import pandas as pd
path='C:/Users/Admin/Desktop/pandas/透视.xlsx'
data = pd.read_excel(path)print(data)print("***********************")
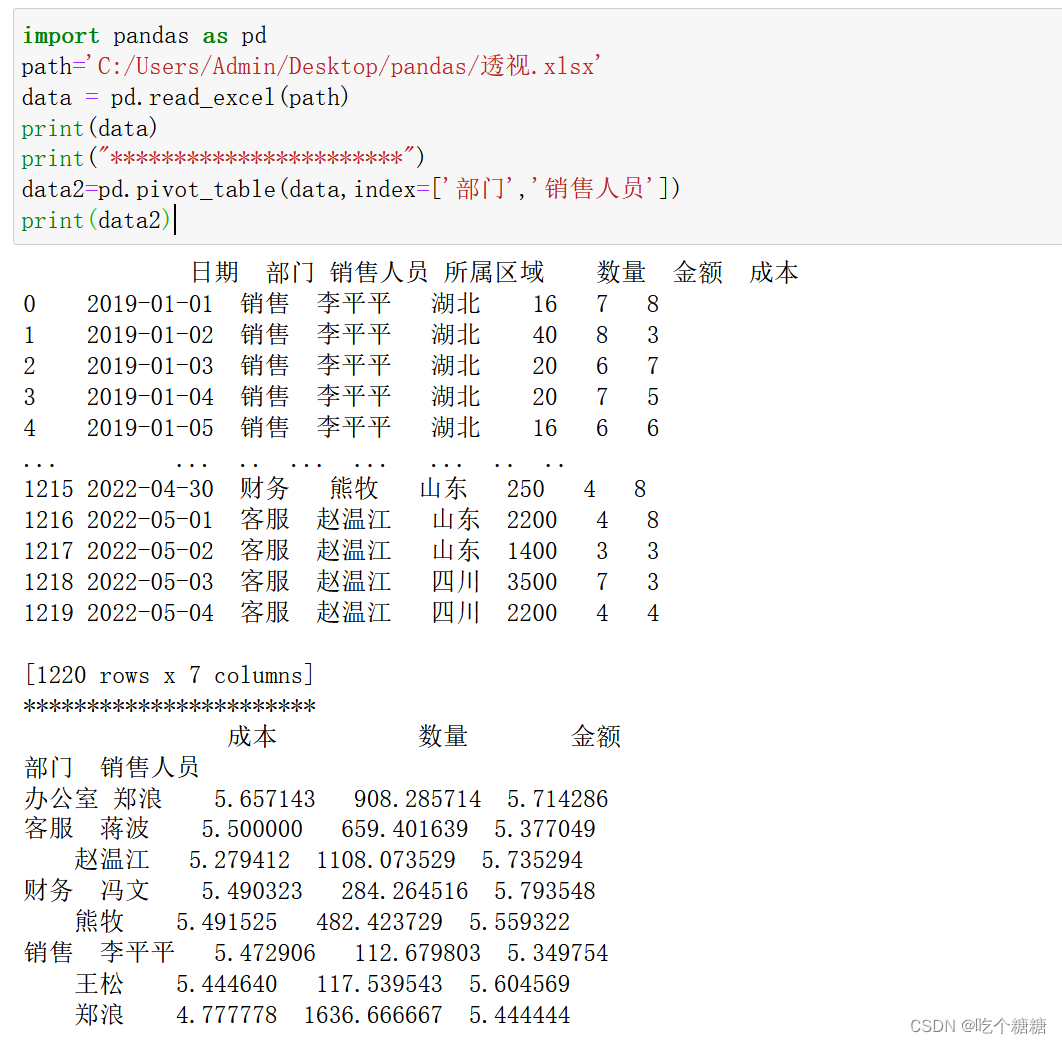
data2=pd.pivot_table(data,index=['部门','销售人员'])print(data2)
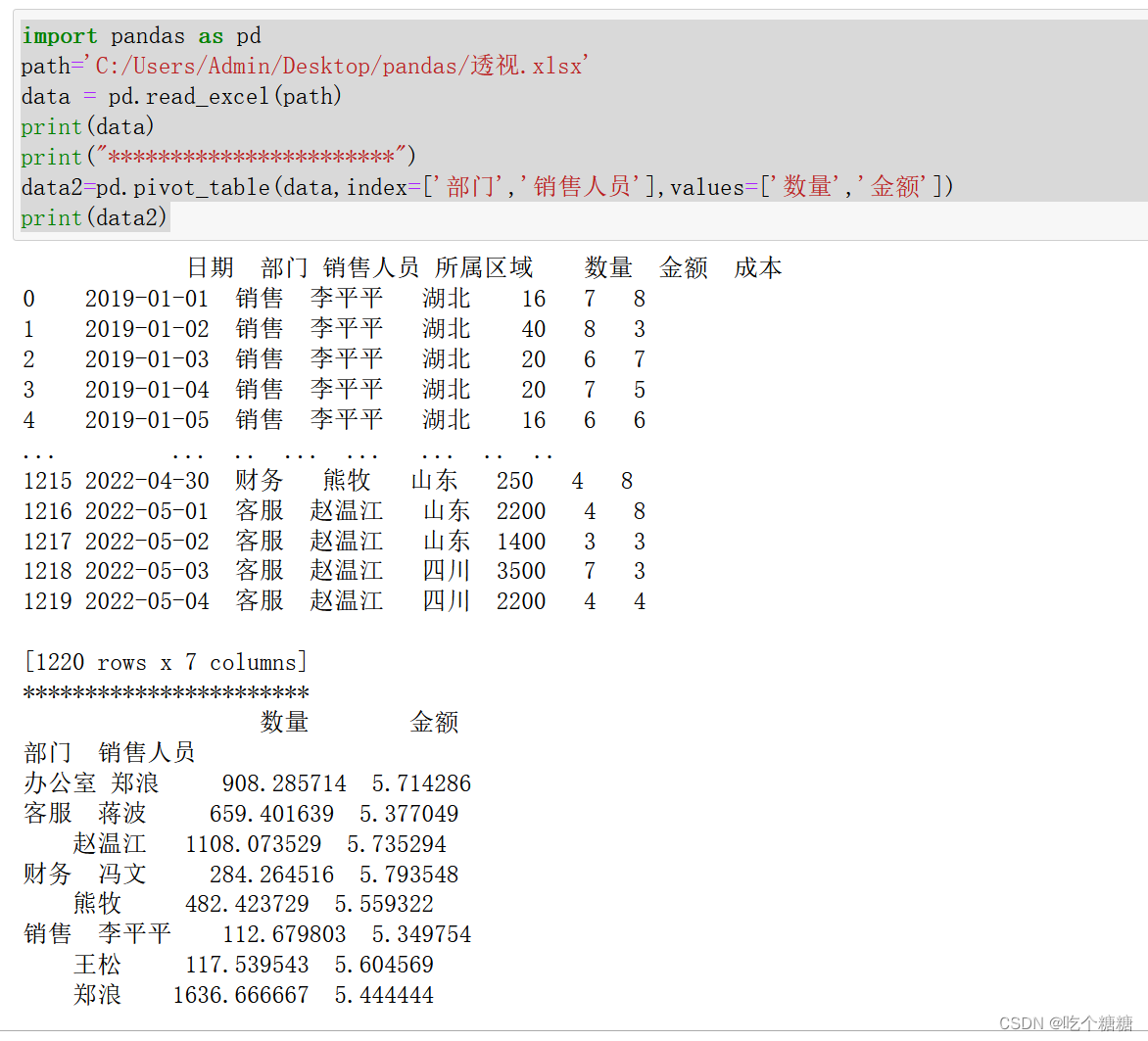
2、values在结果透视的行上进行分组的列名或其它分组键【就是透视表里显示的列】
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/透视.xlsx'
data = pd.read_excel(path)print(data)print("***********************")
data2=pd.pivot_table(data,index=['部门','销售人员'],values=['数量','金额'])print(data2)
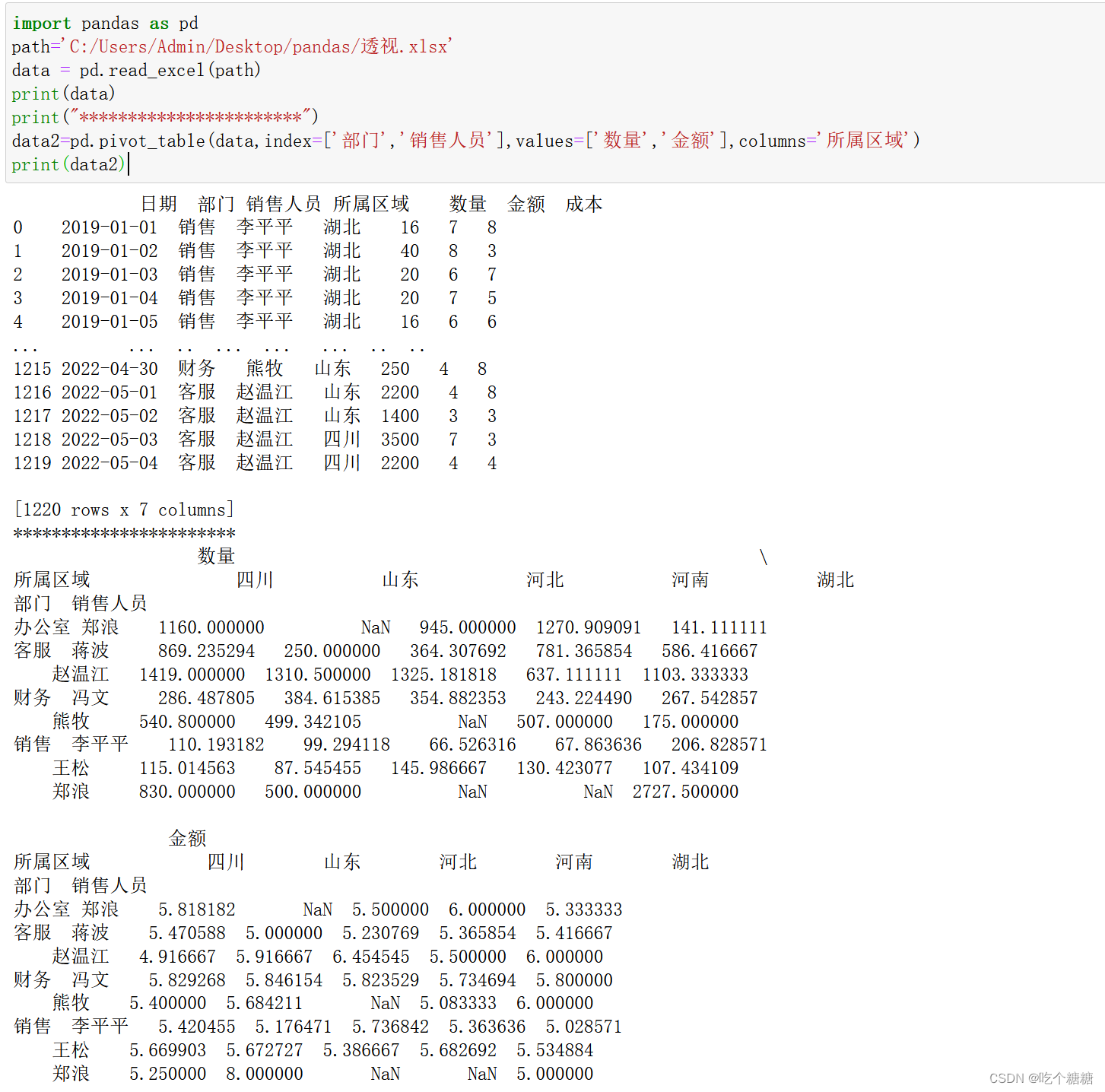
3、columns在结果透视表的列上进行分组的列名或其它分组键
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/透视.xlsx'
data = pd.read_excel(path)print(data)print("***********************")
data2=pd.pivot_table(data,index=['部门','销售人员'],values=['数量','金额'],columns='所属区域')print(data2)
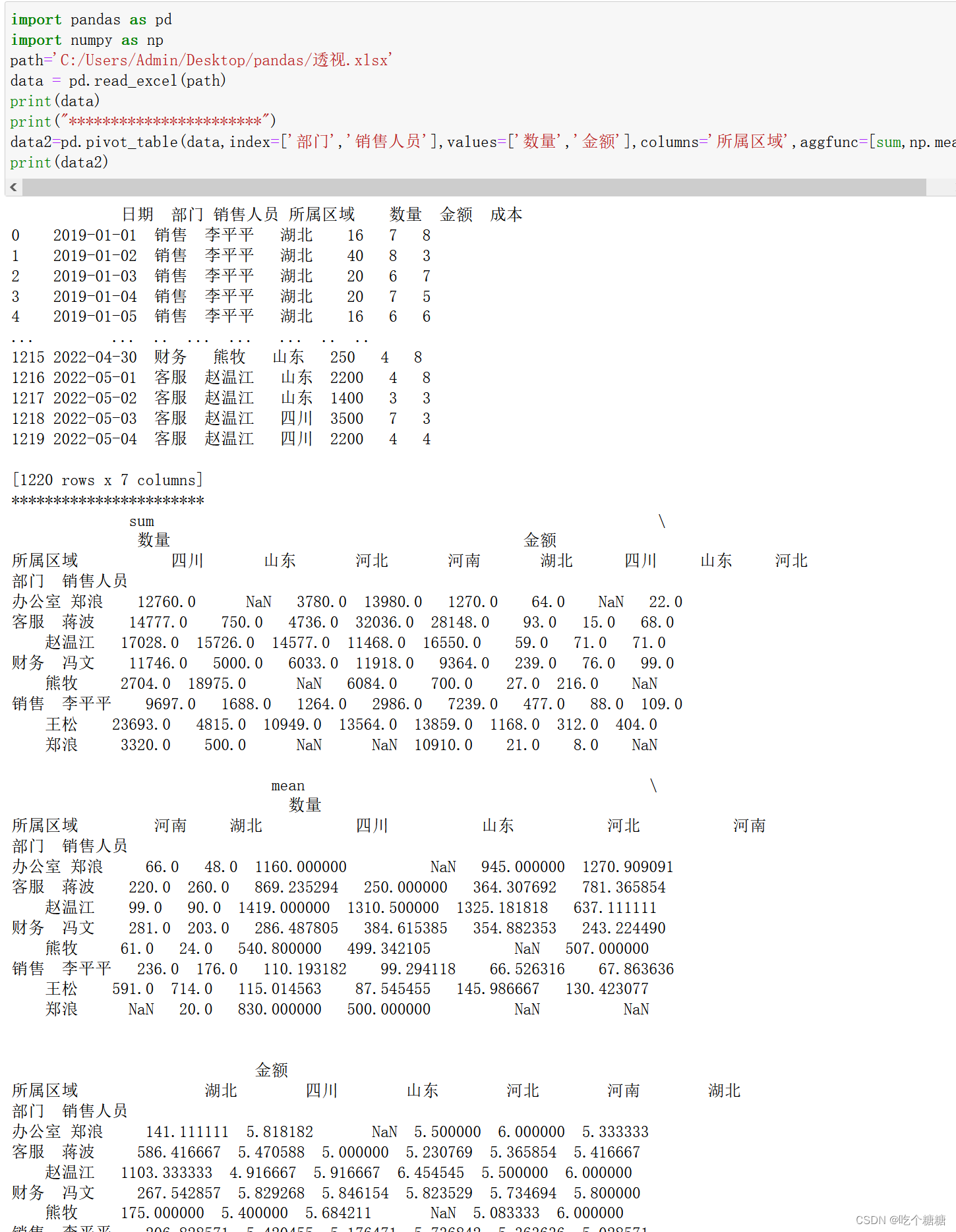
4、Aggfunc聚合函数或函数列表(默认情况下是mean)可以是groupby里面的任意有效函数
import pandas as pd
import numpy as np
path='C:/Users/Admin/Desktop/pandas/透视.xlsx'
data = pd.read_excel(path)print(data)print("***********************")
data2=pd.pivot_table(data,index=['部门','销售人员'],values=['数量','金额'],columns='所属区域',aggfunc=[sum,np.mean])print(data2)