文章目录
- 一、Elasticsearch的介绍
- 1、Elasticsearch索引
- 2、Elasticsearch的介绍
- 二、Elasticsearch的安装
- 1、安装ES服务
- 2、安装kibana
- 3、Docker安装ES
- 4、Docker安装Kibana
- 三、ES的常用操作
- 1、索引操作
- 2、文档操作
- 3、域的属性
- 3.1 index
- 3.2 type
- 3.3 store
- 总结
一、Elasticsearch的介绍
1、Elasticsearch索引
- Elasticsearch是一个全文检索服务器,全文检索是一种非结构化数据的搜索方式。
结构化数据:指具有固定长度的数据,如数据库中的字段。
非结构化数据:指格式和长度不固定的数据。
结构化数据一般存入数据库,使用sql语句即可快速查询。但由于非结构化数据量大且格式不固定,需要采用全文检索的方式进行搜索。全文检索通过建立倒排索引加快搜索效率。 - 索引:将数据中的一部分信息提取出来,重新组织成一定的数据结构,可以根据该结构进行快速搜索,这样的结构称之为索引。索引分为正排索引和倒排索引。
正排索引(正向索引):将文档id建立为索引,通过id可以快速查找数据。如数据库的主键就是创建的正排索引。
倒排索引(反向索引):非结构化数据中往往会根据关键词查询数据。此时将数据中的关键词建立为索引,指向文档数据,这样的数据称为倒排索引。
2、Elasticsearch的介绍
- Elasticsearch是基于Lucene开发的项目;本质是一个Java语言开发的web项目。 可以通过RESTful风格的接口访问该项目内部的Lucene,从而让全文搜索变得简单。ES内部包含了Lucene。
- Elasticsearch自身带有分布式协调管理功能;solr利用zookeeper进行分布式管理。
Elasticsearch仅支持json文件格式;solr支持很多格式的数据。
Elasticsearch本身更注重于核心功能,高级功能多由第三方插件提供;solr官方提供的功能更多。
solr在传统的搜索应用中表现好于Elasticsearch,但在处理实时搜索应用时(即边添加边搜索)效率明显低于Elasticsearch。
目前ES市场占有率越来越高,solr已经停止维护。 - 文档(Document):是可被查询的最小数据单元,一个文档就是一条数据。类似于关系型数据库中的记录的概念。
类型(Type):具有一组共同字段的文档定义成一个类型,类似于关系型数据库中的数据表的概念。
索引(Index):是多种类型文档的集合,类似于关系型数据库中库的概念。
域(Field):文档由多个域组成,类似于关系型数据库中的字段的概念。
ES7.X之后删除了Type的概念,一个索引不会代表一个库,而是代表一张表。
即原本对应表概念的Type没有了,使用Index代替对应表概念,同时删除了ES中相当于关系型数据库的库的概念。
二、Elasticsearch的安装
1、安装ES服务
- 准备一个CentOS7系统的虚拟机,使用MobaX终端连接虚拟机。
- 关闭防火墙:
systemctl stop firewalld.service
禁止防火墙自启动:systemctl disable firewalld.service - 配置最大可创建文件数大小
1)打开系统文件:vim /etc/sysctl.conf
2)添加一下配置:vm.max_map_count=655360,保存退出
3)在命令行使配置生效:sysctl -p - 因为ES不能以root用户运行,需要创建一个非root用户es:
useradd es - 在官网下载linux的Elasticsearch压缩包:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.6.1-linux-x86_64.tar.gz - 通过mobax上传到目录/中,然后解压缩:
tar -zxvf elasticsearch-8.6.1-linux-x86_64.tar.gz - 重命名ES文件:
mv elasticsearch-8.6.1 elasticsearch - 将ES文件移动到目录/usr/local/中:
mv elasticsearch /usr/local/ - 让es用户取得该文件夹权限:
chown -R es:es /usr/local/elasticsearch - 切换为es用户:
su es - 找到/usr/local/elasticsearch/config/目录下面的elasticsearch.yml配置文件,把安全认证开关从原先的true都改成false,即可实现免密登录访问
- 进入到目录/usr/local/elasticsearch/bin:
cd /usr/local/elasticsearch/bin - 启动es服务:
./elasticsearch - 新开一个窗口查询es服务是否启动成功:
curl 127.0.0.1:9200,此时{}内有数据,即非Empty时证明启动成功
2、安装kibana
- 在Elasticsearch官网下载linux版的kibana:
https://artifacts.elastic.co/downloads/kibana/kibana-8.6.1-linux-x86_64.tar.gz - 在目录/中上传该压缩包,然后在目录/下解压缩到目录/usr/local/中:
tar -zxvf kibana-8.6.1-linux-x86_64.tar.gz -C /usr/local/ - 修改配置文件
1)进入到config目录下:cd /usr/local/kibana-8.6.1/config
2)修改配置文件:vim kibana.yml
3)添加kibana主机ip:server.host: "192.168.126.24"
添加Elasticsearch路径:elasticsearch.hosts: ["http://127.0.0.1:9200"] - 给es用户设置kibana目录权限:
chown -R es:es /usr/local/kibana-8.6.1/ - 切换到es用户:
su es - 进入到kibana的bin目录:
cd /usr/local/kibana-8.6.1/bin/ - 确保启动Elasticsearch后,再启动kibana:
./kibana - 在浏览器中访问kibana:
http://192.168.126.24:5601/
如果google浏览器版本太低的话是访问不到这个页面的 - 在kibana页面中选择Management,再选择Index Management,即可查看Elasticsearch索引信息
3、Docker安装ES
- 安装docker:
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
重复了2次命令,第一次显示获取密钥失败,第二次才安装成功 - 启动docker :
systemctl start docker - 拉取ES镜像:
docker pull elasticsearch:8.6.1 - docker容器间建立通信:
docker network create elastic - 创建ES容器:
docker run --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --name='elasticsearch' --net elastic --cpuset-cpus="1" -m 1G -d elasticsearch:8.6.1
参数:
-p:第一个-p是外部访问时的端口号,第二个-p是ES集群内部通信的端口号
-e:第一个-e是指ES是单节点的,第二个-e是指该ES在JAVA中占用的内存为固定内存512M
–name:指该容量的名字
–net:指使用的网关
–cpuset-cpus:指使用多少个cpu
-m:占用的内存
-d:指被使用的镜像名字 - 修改配置文件(设置免密码登录)
1)将ES容器中的elasticsearch.yml拷贝到当前目录下:docker cp elasticsearch:/usr/share/elasticsearch/config/elasticsearch.yml .
因为相对路径显示找不到文件,此时用的是绝对路径
2)修改yml文件:vim elasticsearch.yml,将所有的true改为false即可
3)将修改后的配置文件拷贝回容器中:docker cp elasticsearch.yml elasticsearch:/usr/share/elasticsearch/config/elasticsearch.yml
4)重启elasticsearch容器:docker restart elasticsearch
4、Docker安装Kibana
- 拉取kibana镜像:
docker pull kibana:8.6.1 - 启动容器:
docker run --name kibana --net elastic --link elasticsearch:elasticsearch -p 5601:5601 -d kibana:8.6.1 - 在浏览器中访问kibana:
192.168.126.24:5601
三、ES的常用操作
1、索引操作
Elasticsearch是使用RESTful风格的http请求访问操作的,请求参数和返回值都是json格式,可以使用kibana发送http请求操作ES。
1)选择Management下的DevTools,即可通过kibana来操作ES
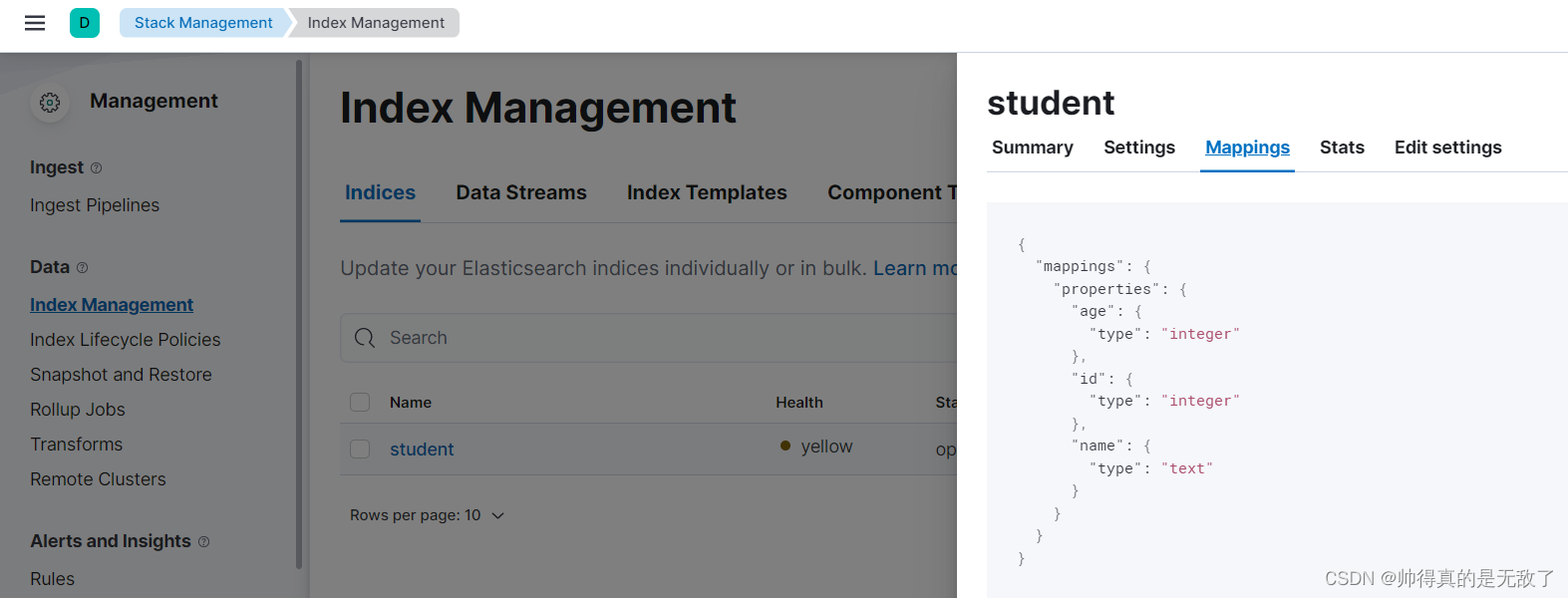
2)在IndexManagement中查看索引
-
创建索引,在kibana中输入下面内容并运行,即可创建student索引
PUT /student { "mappings": { "properties": { "id": { "type": "integer" }, "name": { "type": "text" }, "age": { "type": "integer" } } } }即创建student索引并添加索引的结构
-
删除索引,在kibana中输入下面内容并运行,即可删除student索引
DELETE /student
2、文档操作
-
新增或修改文档
POST /student/_doc/1 { "id":1, "name":"zzx", "age":10 }此时文档id设置为1,如果不写id则自动生成文档id,id和已有id重复时修改文档
-
根据文档id查询文档
GET /student/_doc/1 -
根据id删除文档
DELETE /student/_doc/1 -
根据id批量查询文档
GET /student/_mget { "docs":[ {"_id":1}, {"_id":2} ] } -
查询所有文档
GET /student/_search { "query":{ "match_all":{} } } -
修改文档
POST /student/_doc/1 { "id": 3, "name": "zzx", "age": 10 }Elasticsearch执行删除操作时,ES先标记文档为deleted状态,而不是直接物理删除。当ES存储空间不足或者工作空闲时,才会执行物理删除。
Elasticsearch执行修改操作时,ES不会真的修改Document中的数据,而是标记ES中原有的文档为deleted状态,再创建一个新的文档来存储数据。
3、域的属性
3.1 index
只有域中的index的值为true时,才能根据该域的关键词查询文档。
-
创建两个索引,其中一个索引的域中的index值为true,另一个为false。
PUT /student1 { "mappings": { "properties": { "name": { "type": "text", "index":true } } } } PUT /student2 { "mappings": { "properties": { "name": { "type": "text", "index":false } } } } -
创建2个域的值相同的文档
POST /student1/_doc/1 { "name":"zzx 111" } POST /student2/_doc/1 { "name":"zzx 111" } -
在这两个文档中,都按name域查找
GET /student1/_search { "query":{ "term":{ "name": "zzx" } } } GET /student2/_search { "query":{ "term":{ "name": "zzx" } } }此时student1的name域的index为true,能找到,但是student2是false,直接报错。并且按域查找时,text类型是以空格符为分割符,即如果是zz的话,也是找不到。
3.2 type
- 字符串类型:text
- 整数类型:long,integer,short,byte
- 浮点型:double,float
- 日期类型:date
- 布尔类型:boolean
- 数组类型:array
- 对象类型:object
- 不分词的字符串:keyword
1)创建一个student3
PUT /student3
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index":true
}
}
}
}
2)进行查询
GET /student3/_search
{
"query":{
"term":{
"name": "zzx"
}
}
}
此时因为keyword类型是不分词的,所以找不到
3.3 store
域中store的值为true,则为单独存储,即该域能够单独查询。
-
创建2个索引
PUT /student1 { "mappings": { "properties": { "age": { "type":"integer" }, "name": { "type": "text", "index":true, "store": true } } } } PUT /student2 { "mappings": { "properties": { "age": { "type":"integer" }, "name": { "type": "text", "index":true, "store": false } } } } -
给俩个索引赋值
POST /student1/_doc/1 { "age":11, "name":"zzx 111" } POST /student2/_doc/1 { "age":11, "name":"zzx 111" } -
分别按域单独查找
GET /student1/_search { "stored_fields":["name"] } GET /student2/_search { "stored_fields":["name"] }其中student1的store值为true,student2为false,索引student1单独查找时能找到域值,而索引student2单独查找时没有找到域值。
总结
- Elasticsearch是一个全文检索服务器,全文检索是一种非结构化数据的搜索方式。
全文检索通过建立倒排索引加快搜索效率。
docker安装ES及Kibana,拉取ES镜像后,创建ES通信用的网关,创建ES容器,将配置文件修改为免密码登录即可;拉取Kibana镜像后,创建Kibana容器后即可通过Kibana访问ES服务。
在使用docker的cp指令时,遇到一个问题,就是不能通过相对路径找到文件,而是用绝对路径才能找到文件。 - ES在执行删除和修改操作时,不会马上删除,而是先标记为deleted状态,在内存不足或工作空闲时,才会执行物理删除操作。
- index为true时,在查询文档时,可以根据域值查找文档。
store为true时,将该域进行单独存储,可以按域名单独查询到。