公司的跑批引擎从impala改成Spark3已经有一个多月了。
不得不说,跑批稳定了好多。资源控制有相对稳定了很多。Spark3比CDH的hive on spark2.4.0要快不少。AQE和CBO真的挺强的。但是使用中发现了一个很奇怪的事情。这个问题在网上搜过,并没有实际解决。当然我的这个帖子只是记录问题以及解决问题,具体原理没有深挖(太忙了没时间深挖)。
我这边有个很简单的SQL。
我有7个表 A,B,C,D,E,F,G
每个表的分区是省会,比如 河南、吉林、北京...等等
select * from
A LEFT JOIN B
ON A.id=B.id and A.region=B.region
LEFT JOIN C
ON B.id=C.id and B.region=C.region
........很简单的SQL,正常来(忽略数据量)说应该很快执行完。但是执行的时候却发现
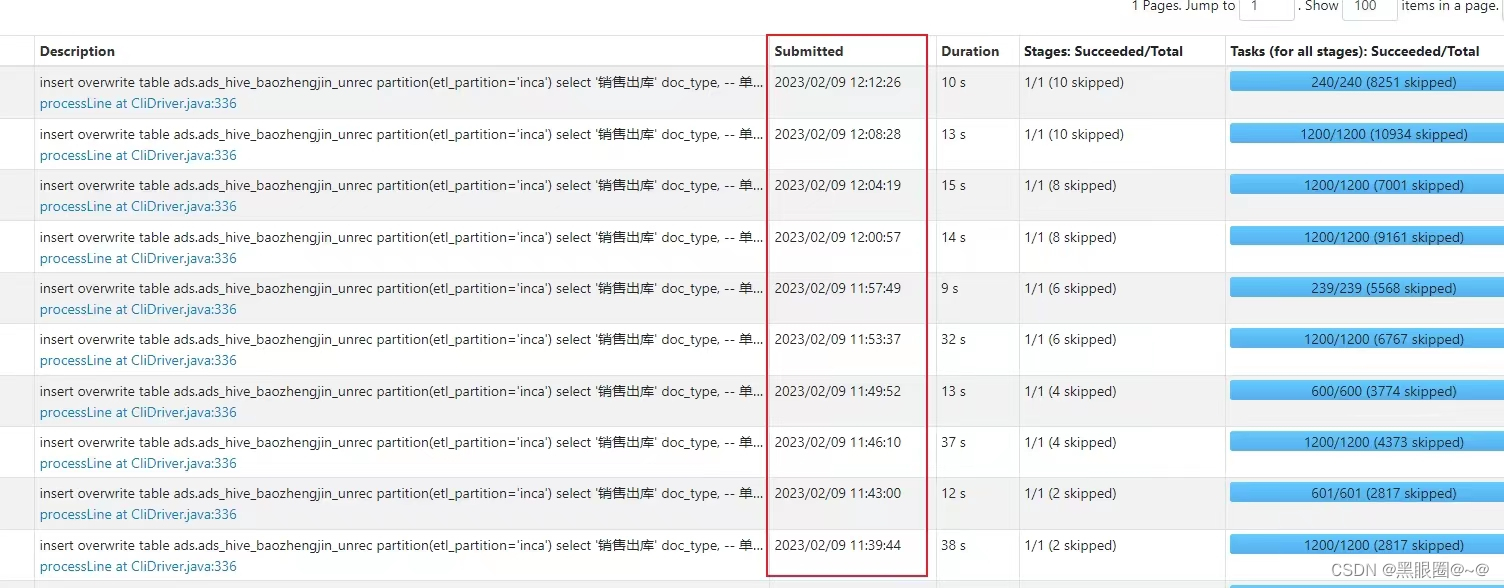
每个job执行都很快,但是每个job执行完,会间隔好几分钟。再执行下一个。
因为网络原因,没办法看到详细 stage的log日志。这可难为坏我了。
查看执行计划太长了。实在是看不下去。
全部任务执行下来跑了俩多小时。
实在无奈,先看看如何优化吧。调整参数AQE啊啥的。没效果。
那么只能从SQL上进行优化了。这时候又犯了难了。这丫的也不算数据倾斜啊。
然后按照正常的思路进行异常排查。发现了问题
我有15个省会大区。
当我执行
select * from A where region in('henan','beijing'....各大区)
left join B
.....他就不会出现每个job之间的间隔。
因为可能未来涉及到增加省会大区。我直接改成
select * from A where region <> 1
left join B
.....逻辑上执行效果和指定省会大区一样的。
最终优化后的SQL,从执行两个半小时,变成了5分钟跑完。