文章目录
- 摘要
- 前言
- 相关的工作
- 方法论
- 动作空间
- 奖励函数设计
- Q学习
- 仿真结果
- 结论
摘要
变道是一项至关重要的车辆操作,需要与周围车辆协调。建立在基于规则的模型上的自动换道功能可能在预定义的操作条件下表现良好,但在遇到意外情况时可能容易失败。在我们的研究中,我们提出了一种基于强化学习的方法来训练车辆智能体学习自动变道行为,以便它可以在各种甚至不可预见的情况下智能地进行变道。特别是,我们将状态空间和动作空间都视为连续的,并设计了一个具有闭式贪心策略的 Q 函数逼近器,这有助于提高深度 Q 学习算法的计算效率。为训练算法进行了广泛的模拟,结果表明基于强化学习的车辆智能体能够为变道操作学习平稳有效的驾驶策略。
论文地址:A Reinforcement Learning Based Approach for Automated Lane Change Maneuvers
前言
变道机动可能是一项艰巨的任务,因为车辆需要警惕地观察其自我车道上的领先车辆和目标车道上的周围车辆,并根据这些相关车辆表现出的潜在对抗或合作反应来执行适当的操作。
自动变道机动的研究已经广泛开展,工作大致可分为两个功能类别:决策模块和控制执行模块。
我们将重点关注操作控制方面,即车辆如何在接收到来自决策模块的命令后自动执行变道操作。
相关的工作
-
解决自动变道问题的传统方法主要依赖于预定义的规则和明确设计的模型。(GPS+差分定位导入到自行车模型中、MPC等等)
缺点:在动态情况和不同驾驶风格下规划的轨迹缺乏灵活性,MPC类时间后退优化方法的因为优化标准可能太复杂而无法针对所有场景明确制定
-
另一种方法是通过合作技术连接所有车辆。
-
机器学习 (ML) 算法,如SVM、随机森林。
-
融合机器学习与传统算法(神经网络+PID)
-
强化学习
在之前的一项研究 [14] 中,我们使用 RL 来训练车辆智能体以在交互式驾驶环境下学习最佳匝道合并驾驶策略。
然而,在那项工作中,我们没有考虑横向控制问题,因为我们假设智能体车辆将沿着其行驶车道的中心线行驶。在这项工作中,我们扩展了之前工作中使用的方法,并采用 RL 架构来处理变道案例,并在状态空间、动作空间和奖励函数中扩展了定义。如果定义了更复杂的状态和动作,我们提出的框架的设计也可以工作。
方法论
在一个统一模型中优化纵向和横向控制是一种很好的做法,如在 MPC 控制器中,但将复杂的车辆操纵分成两个相关模块也很常见,即纵向控制模块和横向控制模块.
我们选择利用成熟的跟车模型、智能驾驶员模型 (IDM) 来构建纵向控制器。
还有一个与两个控制器并行工作的间隙选择模块。车辆收到换道指令后,间隙选择模块会根据周围车辆的所有信息(如速度、加速度、位置、 ETC。)。如果间隙足以容纳允许最大加减速度下的速度差,并能保证当前速度下的最小安全距离,则认为是可接受的间隙,然后将启动变道控制器。纵向和横向控制器将相互交互并共同发挥作用以执行整体变道任务,而它们被单独设计为单独的模块。
在自由交通条件下或在交互式驾驶情况下的纵向行为。
同样值得注意的是,当自我车辆进行车道变换时,它可能会在过渡期间看到自我车道和目标车道中的两辆领先车辆。我们实施的 IDM 跟车模型将允许自我车辆通过在其自我车道和目标车道上观察到的两个领导者之间进行平衡来调整其纵向加速度。较小的值将用于削弱车道变换启动引起的车辆加速度的潜在不连续性。同时,间隙选择模块在整个换道过程中仍然充当安全卫士,检查每个时间步的间隙是否仍然可以接受。如果没有,决策模块将发出改变或中止机动的命令,控制执行模块将重新定位在原来的车道上。这样,纵向控制器会考虑周围的驾驶环境以确保纵向安全,而横向控制器会指示车辆智能地并入任何可接受的间隙。
动作空间
为确保转向角输入连续且平滑,偏航率不应有突然变化,换句话说,偏航加速度不会无规律地波动。因此,我们设计了 RL 智能体来学习偏航加速度,即,动作空间定义为车辆偏航加速度
a
y
a
w
a_{yaw}
ayaw。
a
=
a
y
a
w
∈
A
a = a_{yaw} \in A
a=ayaw∈A
成功的变道不仅与车辆动力学有关,还取决于道路几何形状,即变道是在直线段还是弯道上进行。在我们的研究中,我们用车辆动力学和道路信息来定义状态空间。具体来说,状态空间包括自我车辆的速度
v
v
v、纵向加速度
a
a
a、位置
x
、
y
x、y
x、y、偏航角
θ
θ
θ、目标车道
i
d
id
id、车道宽度
w
w
w和道路曲率
w
w
wc。
s
=
(
v
,
a
,
x
,
y
,
θ
,
i
d
,
w
,
c
)
∈
S
s=(v,a,x,y,\theta,id,w,c)\in S
s=(v,a,x,y,θ,id,w,c)∈S
当输入状态处于高维空间(例如来自视觉感知模块)或带有测量噪声时,可以在不改变算法结构的情况下将此处定义的状态空间自适应扩展到较大尺寸,这是 RL 方法的一个优势。
奖励函数设计
通常,在变道过程中,我们的注意力集中在操作的安全性、平稳性和效率上。由于纵向模块和间隙选择模块已经考虑到安全问题,横向控制器通过奖励函数来考虑平滑性和效率。奖励函数中的组件是根据与动作表现最相关的变量来选择的,它们的权重是通过尝试不同的参数集来决定的。具体而言,由于考虑到偏航加速度直接影响横向运动中的偏移量,所以通过偏航加速度
r
a
c
c
e
r_{acce}
racce来评估平滑度。
r
a
c
c
e
=
w
a
c
c
e
∗
f
a
c
c
e
∗
(
a
y
a
w
)
r_{acce}=w_{acce}*f_{acce}*(a_{yaw})
racce=wacce∗facce∗(ayaw)
其中 r a c c e r_acce racce表示偏航加速度获得的即时奖励, w a c c e w_{acce} wacce是权重,可以设计为常数值或与横向位置相关的函数, w a c c e w_{acce} wacce是评价 a y a w a_{yaw} ayaw的函数。我们目前使用的简单格式为 r a c c e = − 1.0 ∗ ∣ a y a w ∣ r_{acce} = −1.0 ∗ |a_{yaw}| racce=−1.0∗∣ayaw∣ 。
另一个衡量平顺性的指标是横摆率 w y a w w_{yaw} wyaw,反映了驾驶员在变道过程中的舒适度,横摆率越大,行驶中的离心拉力就越大。该函数在 (4) 中给出。
r
r
a
t
e
=
r
r
a
t
e
∗
f
r
a
t
e
∗
(
w
y
a
w
)
r_{rate}=r_{rate}*f_{rate}*(w_{yaw})
rrate=rrate∗frate∗(wyaw)
其中
r
r
a
t
e
r_{rate}
rrate反映的是偏航率得到的即时奖励,
w
y
a
w
w_{yaw}
wyaw是权重,也可以设计成常数或函数,
f
r
a
t
e
f_{rate}
frate是评估
w
y
a
w
w_{yaw}
wyaw的函数.在我们的研究中,我们应用
r
r
a
t
e
=
−
1.0
∗
∣
w
y
a
w
∣
r_{rate} = −1.0 ∗ |w_{yaw}|
rrate=−1.0∗∣wyaw∣ 。
效率由完成机动所消耗的换道时间来评估。通过向奖励函数添加第三项来考虑这样的组件,以避免过长和延长的车道变换动作。
r
t
i
m
e
=
w
t
i
m
e
∗
f
l
a
t
(
Δ
d
l
a
t
)
r_{time}=w_{time}*f_{lat}(\Delta d_{lat})
rtime=wtime∗flat(Δdlat)
其中
r
r
a
t
e
r_{rate}
rrate是评估动作效率的直接奖励,
w
r
a
t
e
w_{rate}
wrate 是权重,
f
r
a
t
e
f_{rate}
frate是当前到目标车道的横向偏差 $\Delta d_{lat}
的函数。
的函数。
的函数。\Delta d_{lat}$越大,换道时间越长。我们使用
r t i m e = − 0.05 ∗ ∣ Δ d l a t ∣ r_{time}=-0.05*|\Delta d_{lat}| rtime=−0.05∗∣Δdlat∣用于效率评估。
单步立即奖励 r 是三部分的总和。为了评估整体表现,我们还需要计算总奖励 R,它是整个换道过程中立即奖励的累积回报。同样,总奖励也可以看作是上述三个单独部分的组合:偏航加速度总奖励
R
a
c
c
e
R_{acce}
Racce,偏航率总奖励
R
r
a
t
e
R_{rate}
Rrate,换道时间总奖励
R
t
i
m
e
R _{time}
Rtime,如(6)所示。
R
=
∑
i
=
1
N
(
r
a
c
c
e
)
i
+
∑
i
=
1
N
(
r
r
a
t
e
)
i
+
∑
i
=
1
N
(
r
t
i
m
e
)
i
R=\sum_{i=1}^N(r_{acce})_i+\sum_{i=1}^N(r_{rate})_i+\sum_{i=1}^N(r_{time})_i
R=i=1∑N(racce)i+i=1∑N(rrate)i+i=1∑N(rtime)i
在公式中,我们将奖励定义为负值,也称为“成本”。这个想法是,如果我们想评估一个动作的不利影响,例如变道机动的不顺畅或低效,则可以将成本视为对动作的惩罚。通过这种方式,智能体应该能够学会避免采取会导致大量惩罚的行动。
Q学习
特别是,我们设计了一个 Q 函数,它在动作上是二次的,因此贪婪动作有一个封闭形式的解决方案。理论解释与[20]中的工作相似。 Q-learning 的这种变体避免了调用策略神经网络并简化了学习算法。在数学上,Q函数逼近器表示如下
Q
(
s
,
a
)
=
A
(
s
)
∗
(
B
(
s
)
−
a
)
2
+
C
(
s
)
Q(s,a)=A(s)*(B(s)-a)^2+C(s)
Q(s,a)=A(s)∗(B(s)−a)2+C(s)
其中 A、B 和 C 是系数,设计有以状态信息为输入的神经网络,如图 1 所示。如果我们在 Q-learning 探索中接近贪婪行为,就会失去一般性。
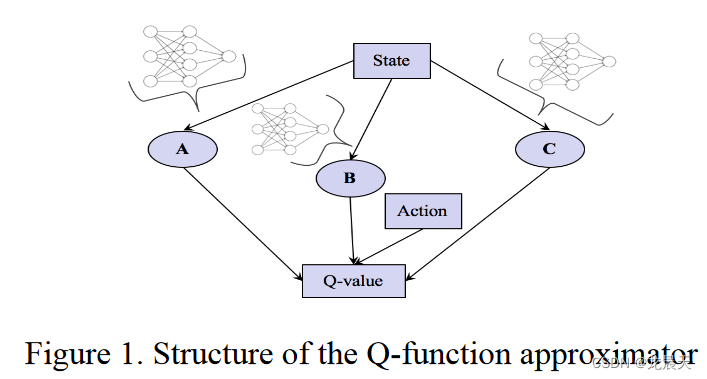
在我们的模型中,A 被设计成一个双层神经网络,输入层有 8 个神经元(即状态空间 S 的维度),隐藏层有 100 个神经元。特别是,在输出层使用 softplus 激活函数乘以负号,A 必然为负。 C 也是一个双层神经网络,具有与 A 相同的神经元数和层数,但它也将终止状态作为换道完成的指标。 B 是一个经过精心设计的形式,具有三个双层神经网络,其结构相同,第一层有 8 个神经元,隐藏层有 150 个神经元,连接在一起输出最终的偏航加速度,可适应不同的驾驶情况.
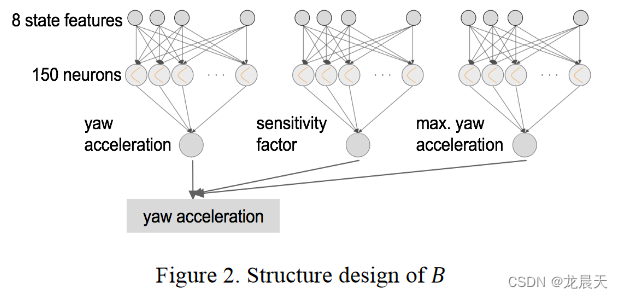
一个神经网络用于计算初始偏航加速度
a
y
a
w
_
p
r
e
a_{yaw\_pre}
ayaw_pre。另一种神经网络是计算一个称为灵敏度因子$ β_sen$ 的因子,以补偿两个连续步骤中的固定时间间隔。而第三个神经网络是输出一个可变的最大偏航加速度
a
y
a
w
_
p
r
e
a_{yaw\_pre}
ayaw_pre,用于根据当前输入状态给出学习到的偏航加速度的可调边界。 B的抽象数学公式在(8)中,B的结构如图2所示。
a
y
a
w
=
m
a
x
(
a
y
a
w
_
p
r
e
∗
β
s
e
n
,
a
y
a
w
_
m
a
x
)
a_{yaw}=max(a_{yaw\_pre}\ast\beta_{sen},a_{yaw\_max})
ayaw=max(ayaw_pre∗βsen,ayaw_max)
通过上述设计,可以从 B 获得给定状态的最佳动作。同时,使用 A 和 C 的附加信息计算 Q 值。还有一个目标 Q 网络,结构相同但不同参数,以计算目标 Q 值。权重根据目标 Q 值和在线 Q 值之间定义的损失进行更新,使用称为经验回放 [21] 的 RL 学习技术。
仿真结果
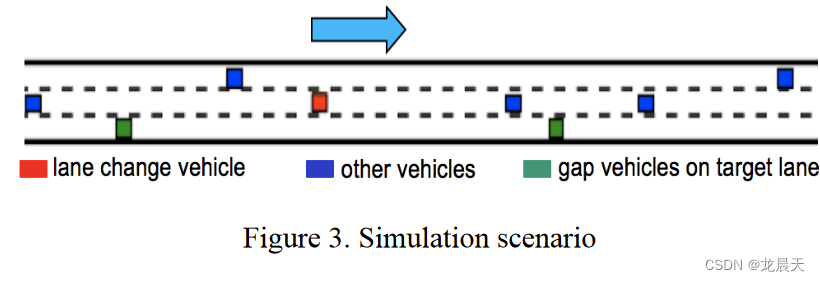
我们通过一个模拟平台测试我们提出的算法,在这个平台上,学习智能体能够一方面与驾驶环境交互,另一方面通过试验和实验错误来改进自己。模拟驾驶环境为单向三车道高速公路路段。路段长度为1000m,每车道宽度为3.75m。可以根据需要定制高速公路上的交通。例如,单个车辆的初始速度、出发时间和限速都可以设置为合理和实用范围内的随机值,以执行各种纵向行为。在我们目前的研究中,发车间隔在5s-10s之间,个人限速在80km/h-120km/h的范围内。使用所提出的 IDM,所有车辆都可以执行实际的跟车行为。可以使用不同的参数集生成不同的交通状况。仿真场景的场景如图 3 所示。
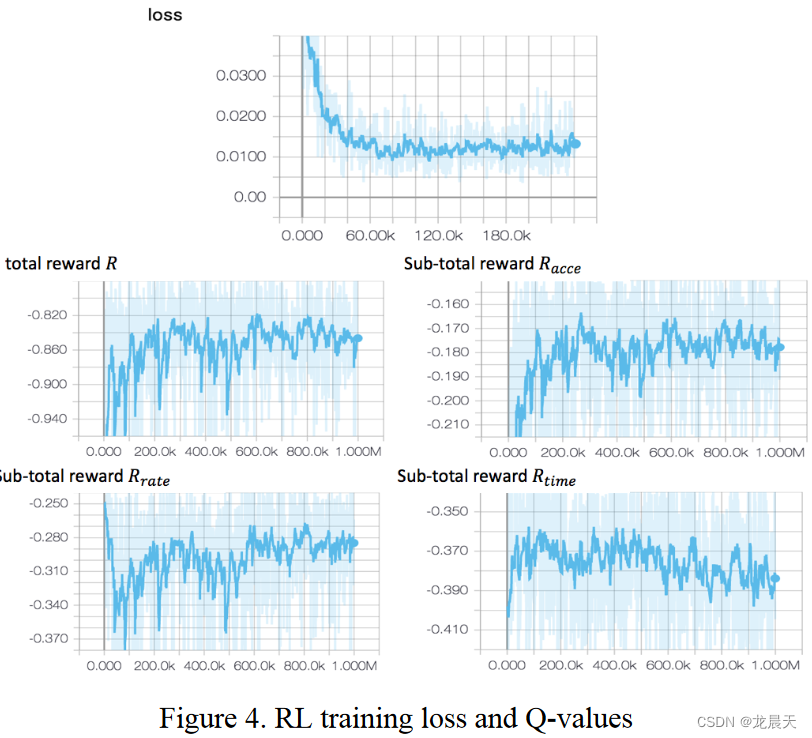
在训练过程中,我们设置训练步数为40000,时间步长间隔dt为0.1s,学习率α为0.01,折扣因子γ为0.9。在训练过程中,总共有大约 5000 辆车执行了变道操作。训练期间收集的损失和奖励如图 4 所示。
结论
在这项工作中,我们应用强化学习方法来学习交互式驾驶环境下的自动变道行为。状态空间和动作空间都被视为连续的,以学习更实用的驾驶操作。二次函数的独特格式用作 Qfunction 逼近器,其中系数是从神经网络学习的。奖励函数定义为偏航率、偏航加速度和换道时间,用于训练平稳高效的换道行为。为了实施所提出的方法,我们开发了一个仿真平台,可以通过调整交通密度、初始速度、限速等来生成不同的仿真场景。初步训练结果显示学习框架中定义的损失和奖励收敛,表明有前途的尝试。
-
我们研究的下一步是扩展 RL 智能体在不同道路几何形状和不同交通流量条件下的测试,以增强其在复杂驾驶场景中的鲁棒性和适应性,这是该方法处理.
-
其次,将换道性能(如横向位置偏差和转向角等)以及收敛趋势与现有的基于优化的方法(如MPC)进行比较,以进行验证和验证。
-
此外,另一个有希望的增强是结合 RL 和 MPC 以充分利用这两种方法。所提出的体系结构可以通过扩展神经网络的第一层来适应来自图像模块的大而模糊的输入状态,然后为传统的基于优化的控制器输出参考指导以发出快速可靠的控制命令来建立机动车。




![回文子串的数量[寻找回文子串的完整思路过程]](https://img-blog.csdnimg.cn/2ce16f8bb3e34207b42e59ee4a028d5e.png)