如何保证服务的高可用性 HA(High Availability)?
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。方法论上,高可用是通过冗余+自动故障转移来实现的。
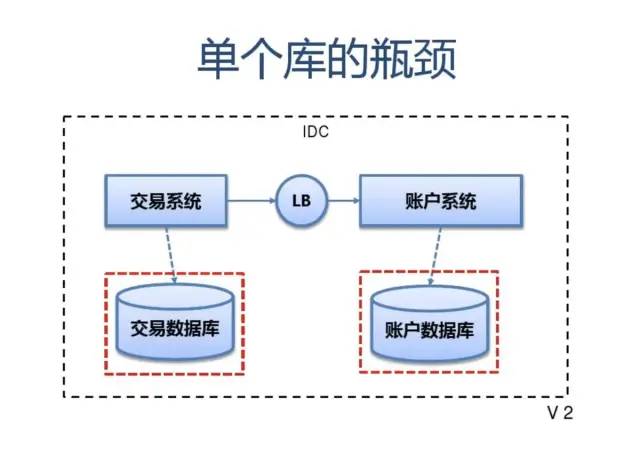
我们都知道,单点是系统高可用的大敌,单点往往是系统高可用最大的风险和敌人,应该尽量在系统设计的过程中避免单点。
方法论上,高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。
保证系统高可用,架构设计的核心准则是:冗余。有了冗余之后,还不够,每次出现故障需要人工介入恢复势必会增加系统的不可服务实践。所以,又往往是通过“自动故障转移”来实现系统的高可用。
互联网架构中,通常是通过冗余+自动故障转移来保证系统的高可用特性。
从实战经验来看如何保证服务的高可用性:
一:服务架构层面
(1)根据服务对象地区,考虑节点分布
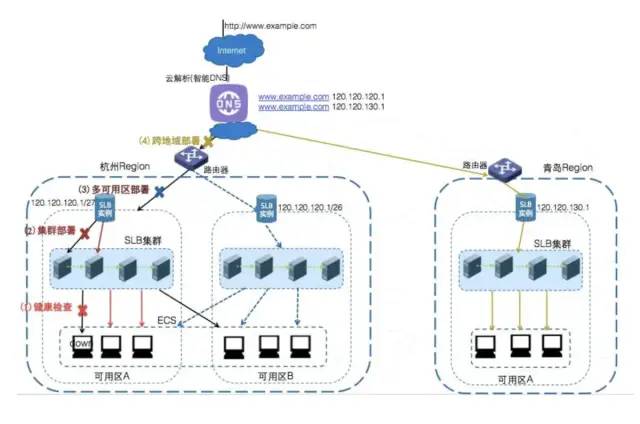
(2)避免服务单点,至少双机
(3)防止代码之间干扰,避免稳定代码和迭代频繁代码放在一起,可以按照业务或者功能做服务分离。
(4)防止服务之间干扰,重要服务最好做隔离,单独部署
(5)防止数据库压力过大,不然,可能产生雪崩效应,可以根据业务特点做分库分表,加缓存等处理.
(6)保证服务能力buffer, 尽量有冗余处理能力.
二:运维层面
(1)服务监控。比如磁盘、CPU、网络
(2)监控多级别,到达不同级别给出不同警告
三:代码层面
(1)保证代码异常不会导致服务挂掉
(2)保证服务是无状态的,可以支持水平扩展
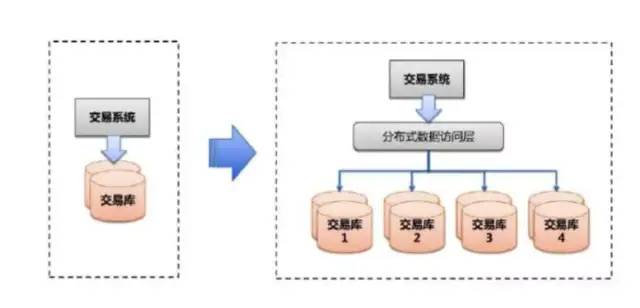
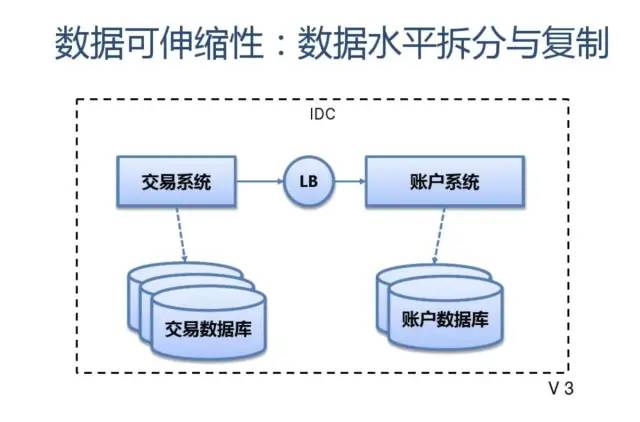
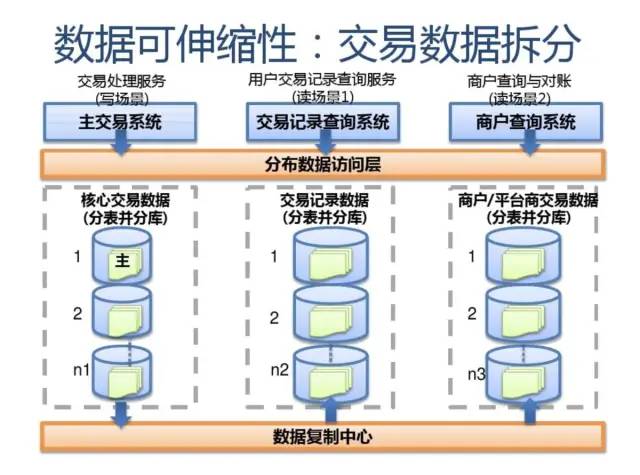
数据的水平扩展
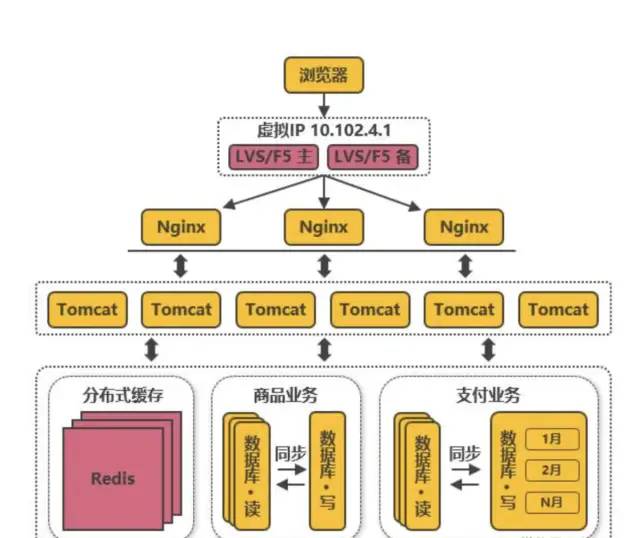
分层高可用架构实践
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据-缓存层:缓存加速访问存储
(6)数据-数据库层:数据库固化数据存储
整个系统的高可用,又是通过每一层的冗余+自动故障转移来综合实现的。
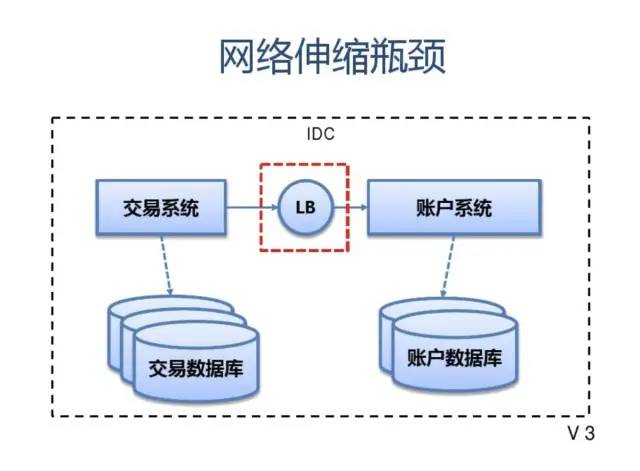
1. 客户端层->反向代理层的高可用
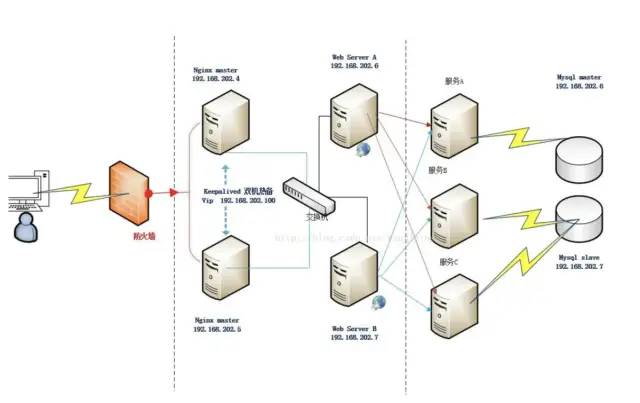
客户端层到反向代理层的高可用,是通过反向代理层的冗余来实现的。以nginx为例:有两台nginx,一台对线上提供服务,另一台冗余以保证高可用,常见的实践是keepalived存活探测,相同virtual IP提供服务。
自动故障转移:当nginx挂了的时候,keepalived能够探测到,会自动的进行故障转移,将流量自动迁移到shadow-nginx,由于使用的是相同的virtual IP,这个切换过程对调用方是透明的。
2. 反向代理层->站点层的高可用
反向代理层到站点层的高可用,是通过站点层的冗余来实现的。假设反向代理层是nginx,nginx.conf里能够配置多个web后端,并且nginx能够探测到多个后端的存活性。
自动故障转移:当web-server挂了的时候,nginx能够探测到,会自动的进行故障转移,将流量自动迁移到其他的web-server,整个过程由nginx自动完成,对调用方是透明的。
3. 站点层->服务层的高可用
站点层到服务层的高可用,是通过服务层的冗余来实现的。“服务连接池”会建立与下游服务多个连接,每次请求会“随机”选取连接来访问下游服务。
自动故障转移:当service挂了的时候,service-connection-pool能够探测到,会自动的进行故障转移,将流量自动迁移到其他的service,整个过程由连接池自动完成,对调用方是透明的(所以说RPC-client中的服务连接池是很重要的基础组件)。
4. 服务层>缓存层的高可用
服务层到缓存层的高可用,是通过缓存数据的冗余来实现的。缓存层的数据冗余又有几种方式:第一种是利用客户端的封装,service对cache进行双读或者双写。
缓存层也可以通过支持主从同步的缓存集群来解决缓存层的高可用问题。
以redis为例,redis天然支持主从同步,redis官方也有sentinel哨兵机制,来做redis的存活性检测。
自动故障转移:当redis主挂了的时候,sentinel能够探测到,会通知调用方访问新的redis,整个过程由sentinel和redis集群配合完成,对调用方是透明的。
说完缓存的高可用,这里要多说一句,业务对缓存并不一定有“高可用”要求,更多的对缓存的使用场景,是用来“加速数据访问”:把一部分数据放到缓存里,如果缓存挂了或者缓存没有命中,是可以去后端的数据库中再取数据的。
这类允许“cache miss”的业务场景,缓存架构的建议是:
将kv缓存封装成服务集群,上游设置一个代理(代理可以用集群的方式保证高可用),代理的后端根据缓存访问的key水平切分成若干个实例,每个实例的访问并不做高可用。
缓存实例挂了屏蔽:当有水平切分的实例挂掉时,代理层直接返回cache miss,此时缓存挂掉对调用方也是透明的。key水平切分实例减少,不建议做re-hash,这样容易引发缓存数据的不一致。
5. 服务层>数据库层的高可用
大部分互联网技术,数据库层都用了“主从同步,读写分离”架构,所以数据库层的高可用,又分为“读库高可用”与“写库高可用”两类。
服务层>数据库层“读”的高可用
服务层到数据库读的高可用,是通过读库的冗余来实现的。
既然冗余了读库,一般来说就至少有2个从库,“数据库连接池”会建立与读库多个连接,每次请求会路由到这些读库。
自动故障转移:当读库挂了的时候,db-connection-pool能够探测到,会自动的进行故障转移,将流量自动迁移到其他的读库,整个过程由连接池自动完成,对调用方是透明的(所以说DAO中的数据库连接池是很重要的基础组件)。
服务层>数据库层“写”的高可用
服务层到数据库写的高可用,是通过写库的冗余来实现的。
以mysql为例,可以设置两个mysql双主同步,一台对线上提供服务,另一台冗余以保证高可用,常见的实践是keepalived存活探测,相同virtual IP提供服务。
自动故障转移:
当写库挂了的时候,keepalived能够探测到,会自动的进行故障转移,将流量自动迁移到shadow-db-master,由于使用的是相同的virtual IP,这个切换过程对调用方是透明的。
小结:
整个互联网分层系统架构的高可用,又是通过每一层的冗余+自动故障转移来综合实现的,具体的:
(1)客户端层到反向代理层的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移。
(2)反向代理层到站点层的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移。
(3)站点层到服务层的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移。
(4)服务层到缓存层的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性。
(5)服务层到数据库“读”的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移。
(6)服务层到数据库“写”的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移。
SLA 是什么?
SLA:服务等级协议(简称:SLA,全称:service level agreement)。是在一定开销下为保障服务的性能和可用性,服务提供商与用户间定义的一种双方认可的协定。通常这个开销是驱动提供服务质量的主要因素。
SLA的定义来源百度,这到底是什么意思呢?
我们平常经常看到互联网公司喊口号,我们今年一定要做到3个9、4个9,即99.9%、99.99%,甚至还有5个9,即99.999%。
这么多9代表什么意思呢?
首先,SLA的概念,对互联网公司来说就是网站服务可用性的一个保证。9越多代表全年服务可用时间越长服务更可靠,停机时间越短,反之亦然。
这么多9是怎么计算的呢?
全年拿365天做计算吧,看看几个9要停机多久时间做能才能达到!
1年 = 365天 = 8760小时
99.9 = 8760 * 0.1% = 8760 * 0.001 = 8.76小时
99.99 = 8760 * 0.0001 = 0.876小时 = 0.876 * 60 = 52.6分钟
99.999 = 8760 * 0.00001 = 0.0876小时 = 0.0876 * 60 = 5.26分钟
从以上看来,全年停机5.26分钟才能做到99.999%,即5个9。依此类推,要达到6个9及更多9,可说是非常难了吧。
怎么做到更多的9?
每个公司对几个9的定义都不一样,互联网公司至少都是99.99吧。像一些政府网站,如社保公积金等,经常故障服务不可用,能做到99.9就不错了。
如果我们提供的服务可用性越低,意味着造成的损失也越大,别的不说,如果是特别重要的时刻,或许就在某一分钟,你可能就会因服务不可用而丢掉一笔大的订单,这都是始料未及的。所以,只要尽可能的提升SLA可用性才能最大化的提高企业生产力。
要做到更多的9,就要不断的监控自己的服务,服务挂掉能及时恢复服务。就像开车出远门,首先得检查轮胎,同时还得准备一个备胎一样的道理。现在的产品和系统都非常的复杂,彼此连接依赖越来越复杂,为了整体的高速运转,对每个部件的稳定性越来越高,越来越精密,发展到一定程度,人力已经无法掌控,任何一个组件出异常都有可能牵一发而动全身,影响全局。每个部件的稳定性和精密程度决定了整体的工程质量,也决定了整体的发展速度。
定义SLI
SLI, Service Level Indicator 关键量化指标.
SLI关注下面五点:
要测量的指标是什么?
测量时的系统状态?
如何汇总处理测量的指标?
测量指标能否准确描述服务质量?
测量指标的可靠度(trust worthy)?
SLO,Service-Level Objective 服务等级目标,指定了服务所提供功能的一种期望状态。
一个有明确SLA的服务最理想的运行状态是:增加额外资源来改进系统所带来的收益小于把该资源投给其他服务所带来的收益。
一个简单的例子就是某服务可用性从99.9%提高到99.99%所需要的资源和带来的收益之比,是决定该服务是否应该提供4个9的重要依据。
SLA的计算方式,是使用正常运行时间/(正常运行时间+故障时间),当指标为99.99的时候,每年的停机时间只有52.26分钟。。。停机时间又分为两种,一种是计划内停机时间,一种是计划外停机时间,而运维则主要关注计划外停机时间。
在分布式系统中用时间指标来衡量系统的可用性,简直就是无效的。分布式系统中,部分可用的情况太多了,例如后端有两个rs,而一个rs坏了,那么就会有百分之五十的请求失败。这种情况SLA怎么来计算?扣时间还是不扣呢?
在分布式系统中,一般使用请求的成功率来计算SLA,也就是
SLA=请求成功/(请求成功+请求失败)
在使用这种计算方式的时候,无论你是前端的web服务,还是后端的存储服务,还是离线服务,都是可以很好的计算。毕竟是一个可以量化的数据。在定义SLA的时候,顺便可以定义出监控的主要指标,例如请求的延迟,吞吐量等。
在进行定义这些关键性指标的时候,也就是定义哪些请求成功,哪些请求失败,是有很大关系的,例如支付宝的核心功能是支付,如果支付功能可以,那么就满足了大多数的高可用,而所谓的其他的一些附加功能,例如城市服务,也影响不了多少人,当然, 也要看基数。
在提供服务的时候,服务可以分为两种类型,一种类型是面对消费者的服务,一种是基础设施服务,例如微信就是面对消费者的服务,而各种云平台则是基础设施服务。
当面对消费者服务的时候,一般会有对应的产品经理,那么可以由产品经理定义各种关键性的指标来衡量一个服务的可用性,例如微信在定义的时候,可以使用发送消息的成功率;消费者服务,可以参考竞争对手的可用性水平;免费的还是收费的;有没有替代产品可以使用。在这个时候,其实还可以定义服务降级,例如微信最常用的功能是发送消息和朋友圈,这两个服务的可用性可以定义为四个9,而对于所谓的摇一摇,附近等服务,可以定义低等级的可用性,例如两个9,这种构建方式,可以很大程度上节省成本,毕竟物理服务器冗余才是提高可用性的唯一方式。
在消费者服务类型中,还需要注意每个请求的成败后果是不一样的,例如系统注册,或者是一个信息发送失败,系统注册失败,可能就不用这个系统了,而一个信息发送失败,用户可能认为是自己的网络有问题。。。
在提供基础设施服务的时候,一般分为两个部分,一个部分是直接提供给用户使用的功能,例如提供VM访问服务;一个部分是平台的管控功能,例如云平台里面创建虚拟机,创建SLB等。这两个的失败是完全不一样的,用户的功能出了问题,那么就是故障了,但是管控服务出现问题,只要及时修好就行了,这种一般使用的评率很少,所以请求数量也不多。
亚马逊的S3服务水平协议
可用性保证(Service Commitment )
保证“每月99.9%的正常运行时间”。S3 SLA保证一个月里所有以5分钟为单位的时间片中,平均有99.9%是可用的。SLA容许的最遭情况等于每月有40分钟不可用。
服务补偿
如果达不到SLA的承诺,Amazon会提供服务补偿,如果达不到 99.9%的服务水平,那么Amazon将减免下个月10%的费用。如果可用性下降到99.0%以下,换算后相当于一个月内至少有将近7个小时无法服务, 那么Amazon将减免25%的费用。
假设一个用户存放了500G的数据。把500G数据放进S3并且在一个月内全部数据都使用10次的话,总共的费用大约是 $1000。
如果发生5小时的故障,那么该用户将得到 $100 的退款。如果故障时间从7个小时到一整个月的话, 该用户将得到 $250 的补偿。
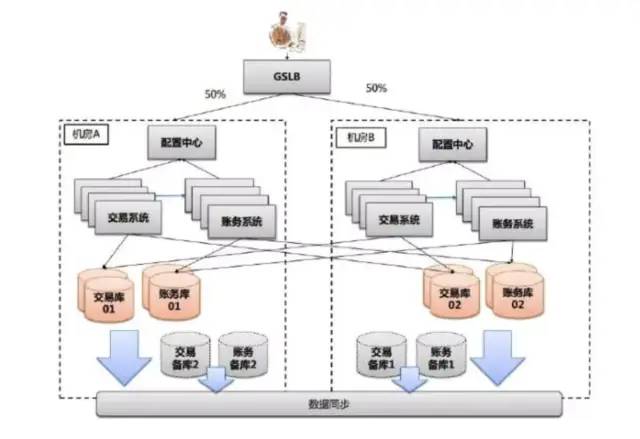
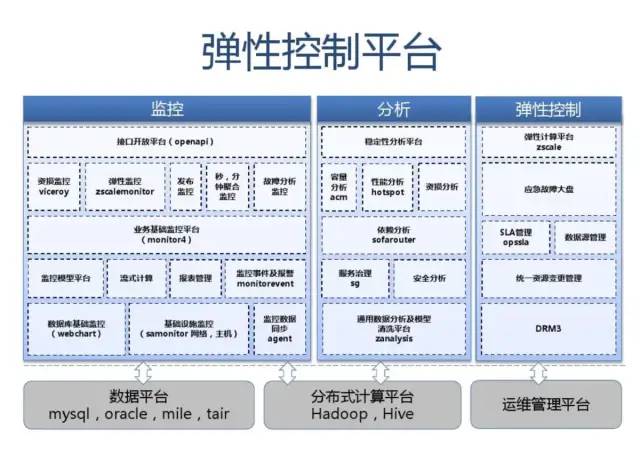
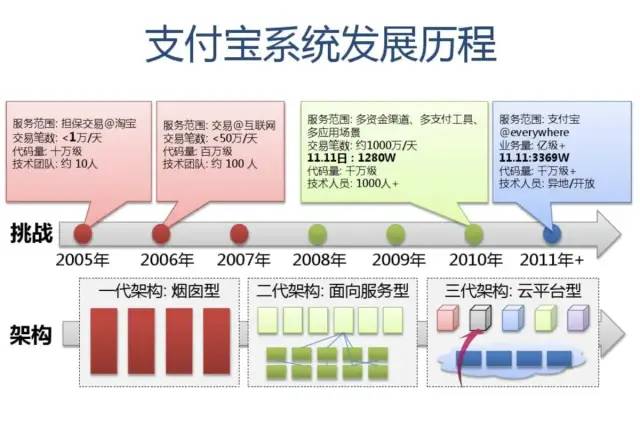
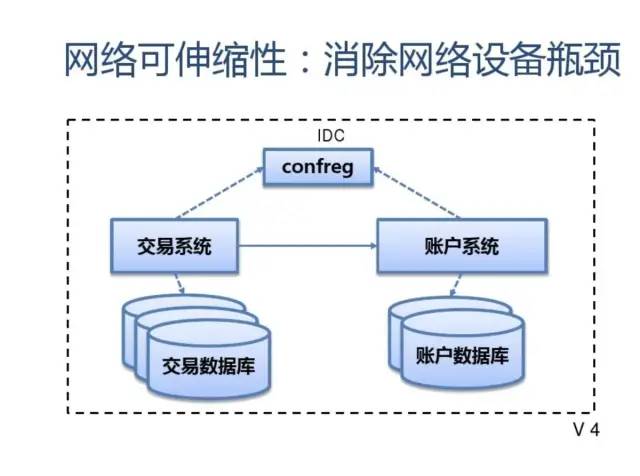
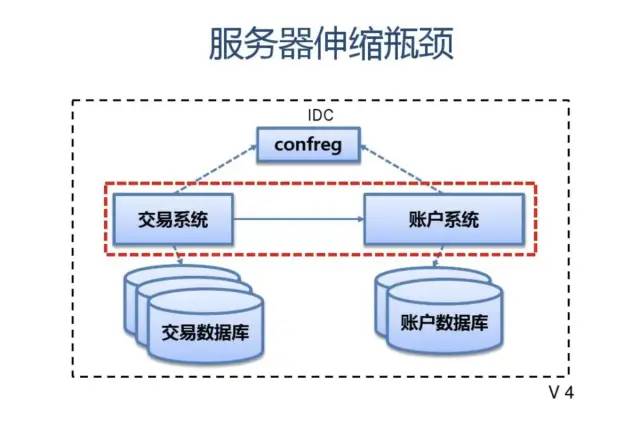
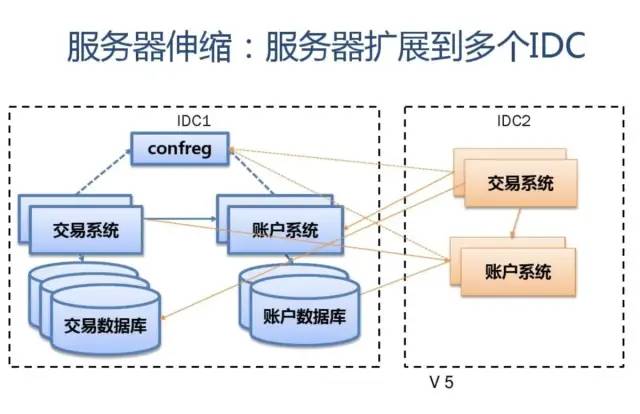
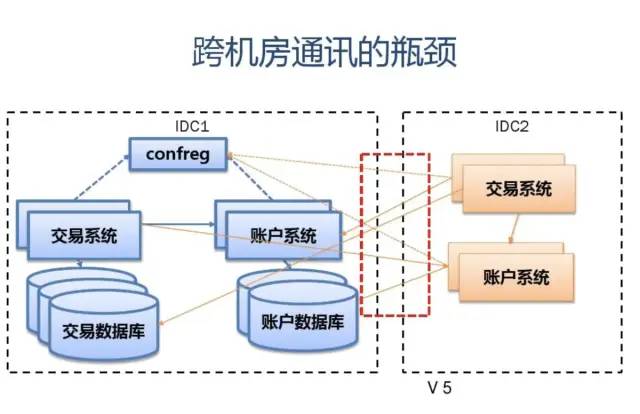
附:支付宝高可用性架构演进

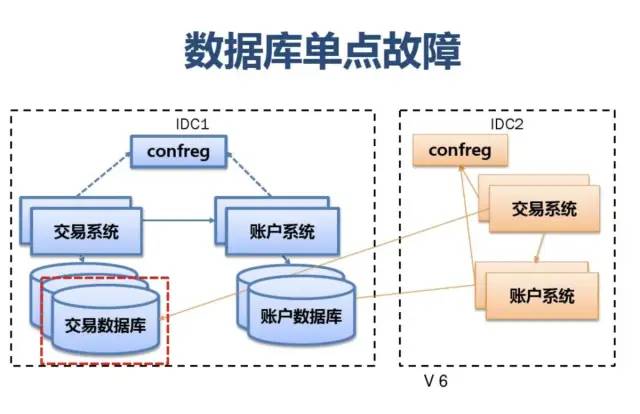
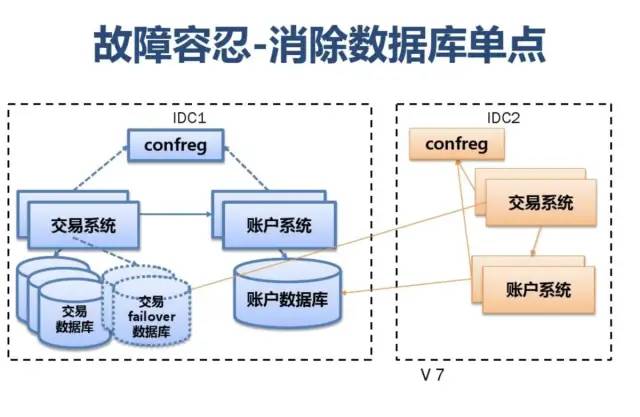
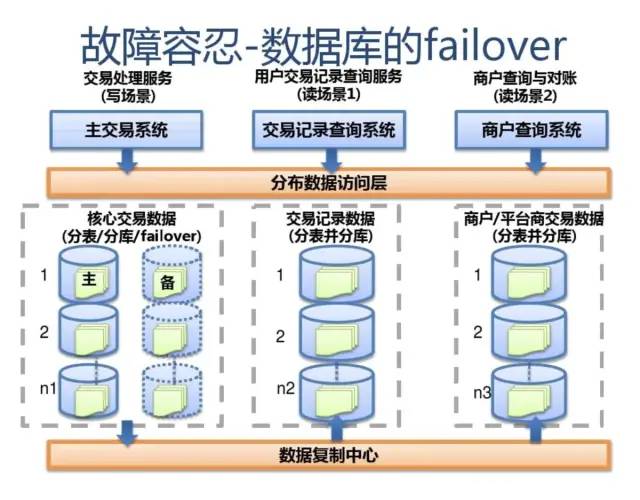
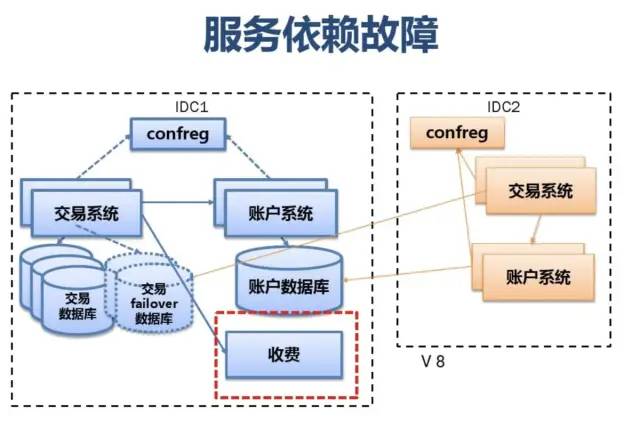
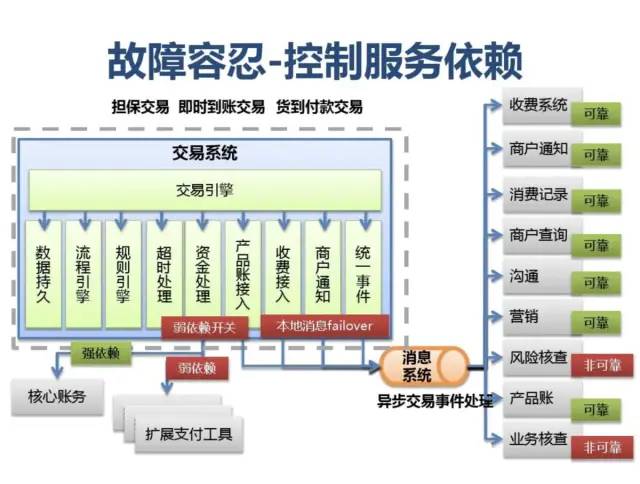
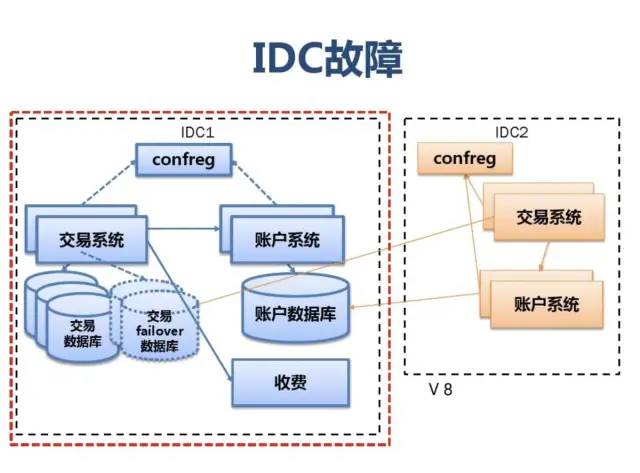
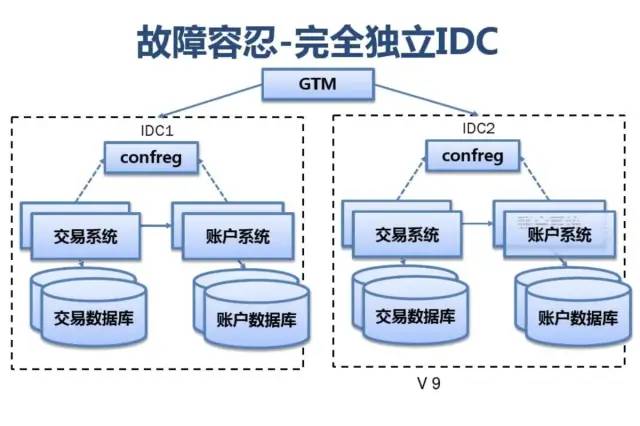

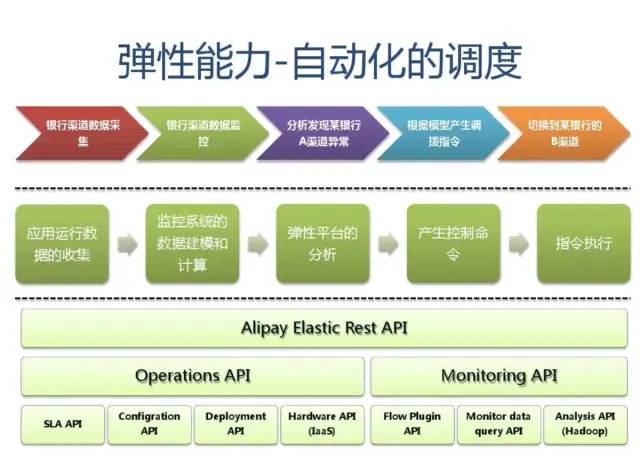
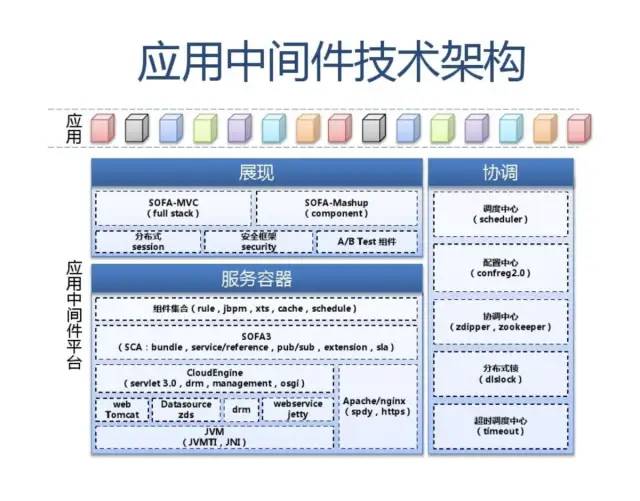
应用中间件技术架构应用:
展现 SOFA-MVC (full stack)分布式 session安全框架 security SOFA-Mashup (component) A/B Test组件
协调/调度中心 (scheduler)
服务容器 组件集合(rule,jbpm,xts,cache,schedule) SOFA3 (SCA:bundle,service/reference,pub/sub,extension,sla) CloudEngine (servlet 3.0,drm,management,osgi) web Tomcat Datasource zds drm webservice jetty Apache/nginx (spdy,https)
配置中心 (confreg2.0)
应用中间件平台
协调中心 (zdipper,zookeeper)
分布式锁 (dlslock)
JVM (JVMTI,JNI)
超时调度中心 (timeout)

参考资料
https://blog.csdn.net/daiyudong2020/article/details/50550471
https://blog.csdn.net/chdhust/article/details/74086776
https://blog.csdn.net/tm6znf87mdg7bo/article/details/83663392
https://blog.csdn.net/chenyong19870904/article/details/52986784
https://wenku.baidu.com/view/444baa0ace2f0066f433221e.html
专注分享 Java、 Kotlin、Spring/Spring Boot、MySQL、redis、neo4j、NoSQL、Android、JavaScript、React、Node、函数式编程、编程思想、"高可用,高性能,高实时"大型分布式系统架构设计主题。
High availability, high performance, high real-time large-scale distributed system architecture design。
分布式框架:Zookeeper、分布式中间件框架等
分布式存储:GridFS、FastDFS、TFS、MemCache、redis等
分布式数据库:Cobar、tddl、Amoeba、Mycat
云计算、大数据、AI算法
虚拟化、云原生技术
分布式计算框架:MapReduce、Hadoop、Storm、Flink等
分布式通信机制:Dubbo、RPC调用、共享远程数据、消息队列等
消息队列MQ:Kafka、MetaQ,RocketMQ
怎样打造高可用系统:基于硬件、软件中间件、系统架构等一些典型方案的实现:HAProxy、基于Corosync+Pacemaker的高可用集群套件中间件系统
Mycat架构分布式演进
大数据Join背后的难题:数据、网络、内存和计算能力的矛盾和调和
Java分布式系统中的高性能难题:AIO,NIO,Netty还是自己开发框架?
高性能事件派发机制:线程池模型、Disruptor模型等等。。。
合抱之木,生于毫末;九层之台,起于垒土;千里之行,始于足下。不积跬步,无以至千里;不积小流,无以成江河。
【更多阅读】
【企业架构设计实战】0 企业数字化转型和升级:架构设计方法与实践
【企业架构设计实战】1 企业架构方法论
【企业架构设计实战】2 业务架构设计
【企业架构设计实战】3 怎样进行系统逻辑架构?
【企业架构设计实战】4 应用架构设计
【企业架构设计实战】5 大数据架构设计
【企业架构设计实战】6 数据架构
企业数字化转型和升级:架构设计方法与实践
【成为架构师课程系列】怎样进行系统逻辑架构?
【成为架构师课程系列】怎样进行系统详细架构设计?
【企业架构设计实战】企业架构方法论
【企业架构设计实战】业务架构设计
【企业架构设计实战】应用架构设计
【企业架构设计实战】大数据架构设计
【软件架构思想系列】分层架构
【软件架构思想系列】模块化与抽象
软件架构设计的核心:抽象与模型、“战略编程”
企业级大数据架构设计最佳实践
编程语言:类型系统的本质
程序员架构修炼之道:软件架构设计的37个一般性原则
程序员架构修炼之道:如何设计“易理解”的系统架构?
“封号斗罗” 程序员修炼之道:通向务实的最高境界
程序员架构修炼之道:架构设计中的人文主义哲学
Gartner 2023 年顶级战略技术趋势
【软件架构思想系列】从伟人《矛盾论》中悟到的软件架构思想真谛:“对象”即事物,“函数”即运动变化
【模型↔关系思考法】如何在一个全新的、陌生的领域快速成为专家?模仿 + 一万小时定律 + 创新
Redis 作者 Antirez 讲如何实现分布式锁?Redis 实现分布式锁天然的缺陷分析&Redis分布式锁的正确使用姿势!
红黑树、B树、B+树各自适用的场景
你真的懂树吗?二叉树、AVL平衡二叉树、伸展树、B-树和B+树原理和实现代码详解
【动态图文详解-史上最易懂的红黑树讲解】手写红黑树(Red Black Tree)
我的年度用户体验趋势报告——由 ChatGPT AI 撰写
我面试了 ChatGPT 的 PM (产品经理)岗位,它几乎得到了这份工作!!!
大数据存储引擎 NoSQL极简教程 An Introduction to Big Data: NoSQL
《人月神话》(The Mythical Man-Month)看清问题的本质:如果我们想解决问题,就必须试图先去理解它
【架构师必知必会】常见的NoSQL数据库种类以及使用场景
新时期我国信息技术产业的发展【技术论文,纪念长者,2008】
B-树(B-Tree)与二叉搜索树(BST):讲讲数据库和文件系统背后的原理(读写比较大块数据的存储系统数据结构与算法原理)
HBase 架构详解及数据读写流程
【架构师必知必会系列】系统架构设计需要知道的5大精要(5 System Design fundamentals)
《人月神话》8 胸有成竹(Chaptor 8.Calling the Shot -The Mythical Man-Month)
《人月神话》7(The Mythical Man-Month)为什么巴比伦塔会失败?
《人月神话》(The Mythical Man-Month)6贯彻执行(Passing the Word)
《人月神话》(The Mythical Man-Month)5画蛇添足(The Second-System Effect)
《人月神话》(The Mythical Man-Month)4概念一致性:专制、民主和系统设计(System Design)
《人月神话》(The Mythical Man-Month)3 外科手术队伍(The Surgical Team)
《人月神话》(The Mythical Man-Month)2人和月可以互换吗?人月神话存在吗?
在平时的工作中如何体现你的技术深度?
Redis 作者 Antirez 讲如何实现分布式锁?Redis 实现分布式锁天然的缺陷分析&Redis分布式锁的正确使用姿势!
程序员职业生涯系列:关于技术能力的思考与总结
十年技术进阶路:让我明白了三件要事。关于如何做好技术 Team Leader?如何提升管理业务技术水平?(10000字长文)
当你工作几年就会明白,以下几个任何一个都可以超过90%程序员
编程语言:类型系统的本质
软件架构设计的核心:抽象与模型、“战略编程”
【图文详解】深入理解 Hbase 架构 Deep Into HBase Architecture
HBase 架构详解及读写流程原理剖析
HDFS 底层交互原理,看这篇就够了!
MySQL 体系架构简介
一文看懂MySQL的异步复制、全同步复制与半同步复制
【史上最全】MySQL各种锁详解:一文搞懂MySQL的各种锁
腾讯/阿里/字节/快手/美团/百度/京东/网易互联网大厂面试题库
Redis 面试题 50 问,史上最全。
一道有难度的经典大厂面试题:如何快速判断某 URL 是否在 20 亿的网址 URL 集合中?
【BAT 面试题宝库附详尽答案解析】图解分布式一致性协议 Paxos 算法
Java并发多线程高频面试题
编程实践系列: 字节跳动面试题
腾讯/阿里/字节/快手/美团/百度/京东/网易互联网大厂面试题库
[精华集锦] 20+ 互联网大厂Java面试题全面整理总结
【BAT 面试题宝库附详尽答案解析】分布式事务实现原理
……