第八章 分布式SQL引擎
回顾一下,如何使用Hive进行数据分析的,提供哪些方式交互分析???
方式一:交互式命令行(CLI)
- bin/hive,编写SQL语句及DDL语句
方式二:启动服务HiveServer2(Hive ThriftServer2)
- 将Hive当做一个服务启动(类似MySQL数据库,启动一个服务),端口为10000
- 1)、交互式命令行,bin/beeline,CDH 版本HIVE建议使用此种方式,CLI方式过时
- 2)、JDBC/ODBC方式,类似MySQL中JDBC/ODBC方式
SparkSQL模块从Hive框架衍生发展而来,所以Hive提供的所有功能(数据分析交互式方式)都支持,文档:http://spark.apache.org/docs/2.4.5/sql-distributed-sql-engine.html。
8.1 Spark SQL CLI
SparkSQL提供spark-sql命令,类似Hive中bin/hive命令,专门编写SQL分析,启动命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-sql --master local[2] --conf spark.sql.shuffle.partitions=4
编写SQL执行,截图如下:

此种方式,目前企业使用较少,主要使用下面所述ThriftServer服务,通过Beeline连接执行SQL。
8.2 ThriftServer JDBC/ODBC Server
Spark Thrift Server将Spark Applicaiton当做一个服务运行,提供Beeline客户端和JDBC方式访问,与Hive中HiveServer2服务一样的。此种方式必须掌握:在企业中使用PySpark和SQL分析数据,尤其针对数据分析行业。

Spark Thrift JDBC/ODBC server 依赖于HiveServer2服务(依赖JAR包),所有要想使用此功能,在编译Spark源码时,支持Hive Thrift。

注意:启动Spark Thrift JDBC/ODBC Server时,不需要HiveServer2服务。
在$SPARK_HOME目录下的sbin目录,有相关的服务启动命令:
SPARK_HOME=/export/server/spark
$SPARK_HOME/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf hive.server2.thrift.bind.host=node1.itcast.cn \
--master local[2]
监控WEB UI界面:

beeline 客户端
SparkSQL类似Hive提供beeline客户端命令行连接ThriftServer,启动命令如下:
/export/server/spark/bin/beeline
Beeline version 1.2.1.spark2 by Apache Hive
beeline> !connect jdbc:hive2://node1.itcast.cn:10000
Connecting to jdbc:hive2://node1.itcast.cn:10000
Enter username for jdbc:hive2://node1.itcast.cn:10000: root
Enter password for jdbc:hive2://node1.itcast.cn:10000: ****
编写SQL语句执行分析:
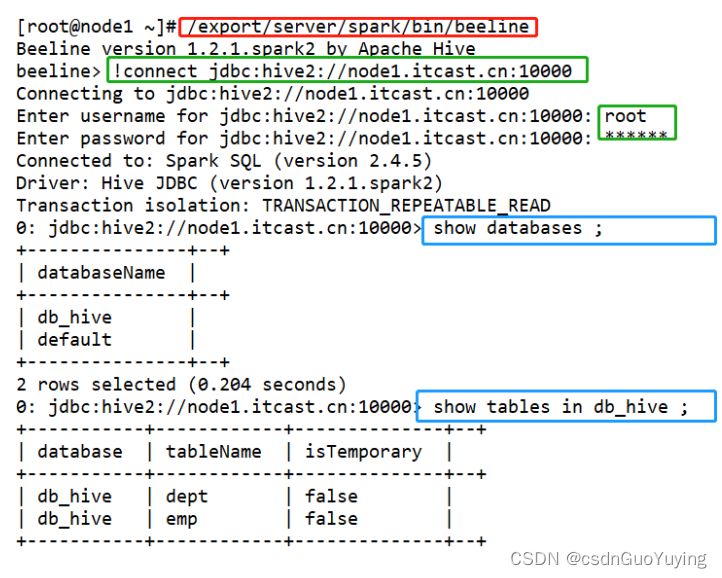
在实际大数据分析项目中,使用SparkSQL时,往往启动一个ThriftServer服务,分配较多资源(Executor数目和内存、CPU),不同的用户启动beeline客户端连接,编写SQL语句分析数据。

JDBC/ODBC 客户端
SparkSQL中提供类似JDBC/ODBC方式,连接Spark ThriftServer服务,执行SQL语句,首先添加Maven依赖库:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_2.11</artifactId>
<version>2.4.5</version>
</dependency>
参考文档:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-JDBC
范例演示:采用JDBC方式读取Hive中db_hive.emp表的数据。
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
/**
* SparkSQL 启动ThriftServer服务,通过JDBC方式访问数据分析查询
* i). 通过Java JDBC的方式,来访问Thrift JDBC/ODBC server,调用Spark SQL,并直接查询Hive中的数据
* ii). 通过Java JDBC的方式,必须通过HTTP传输协议发送thrift RPC消息,Thrift JDBC/ODBC server必须通过上面命
令启动HTTP模式
*/
object SparkThriftJDBC {
def main(args: Array[String]): Unit = {
// 定义相关实例对象,未进行初始化
var conn: Connection = null
var pstmt: PreparedStatement = null
var rs: ResultSet = null
try {
// TODO: a. 加载驱动类
Class.forName("org.apache.hive.jdbc.HiveDriver")
// TODO: b. 获取连接Connection
conn = DriverManager.getConnection(
"jdbc:hive2://node1.itcast.cn:10000/db_hive",
"root",
"123456"
)
// TODO: c. 构建查询语句
val sqlStr: String =
"""
|select e.ename, e.sal, d.dname from emp e join dept d on e.deptno = d.deptno
""".stripMargin
pstmt = conn.prepareStatement(sqlStr)
// TODO: d. 执行查询,获取结果
rs = pstmt.executeQuery()
// 打印查询结果
while (rs.next()) {
println(s"empno = ${rs.getInt(1)}, ename = ${rs.getString(2)}, sal = ${rs.getDouble(3
)}, dname = ${rs.getString(4)}")
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (null != rs) rs.close()
if (null != pstmt) pstmt.close()
if (null != conn) conn.close()
}
}
}