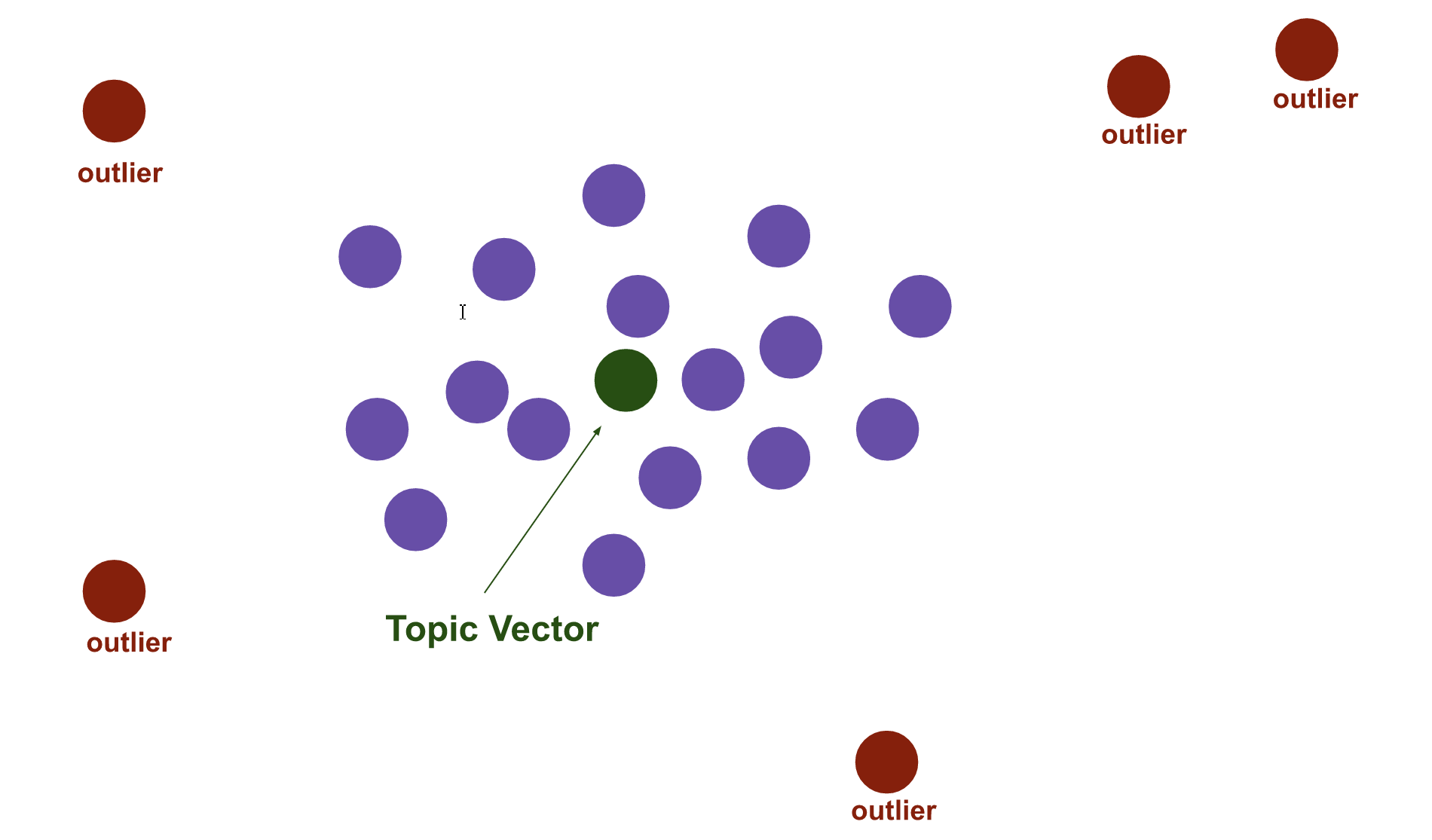
4.计算质心
对于每个密集区域,计算文档向量在原始维度的质心,这就是主题向量。红点是异常文档,不用于计算主题向量。紫色点是属于密集区域的文档向量,从中计算主题向量。
5.词向量排序
找到与生成的主题向量最接近的词向量。最接近的词向量作为主题词。