五、分布式锁
1. 概念
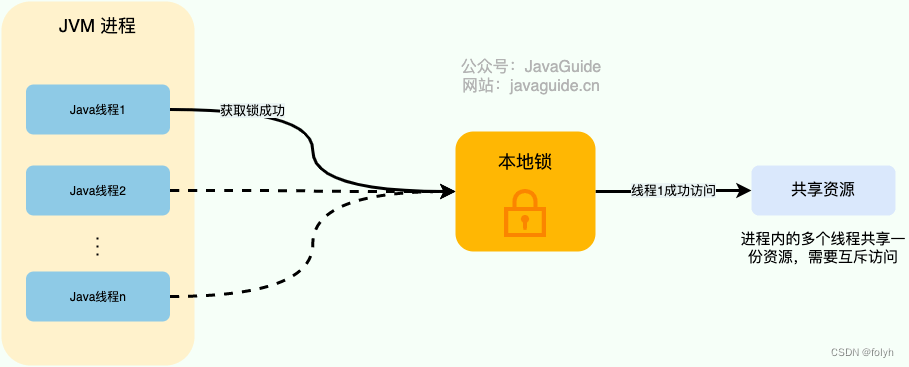
1.1 本地锁
使用ReetrantLock类和synchronized关键字JDK自带的本地锁来控制一个JVM进程内的多个线程对本地共享资源的访问。
1.2 分布式锁
分布式系统下,不同的服务器/客户端通常运行在独立的JVM进程上。
多个JVM进程共享一份资源的话,使用本地锁就无法实现资源的互斥访问。
通过分布式锁,能使得不在同一个JVM进程中的多个线程也能获取到同一把锁,进而实现共享资源的互斥访问。

1.2 分布式锁要满足的条件
(1)互斥
任意一个时刻,锁只能被一个线程持有;
(2)高可用
锁服务是高可用的
(3)可重入
一个节点获取了锁之后,还可以再次获取锁
一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁
2. Redis 分布式锁
不论是实现锁还是分布式锁,核心都在于“互斥”。
2.1 实现
在 Redis 中, SETNX 命令是可以帮助我们实现互斥。
(1)SETNX命令
即 SET if Not eXists (对应 Java 中的 setIfAbsent 方法)
如果 key 不存在的话,才会设置 key 的值。如果 key 已经存在, SETNX 啥也不做。
> SETNX lockKey uniqueValue
(integer) 1
> SETNX lockKey uniqueValue
(integer) 0
(2)DEL命令
删除对应的 key,即释放锁。
> DEL lockKey
(integer) 1
(3)防误删
为了误删到其他的锁,这里我们建议使用 Lua 脚本通过 key 对应的 value(唯一值)来判断。
选用 Lua 脚本是为了保证解锁操作的原子性。因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
// 释放锁时,先比较锁对应的 value 值是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
(4)简易实现图及优缺点

优缺点: 实现简单性能高效;
缺点: 比如释放锁的逻辑突然挂掉,可能导致锁无法被释放,进而造成共享资源无法再被其他线程/进程访问。
2.2 设置锁过期时间
为了避免锁无法被释放,可以 给这个 key(也就是锁) 设置一个过期时间
127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX
OK
(1)语句
lockKey : 加锁的锁名;
uniqueValue : 能够唯一标示锁的随机字符串;
NX : 只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
EX : 过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位)
(2)一定要保证设置指定key的值和过期时间是一个原子操作。
不然的依然可能会出现锁无法被释放的问题
(3)问题
如果操作共享资源的时间大于过期时间,就会出现锁提前过期的问题,进而导致分布式锁直接失效。
如果锁的超时时间设置过长,又会影响到性能。
2.3 实现锁优雅续期
Redisson 中的分布式锁自带自动续期机制
Redisson 是一个开源的 Java 语言 Redis 客户端,包括多种分布式锁的实现、 Redis 单机、Redis Sentinel 、Redis Cluster 等多种部署架构。
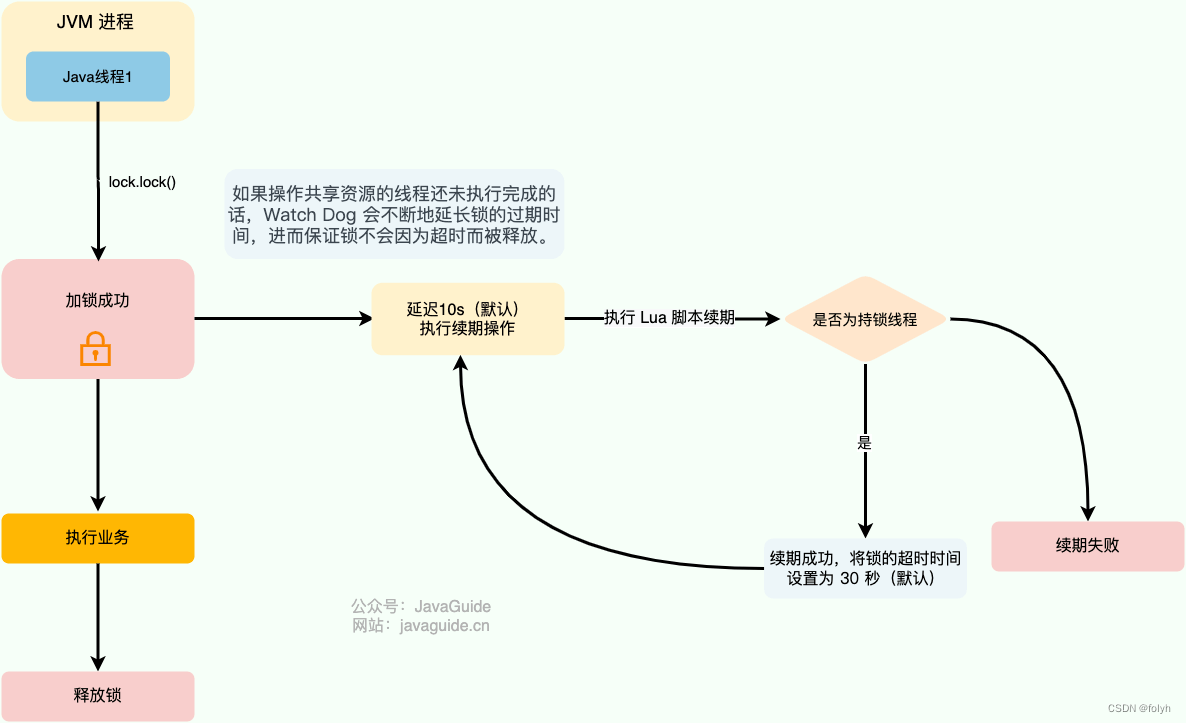
(1)提供了一个专门用来监控和续期锁的 Watch Dog( 看门狗)。
如果操作共享资源的线程还未执行完成的话,Watch Dog 会不断地延长锁的过期时间,进而保证锁不会因为超时而被释放。
(2)看门狗名字的由来于 getLockWatchdogTimeout() 方法:
//默认 30秒,支持修改
private long lockWatchdogTimeout = 30 * 1000;
public Config setLockWatchdogTimeout(long lockWatchdogTimeout) {
this.lockWatchdogTimeout = lockWatchdogTimeout;
return this;
}
public long getLockWatchdogTimeout() {
return lockWatchdogTimeout;
}
(3)renewExpiration() 方法包含了看门狗的主要逻辑
private void renewExpiration() {
//......
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//......
// 异步续期,基于 Lua 脚本
CompletionStage<Boolean> future = renewExpirationAsync(threadId);
future.whenComplete((res, e) -> {
if (e != null) {
// 无法续期
log.error("Can't update lock " + getRawName() + " expiration", e);
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
return;
}
if (res) {
// 递归调用实现续期
renewExpiration();
} else {
// 取消续期
cancelExpirationRenewal(null);
}
});
}
// 延迟 internalLockLeaseTime/3(默认 10s,也就是 30/3) 再调用
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
(4)看门狗没每过10秒就会判断是否需要执行续期操作,需要就将锁的超时时间设置为30秒,否则取消续期操作。
Watch Dog 通过调用 renewExpirationAsync() 方法实现锁的异步续期:
protected CompletionStage<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
// 判断是否为持锁线程,如果是就执行续期操作,就锁的过期时间设置为 30s(默认)
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}
renewExpirationAsync 方法其实是调用 Lua 脚本实现的续期,这样做主要是为了保证续期操作的原子性。
(6)如何使用 Redisson 实现分布式锁
以 Redisson 的分布式可重入锁 RLock 为例来说明:
<1> 代码如下:
// 1.获取指定的分布式锁对象
RLock lock = redisson.getLock("lock");
// 2.拿锁且不设置锁超时时间,具备 Watch Dog 自动续期机制
lock.lock();
// 3.执行业务
...
// 4.释放锁
lock.unlock();
<2> 只有未指定锁超时时间,才会使用到 Watch Dog 自动续期机制。
// 手动给锁设置过期时间,不具备 Watch Dog 自动续期机制
lock.lock(10, TimeUnit.SECONDS);
<3> 如果使用 Redis 来实现分布式锁的话,还是比较推荐直接基于 Redisson 来做的。
2.4 如何实现可重入锁?
可重入锁指的是在一个线程中可以多次获取同一把锁
如:一个线程在执行一个带锁的方法,该方法又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法即可重入,而无需重新获得锁。
java中的synchronized、ReentrantLock都属于可重入锁。
(1)可重入分布式锁的实现核心思路
线程在获取锁的时候判断是否为自己的锁,如果是就不用再重新获取了。
所以,我们可以为每个锁关联一个可重入计数器和一个占有它的线程。
当可重入计数器大于0则锁被占有,需要判断占有该锁的线程和请求获取锁的线程是否为同一个。
(2)推荐使用 Redisson
内置了多种类型的锁,如可重入锁(Reentrant Lock)、自旋锁(Spin Lock)、公平锁(Fair Lock)、多重锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)。
2.5 Redis 如何解决集群分布式锁的可靠性?
2.5.1 问题
Redis集群数据同步到各个节点是异步的,如果Redis主节点获取到锁后还没有同步到其他节点就宕机了,新的主节点依然可以获取到锁,所以多个应用服务就可以同时获取到锁。
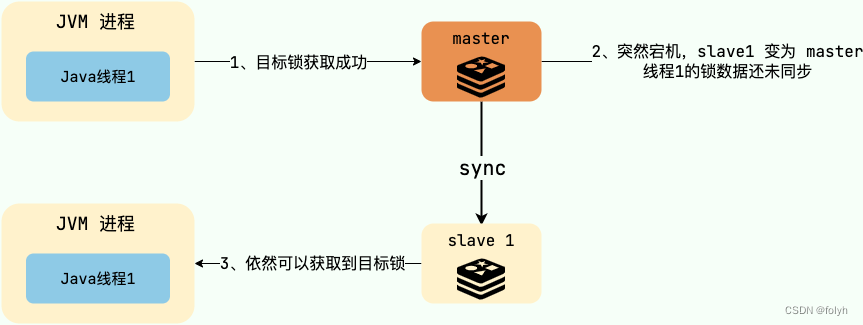
2.5.2 使用Redlock解决
(1)思想
让客户端Redis集群中的多个独立的Redis实例依次请求申请加锁。
如果客户端能够和半数以上的实例成功的完成加锁操作,那么就认为,客户端成功的获得分布式锁,否则加锁失败。
(2)即使部分 Redis 节点出现问题,只要保证 Redis 集群中有半数以上的 Redis 节点可用,分布式锁服务就是正常的。
(3)Redlock 是直接操作 Redis 节点的,并不是通过 Redis 集群操作的,这样才可以避免 Redis 集群主从切换导致的锁丢失问题。
(4)实际项目中不建议使用 Redlock 算法,成本和收益不成正比。
如果不是非要实现绝对可靠的分布式锁的话,其实单机版 Redis 就完全够了,实现简单,性能也非常高。
如果你必须要实现一个绝对可靠的分布式锁的话,可以基于 Zookeeper 来做,只是性能会差一些。
关于Redission实践,推荐这篇文章:
redission实践
六、分布式事务
1.事务
事务是逻辑上的一组操作,要么都执行,要么都不执行。
1.1 例子:转账
(1)将小明的余额减少1000元
(2)将小红的余额增加1000元。
将这个操作看成逻辑上的一个整体,要么成功,要么失败。
这样就不会出现小明余额减少而小红的余额却没有增加。

2.数据库事务
一般开发中事务没有特指就是数据库事务,尤其是在单体架构中接触最多。
2.1 作用
保证多个对数据库的操作要么全部执行成功,要么全部不执行。
# 开启一个事务
START TRANSACTION;
# 多条SQL语句
SQL1,SQL2....
# 提交事务
COMMIT;

2.2 ACID特性
(1)原子性(Atomicity)
操作要么全部执行成功,要么全部不执行。
(2)一致性(Consistency)
事务执行前后处于一致性状态(数据保持一致)
·
(3)隔离性(Isolation)
各事务之间独立互不干扰。
(4)持久性(Durability)
事务一旦提交,数据的改变是永久性的,即使这时候数据库发生故障,数据也不会丢失。

&&:只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障!
A、I、D是手段,C才是目的。

2.3 实现原理
以MySQL的InnoDB为例:
InnoDB引擎使用undo log(回滚日志)来保证事务的原子性,
通过锁机制、MVCC等手段来保证事务的隔离性(如默认的REPEATABLE-READ),
使用redo log(重做日志)保证事务的持久性。
3.分布式事务
3.1 概念
电商系统中,创建一个订单会涉及到:订单服务(订单数加1)、库存服务(库存减1)等服务,而这些服务都有独立的数据库。
(1)分布式事务是用来保证分布式系统下的一组操作要么都执行成功、要么都不执行。
(2)分布式事务的终极目标就是保证系统中多个相关联的数据库中的数据一致性。
4.分布式事务基础理论
4.1 CAP理论和BASE理论
详见我另一篇博客,链接:
分布式(二)
4.2 一致性的3种级别
(1)强一致性
系统写入了什么,读出来的就是什么。
(2)弱一致性
不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
(3) 最终一致性
弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
备注: 业界比较推崇最终一致性;不过某些对数据一致性要求十分严格的场景如银行转账还是要保证强一致性。
另外还有读写一致性、因果一致性等一致性模型,不过用的很少。
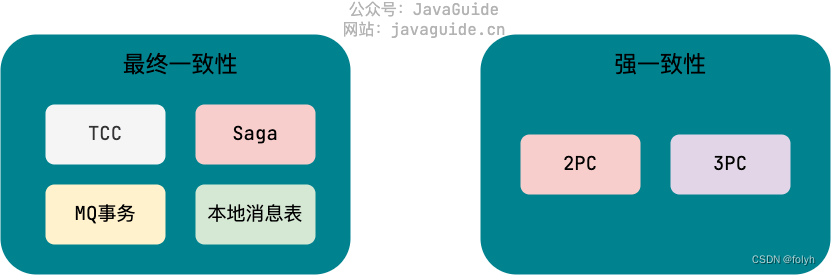
4.3 柔性事务
(1)柔性事务就是BASE理论+业务实践。
(2)目标
根据自身业务特性,通过适当的方式来保证系统数据的最终一致性。
如:TCC 、Saga 、MQ事务 、本地消息表
4.4 刚性事务
与柔性事务相对立,目标是强一致性。
如2PC 、3PC。
5.分布式事务解决方案
常见方案:
TCC 、Saga 、MQ事务(Kafka、RocketMQ) 、本地消息表、2PC、3PC
5.1 2PC、3PC(XA规范角色组成)

(1)AP(Application Program)
应用程序
(2)RM(Resource Manager)
资源管理器:事务的参与者,一般指数据库,分布式事务涉及到多个RM
(3)TM(Transaction Manager)
事务管理器(协调器):负责管理全局事务,分配事务的唯一标识,监控事务的执行进度,并负责事务的提交、回滚、失败恢复等

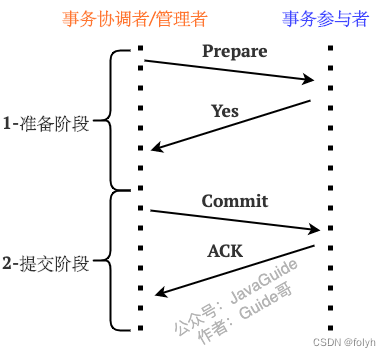
5.2 2PC(两阶段提交协议)
5.2.1 含义
(1)2:事务提交的2个阶段
(2)P:Prepare准备阶段
(3)C:Commit提交阶段
5.2.2 准备阶段流程
核心是询问事务参与者执行本地数据库操作是否成功
(1)TM事务管理者向所有涉及到的RM事务参与者发送消息询问:“你是否可以执行事务操作呢?”,并等待其回复
(2)RM事务参与者接收到消息后,开始执行本地数据库事务预操作,如redo log/ undo log日志,此时并不会提交事务
(3)RM事务参与者如果执行本地数据库事务操作成功,那就回复“Yes”表示我已就绪,否则就回复“No”表示我未就绪
5.2.3 提交阶段流程
核心是询问事务参与者提交本地事务是否成功。
5.2.3.1 就绪状态
当所有事务参与者都是就绪状态的话:
(1)TM事务管理者向所有RM事务参与者发送消息:“你们可以提交事务了”(Commit消息)
(2)RM事务参与者接收到Commit消息后执行提交本地数据库事务操作,执行完成之后释放整个事务期间所占用的资源
(3)RM事务参与者回复:“事务已经提交”(ACK消息)
(4)TM事务管理者收到所有RM事务参与者的ACK消息后,整个分布式事务过程正式结束
5.2.3.1 未就绪状态
当任一事务参与者是未就绪状态:
(1)TM事务管理者向所有RM事务参与者发送消息:“你们可以回滚事务了”(Rollback消息)
(2)RM事务参与者接收到Rollback消息后执行回滚本地数据库事务操作,执行完成之后释放整个事务期间所占用的资源
(3)RM事务参与者回复:“事务已经回滚”(ACK消息)
(4)TM事务管理者收到所有RM事务参与者的ACK消息后,整个分布式事务过程正式结束

5.2.4 总结
(1)准备阶段的主要目的
测试RM事务参与者能否执行本地数据库事务操作(这一步并不会提交事务)
(2)提交阶段中TM事务管理者会根据准备阶段中的RM事务参与者的消息来决定执行事务提交还是回滚操作。
(3)提交阶段之后一定会结束当前的分布式事务
5.2.5 优点
(1)实现简单
各大主流数据库如MySQL、Oracle都自己实现
(2)针对数据强一致性
5.2.6 存在的问题
(1)同步阻塞
TM事务参与者在正式提交事务之前,会一直占用相关的资源
比如用户小明转账给小红,那其他事务也操作用户小明或小红就会阻塞
(2)数据不一致
由于网络问题或者TM宕机都可能造成数据不一致。
比如在提交阶段,部分网络出现问题导致部分参与者收到不到Commit或者Rollback消息就会导致数据不一致
(3)单点问题
如果TM事务管理者在准备阶段完成之后挂掉,事务参与者就会一直卡在提交阶段。
5.3 3PC(三阶段提交协议)
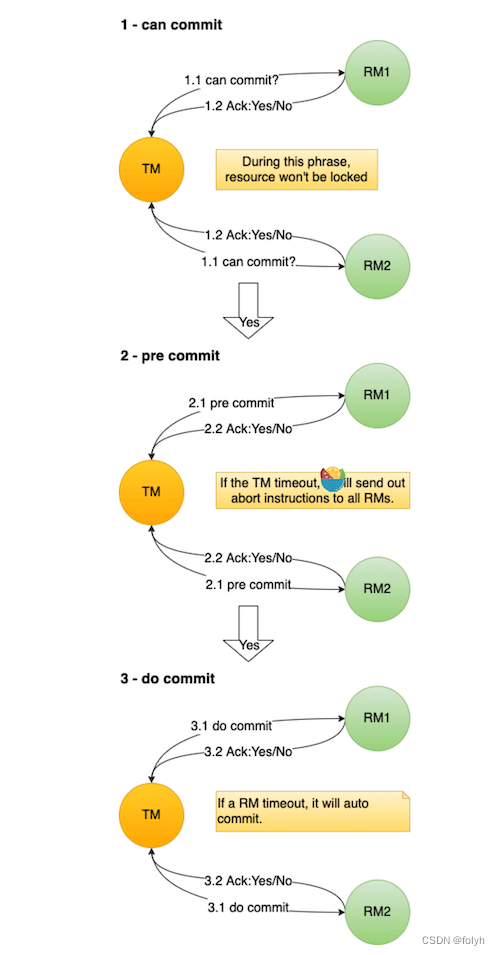
3PC把2PC中的准备阶段做了进一步细化,分为2个阶段:
(1)准备阶段(CanCommit)
(2)预提交阶段(PreCommit)
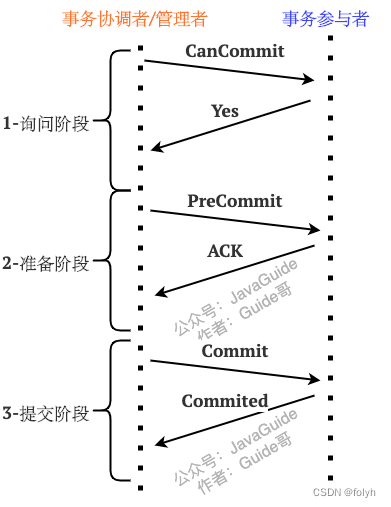
5.3.1 准备阶段(CanCommit)
(1)TM事务管理者向所有涉及到的RM发送准备请求,询问事务参与者RM能否执行本地数据库事务操作。
(2)RM事务参与者回复“Yes”、“No”,或者直接超时
(3)如果任一RM事务参与者回复“No”或者超时,TM事务管理者就中断事务(向所有参与者发送“Abort”消息)。
否则进入预提交阶段。
5.3.2 预提交阶段(PreCommit)
(1)TM事务管理者向所有涉及到的RM发送预提交请求
(2)如果任一RM事务参与者回复“No”或者超时,TM事务管理者就中断事务(向所有参与者发送“Abort”消息)。
否则进入执行事务提交阶段。
(3)当所有事务参与者RM都返回“Yes”之后,事务参与者RM才会执行本地数据库事务预操作redo log/ undo log日志。
5.3.3 执行事务提交阶段(DoCommit)
执行事务提交阶段就开始进行真正的事务提交。
(1)TM事务管理者向所有涉及到的RM发送执行事务提交请求
(2)RM事务参与者收到消息后开始正式提交事务,并在完成事务提交后释放占用的资源
(3)事务结束
<1> RM正确提交事务
TM事务管理者收到所有RM事务参与者正确提交事务的消息后,整个分布式事务过程正式结束
<2> RM未正确提交事务或者超时
a. 如果任一RM事务参与者没有正确提交事务或者超时的话,TM事务管理者就中断事务。
并向所有RM事务参与者发送“Abort”消息。
b.RM事务参与者接收到Abort请求后,执行本地数据库事务回滚
c.TM事务管理者收到所有RM事务参与者的回滚数据库事务的消息后,整个分布式事务过程正式结束
5.3.4 总结
(1)3PC把2PC中的准备阶段进行细化了
(2)3PC还同时在TM事务管理者和RM事务参与者中引入了超时机制
如果在一定时间内没有收到事务参与者的消息就默认失败,进而避免事务参与者一直阻塞占用自用资源。(而2PC只有事务管理者才拥有超时机制)
(3)问题
3PC并没有完美解决2PC的阻塞问题,还引入了一些新问题如性能糟糕,而且依然存在数据不一致的问题。因此其应用不广泛,多数应用会选择通过复制状态机来解决2PC的阻塞问题。
5.4 TCC(补偿事务)
5.4.1 三阶段
(1)Try尝试阶段
尝试执行:完成业务检查,并预留好必需的业务资源
场景:转账中检查账户余额是否充足,预留的资源就是转账资金
(2)Confirm确认阶段
确认执行:当所有事务参与者的Try阶段执行成功就会执行Confirm,Confirm阶段会处理Try阶段预留的业务资源。否则就执行Cancel。
场景:如果Try阶段执行成功的话,Confirm阶段就会执行真正的扣钱操作
(3)Cancel取消阶段
取消执行:释放Try阶段预留的业务资源
5.4.2 流程
一般需要自己实现Try、Confirm、Cancel 3个方法,来达到最终一致性
(1)正常情况下会执行Try、Confirm方法

(2)异常情况下会执行Try、Cancel 方法
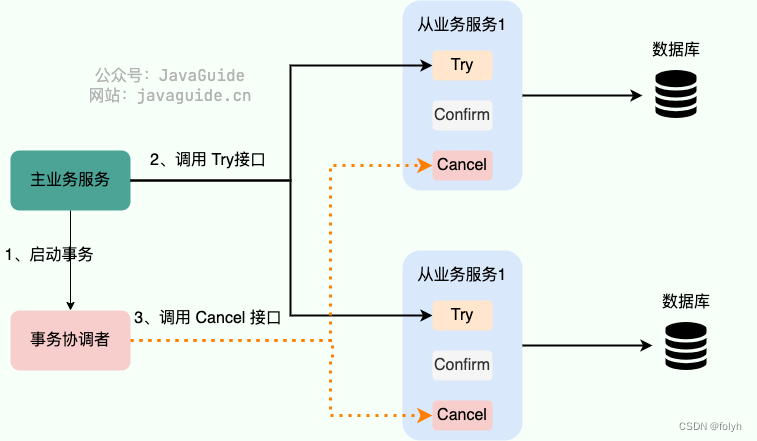
(3)Confirm或Cancel阶段失败了
代码没有特殊bug的话Confirm或Cancel阶段出现问题概率比较小
<1> TCC会记录事务日志并持久化事务日志到某种存储介质上
存储介质如本地文件、关系型数据库、Zookeeper
事务日志包含了事务的执行状态,通过事务执行状态可以判断事务是提交成功了还是失败了,以及具体失败在哪一步
如果事务提交成功(没有抛任何异常)就可以删除对应的事务日志,节省资源。
<2> 如果发现是Confirm或Cancel阶段失败,会进行重试。
继续尝试执行Confirm或Cancel阶段的逻辑
重试次数通常为6次,如果超过重试次数还未成功的,就需要人工介入处理了
5.4.3 TCC和2PC/3PC有什么区别
TCC模式不需要依赖于底层数据资源的事务支持,但是需要我们手动实现更多的代码,属于侵入业务代码的一种分布式解决方案。

(1)2PC/3PC依靠数据库或者存储资源层面的事务,TCC主要通过修改业务代码来实现
(2)2PC/3PC属于业务代码无侵入,TCC对业务代码有侵入
(3)2PC/3PC追求的是强一致性,在两阶段提交的整个过程中,一直会持有数据库的锁。
TCC追求的是最终一致性,不会一直持有各个业务资源的锁。
5.4.4 TCC的实现开源框架
(1)ByteTCC
ByteTCC基于Try-Confirm-Cancel(TCC)机制的分布式事务管理器的是实现。
(2)Seata
下面会讲
(3)Hmily:金融级分布式事务解决方案
5.5 MQ事务
RocketMQ、Kafka、Pulsar、QMQ都提供了事务相关的功能。
事务允许事件流应用将生产、消费、处理信息整个过程定义为一个原子操作
5.5.1 RocketMQ
详见我另一篇博客,链接:
SpringCloud之RocketMQ1
5.5.2 QMQ
核心思想是本地消息表方案,将分布式事务拆分成本地事务进行处理
(1)维护一个本地消息表用来存放消息发送的状态,保存消息操作和业务操作要在一个事务里提交,业务执行成功就代表消息表也写入消息成功。
(2)再单独起一个线程定时轮询消息表,把没有处理的消息发送到消息中间件
(3)消息发送成功后,更新消息状态为成功或者直接删除消息
备注: QMQ即使消息队列挂了也不会影响数据库事务的执行,而且QMQ封装的更好开箱即用,因此QMQ更加适应与大多数业务。
5.6 Saga
属于长事务解决方案,核心思想是将长事务拆分为本地多个本地短事务(本地短事务序列)
5.6.1 图解
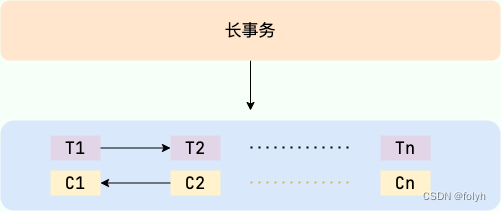
(1)长事务 ----> T1,T2…Tn个本地短事务
(2)每个短事务都有一个补偿动作 ----> C1,C2…Cn
5.6.2 恢复模式
如图:
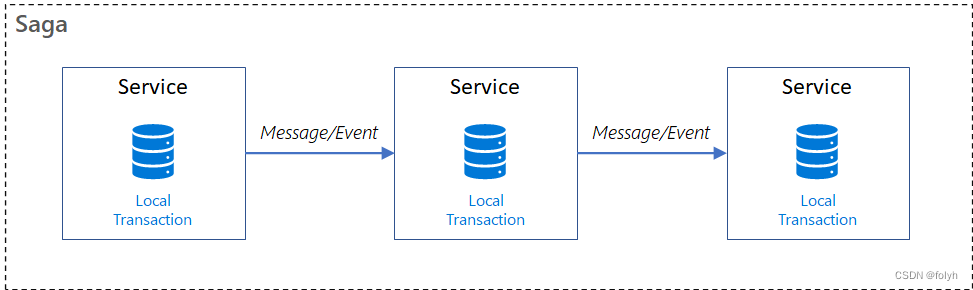
如果T1,T2…Tn个本地短事务都能顺利完成的话,整个事务也顺利结束。否则将采取恢复模式。
(1)反向恢复
<1> 简介
如果Ti短事务提交失败,则补偿所有已完成的事务(一直执行Ci对Ti进行补偿)
<2> 执行顺序
T1,T2…Ti(失败),Ci(补偿),…,C2,C1
(1)正向恢复
<1> 简介
如果Ti短事务提交失败,则一直对Ti进行重试,直至成功为止。
<2> 执行顺序
T1,T2…Ti(失败),Ti(重试),…,Ti+1,…,Tn
5.6.3 总结
(1)与TCC比较
与TCC类似,Saga正向操作与补偿操作都需要业务开发者自己实现,因此也属于侵入业务代码的分布式解决方案。
和TCC很大不同的是Saga没有Try动作,他的本地事务Ti直接被提交
(2)补偿操作执行失败
<1> 网络出现问题或者服务器(包括Saga系统本身崩溃)宕机导致
<2> 通过日志(Saga log)记录短事务提交或补偿操作,等Saga系统恢复后,通过日志查找短事务执行或补偿操作到哪一步,进行人工干预。
<3> Saga没有进行Try动作预留资源,所以不能保证隔离性。
5.6.4 实现开源框架
(1)ServiceComb Pack
微服务应用的数据最终一致性解决方案
(2)Seata
下面会讲
链接:
官网
6.分布式事务开源项目
6.1 Seata
详见我另一篇博客,链接:
SpringCloud之Seata
6.2 Hmily
(1)高性能、零侵入、金融级分布式事务解决方案
(2)主要提高柔性事务支持,包含TCC、TAC(自动生成回滚SQL)方案,未来还会支持XA等方案
目前京东数科正在重启
6.3 Raincat
2阶段提交分布式事务中间件
6.4 Myth
(1)采用消息队列解决分布式事务的开源框架,采用java语言开发
(2)支持Dubbo、SpringCloud、Motan等RPC框架进行分布式事务
上一篇跳转—分布式(三)
本篇文章主要参考链接如下:
参考链接1-JavaGuide
持续更新中…
随心所往,看见未来。Follow your heart,see light!
欢迎点赞、关注、留言,一起学习、交流!