欢迎关注“
计算机视觉研究院
”

计算机视觉研究院专栏
作者:Edison_G
ImageNet可以说是最受欢迎的图像分类基准,但它也是一个具有显著噪声的标签。最近的研究表明,许多样本包含多个类,尽管被假定为单个标签基准。因此,他们建议将ImageNet评估变成一个多标签任务,每个图像都有详尽的多标签注释。然而,他们还没有固定训练集,大概是因为强大的注释成本。

长按扫描二维码关注我们
回复“Re-image”获取论文
及Github代码
1.动机
所以作者认为在训练设置中,单标签注释和有效的多标签图像之间的不匹配是同样的问题。使用单标签注释,图像的随机裁剪可能包含与真值完全不同的目标,在训练过程中引入噪声甚至不正确的监督。因此,作者用多标签重新标记ImageNet训练集。
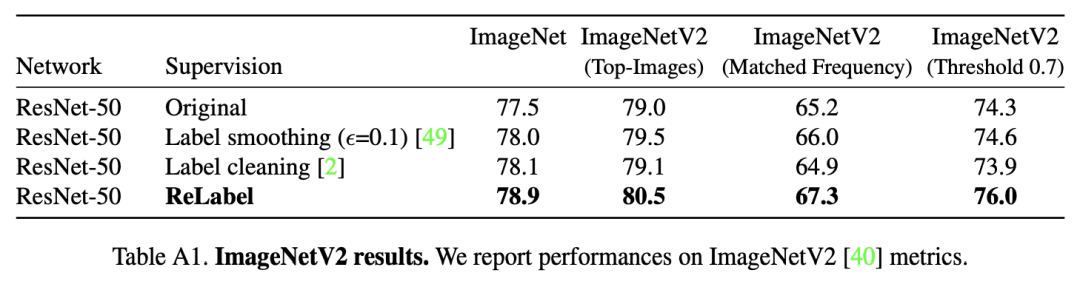
通过让一个强大的图像分类器,在额外的数据源上训练,生成多标签来解决注释成本障碍。利用最终池化层之前的像素级多标签预测,以利用额外的特定位置的监督信号。对重新标记的样本进行训练,可以全面提高模型性能。在ImageNet上,ResNet-50的分类精度达到了78.9%,局部多标签,这可以进一步提高到80.2%。作者表明,用局部多标签训练的模型也优于迁移学习到目标检测和实例分割任务的基线,以及各种鲁棒性基准。
2.引言
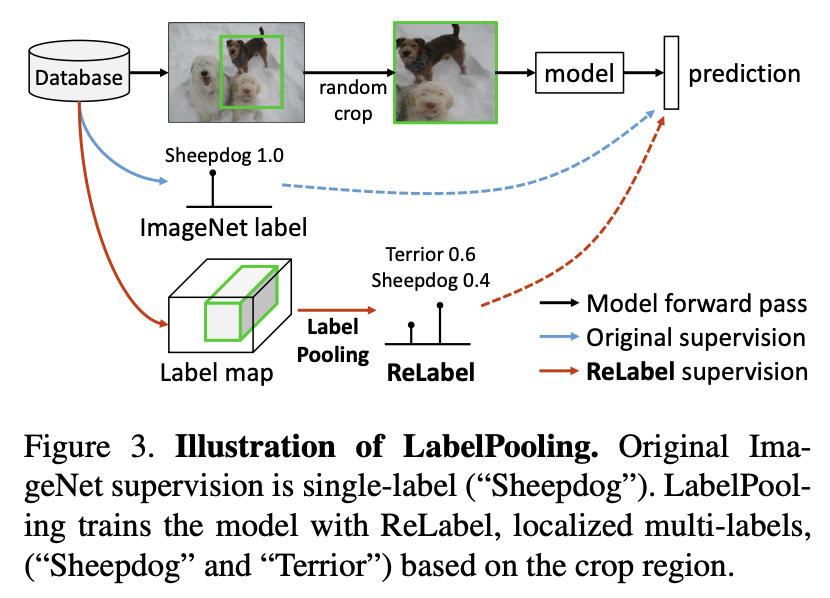
每个图像的目标类的多样性与单个标签的分配之间的不匹配不仅导致了评估问题,而且还导致了训练问题:监督变的嘈杂。random crop augmentation的广泛采用加剧了这一问题。图像的随机裁剪可能包含与原始单个标签完全不同的对象,在训练过程中引入潜在的错误监督信号,如下图所示。
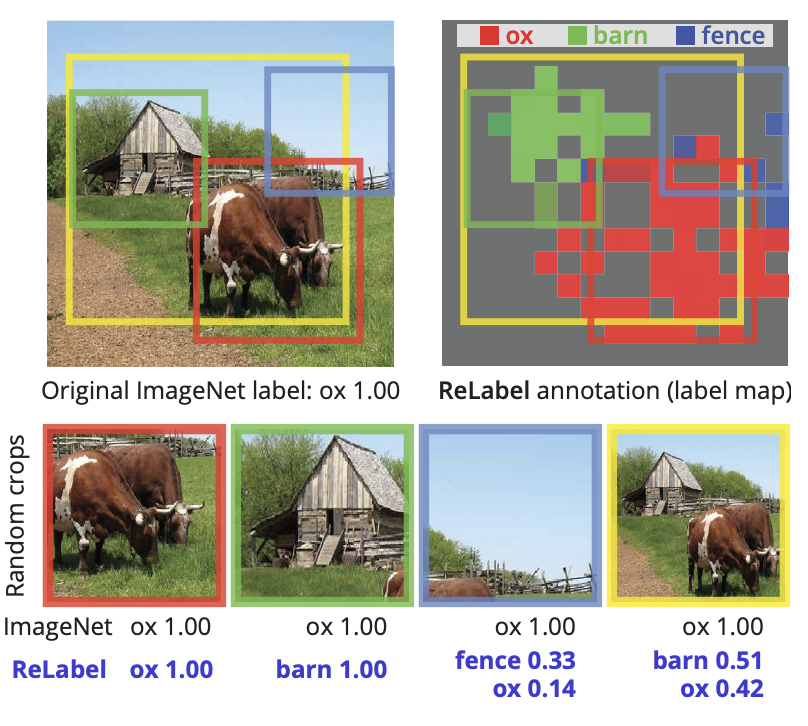
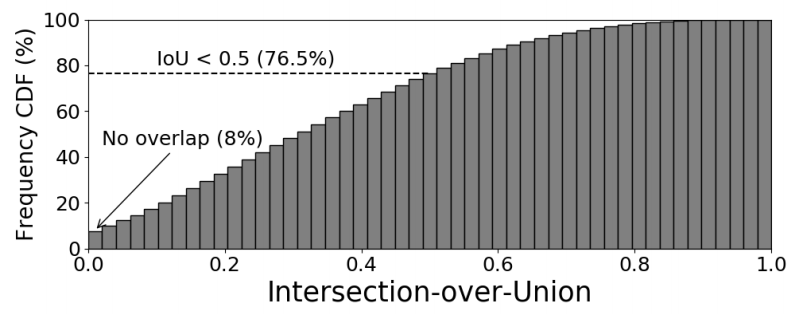
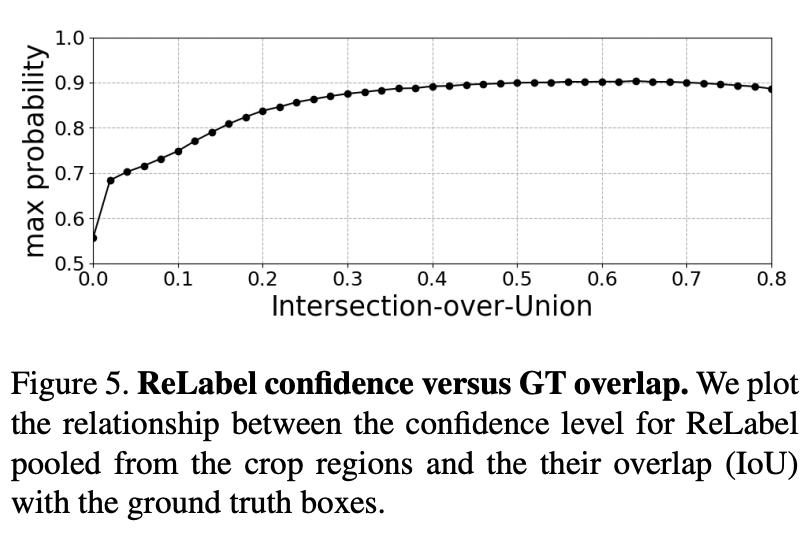
Random crop augmentation不仅对具有多个对象类的图像产生监督噪声。即使对于具有单个对象类的图像,随机裁剪通常也不包含前景对象。据估计,在标准的ImageNet训练设置下,8%的随机裁剪与真实值没有重叠。只有23.5%的随机裁剪与真实的IoU大于50%(见下图)。在ImageNet上训练模型不可避免地涉及到许多嘈杂的监督信号。
3.问题
Labeling issues in ImageNet
ImageNet有效地作为图像分类器的标准基准,Shankar等人认为:“方法在这个基准上的性能是活的还是死的”。
因此,基准本身的可靠性已成为认真研究和分析的主题。与许多其他数据集一样,ImageNet包含许多标签噪声。在ImageNet上最持久和系统的标签错误类型之一是错误的单个标签,指的是在多个现有类别中只有一个被注释的情况。这种错误很普遍,因为ImageNet包含许多具有多个类的图像。
Shankar等人和Beyer等人为错误的单个标签确定了三个子类别:
(1) 图像包含多个对象类,
(2 )存在多个同义或层次性的标签,包括另一个,
(3) 图像中固有的模糊性使多个标签可信。
这些研究已经将验证集标签细化为多标签,以对有效的多标签图像建立真实和公平的模型评估。然而,[Vaishaal Shankar, Rebecca Roelofs, Horia Mania, Alex Fang, Benjamin Recht, and Ludwig Schmidt. Evaluating machine accuracy on imagenet. In Proceedings of the 37th International Conference on Machine Learning, 2020]关注的重点只是验证,而不是训练。[Lucas Beyer, Olivier J Henaff, Alexander Kolesnikov, Xiaohua Zhai, and Aaron van den Oord. Are we done with imagenet? arXiv preprint arXiv:2006.07159, 2020]引入了一种清理方案,通过使用强分类器的预测来验证来删除具有潜在错误标签的训练样本。
作者的工作重点是对ImageNet训练标签的清理策略。和[Lucas Beyer, Olivier J Henaff, Alexander Kolesnikov, Xiaohua Zhai, and Aaron van den Oord. Are we done with imagenet? arXiv preprint arXiv:2006.07159, 2020]一样,作者也使用强分类器来清理训练标签。与其不同的是,作者纠正了错误的标签,而不是删除。
作者提出的标签也是在每个地区给出的。在实验中表明,新的方案比[Lucas Beyer, Olivier J Henaff, Alexander Kolesnikov, Xiaohua Zhai, and Aaron van den Oord. Are we done with imagenet? arXiv preprint arXiv:2006.07159, 2020]提高了性能。
4.Re-labeling ImageNet
Training a Classifier with Dense Multi-labels
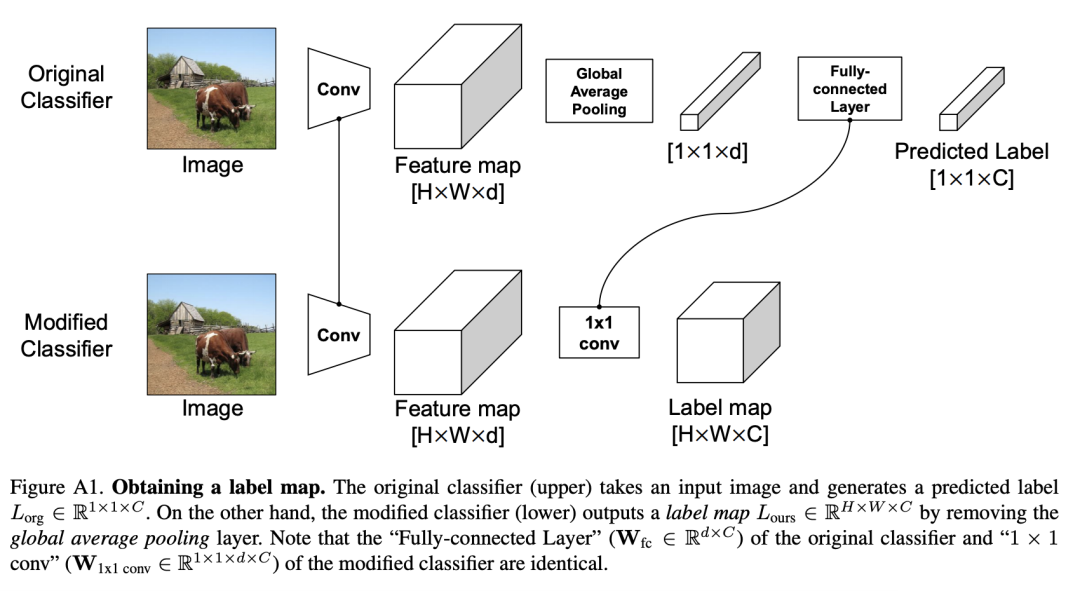
在获得了如上所述的密集多标签L∈RW×H×C之后,我们如何用它们训练分类器?
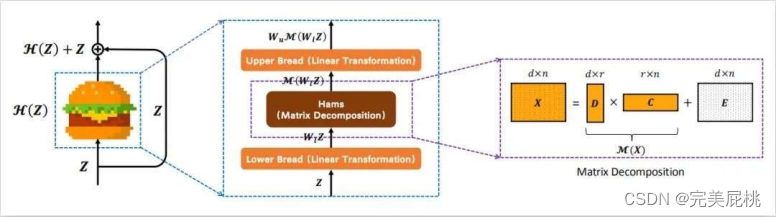
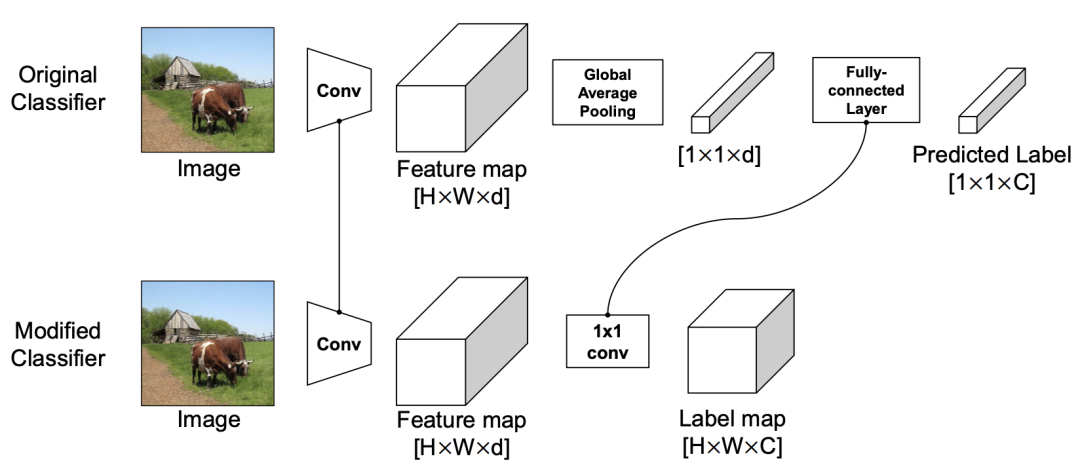
为此,提出了一种新的训练方案,LabelPooling(标签池化),它考虑了局部真值。在上图中显示了标签池化和原始ImageNet训练之间的区别。在一个标准的ImageNet训练设置中,随机裁剪的监督是由每个图像给出的单个标签真值给出的。另一方面,标签池加载一个预先计算的标签映射,并在标签映射上进行与随机裁剪坐标对应的区域池化操作。 作者采用RoIAlign区域池化方法,在集合预测映射上执行全局平均池化和Softmax操作,以获得[0,1]中的多标签真值向量,并与该模型进行训练。使用交叉熵损失,训练计划的伪代码实施情况如下:


Which machine annotator should we select?
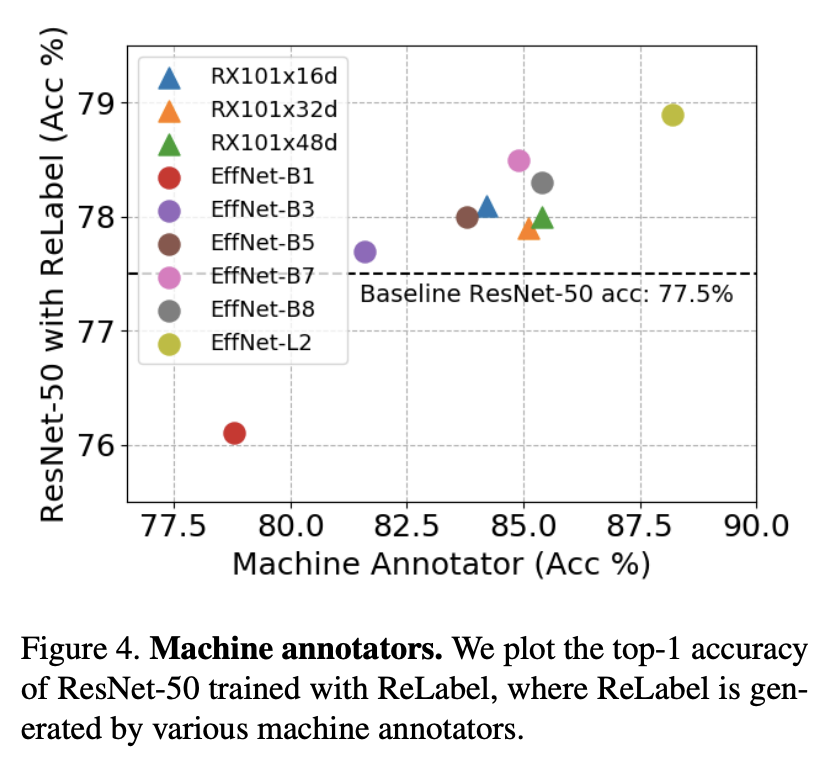
目标模型的性能总体上遵循machine annotator的性能。当机器监督不够强(例如,EfficientNet-B1)时,经过训练的模型表现出严重的性能下降(76.1%)。我们选择EfficientNet-L2作为机器注释器,在其余的实验中,ResNet-50(78.9%)的性能最好。
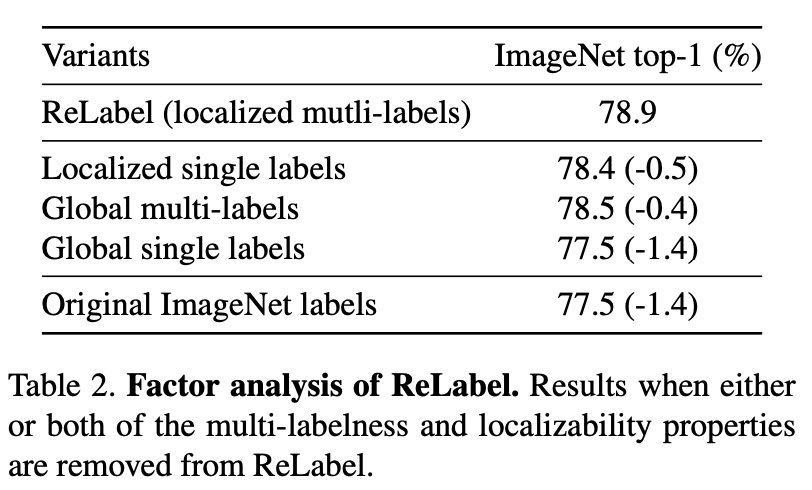
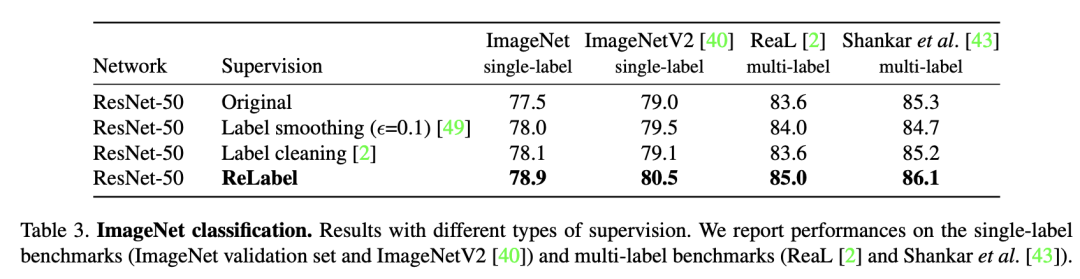
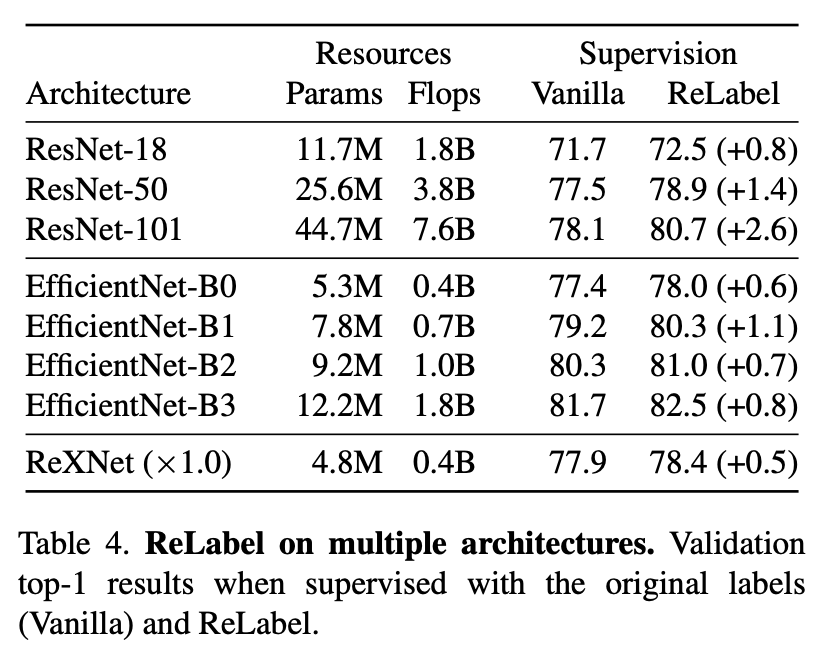
5.实验结果


© THE END
如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

计算机视觉研究院
长按扫描二维码关注我们
回复“Re-image”获取论文
及Github代码