目录
一. 什么是引用
1.1 引用的概念
1.2 引用的定义
二. 引用的性质和用途
2.1 引用的三大主要性质
2.2 引用的主要应用
三. 引用的效率测试
3.1 传值调用和传引用调用的效率对比
3.2 值返回和引用返回的效率对比
四. 常引用
4.1 权限放大和权限缩小问题
4.2 跨数据类型的引用问题
五. 引用和指针的区别
一. 什么是引用
1.1 引用的概念
引用,通俗的讲,就是给已经存在的变量取一个别名,而不是创建一个新的变量。引用和被引用对象共同使用一块内存空间。
引用就好比一个人的大名和小名,大名和小名都是一个人。再比如,李逵外号黑旋风,叫李逵和黑旋风表示同一个人。
1.2 引用的定义
引用定义的语法格式:类型& 引用的名称 = 被引用实体
如,定义int a = 10,希望再定义一个引用b,来表示整形变量a的别名,语法为:int& b = a。演示代码1.1展示了引用的定义过程,对原变量a和引用b的其中任意一个赋值,都会使a和b的值均发生改变,这是因为a和b共用一块内存空间。
演示代码1.1:
int main()
{
int a = 10;
int& b = a; //b是a的引用(别名)
printf("a = %d, b = %d\n", a, b); //10,10
a = 20; //对a赋值,同时改变a和b
printf("a = %d, b = %d\n", a, b); //20,20
b = 30; //对b赋值,同时改变a和b
printf("a = %d, b = %d\n", a, b); //30,30
return 0;
}
二. 引用的性质和用途
2.1 引用的三大主要性质
1、引用在定义时必须初始化
定义引用时必须给出这个引用的被引用实体是谁,如:int &b; -- 是非法的。
演示代码2.1:
int main()
{
int a = 10;
int& b; //报错
int& c = a; //初始化引用
return 0;
}

2、一个变量可以有多个引用
我们可以为一个变量取多个别名。如演示代码2.2所示,给a变量取b、c、d三个别名是可行的。对a、b、c、d中的任意一个赋值,都会使a、b、c、d的值均发生改变。a、b、c、d共用一块内存空间。
演示代码2.2:
int main()
{
int a = 10;
int& b = a;
int& c = a;
int& d = a; //为a取b、c、d三个别名
printf("a = %d, b = %d, c = %d, d = %d\n", a, b, c, d); //10,10,10,10
c = 20;
printf("a = %d, b = %d, c = %d, d = %d\n", a, b, c, d); //20,20,20,20
return 0;
}
3、一个引用一旦引用了某个实体,就不能再引用其他实体
演示代码2.3中的b = c并不是将b变为变量c的引用,而是将变量c的值赋给b,通过打印b和c的地址,我们可以发现b和c并不共用一块内存空间,而赋值之后,a和b的值都变为了20。
演示代码2.3:
int main()
{
int a = 10;
int& b = a;
int c = 20;
b = c; //将c的值赋给b,而不是让b变为c的引用
printf("&b = %p, &c = %p\n", &b, &c); //b和c的地址不一致
printf("a = %d, b = %d\n", a, b); //a、b都变为了c的值20
return 0;
}
正是因为引用一旦引用了某个实体之后就不能再引用其他实体,所以引用无法替代指针来实现链表数据结构。否则就无法实现链表的增、删等操作,链表的增删操作需要改变指针的指向。
2.2 引用的主要应用
1、引用做函数参数
要写一个swap函数,实现两个整形数据的交换,如果用C语言来写这个函数,就必须使用指针来作为函数的参数,即:void swap(int* px, int* py)。但是,如果使用C++来写,则可以用引用传参来替代指针传参,因为引用和被引用实体共用一块内存空间,引用传参使得函数内部可以控制实参所占用的内存空间,这是,swap可以声明为:void swap(int& rx, int& ry)。
演示代码2.4:
void swap(int& rx, int& ry)
{
int tmp = rx;
rx = ry;
ry = tmp;
}
int main()
{
int x = 10, y = 20;
printf("交换前:x = %d,y = %d\n", x, y); //10,20
swap(x, y);
printf("交换后:x = %d,y = %d\n", x, y); //20,10
return 0;
}
至此,可以总结出函数的三种调用方法:
- 传值调用。
- 传地址调用。
- 传引用调用。
问题:void swap(int x, int y)和void swap(int& x, int& y)能否构成函数重载?
答案是可以的。因为其满足构成函数重载的条件之一 :参数的类型不同。
但是,在调用这两个swap函数时,会存在歧义。通过语句swap(x,y)调用,无法确定是调用swap(int x, int y)还是swap(int&x, int& y)。
2、引用做函数的返回值
在演示代码2.5中,定义函数int& Add(int x, int y),函数返回z的别名。我们希望这个函数能够对x+y进行计算。但是显然,这段代码是有潜在问题的,因为在add函数调用结束后,为add函数创建的栈帧会被销毁,这块栈空间会还给操作系统。此时再使用add函数的返回值,就会造成对内存空间的非法访问,而大部分情况下,编译器不会对非法访问内存报错。
演示代码2.5:
int& add(int x, int y)
{
int z = x + y;
return z;
}
int main()
{
int& ret = add(1, 2);
printf("ret = %d\n", ret);
return 0;
}对于演示代码2.5的运行结果,可以分为两种情况讨论:
- 函数栈帧销毁后,编译器不对被销毁的栈空间进行清理,打印函数的返回值,结果依旧为x + y的值。
- 函数栈帧销毁后,编译器对被销毁的栈空间进行清理,函数的返回值为随机值。
在VS2019 编译环境下,演示代码2.5的运行结果为3,说明VS编译器不会清理被销毁的函数栈帧空间中内容。

既然VS编译器不会对被销毁的函数栈帧进行清理,那么是否在VS编译环境下,可以正常使用演示代码2.5中的add函数呢?答案显然是否定的,这可以从以下两个方面解释:
- 如果在其他编译环境下进行编译,则被销毁的函数空间可能会被清理,这样会降低代码的可移植性。
- 即使函数栈帧空间不被清理,但这块空间已经换给了操作系统,如果调用完add函数后再调用其他函数,那么原本为z开辟的空间可能会被覆盖,从而改变ret的值。
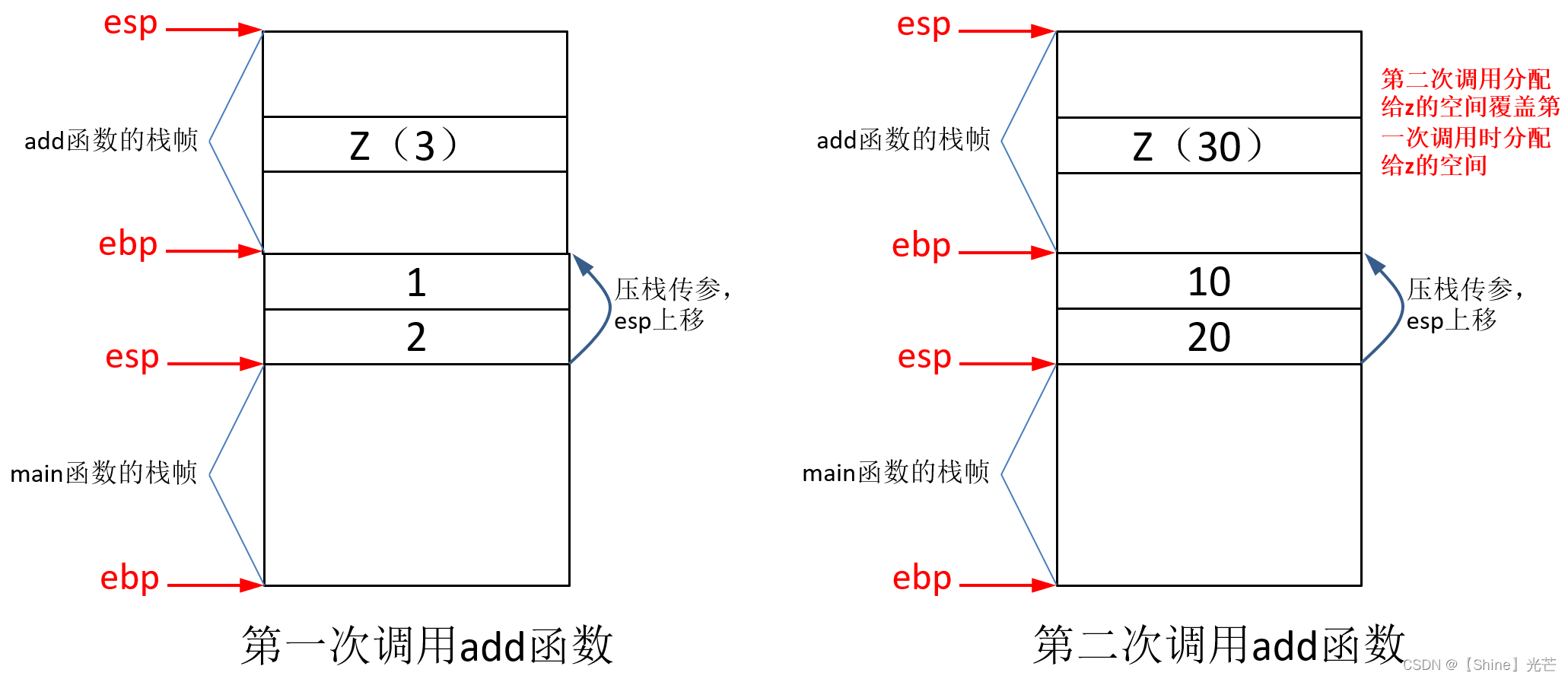
如演示代码2.6所示,第一次调用add函数使用ret来接收返回值,第二次调用add函数不接收返回值。但是第二次调用add函数之后,ret的值却变为了30,这是因为第二次调用add函数覆盖了第一次调用时创建的函数栈帧,原来第一次调用存放变量z的内存空间的内容由3变为了30,因此,程序运行的结果为30。这段代码在运行过程中栈帧的创建和销毁情况见图2.7。
演示代码2.6:
int& add(int x, int y)
{
int z = x + y;
return z;
}
int main()
{
int& ret = add(1, 2);
cout << ret << endl;
add(10, 20);
cout << ret << endl;
return 0;
}
总结(什么时候可以用引用返回,什么时候不可以):
- 如果出了函数作用域,函数返回的对象被销毁了,则不能使用引用类型作为返回值。
- 如果出了函数作用域,函数的返回对象还没有被销毁(存储返回对象的内存还没有还给操作系统),则可以使用引用作为返回值。
演示代码2.7给出了两种可以使用引用作为返回的情况,一种是以静态变量作为返回对象,另一种是返回对象为调用函数中开辟的一块内存空间中的内容(调用函数中开辟的数组)。
演示代码2.7:
int& func1()
{
static int n = 0;
++n;
return n;
}
char& func2(char* str, int i)
{
return str[i];
}
int main()
{
cout << func1() << endl; //1
cout << func1() << endl; //2
char ch[] = "abcdef";
for (int i = 0; i < strlen(ch); ++i)
{
func2(ch, i) = '0' + i;
}
cout << ch << endl; //012345
return 0;
}
思考问题:既然函数完成调用时才会返回,而调用完成时函数栈帧又会被销毁。那么,以值作为函数返回类型时,时如何从函数中接收返回值的呢?
就比如演示代码2.8中的add函数,函数返回值时add函数中的临时变量z的值,在主函数中的ret如何从add函数中接收z值。
演示代码2.8:
int add(int x, int y)
{
int z = x + y;
return z;
}
int main()
{
int ret = add(2, 3);
return 0;
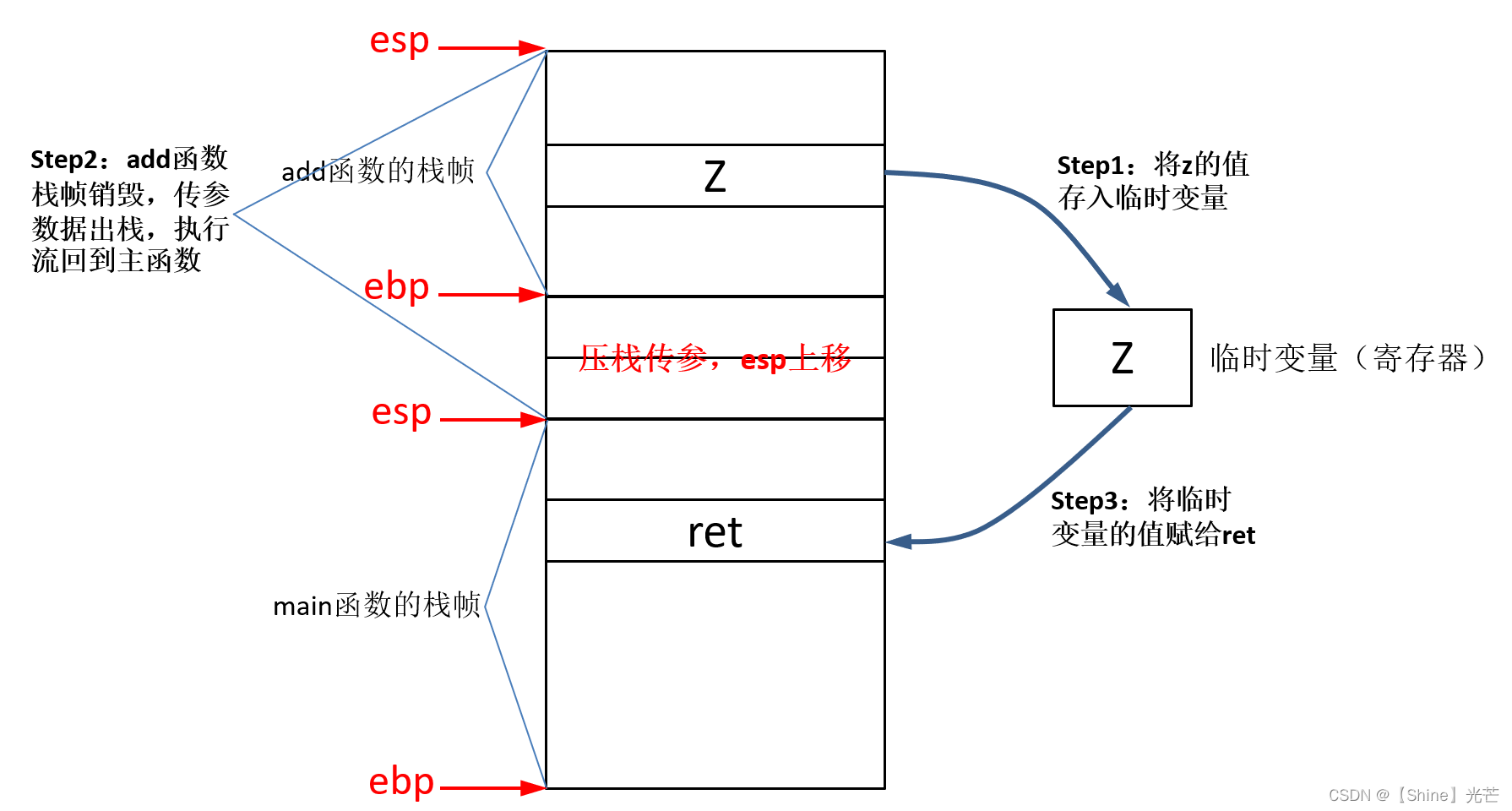
}答案其实很简单,ret并不是直接从add函数栈帧的空间中接收返回值,而是在add函数完成调用、函数栈帧销毁之前,存储一个临时变量用于接收函数的返回值,然后在将临时变量的值赋给ret。
那么,这个临时变量存储在什么位置呢?分两种情况讨论:
- 如果返回值比较小,则使用寄存器充当临时变量。
- 如果返回值比较大,则将临时变量放在调用add函数的函数内部,在调用add函数之前在调用add的函数的栈帧中预先开辟一块空间用于存储临时变量。
三. 引用的效率测试
3.1 传值调用和传引用调用的效率对比
演示代码3.1分别执行100000次传值调用和100000次传引用调用,每次传值调用传给函数的形参的大小为40000bytes,记录传值调用和传引用调用消耗的时间。
程序运行结果显示,10000次传值调用耗时71ms,100000次传引用调用耗时2ms,传引用调用的效率远高于传值调用。这是因为传引用调用不用再为形参开辟一块内存空间,而为形参开辟空间存在一定的时间消耗。
演示代码3.1:
#include<iostream>
#include<time.h>
using namespace std;
//大小为40000bytes的结构体
typedef struct A
{
int arr[10000];
}A;
void Testvaluefunc(A a) { }; //传值调用测试函数
void TestReffunc(A& a) { }; //传引用调用测试函数
void TestRefAndValue1()
{
A a;
int i = 0;
size_t begin1 = clock(); //记录开始传值调用的时间(传值调用100000次)
for (i = 0; i < 100000; ++i)
{
Testvaluefunc(a);
}
size_t end1 = clock(); //记录结束传值调用的时间
size_t begin2 = clock(); //记录开始传引用调用的时间(调用100000次)
for (i = 0; i < 100000; ++i)
{
TestReffunc(a);
}
size_t end2 = clock();
cout << "传值调用10000次耗费时间:" << end1 - begin1 << endl;
cout << "传引用调用10000次耗费时间:" << end2 - begin2 << endl;
}
3.2 值返回和引用返回的效率对比
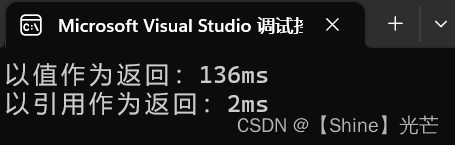
演示代码3.2分别执行100000次值返回函数和100000次引用返回函数,记录调用值返回函数和调用引用返回函数消耗的时间。程序运行结果表明,调用100000次值返回函数耗时136ms,调用100000次引用返回函数耗时2ms,引用返回的效率远高于值返回。
演示代码3.2:
#include<iostream>
#include<time.h>
using namespace std;
typedef struct A
{
int arr[10000];
}A;
A a;
A TestValuefunc2()
{
return a;
}
A& TestReffunc2()
{
return a;
}
void TestRefAndValue2()
{
int i = 0;
size_t begin1 = clock(); //记录开始时间(调用100000次)
for (i = 0; i < 100000; ++i)
{
TestValuefunc2();
}
size_t end1 = clock(); //记录结束时间
size_t begin2 = clock(); //记录开始的时间(调用100000次)
for (i = 0; i < 100000; ++i)
{
TestReffunc2();
}
size_t end2 = clock(); //记录结束时间
cout << "以值作为返回:" << end1 - begin1 << "ms" << endl;
cout << "以引用作为返回:" << end2 - begin2 << "ms" << endl;
}
int main()
{
TestRefAndValue2(); //引用作为返回和值作为返回的效率测试
return 0;
}
四. 常引用
4.1 权限放大和权限缩小问题
如果int& b = a,而a是整形常量,被const关键字修饰,那么b就不能作为a的别,因为a变量是只读的,而将b定义为int&类型,则表明b是可读可写的类型,b对a存在权限放大问题。
对于int a = 10,使用const int& b = a来表示a的别名是可以编译通过的。因为a为读写类型,而b为只读类型,b相对于a权限缩小,C++允许权限缩小。
总结:C++允许权限缩小,不允许权限放大。
演示代码4.1:
int main()
{
//权限放大问题
const int a = 10;
//int& b = a; //报错
const int& b = a; //编译通过
//权限缩小
int c = 10;
const int& d = c; //能够编译通过
return 0;
}4.2 跨数据类型的引用问题
看一个很诡异的问题。在演示代码4.2中,定义一个双精度浮点型数据double d = 1.1,编译程序,出现下面的现象:
- 将d赋给int型数据i1,编译通过。
- 用int& i2 = d来作为d的引用(别名),编译报错。
- 但是,使用const int& i3 = d来作为d的引言,编译通过。
演示代码4.2:
int main()
{
double d = 11.11;
int i1 = d; //强转,编译通过
//int& i2 = d; //编译报错
const int& i3 = d; //编译通过
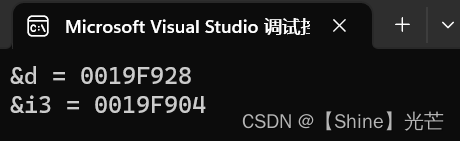
printf("&d = %p\n", &d);
printf("&i3 = %p\n", &i3);
return 0;
}那么,为什么const int& i3类型的可以作为d的引用,而int& i2却不行?问题出在强制类型转换上。要理解这个问题,首先要清楚强制类型转换的过程,强制类型转换(int i1 = d),并不是将d强转后的数据直接赋给i1,而是先将d强转为int类型数据的值存储在一个临时变量中,然后再将临时变量的值传给i1,详见图4.1。
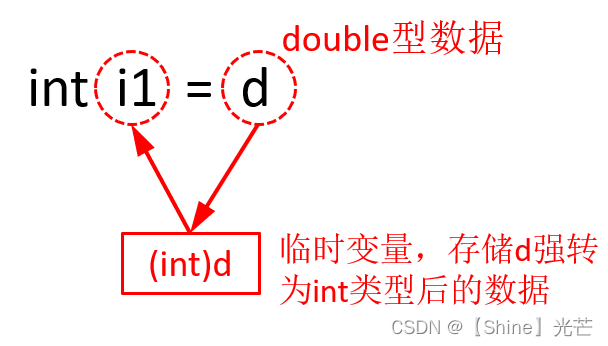
临时变量具有常性,只可读不可改。因此,int& i2 = d就存在权限放大的问题,编译无法通过,而const int& i3 = d不会存在权限放大的问题,可以编译通过。但是,这里的i3就不再是d的别名,而是存储d强转为int类型数据值的临时变量的别名,因此i3和d的地址也就不同。演示代码4.2打印了i3和d的地址,表面他们不同,i3其实并不是d的别名。
提示:一定要弄清楚强转类型转换时临时变量做中间值的问题!
五. 引用和指针的区别
- 引用是定义一个变量的别名,而指针存储一个地址。
- 引用不占用额外的内存空间,而指针要占用4bytes或8bytes的内存空间。
- 引用在定义时必须初始化,而指针可以不初始化。(建议指针在定义时避免不初始化)。
- 引用一旦引用了某个实体,便不能更改被引用实体,而指针可以更改指向。
- 对引用自加,即对被引用的实体+1,指针自加,向后偏移一个指针类型的大小(bytes)。
- 没有多级引用,有多级指针。
- 访问实体时,引用直接由编译器处理即可,指针需要解应用。
- 没有空引用,但有空指针NULL。
- 引用相对于指针更加安全。
因为指针存在野指针、空指针等问题,造成指针过于灵活,所以指针的安全性不如引用。
引用的底层是通过指针来实现的。
引用最大的局限性在于不能更改引用实体,因此虽然引用的底层是通过指针实现的,但引用不能替代指针来实现链表数据结构。因为链表的操作需要更改指针的指向。