目录
1. 存在重复元素 II
2. 按要求实现程序功能
3. 分割链表
附录
链表
1. 存在重复元素 II
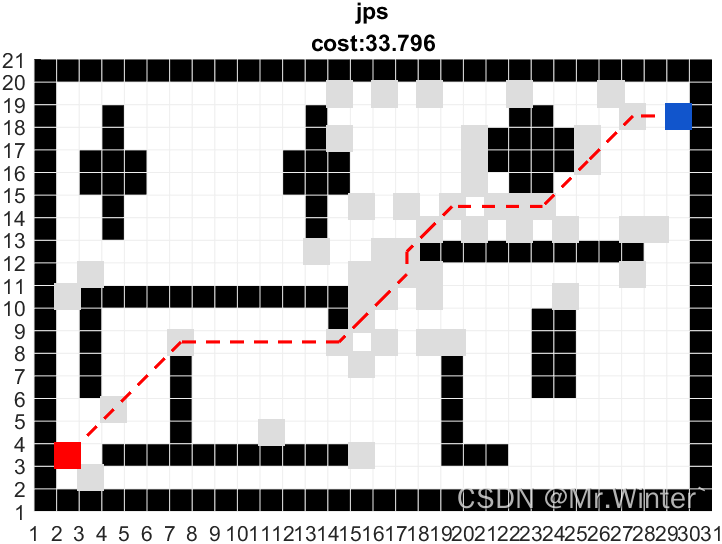
给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的 绝对值 至多为 k。
示例 1:
输入: nums = [1,2,3,1], k = 3 输出: true
示例 2:
输入: nums = [1,0,1,1], k = 1 输出: true
示例 3:
输入: nums = [1,2,3,1,2,3], k = 2 输出: false
代码:
class Solution:
def containsNearbyDuplicate(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: bool
"""
if len(list(set(nums))) == len(nums):
return False
left = 0
right = left + k
if k >= len(nums):
return len(list(set(nums))) < len(nums)
while right < len(nums):
while left < right:
if nums[left] == nums[right]:
return True
else:
right -= 1
left += 1
right = left + k
if len(list(set(nums[left:]))) < len(nums[left:]):
return True
return False
if __name__ == "__main__":
s = Solution()
print(s.containsNearbyDuplicate([1,2,3,1],3))
print(s.containsNearbyDuplicate([1,0,1,1],1))
print(s.containsNearbyDuplicate([1,2,3,1,2,3],2))输出:
True
True
False
2. 按要求实现程序功能
(1)定义一个函数prime判断某个整数是否为素数;
(2)然后从键盘输入一行字符串,将其中的连续数字依次提取出来形成一个列表。
例如:字符串“ab12cd34fg67”按要求提取后形成列表[12,34,67];
(3)将列表中的所有非素数改为0(要求用prime函数判断列表中的元素是否为素数);
(4)输出原始字符串及修改前、修改后的列表。
提示:可以用s.isdigit()判断s是否为数字字符(串)
代码:
import math,re
def prime(num):
flag = False
if num > 1:
for i in range(2, math.floor(math.sqrt(num))):
if (num % i) == 0:
flag = True
break
if flag:
print(num, "不是素数")
else:
print(num, "是素数")
return flag
s = input("请输入字符串:")
sList = re.findall(r'(\d+)', s)
sNum = [int(x) for x in sList]
y = lambda x: 0 if prime(x) else x
sNew = [y(x) for x in sNum]
print(sNum)
print(sNew) 输出:
True
True
False
3. 分割链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
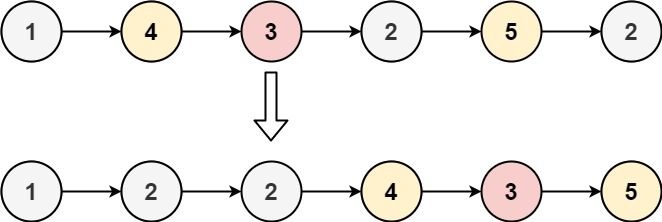
输入:head = [1,4,3,2,5,2], x = 3 输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2 输出:[1,2]
提示:
- 链表中节点的数目在范围
[0, 200]内 -100 <= Node.val <= 100-200 <= x <= 200
代码:
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
class LinkList:
def __init__(self):
self.head=None
def initList(self, data):
self.head = ListNode(data[0])
r=self.head
p = self.head
for i in data[1:]:
node = ListNode(i)
p.next = node
p = p.next
return r
def convert_list(self,head):
ret = []
if head == None:
return
node = head
while node != None:
ret.append(node.val)
node = node.next
return ret
class Solution(object):
def partition(self, head, x):
"""
:type head: ListNode
:type x: int
:rtype: ListNode
"""
if head is None:
return None
less = lesshead = None
last = pos = head
while pos is not None:
if pos.val < x:
if lesshead is None:
lesshead = pos
else:
less.next = pos
less = pos
if head == pos:
last = head = pos.next
else:
last.next = pos.next
else:
last = pos
pos = pos.next
if lesshead is not None:
less.next = head
else:
lesshead = head
return lesshead
if __name__ == "__main__":
l = LinkList()
list1 = [1,4,3,2,5,2]
l1 = l.initList(list1)
x = 3
s = Solution()
print(l.convert_list(s.partition(l1, x)))
list2 = [2,1]
l2 = l.initList(list2)
x = 2
print(l.convert_list(s.partition(l2, x)))
输出:
[1, 2, 2, 4, 3, 5]
[1, 2]
附录
链表
是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。
链表有很多种不同的类型:单向链表,双向链表以及循环链表。链表可以在多种编程语言中实现。像Lisp和Scheme这样的语言的内建数据类型中就包含了链表的存取和操作。程序语言或面向对象语言,如C,C++和Java依靠易变工具来生成链表。










![[Incognito 4.0] ictf 2023](https://img-blog.csdnimg.cn/img_convert/9ccae03e857599815611724474a40281.png)