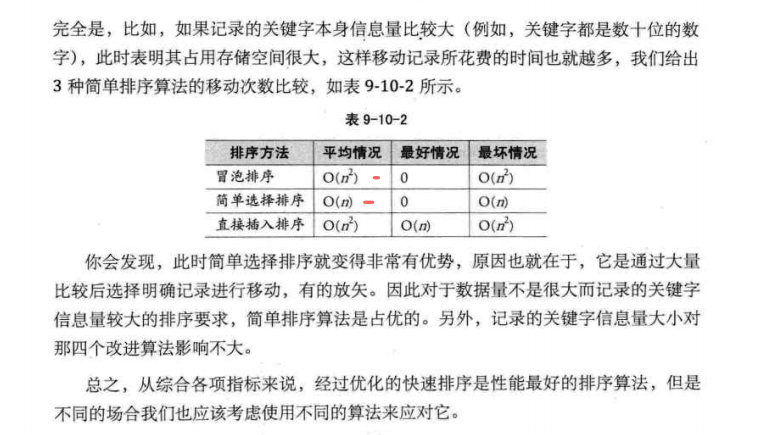
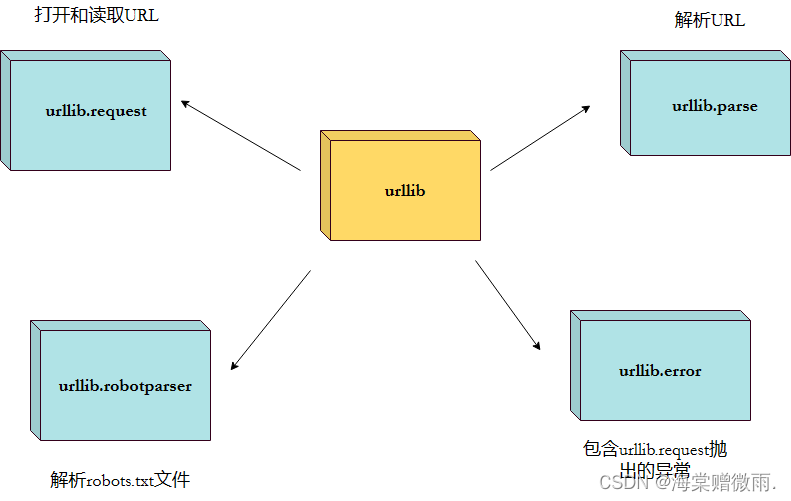
Java序列化机制
概述
java中的序列化可能都停留在实现Serializable接口上,对于它里面的一些核心机制没有深入了解过。直到最近在项目中踩了一个坑,就是序列化对象添加一个字段以后,使用方系统报了反序列化失败,原因是我们双方的序列化对象没有加上serialVersionUID,
- 序列化对象中的serialVersionUID 是干嘛用的?
- 如何修改默认的序列化机制?
- 如何使用序列化的方式克隆对象?
对象序列化和反序列化机制
-
序列化: 将对象转成二进制写到输出流的过程。
-
反序列化: 通过输入流读回二进制转成对象的过程。
通过对象的序列化和反序列化机制可以实现对象在网络之间传输。
在Java中,如果一个对象要想实现序列化,必须要实现下面两个接口之一:
- Serializable 接口
- Externalizable 接口
这里我们先讲解常用的Serializable 接口。
writeObject序列化过程例子:
public class User implements Serializable {
private String userName;
private Integer age;
//有参,无参构造方法
//set,get方法
}
@Test
public void testSerializable() throws FileNotFoundException {
User user = new User("admin",20);
//文件输出流
FileOutputStream outputStream = new FileOutputStream("user.dat");
try(ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream)){
//序列化
objectOutputStream.writeObject(user);
}catch (IOException e){
e.printStackTrace();
}
}
结果:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZTIC0Swa-1676897166151)(java序列化机制.assets/image-20221007211113075.png)]](https://img-blog.csdnimg.cn/2f18da3b44d743bcb352271efebd3f5a.png)
readObject反序列化例子:
现在模拟另外一个系统需要反序列化user.dat
@Test
public void testDeSerializable() throws FileNotFoundException {
User user = null ;
//写到内存中,也写到文件中
FileInputStream fileInputStream = new FileInputStream("user.dat");
try(ObjectInputStream inputStream = new ObjectInputStream(fileInputStream)){
//反序列化
user = (User) inputStream.readObject();
}catch (IOException | ClassNotFoundException e){
e.printStackTrace();
}
Assert.assertEquals("alvin","姓名:"+user.getUserName()+",年龄:"+user.getAge());
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ocL6MREJ-1676897166153)(java序列化机制.assets/image-20221007212831133.png)]](https://img-blog.csdnimg.cn/870d706608324575bb6c6dfcb6ca8ae9.png)
如果User类不实现Serializable接口, 那会怎么样?
当然是报错了,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L5JVTNFS-1676897166153)(java序列化机制.assets/image-20221007212904237.png)]](https://img-blog.csdnimg.cn/69c9849bbd954c95b93c973531e2916a.png)
小结:
一个对象想要被序列化,那么它的类就要实现此接口或者它的子接口。
修改默认的序列化机制
默认的情况下,如果实现了Serializable接口的对象进行序列化的时候,默认会将全部的数据域,也就是成员变量进行序列化输出,那往往有时候并不需要这样,有什么方法可以修改序列化机制呢?下面提供3中方式。
使用transient关键字
将成员变量标记成transient,那么在序列化的过程中这些数据域会被跳过,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8TLi7PtH-1676897166154)(java序列化机制.assets/image-20221007213016833.png)]](https://img-blog.csdnimg.cn/997cd71ee0804e51976296dcbb130b95.png)
这是一种最简单的方式,但是不够灵活。
自定义readObject、writeObject方法
序列化类中可以通过定义下面签名的方法:
-
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException -
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException
只要类中有这两个签名的方法,那么就不会调用默认的序列化,取而代之调用这些方法。
本例我们举个jdk中的例子,ArrayList就实现了这两个方法,重写了序列化机制。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cbRSD2CE-1676897166155)(java序列化机制.assets/image-20221007213318034.png)]](https://img-blog.csdnimg.cn/e5c50ff42db34df2a78e6ea469ccd918.png)
主要原因ArrayList底层的数组通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用自定义方式实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
实现Externalizable接口
Externalizable接口想必大家很少用到,它是Serializable接口的子类,用户要实现的writeExternal()和readExternal() 方法,用来决定如何序列化和反序列化。
因为序列化和反序列化方法需要自己实现,因此可以指定序列化哪些属性,而transient在这里无效。
对Externalizable对象反序列化时,会先调用类的无参构造方法,这是有别于默认反序列方式的。如果把类的不带参数的构造方法删除,或者把该构造方法的访问权限设置为private、默认或protected级别,会抛出java.io.InvalidException: no valid constructor异常,因此Externalizable对象必须有默认构造函数,而且必需是public的。
举例说明:
public class User implements Externalizable {
private String userName;
private Integer age;
public User() {
}
public User(String userName, Integer age) {
this.userName = userName;
this.age = age;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeUTF(userName);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
this.userName = in.readUTF();
this.age = in.readInt();
}
}
serialVersionUID的作用
这就回到概述中提到的项目中遇到的问题,现在简要描述下:
A系统中的序列化对象User用的最新版本如下:
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MIjXJky0-1676897166155)(java序列化机制.assets/image-20221007213829704.png)]](https://img-blog.csdnimg.cn/5e3b995f8e5c48ddaf055810fb719796.png)
B系统中反序列化的对象,还是老的User版本如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ecWeC4VA-1676897166156)(java序列化机制.assets/image-20221007213918141.png)]](https://img-blog.csdnimg.cn/15b83aac58cb40aab85f29b9472abffb.png)
这时候A系统生成的序列化文件,交给B系统反序列化时,出错了, 如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lbs9lP3z-1676897166156)(java序列化机制.assets/image-20221007214057070.png)]](https://img-blog.csdnimg.cn/246e388d965c4c21b855128c18008c27.png)
原因:
类定义发生了变化,比如添加、删除、修改类中的数据域后,它的唯一标记符或者称为SHA指纹、或者理解为serialVersionUID都会发生变化,这个值会保存在序列化二进制中,如果反序列化过程发现对不上,就会报错,如上图所示。
那么如何处理呢?
这时候,我们如果觉得这个序列化对象是可以兼容的,那么可以自定义一个serialVersionUID的静态成员变量,它就不会自动生成,而是直接用这个值,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rj0zXeTc-1676897166157)(java序列化机制.assets/image-20221007214332070.png)]](https://img-blog.csdnimg.cn/06b67897f3bf4e118e20312e7b5f8382.png)
使用序列化clone
clone大家都知道吧,在深拷贝的时候编码还是很麻烦的,借用序列化机制可以实现深拷贝。做法很简单,就是将对象序列化到输出流中,然后读回。
public class SerialCloneable implements Cloneable, Serializable {
@Override
public Object clone() throws CloneNotSupportedException {
try {
// 保存到字节数组流
ByteArrayOutputStream bout = new ByteArrayOutputStream();
try(ObjectOutputStream out = new ObjectOutputStream(bout)) {
out.writeObject(this);
}
// 读取
try(InputStream bin = new ByteArrayInputStream(bout.toByteArray())) {
ObjectInputStream in = new ObjectInputStream(bin);
return in.readObject();
}
} catch (IOException | ClassNotFoundException e) {
CloneNotSupportedException e2 = new CloneNotSupportedException();
e2.initCause(e);
throw e2;
}
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6x4SuigW-1676897166157)(java序列化机制.assets/image-20221007214211484.png)]](https://img-blog.csdnimg.cn/1839269acfa144ccab2ed4a8be4b5325.png)
注意一点,这种方式性能不高,通常比显示构建、复制数据要慢不少。
总结
本文讲解了序列化的一些核心机制,不再简简单单的停留在序列化就是实现Serializable接口了