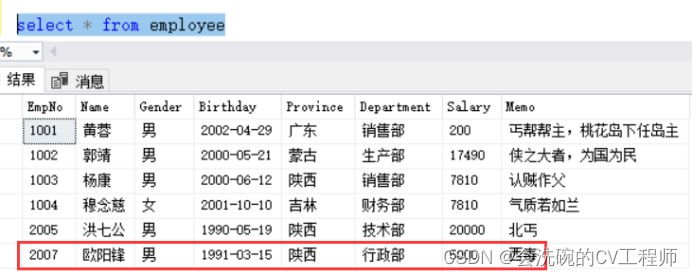
0基础学习diffusion_model扩散模型【易理解的公式推导】
- 一、概述
- 二、扩散过程(已知X0求Xt)
- 三、逆扩散过程(已知Xt求Xt-1)
- 1。算法流程图
- 四、结论
- 五、损失函数
- 六、心得体会(优缺点分析)
一、概述

DDPM论文链接:
Jonathan Ho_Denoising Diffusion Probabilistic Models(NeurIPS 2020)
去噪扩散概率模型。
项目地址:
https://github.com/hojonathanho/diffusion
本文是笔者在学习扩散模型时的一些笔记与心得,在公式推导过程中能够保证自己是一步一步去推导并且理解了的。概述是我认为比较重要的部分能够帮助理解公式的推导,具体的公式推导在每一小节中进行。
1、扩散过程:如上图所示,扩散过程为从右到左 X 0 → X T X_0 \rightarrow X_T X0→XT的过程,表示对图片逐渐加噪,且 X t + 1 X_{t+1} Xt+1是在 X t X_{t} Xt加躁得到的,其只受 X t X_{t} Xt的影响,因此扩散过程是一个马尔科夫过程。 X 0 X_0 X0表示从真实数据集中采样得到的一张图片,对 X 0 X_0 X0 添加T次噪声,图片逐渐变得模糊,当T足够大时, X T X_T XT为标准正态分布。在训练过程中,每次添加的噪声是已知的,即 q ( X t ∣ X t − 1 ) q(X_t|X_{t-1}) q(Xt∣Xt−1)是已知的,根据马尔科夫过程的性质,我们可以递归得到 q ( X t ∣ X 0 ) q(X_t|X_0) q(Xt∣X0),即 q ( X t ∣ X 0 ) q(X_t|X_0) q(Xt∣X0)是已知的。具体推导过程见本文的扩散过程。
2、逆扩散过程:如上图所示,逆扩散过程为从左到右 X T → X 0 X_T \rightarrow X_0 XT→X0的过程,表示从噪声中逐渐复原出图片。如果我们能够在给定 X t X_t Xt条件下知道 X t − 1 X_{t-1} Xt−1的分布,即如果我们可以知道 q ( X t − 1 ∣ X t ) q(X_{t-1}|X_t) q(Xt−1∣Xt),那我们就能够从任意一张噪声图片中经过一次次的采样得到一张图片而达成图片生成的目的。显然我们很难知道 q ( X t − 1 ∣ X t ) q(X_{t-1}|X_t) q(Xt−1∣Xt),因此我们才会用 p Θ ( X t − 1 ∣ X t ) p_{Θ}(X_{t-1}|X_t) pΘ(Xt−1∣Xt)来近似 q ( X t − 1 ∣ X t ) q(X_{t-1}|X_t) q(Xt−1∣Xt), p Θ ( X t − 1 ∣ X t ) p_{Θ}(X_{t-1}|X_t) pΘ(Xt−1∣Xt)就是我们要训练的网络,在原文中就是个U-Net。而很妙的是,虽然我们不知道 q ( X t − 1 ∣ X t ) q(X_{t-1}|X_t) q(Xt−1∣Xt),但是 q ( X t − 1 ∣ X t X 0 ) q(X_{t-1}|X_tX_0) q(Xt−1∣XtX0)却是可以用 q ( X t ∣ X 0 ) q(X_t|X_0) q(Xt∣X0)和 q ( X t ∣ X t − 1 ) q(X_t|X_{t-1}) q(Xt∣Xt−1)表示的,即 q ( X t − 1 ∣ X t X 0 ) q(X_{t-1}|X_tX_0) q(Xt−1∣XtX0)是可知的,**因此我们可以用 q ( X t − 1 ∣ X t X 0 ) q(X_{t-1}|X_tX_0) q(Xt−1∣XtX0)q来指导 p Θ ( X t − 1 ∣ X t ) p_{Θ}(X_{t-1}|X_t) pΘ(Xt−1∣Xt)进行训练。**具体推导过程见本文的逆扩散过程。
二、扩散过程(已知X0求Xt)

- 第一步其实就是不断往输入数据中加噪声,最后就快变成了个纯噪声。
- 每一个时刻都要添加高斯噪声,后一时刻都是由前一刻是增加噪声得到。(马尔科夫过程)
- 其实这个过程可以看作是不断构建标签 (噪声) 的过程,后续会用到。
α
t
=
1
−
β
t
\alpha_{t}=1-\beta_{t}
αt=1−βt
β
\beta
β要越来越大,论文中
β
\beta
β是从0.0001 到 0.002 ,从而
α
\alpha
α 也就是要越来越小。
x
t
=
a
t
x
t
−
1
+
1
−
α
t
z
1
(1)
x_{t}=\sqrt{a_{t}} x_{t-1}+\sqrt{1-\alpha_{t}} z_{1} \tag{1}
xt=atxt−1+1−αtz1(1)
一开始加点噪就有效果,越往后得加噪越多才行。
但是现在咱们只能知道后一时刻分布是由前一时刻加噪得到的,但是整个序列咋算?
如果一个个来计算,那也太慢了吧,能不能直接Xt由X0直接就能算出来呢?咱们来试试看:
x
t
−
1
=
a
t
−
1
x
t
−
2
+
1
−
α
t
−
1
z
2
x_{t-1}=\sqrt{a_{t-1}} x_{t-2}+\sqrt{1-\alpha_{t-1}} z_{2}
xt−1=at−1xt−2+1−αt−1z2一步步来,再往前一时刻咱们也能算。继续代入公式(1):
x t = a t ( a t − 1 x t − 2 + 1 − α t − 1 z 2 ) + 1 − α t z 1 x_{t}=\sqrt{a_{t}}\left(\sqrt{a_{t-1}} x_{t-2}+\sqrt{1-\alpha_{t-1}} z_{2}\right)+\sqrt{1-\alpha_{t}} z_{1} xt=at(at−1xt−2+1−αt−1z2)+1−αtz1
其中每次加入的噪声都服从高斯分布
z
1
,
z
2
,
…
∼
N
(
0
,
I
)
z_{1}, z_{2}, \ldots \sim \mathcal{N}(0, \mathbf{I})
z1,z2,…∼N(0,I)
=
a
t
a
t
−
1
x
t
−
2
+
(
a
t
(
1
−
α
t
−
1
)
z
2
+
1
−
α
t
z
1
)
=\sqrt{a_{t} a_{t-1}} x_{t-2}+\left(\sqrt{a_{t}\left(1-\alpha_{t-1}\right)} z_{2}+\sqrt{1-\alpha_{t}} z_{1}\right)
=atat−1xt−2+(at(1−αt−1)z2+1−αtz1) 这步就展开而已。
=
a
t
a
t
−
1
x
t
−
2
+
1
−
α
t
α
t
−
1
z
ˉ
2
=\sqrt{a_{t} a_{t-1}} x_{t-2}+\sqrt{1-\alpha_{t} \alpha_{t-1}} \bar{z}_{2}
=atat−1xt−2+1−αtαt−1zˉ2 Z1与Z2都服从高斯分布,分别:
N
(
0
,
1
−
α
t
)
N
(
0
,
a
t
(
1
−
α
t
−
1
)
)
\begin{array}{l} \mathcal{N}\left(0,1-\alpha_{t}\right) \\ \mathcal{N}\left(0, a_{t}\left(1-\alpha_{t-1}\right)\right) \end{array}
N(0,1−αt)N(0,at(1−αt−1))
这里就是相加后仍服从高斯做了化简
N
(
0
,
σ
1
2
I
)
+
N
(
0
,
σ
2
2
I
)
∼
N
(
0
,
(
σ
1
2
+
σ
2
2
)
I
)
\mathcal{N}\left(0, \sigma_{1}^{2} \mathbf{I}\right)+\mathcal{N}\left(0, \sigma_{2}^{2} \mathbf{I}\right) \sim \mathcal{N}\left(0,\left(\sigma_{1}^{2}+\sigma_{2}^{2}\right) \mathbf{I}\right)
N(0,σ12I)+N(0,σ22I)∼N(0,(σ12+σ22)I)
不断迭代:令
α
ˉ
t
=
∏
i
=
1
t
α
i
\bar{\alpha}_{t}=\prod_{i=1}^{t} \alpha_{i}
αˉt=∏i=1tαi
x
t
=
α
‾
t
x
0
x_t=\sqrt {\overline{\alpha}_ {t}}x_ {0}
xt=αtx0 +
1
−
α
‾
t
\sqrt {1-\overline {\alpha} }_ {t}
1−αt
z
‾
t
\overline {z}_t
zt
规律是任意时刻的分布都可以直接通过X0的初始状态算出来。
加噪过程已知,后面便是去噪生成。
三、逆扩散过程(已知Xt求Xt-1)

首先看
X
−
t
−
1
X-{t-1}
X−t−1的推导公式。
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
(2)
q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathbf{x}_{0}\right)=q\left(\mathbf{x}_{t} \mid \mathbf{x}_{t-1}, \mathbf{x}_{0}\right) \frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{0}\right)}{q\left(\mathbf{x}_{t} \mid \mathbf{x}_{0}\right)}\tag{2}
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)(2)对于这个公式其实就是一个贝叶斯公式。
q
(
x
t
−
1
∣
x
t
)
=
q
(
x
t
x
t
−
1
)
q
(
x
t
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
)
q
(
x
t
)
q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)=\frac{q\left(\mathbf{x}_{t} \mathbf{x}_{t-1}\right)}{q(\mathbf{x}_{t})}=q(\mathbf{x}_{t}\mid\mathbf{x}_{t-1})\frac{q(\mathbf{x}_{t-1})}{q(\mathbf{x}_{t})}
q(xt−1∣xt)=q(xt)q(xtxt−1)=q(xt∣xt−1)q(xt)q(xt−1)
然后在已知X0的情况下加一个X0就是公式(2)。
然后令
α
ˉ
t
=
∏
i
=
1
t
α
i
\bar{\alpha}_{t}=\prod_{i=1}^{t} \alpha_{i}
αˉt=∏i=1tαi
q
(
x
t
−
1
∣
x
0
)
=
a
‾
t
−
1
x
0
+
1
−
a
ˉ
t
−
1
z
∼
N
(
a
‾
t
−
1
x
0
,
1
−
a
ˉ
t
−
1
)
q
(
x
t
∣
x
0
)
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
∼
N
(
α
ˉ
t
x
0
,
1
−
α
ˉ
t
)
q
(
x
t
∣
x
t
−
1
,
x
0
)
=
a
t
x
t
−
1
+
1
−
α
t
z
∼
N
(
a
t
x
t
−
1
,
1
−
α
t
)
\begin{array}{l} q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{0}\right)=\sqrt{\overline{a}_{t-1}} x_{0}+\sqrt{1-\bar{a}_{t-1}} z\sim \mathcal{N}\left(\sqrt{\overline{a}_{t-1}}x_{0}, 1-\bar{a}_{t-1}\right) \\ q\left(\mathbf{x}_{t} \mid \mathbf{x}_{0}\right)=\sqrt{\bar{\alpha}_{t}} x_{0}+\sqrt{1-\bar{\alpha}_{t}} z\sim \mathcal{N}\left(\sqrt{\bar{\alpha}_{t}} x_{0}, 1-\bar{\alpha}_{t}\right) \\ q\left(\mathbf{x}_{t} \mid \mathbf{x}_{t-1}, \mathbf{x}_{0}\right)=\sqrt{a_{t}} x_{t-1}+\sqrt{1-\alpha_{t}} z\sim \mathcal{N}\left(\sqrt{a_{t}} x_{t-1}, 1-\alpha_{t}\right) \end{array}
q(xt−1∣x0)=at−1x0+1−aˉt−1z∼N(at−1x0,1−aˉt−1)q(xt∣x0)=αˉtx0+1−αˉtz∼N(αˉtx0,1−αˉt)q(xt∣xt−1,x0)=atxt−1+1−αtz∼N(atxt−1,1−αt)
可见这三项都是已知的,分布也已经知道了。
然后
q
(
x
t
−
1
∣
x
t
,
x
0
)
q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathbf{x}_{0}\right)
q(xt−1∣xt,x0)的分布也就是:
∝
exp
(
−
1
2
(
(
x
t
−
α
t
x
t
−
1
)
2
β
t
+
(
x
t
−
1
−
α
ˉ
t
−
1
x
0
)
2
1
−
α
ˉ
t
−
1
−
(
x
t
−
α
ˉ
t
x
0
)
2
1
−
α
ˉ
t
)
)
\propto \exp \left(-\frac{1}{2}\left(\frac{\left(\mathbf{x}_{t}-\sqrt{\alpha_{t}} \mathbf{x}_{t-1}\right)^{2}}{\beta_{t}}+\frac{\left(\mathbf{x}_{t-1}-\sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_{0}\right)^{2}}{1-\bar{\alpha}_{t-1}}-\frac{\left(\mathbf{x}_{t}-\sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}\right)^{2}}{1-\bar{\alpha}_{t}}\right)\right)
∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))
把标准的正太分布展开后也就是一个e的指数函数,乘法和除法分别对应指数的加法和减法。
然后继续化简:(因为只关心
X
t
−
1
X_{t-1}
Xt−1所以将含有
X
t
−
1
X_{t-1}
Xt−1的项开方并化简,
X
t
与
X
0
X_{t}与X_{0}
Xt与X0当常数)
=
exp
(
−
1
2
(
x
t
2
−
2
α
t
x
t
x
t
−
1
+
α
t
x
t
−
1
2
β
t
+
x
t
−
1
2
−
2
α
ˉ
t
−
1
x
0
x
t
−
1
+
α
ˉ
t
−
1
x
0
2
1
−
α
ˉ
t
−
1
−
(
x
t
−
α
ˉ
t
x
0
)
2
1
−
α
ˉ
t
)
)
=\exp \left(-\frac{1}{2}\left(\frac{\mathbf{x}_{t}^{2}-2 \sqrt{\alpha_{t}} \mathbf{x}_{t} \mathbf{x}_{t-1}+\alpha_{t} \mathbf{x}_{t-1}^{2}}{\beta_{t}}+\frac{\mathbf{x}_{t-1}^{2}-2 \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_{0} \mathbf{x}_{t-1}+\bar{\alpha}_{t-1} \mathbf{x}_{0}^{2}}{1-\bar{\alpha}_{t-1}}-\frac{\left(\mathbf{x}_{t}-\sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}\right)^{2}}{1-\bar{\alpha}_{t}}\right)\right)
=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))
=
exp
(
−
1
2
(
(
α
t
β
t
+
1
1
−
α
ˉ
t
−
1
)
x
t
−
1
2
−
(
2
α
t
β
t
x
t
+
2
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
x
t
−
1
+
C
(
x
t
,
x
0
)
)
)
=\exp \left(-\frac{1}{2}\left(\left(\frac{\alpha_{t}}{\beta_{t}}+\frac{1}{1-\bar{\alpha}_{t-1}}\right) \mathbf{x}_{t-1}^{2}-\left(\frac{2 \sqrt{\alpha_{t}}}{\beta_{t}} \mathbf{x}_{t}+\frac{2 \sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}} \mathbf{x}_{0}\right) \mathbf{x}_{t-1}+C\left(\mathbf{x}_{t}, \mathbf{x}_{0}\right)\right)\right)
=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
其中C是常数项。
类似于:
exp
(
−
(
x
−
μ
)
2
2
σ
2
)
=
exp
(
−
1
2
(
1
σ
2
x
2
−
2
μ
σ
2
x
+
μ
2
σ
2
)
)
\exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right)=\exp \left(-\frac{1}{2}\left(\frac{1}{\sigma^{2}} x^{2}-\frac{2 \mu}{\sigma^{2}} x+\frac{\mu^{2}}{\sigma^{2}}\right)\right)
exp(−2σ2(x−μ)2)=exp(−21(σ21x2−σ22μx+σ2μ2))
可以求得期望和方差。
其实:
q
(
X
t
−
1
∣
X
t
X
0
)
=
1
2
π
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
exp
(
−
1
2
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
(
X
t
−
1
2
−
2
(
(
1
−
α
ˉ
t
−
1
)
α
t
X
t
1
−
α
ˉ
t
+
β
t
α
ˉ
t
−
1
X
0
1
−
α
ˉ
t
)
X
t
−
1
+
C
(
X
0
,
X
t
)
q\left(X_{t-1} \mid X_{t} X_{0}\right)=\frac{1}{\sqrt{2 \pi \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}} \beta_{t}}} \exp \left(-\frac{1}{2 \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}} \beta_{t}}\left(X_{t-1}^{2}-2\left(\frac{\left(1-\bar{\alpha}_{t-1}\right) \sqrt{\alpha_{t}} X_{t}}{1-\bar{\alpha}_{t}}+\frac{\beta_{t} \sqrt{\bar{\alpha}_{t-1}} X_{0}}{1-\bar{\alpha}_{t}}\right) X_{t-1}\right.\right.+C(X_0,X_t)
q(Xt−1∣XtX0)=2π1−αˉt1−αˉt−1βt1exp(−21−αˉt1−αˉt−1βt1(Xt−12−2(1−αˉt(1−αˉt−1)αtXt+1−αˉtβtαˉt−1X0)Xt−1+C(X0,Xt)
即:
q
(
X
t
−
1
∣
X
t
X
0
)
=
N
(
X
t
−
1
;
(
1
−
α
ˉ
t
−
1
)
α
t
X
t
1
−
α
ˉ
t
+
β
t
α
ˉ
t
−
1
X
0
1
−
α
ˉ
t
,
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
)
q\left(X_{t-1} \mid X_{t} X_{0}\right)=N\left(X_{t-1} ; \frac{\left(1-\bar{\alpha}_{t-1}\right) \sqrt{\alpha_{t}} X_{t}}{1-\bar{\alpha}_{t}}+\frac{\beta_{t} \sqrt{\bar{\alpha}_{t-1}} X_{0}}{1-\bar{\alpha}_{t}}, \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}} \beta_{t}\right)
q(Xt−1∣XtX0)=N(Xt−1;1−αˉt(1−αˉt−1)αtXt+1−αˉtβtαˉt−1X0,1−αˉt1−αˉt−1βt)
但是现在的问题是没有
X
0
X_0
X0,我们需要用
X
t
X_t
Xt来替换它。
即:
x
0
=
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
z
t
)
,
z
t
是标准的正太分布。
\mathbf{x}_{0}=\frac{1}{\sqrt{\bar{\alpha}_{t}}}\left(\mathbf{x}_{t}-\sqrt{1-\bar{\alpha}_{t}} \mathbf{z}_{t}\right),z_t是标准的正太分布。
x0=αˉt1(xt−1−αˉtzt),zt是标准的正太分布。
代入化简,很巧妙的是:
q
(
X
t
−
1
∣
X
t
X
0
)
=
N
(
X
t
−
1
;
1
α
t
X
t
−
β
t
α
t
(
1
−
α
ˉ
t
)
Z
,
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
)
,
Z
∼
N
(
0
,
I
)
q\left(X_{t-1} \mid X_{t} X_{0}\right)=N\left(X_{t-1} ; \frac{1}{\sqrt{\alpha_t}} X_{t}-\frac{\beta_{t}}{\sqrt{\alpha_{t}\left(1-\bar{\alpha}_{t}\right)}} Z, \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}} \beta_{t}\right), Z \sim N(0, I)
q(Xt−1∣XtX0)=N(Xt−1;αt1Xt−αt(1−αˉt)βtZ,1−αˉt1−αˉt−1βt),Z∼N(0,I)
其中
z
t
z_t
zt是每一时刻的噪音。
- 用模型来计算,论文里用Unet来玩,模型的输入有两个,分别是当前时刻的分布和时刻t
1。算法流程图

核心是两个公式:
x
t
=
α
‾
t
x
0
+
1
−
α
‾
t
z
‾
t
(a)
x_t=\sqrt {\overline{\alpha}_ {t}}x_ {0} + \sqrt {1-\overline {\alpha} }_ {t}\overline {z}_t\tag{a}
xt=αtx0+1−αtzt(a)
x
t
−
1
=
μ
t
+
σ
t
x
t
(b)
x_{t-1}=\mu_t+\sigma_tx_t\tag{b}
xt−1=μt+σtxt(b)
其中的一些参数均能求出。
四、结论
简单的说,扩散模型的目的是希望学习出一个
p
Θ
(
X
t
−
1
∣
X
t
)
p_{Θ}(X_{t-1}|X_t)
pΘ(Xt−1∣Xt),即能够从噪声图恢复出原图。
为了达到这一个目的,我们使用
q
(
X
t
−
1
∣
X
t
X
0
)
q(X_{t-1}|X_tX_0)
q(Xt−1∣XtX0)来监督
p
Θ
(
X
t
−
1
∣
X
t
)
p_{Θ}(X_{t-1}|X_t)
pΘ(Xt−1∣Xt)进行训练,
q
(
X
t
−
1
∣
X
t
X
0
)
q(X_{t-1}|X_tX_0)
q(Xt−1∣XtX0)是可以用
q
(
X
t
∣
X
0
)
q(X_t|X_0)
q(Xt∣X0)和
q
(
X
t
∣
X
t
−
1
)
q(X_t|X_{t-1})
q(Xt∣Xt−1)表示的,即
q
(
X
t
−
1
∣
X
t
X
0
)
q(X_{t-1}|X_tX_0)
q(Xt−1∣XtX0)是已知的。
五、损失函数
打算后面再写一篇文章作为补充。
六、心得体会(优缺点分析)
扩散模型可以与许多CV方向的任务结合,是最新的生成模型。对于GAN而言需要训练两个网络,难度较大,不容易收敛,多样性较差,重点是骗过鉴别器。
扩散模型的优点:
- 训练稳定
- 更逼真
- 更具有可控性。
参考链接:
- https://www.bilibili.com/video/BV1B8411G7sV/?vd_source=5413f4289a5882463411525768a1ee27
- https://blog.csdn.net/Little_White_9/article/details/124435560?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167677401216782425144637%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=167677401216782425144637&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-124435560-null-null.142v73control,201v4add_ask,239v2insert_chatgpt&utm_term=diffusion%20model&spm=1018.2226.3001.4187










![[ 对比学习篇 ] 经典网络模型 —— Contrastive Learning](https://img-blog.csdnimg.cn/efd2df2692f540e3bca5e89c2c9e7660.png#pic_center)