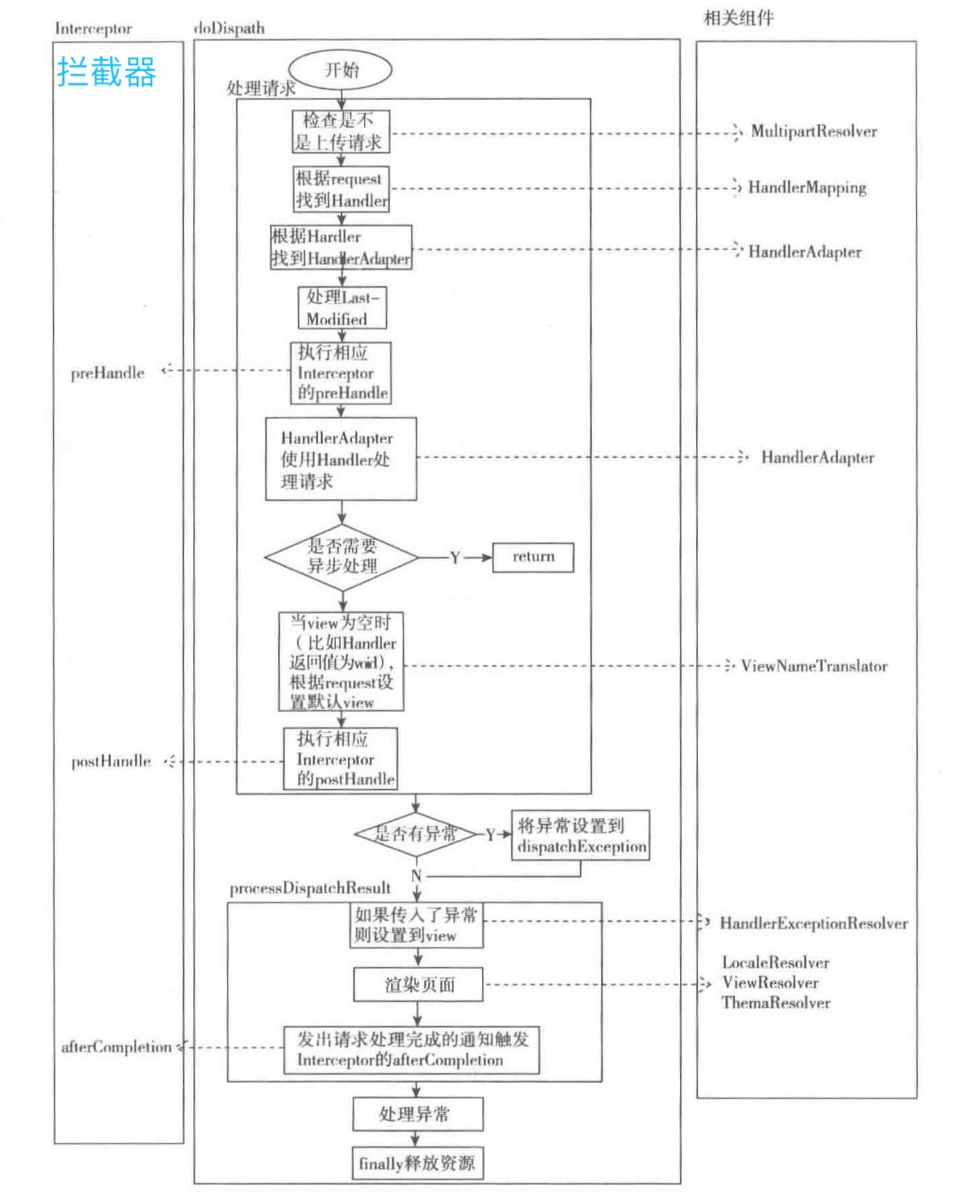
论文题目: Language Models are Unsupervised Multitask Learners
论文地址: https://life-extension.github.io/2020/05/27/GPT技术初探/language-models.pdf
论文发表于: OpenAI 2019
论文所属单位: OpenAI
论文大体内容:
本文主要提出了GPT-2(Generative Pre-Training)模型,通过大模型pre-train进行Unsupervise Learning,并使用Zero-shot Learning的方式在NLU系列任务中取得收益。
Motivation
创建通用的大模型,是GPT系列文章的最大目标。而对于未涉猎过的领域(Zero-shot learning),通用大模型的效果会是怎么样的呢?
Contribution
①训练更通用的pre-train模型;
②在zero-shot learning中应用pre-train模型取得优异成绩;
1. 本文作者相信,Language model经过训练后,有能力推断和预测对应的任务,也就是进行Unsupervisor Multi-task Learning。而本文在后面的实验中就用Zero-shot learning来进行验证。
2. 为了能训练出更通用的模型,需要收集到大的通用数据集,本文基于Common Crawl的工具去爬取海量的互联网数据。但是这些数据存在质量问题。所以本文做了一些爬取策略来提升数据质量,包括只爬取Reddit的外链以及启发式的清理。总共爬取到800万个文档共40GB。另外为了更好的进行Zero-shot Learning(避免Trainset和Testset数据重合),所以本文的训练数据集也去掉了普遍都使用的Wiki文档。
3. Byte-level Language Model效果逊色于Word-level Language Model,但是能够拥有更大范围的词汇量。而Byte Pair Encoding (BPE)介于两者之间,能够同时拥有大的词汇量和优秀的表现。本文也采用这种方法。
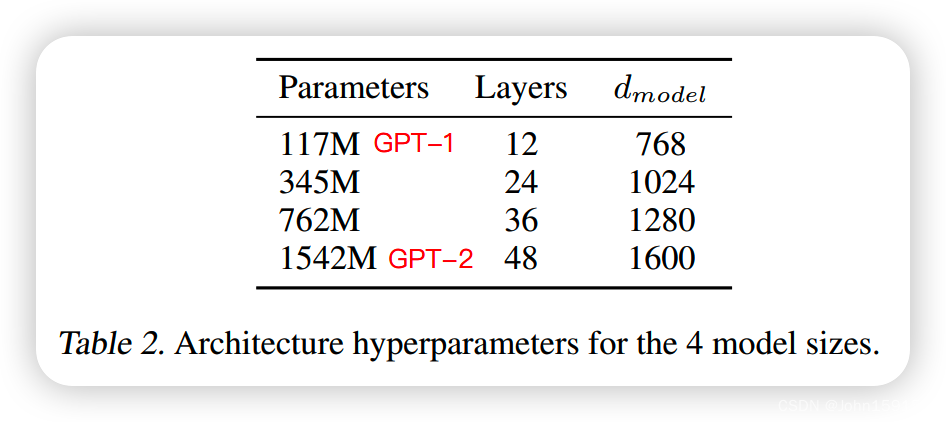
4. 模型架构跟GPT-1[1]类似,只不过在GPT-2里面使用了更多的层,另外也采用了残差网络的方式去避免梯度弥散问题。
实验
5. Dataset
①LAMBADA
②CBT
③WikiText2
④PTB
⑤enwik8
⑥text8
⑦WikiText103
⑧1BW
6. Language Modeling
在8个数据集中的7个Zero-shot learning的效果优于SOTA。在1BW中,效果差的原因可能是其中进行了句子级别的预处理,导致破坏了里面的句子结构。

7. Children’s Book Test
任务是用10个选项进行完形填空。

8. LAMBADA
任务是预测句子的最后一个word。
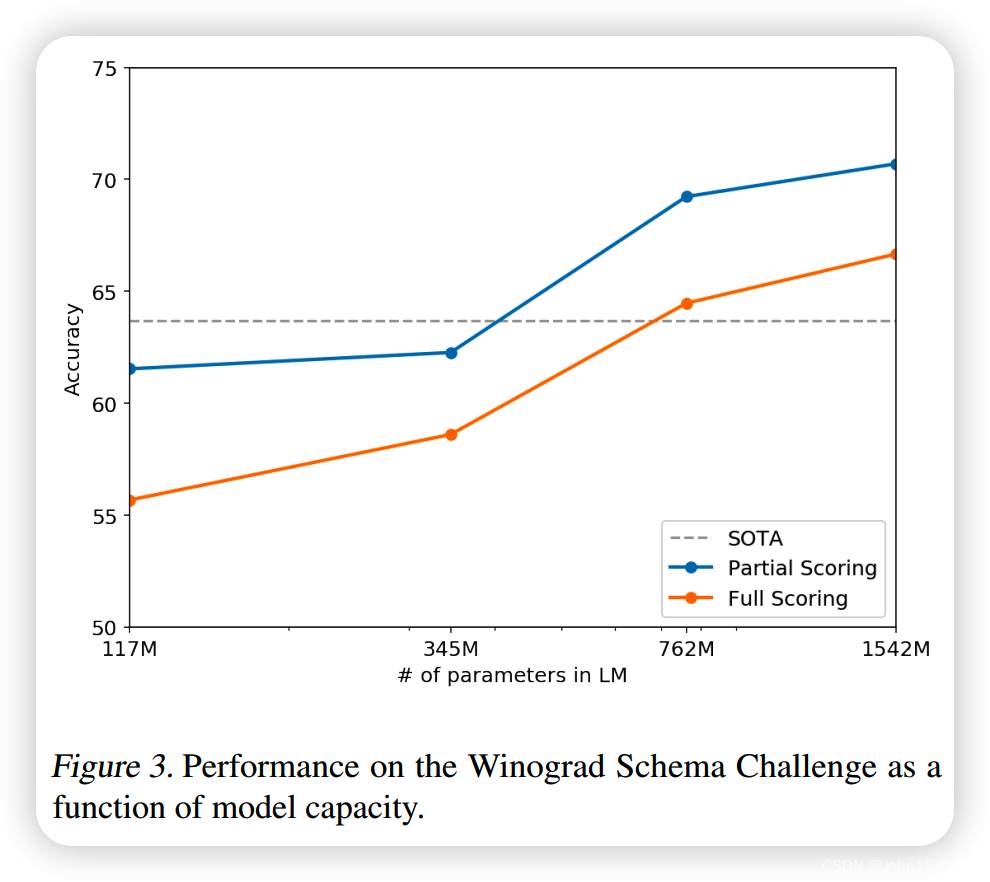
9. Winograd Schema Challenge
任务是解决文本歧义。
10. Reading Comprehension
任务是阅读理解。
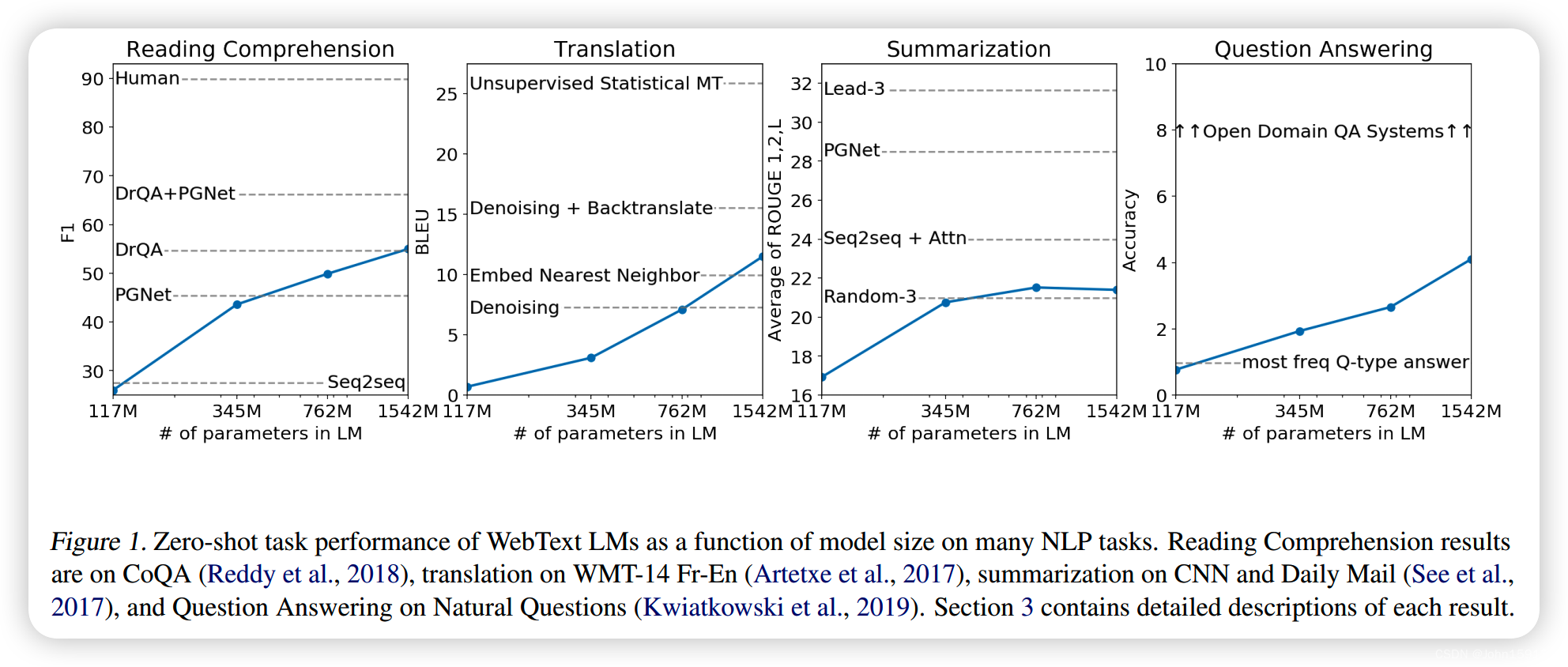
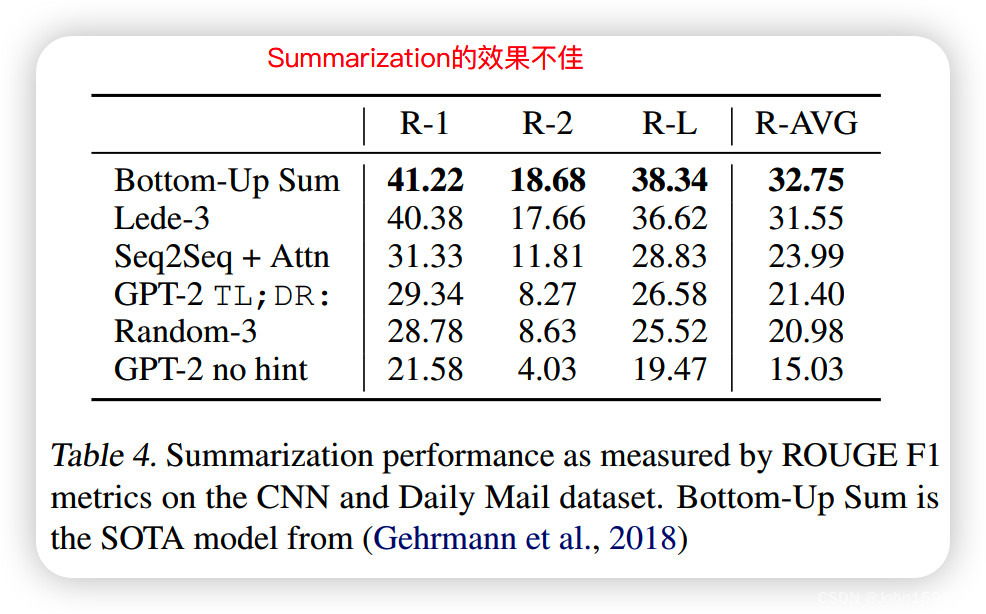
11. Summarization
Extractive的文本摘要,仅比随机抽取3个句子的效果好一点。
12. Translation
Translation效果差,是因为训练数据集里面基本只有英文内容,别的语言文档太少导致。
13. Question Answering
QA效果差,但可以发现随着模型参数量增大,效果会提升明显,所以本文作者认为模型容量是对效果影响的关键因素,这也更坚定了GPT系列会不断把模型做大做深。
14. 本文Discuss里面表达了对当前方向的认可,但是针对目前在某些任务上仍然无法取得较好的效果表达了未知,后续仍需要比较多的探索。这个方向很美好或者很理想,但是仍需很大的努力。
参考资料
[1] https://blog.csdn.net/John159151/article/details/129062724
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!