在一些图计算的场景下,我们会遇到同时需要处理 OLTP 和 OLAP 的问题。而本文就给了一个 OLTP 与 OLAP 融合实践的指导思路,希望给你带来一点启发。
Dag Controller 介绍
Dag Controller 是 NebulaGraph 企业版的图系统,经过反复测试无误后已经发布,它主要解决的是 OLTP 和 OLAP 的融合问题,以及复杂场景下的图计算问题。
欢迎大家来详细了解下:https://docs.nebula-graph.com.cn/3.2.1/graph-computing/0.deploy-controller-analytics/。
下面,我对 Dag Controller 做个简单分享,欢迎大家留言一起探讨。
相信大家对 OLTP 和 OLAP 都不陌生,我这里再简单介绍下:OLTP 是一种快速响应、实时在线的一种数据处理方式。与之对应的 OLAP,是一种离线的、复杂场景的数据计算方式。
对 NebulaGraph 来说,OLTP 有多种多样的查询语句,如:GO、MATCH 等。OLAP 有各种各样的图算法,如:PageRank、Louvian、WCC、KCore、Jaccard 等算法。
OLTP 和 OLAP 并不是各自独立存在的,举例来说,我们可以将 MATCH 跑出来的子图喂给 PageRank 算法,PageRank 跑出来的结果可以写入到 NebulaGraph,继续执行 MATCH 语句或其它算法。就像拼积木一样,可以将各种各样的 OLTP 和 OLAP 组装起来,形成一种更加复杂场景的数据处理方式。
Dag Controller 就是处理这种场景的系统,它负责 OLTP、OLAP 的串联和执行。
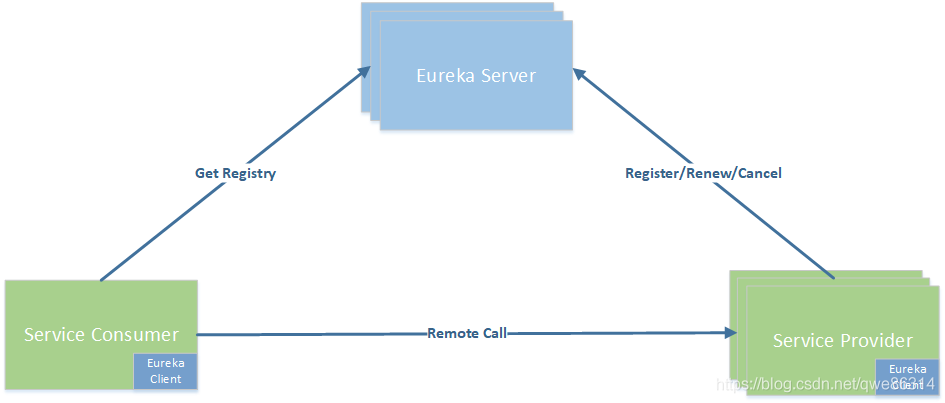
架构
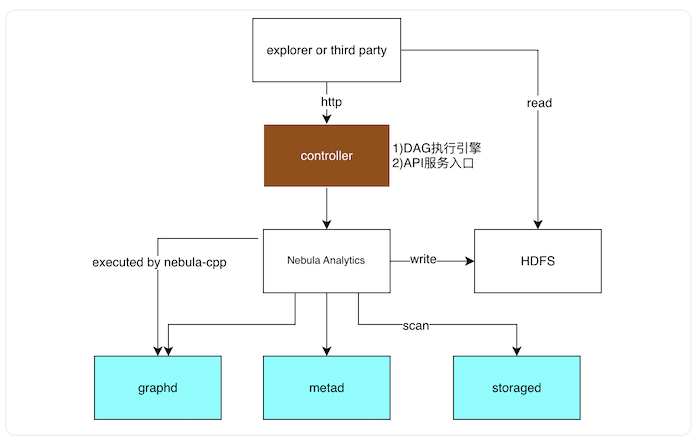
Dag Controller 的职责:
- 向外部提供了 http 接口,用于 Job 的提交、停止、删除等操作,以及系统环境的配置等。
- DAG 的执行:Dag Controller 在执行 DAG(有向无环图)时,OLAP 部分会调用 NebulaGraph Analytics 系统,OLTP 部分会调用 graphd 完成 nGQL 的执行。
NebulaGraph Analytics 是 NebulaGraph 的图计算系统,支持 PageRank、WCC、Louvain、Jaccard 等图分析算法,支持 HDFS 和 NebulaGraph 数据源。
graphd、metad、storaged 是 NebulaGraph 中的组件,graphd 主要负责 nGQL 的解析,storaged 负责数据的存储,metad 负责元数据的存储。
案例
案例 1
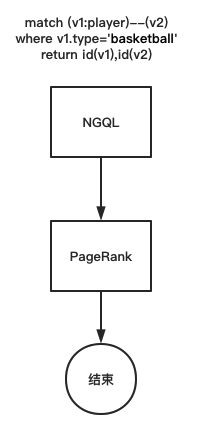
上图是一个对子图跑 PageRank 算法的 DAG 模型,首先用 nGQL 语句获取一个子图,然后再对这个子图跑 PageRank 算法。
当我们的图规模特别大的情况下,且我们只想对部分图数据跑算法,就可以使用这种方式。
案例 2
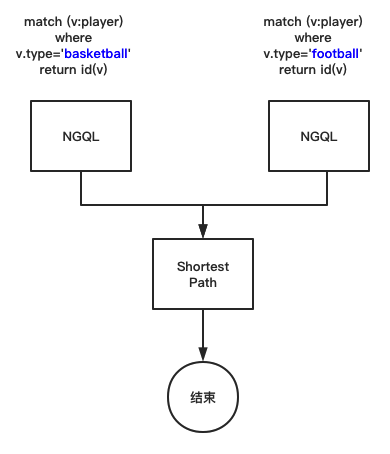
上图是一个对两类顶点计算最短路径的模型。
首先,分别用 nGQL 分别获取两个类别的顶点 ID。然后再把这两类顶点 ID 交给 ShortestPath 算法,ShortestPath 会在全图中计算这两类顶点之间的路径。
每个算法是可以设置基于全图跑算法,也可以基于子图跑算法。
DAG 模型有多种多样,可以根据不用的业务场景搭建不同的 DAG 模型。
技术实现
DAG 模型
DAG 指的是一个没有回路的有向图。DAG 的一个实例看作是一个 Job,一个 Job 有多个 Task。
Dag Controller 中的 Task 可以是一个 nGQL,也可以是一个图算法,如 PageRank、Louvain、SSSP 等。
Job 执行时候需要先对 Task 排序,网上有很多相关的代码,这里不再赘述。
并行执行
为了保障 DAG 的执行效率,多个 DAG 需要做到并行执行。同时,在一个 DAG 的内部,无上下游依赖关系的 Task 也需要并行执行。
如何做到多个 DAG 并行执行以及 Task 的并行执行?简单的说,通过两个线程池分别处理 DAG 和 Task。
具体描述如下:
- 系统启动时,分配 Job 线程池和 Task 线程池,分别处理 Job 的执行和 Task 的执行。
- 定时地从数据库中获取未执行的 Job,交由 Job 线程池运行。
- Job 执行时按照上下游的依赖关系对 Task 排序,然后依次判断每个 Task 的所有上游是否执行完成,上游执行完成后将此 Task 交给 Task 线程池执行,如果上游未执行完则等待。
- 在 Job 执行过程中,如果 Job 线程池满了之后,定时获取未执行 Job 时需要做等待处理。Task 线程池满了之后,也同样做等待处理。
类型校验
Task 之间的数据输入与输出存在数据类型校验问题,这里需要注意。比如:Task2 是 Task1 的下游,Task2 的输入需要的是 int 类型,而 Task1 输出也必须是 int 类型。
DAG 停止
在停止 Job 的时候,需要对多个并行运行的 Task 进行停止。一个 Task 的有准备阶段、运行阶段,并且运行阶段会存在跨机器、多进程的情况。停止 Job 需要避免孤儿进程的问题。
自定义算法支持
我们支持将客户的算法当作一种 Task,用于 DAG 的搭建。首先,在系统中配置算法相关的参数信息。在执行 Job 时,由系统负责运行与 Task 相对应的算法。
谢谢你读完本文 (///▽///)
要来近距离体验一把图数据库吗?现在可以用用 NebulaGraph Cloud 来搭建自己的图数据系统哟,快来节省大量的部署安装时间来搞定业务吧~ NebulaGraph 阿里云计算巢现 30 天免费使用中,点击链接来用用图数据库吧~
想看源码的小伙伴可以前往 GitHub 阅读、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呢~