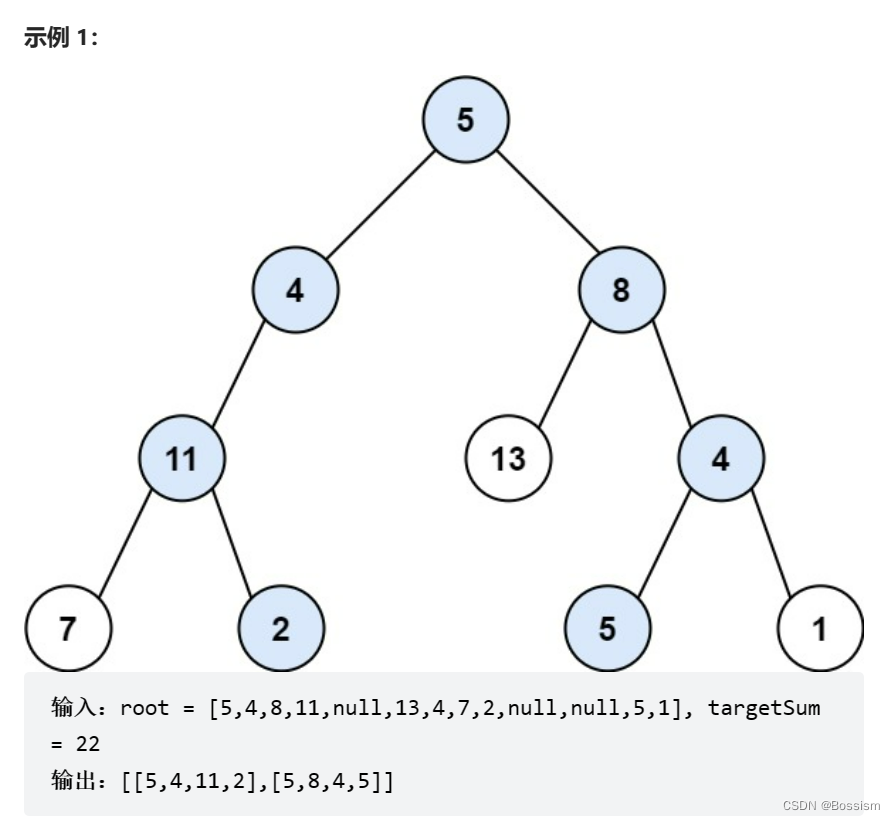
原始 Tomcat配置
Plaintext -Xms256m -Xmx512m -XX:MaxPermSize=128m
XML <Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
第一次修改
问题表现
Tomcat 接口重启,tomcat 线程飙升到1000+,短时间内出现大量OOM,表现出的现象数据库连接不可用,数据查询超时等。进而导致服务不可用 Plaintext ?[m?[1;35m2022-04-13 19:01:42 ERROR [http-nio2-8803-exec- 500 ] (ResultInterceptor.java:172) [result exception...msgType : 3, code : 99, msg : Could not get JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10656, active 18, maxActive 24, creating 0, error: com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1775)
Plaintext ?[m?[1;35m2022-04-13 19:05:26 ERROR [http-nio2-8812-exec-303] (ResultInterceptor.java:172) [result ?[mognl.MethodFailedException: Method "handleMsg" failed for object friendGame.action.HandleMsgAction@31aa0e68 [java.lang.OutOfMemoryError: GC overhead limit exceeded]
推测问题原因
Tomcat 线程数配置的过高,减少tomcat的最大线程配置,调大tomcat 的初始线程数 服务中过度依赖memcached ,一个登录操作可能存在几十个查询操作,memcached响应过慢时,会导致tomcat 导致创建大量线程 基于 xmemcached 作为memcached连接SDK 其底层消息响应机制基于java.util.concurrent.CountDownLatch
程序修改点
堆最大小统一为512MB ,移除jdk7的永久代参数配置,新增新生代配置
Plaintext -Xms512m -Xmx512m -Xmn256m
Tomcat 参数配置
Connector maxThreads修改为500,新增 minSpareThreads="50" Plaintext <!-- <Executor name="tomcatThreadPool" namePrefix="catalina-exec-"--> <Connector minSpareThreads="50" maxThreads="500" compression="on" compressionMinSize="2048"
优化点
限制 tomcat 的线程数,避免重启时(瞬时高峰)导致线程创建过多 修改堆的最大最小值,降低堆内存的动态变化的性能影响 项目中对应公共不变的数据,采用本地缓存(Caffeine ) 仍存在的问题
重启时Tomcat 仍创建到了 线程池限制的最大值 短时间出现memcached 连接超时大量减少,但极少连接超时信息
第二次修改
问题表现
项目下午三点更新,晚七点高峰期开始收到服务器资源预警,CPU和内存使用暴增,观察接口出现大量数据连接异常和OOM 日志 观察PinPoint 上日志记录 更新后tomcat 线程持续保持在最大值附近,jvm频繁的出现full gc 查看历史的升级记录,每次升级tomcat 线程都是保持到最大值持续到第二天凌晨开始降低 推测问题原因
对比其它项目组的jvm内存配置,jvm 堆内存设置偏小 运维的通过监听tomcat端口号的限流策略存在不合理处。在端口号启动后将有半分钟左右的服务不可用空窗期,大量的消息堆积导致至服务可用时,tomcat 的处理线程被压满,因为tomcat 的线程销毁策略是60s内没有被使用。故tomcat 的线程数目在凌晨左右开始降低
程序修改点
Plaintext -Xms1g
优化点
设置新生代的的初始值,避免在未达到初始值前提下每次扩增时带来的 FullGC 运维人员使用新的重启放流策略,采用监控url 方式取代端口监听。 重启时限制nginx 发送消息到接口,监控接口服务检测url 地址 是否可用,第一次可用时延期1min 再次检测是否可用。两次可用时,nginx 开始放流 修改接口重启时各项指标保持在正常水平,客户端没有明显的卡顿感 第三次修改
问题表现
pinpoint上观察堆使用明显偏高,full gc 的一天有三四次,在12,19 点高峰期尤为明显
推测问题原因
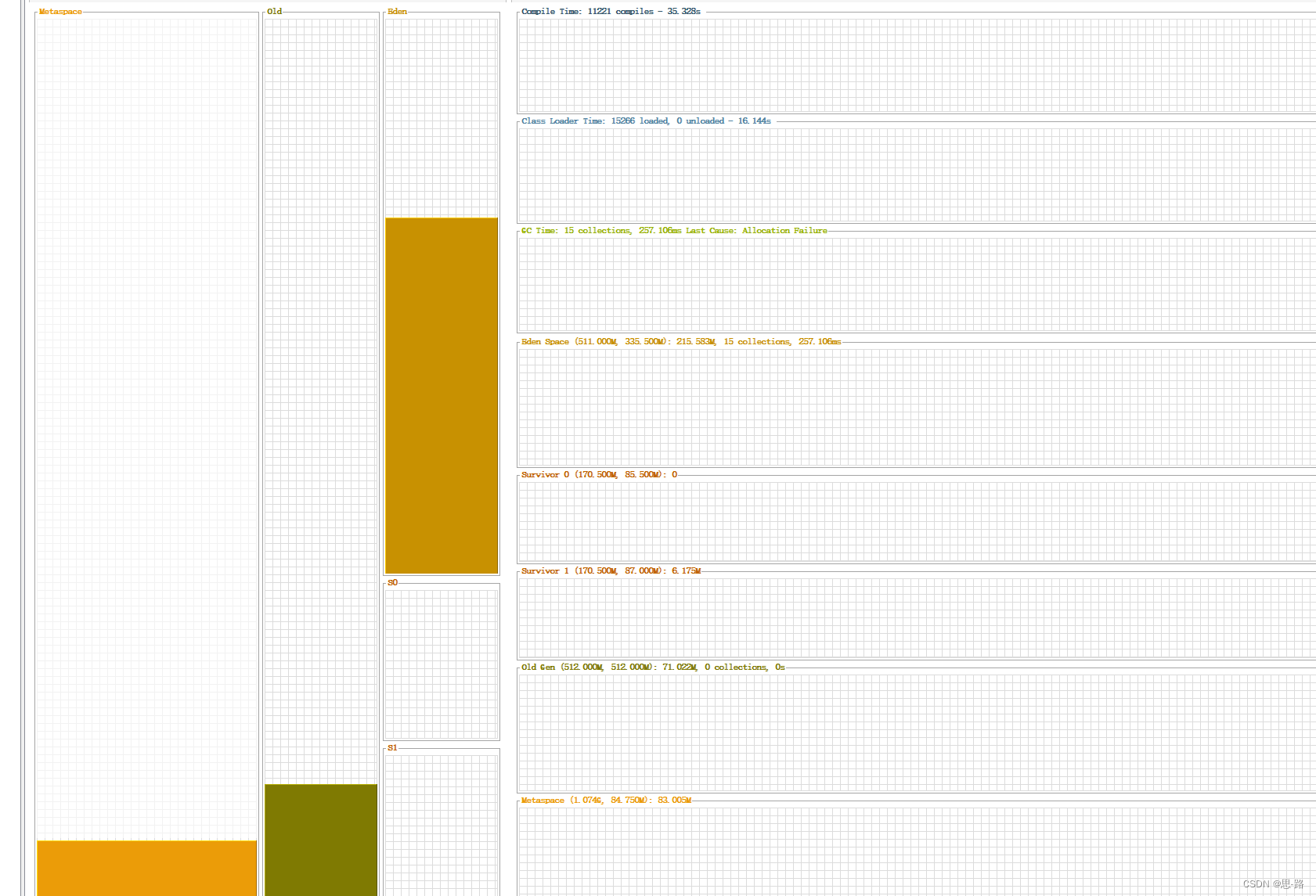
本地保持与线上相同的tomcat配置,压测接口。并通过visualvm 观察jvm 堆信息。 压测后发现 s1,s0 逐渐变小,eden 开始变大,导致 eden gc时 s0,s1容量无法承受eden 的对象信息,导致大量对象进入老年代,进而fullgc 比较频繁
程序修改点
Plaintext -Xms1g
优化点
指定 CMS 作为 老年代的 GC 算法,并开启 GC 后压缩 UseCMSCompactAtFullCollection 通过指定 CMS 禁用了 UseAdaptiveSizePolicy 新生代的内存动态变化策略,避免过多数据进入老年代 开启UseAdaptiveSizePolicy
高并发访问后
重点关注
Tomca 线程数目最大值设置数目过大,瞬时高峰导致创建过多线程可能导致 OOM Tomcat 业务处理线程,并非启动时创建。是在第一个 http 请求到来时开始创建(最多一次创建 50 个线程。未达到核心线程时,第二次访问再创建),故前端开始放流时,会出现短暂的 CPU 使用率增高 GC 算法选择,不推荐使用默认的 -XX:+UseAdaptiveSizePolicy ( Jdk5 默认开启) 其目的为了增大 JVM 吞吐量。开启后 新生代 egen:s0:s1 不再遵守指定的比例大小( 4:1:1 )而是采用 JVM 自己 动态变化的新生代的分层大小。故开启后 s1,s2 很可能被压缩的很小,导致 youngGc 时,大量的对象被压倒 老年代 ,进而产生频繁 full gc 。 推荐使用 Jdk8 推荐 CMS , Jdk9+ 使用 G1 ( jdk9 g1 商用化) Jvm 内存大小设置,推荐堆的总体大小 1g+ ,新生代不少于堆总体一半, s1,s2 的容量不要过小,避免 yongGc 时因对象过大,而直接进入老年代
监控工具
pinpoint (运维部门已支持),可以监控jvm 的大至堆使用,fullgc 的频率 Arthas 用于堆使用详情,gc的详情,以及动态修改jvm 部分参数 visualVm 用于开发环境测试(推荐 安装 visualgc 插件,监控gc详情)
visualVm 本机使用观察注意项
下载 不推荐 Oracle jdk8 自带的。
推荐下载的插件
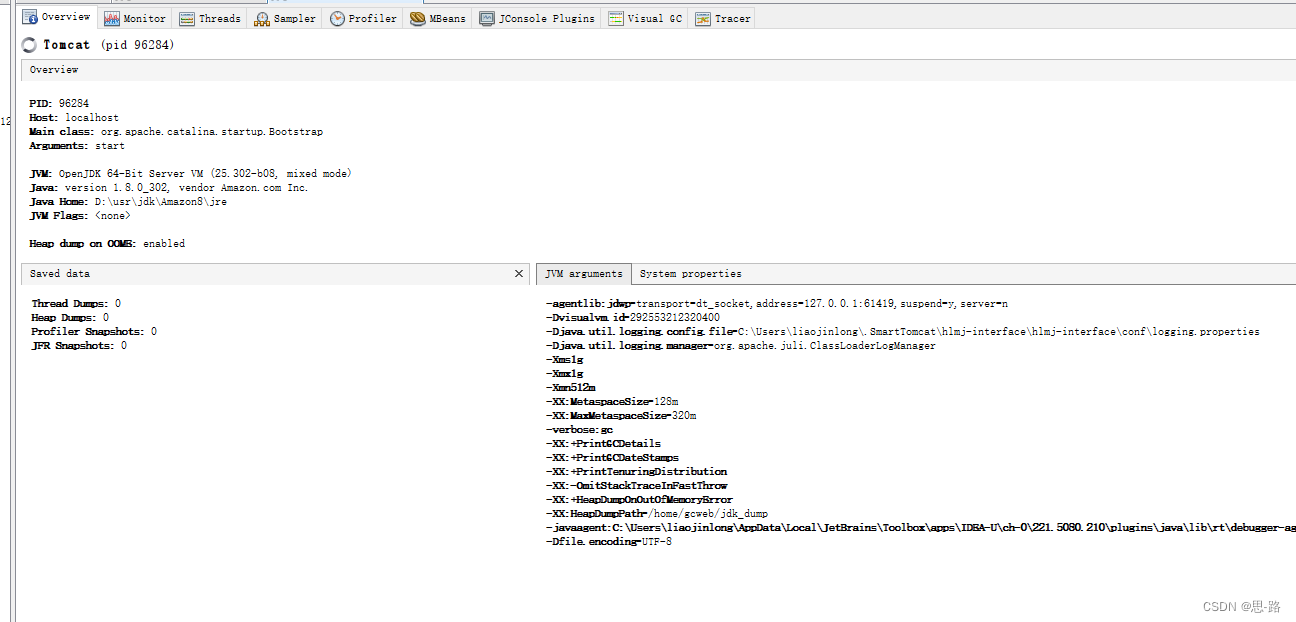
Java 启动的参数信息
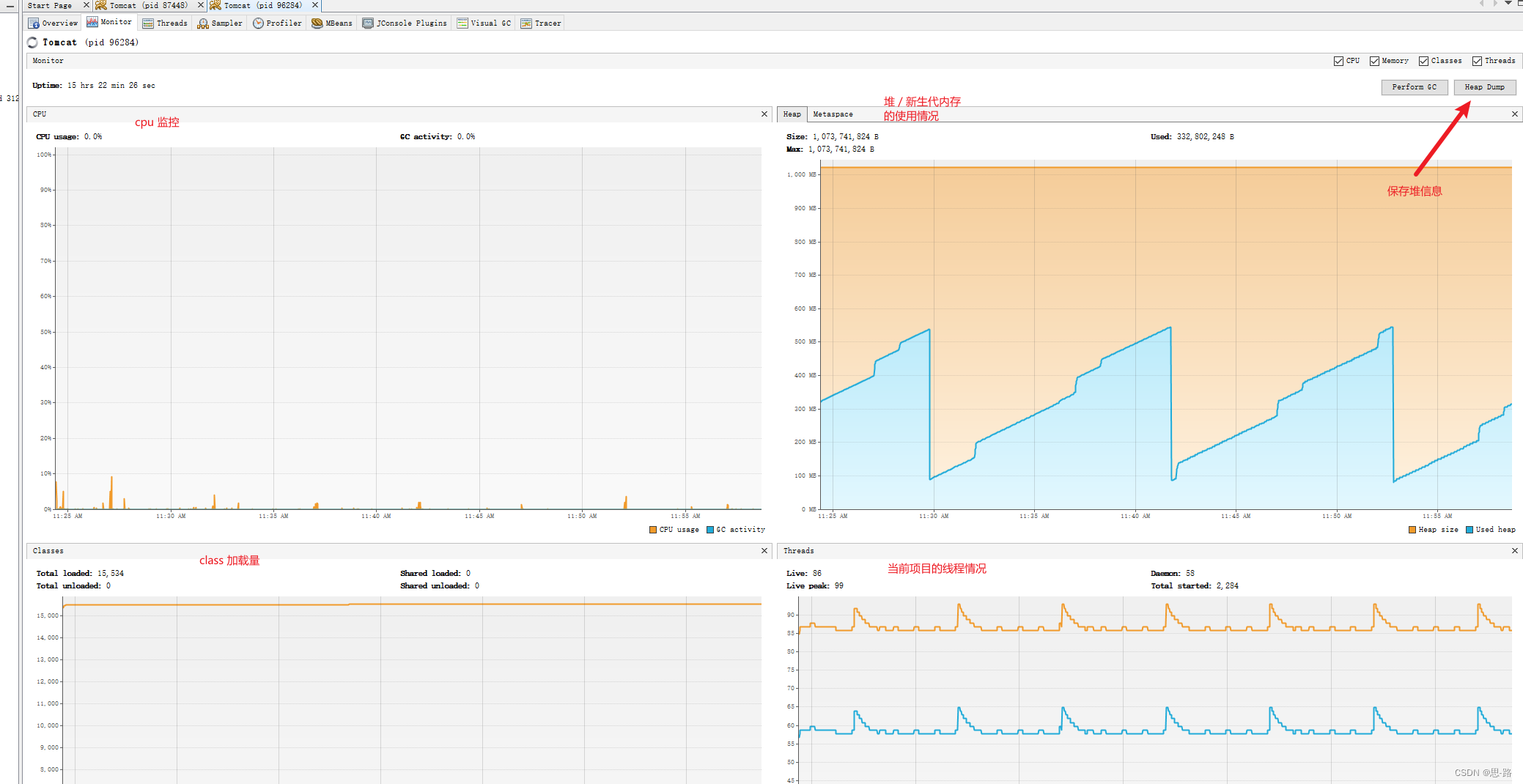
仪表盘信息,总体介绍 jvm 使用信息
当前线程使用情况
支持sample 支持监控特定时间的 java 的内存cpu 使用情况
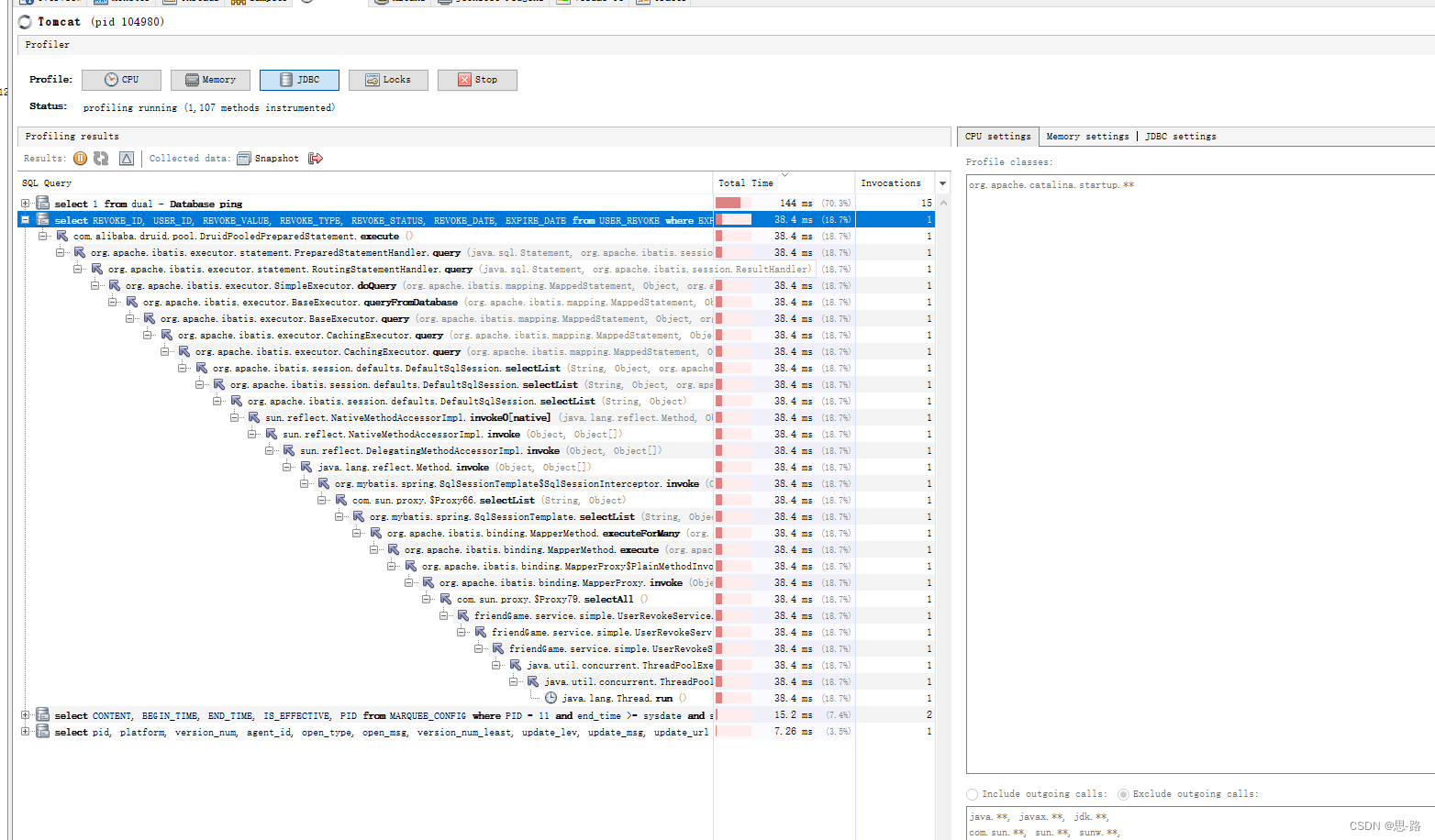
profile 可用监控 项目中 sql 的使用信息,cpu,锁 等信息监控,(开源版存在,Oracle版无)
常用 jdk8 JVM 参数
Plaintext -Xmx1g :初始堆大小直接等于最大堆大小