总体框架:
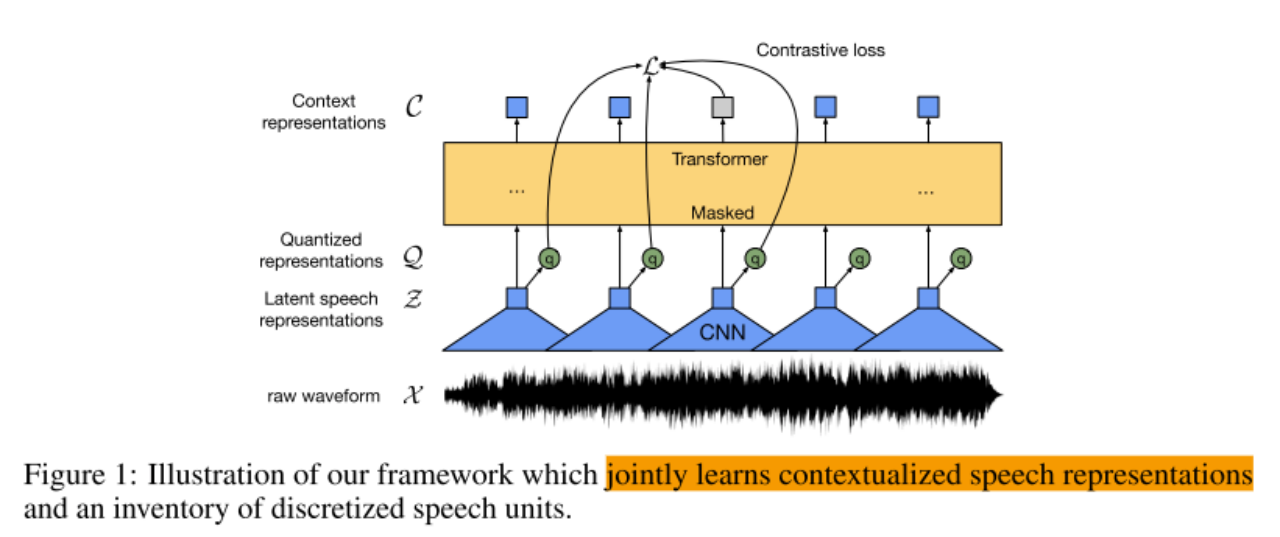
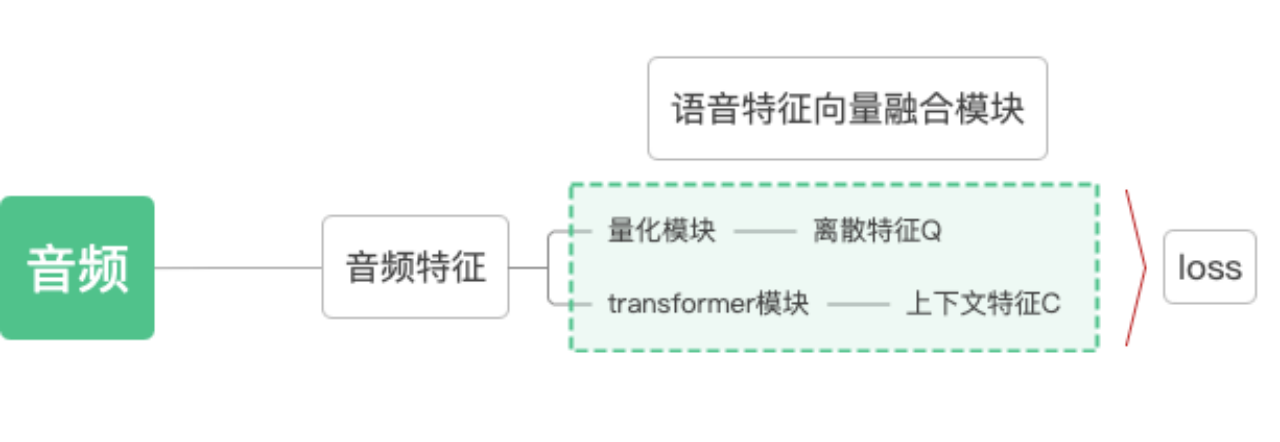
主要分为2个大模块:1:语音特征提取模块 2:语音特征向量融合模块
1:特征提取模块
输入:音频
输出:音频特征向量
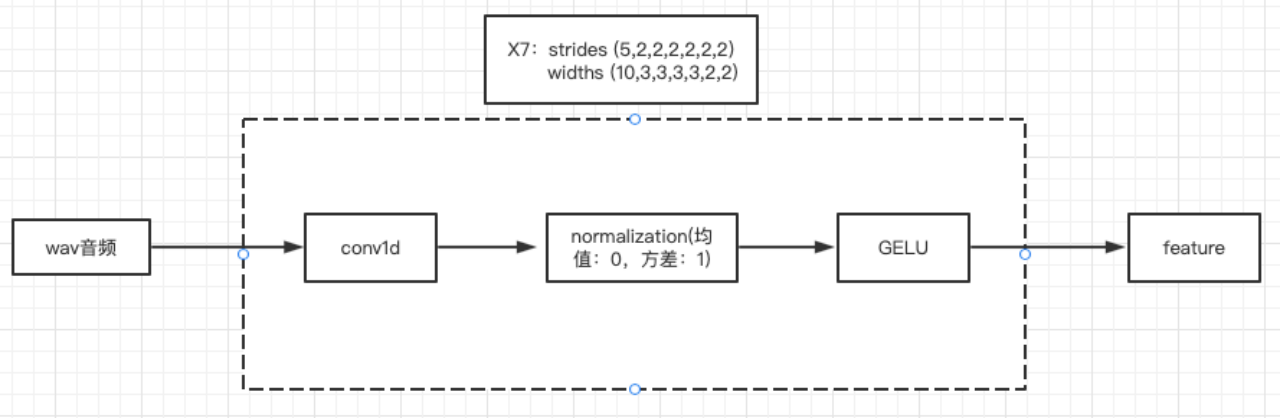
过程:
1)跟具体采样率有关,如果一段1S的音频,采样率是16K,则这段1S的音频可以用1*16000的矩阵表示。
2)此模块的结构:
文章使用了7层的CNN,步长为(5,2,2,2,2,2,2),卷积核宽度为(10,3,3,3,3,2,2),假设输入语音的长度为(1,x):
cnn0 (x-10)/5+1=x/5-1
cnn1 ((x/5-1)-3)/2+1=x/10-1
cnn2 x/20-1
cnn3 x/40-1
cnn4 x/80-1
cnn5 x/160
cnn6 x/320
论文中的channels大小设置的为512,如果采样率是16K,对应的输出为:(512,16000/320)=(512,50),可以得到50个512维的向量,相当于每20ms产生一个512维的特征向量。
2:语音特征向量融合模块
2.1)向量量化(Vector Quantization,VQ),将将由第一步得到的连续的语音特征Z转为离散特征Q;
- 保留一段语音中相应最大值的索引,其他置0。既将原来连续特征变为one-hot特征。
- 实现上述过程,有两种算法:
(a)gumbel softmax
(b)k-means clustering
结构:

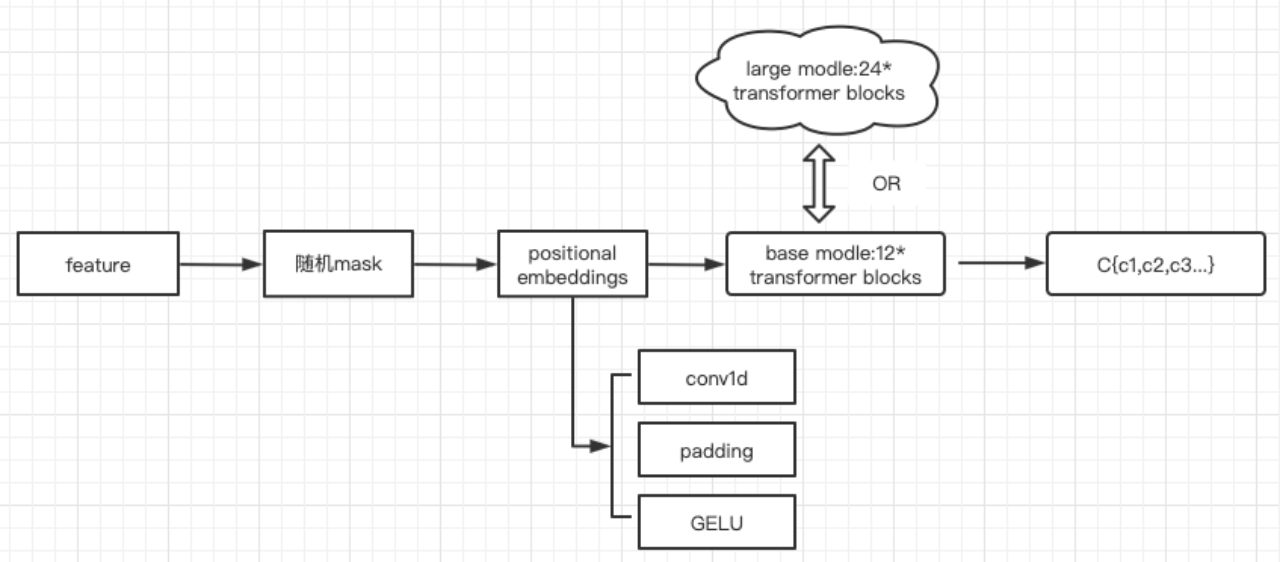
2.2)将由第一步得到的语音特征做随机掩码,然后经过transformer模型得到上下文表征C;
过程: - 使用conv1替代原来的positional embedding;
- Transfoemer
结构:
2.3)对Q与C,通过对此学习损失L,Contrastive Loss,拉近对应Q与C的距离,达到自监督学习目的。
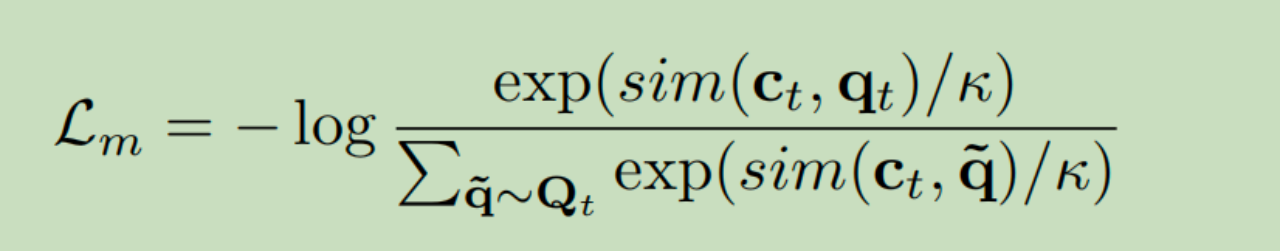
自监督模块的loss,计算one-hot量化后的音频特征与加mask之后获取的上下文特征之间的相似度。





![推荐系统[三]:粗排算法常用模型汇总(集合选择和精准预估),技术发展历史(向量內积,WideDeep等模型)以及前沿技术](https://img-blog.csdnimg.cn/b935ff75e3e84d7f88de39613bb02bad.png)