编码解码
- 一、背景
- 二、字符的相关概念
- 三、字符集
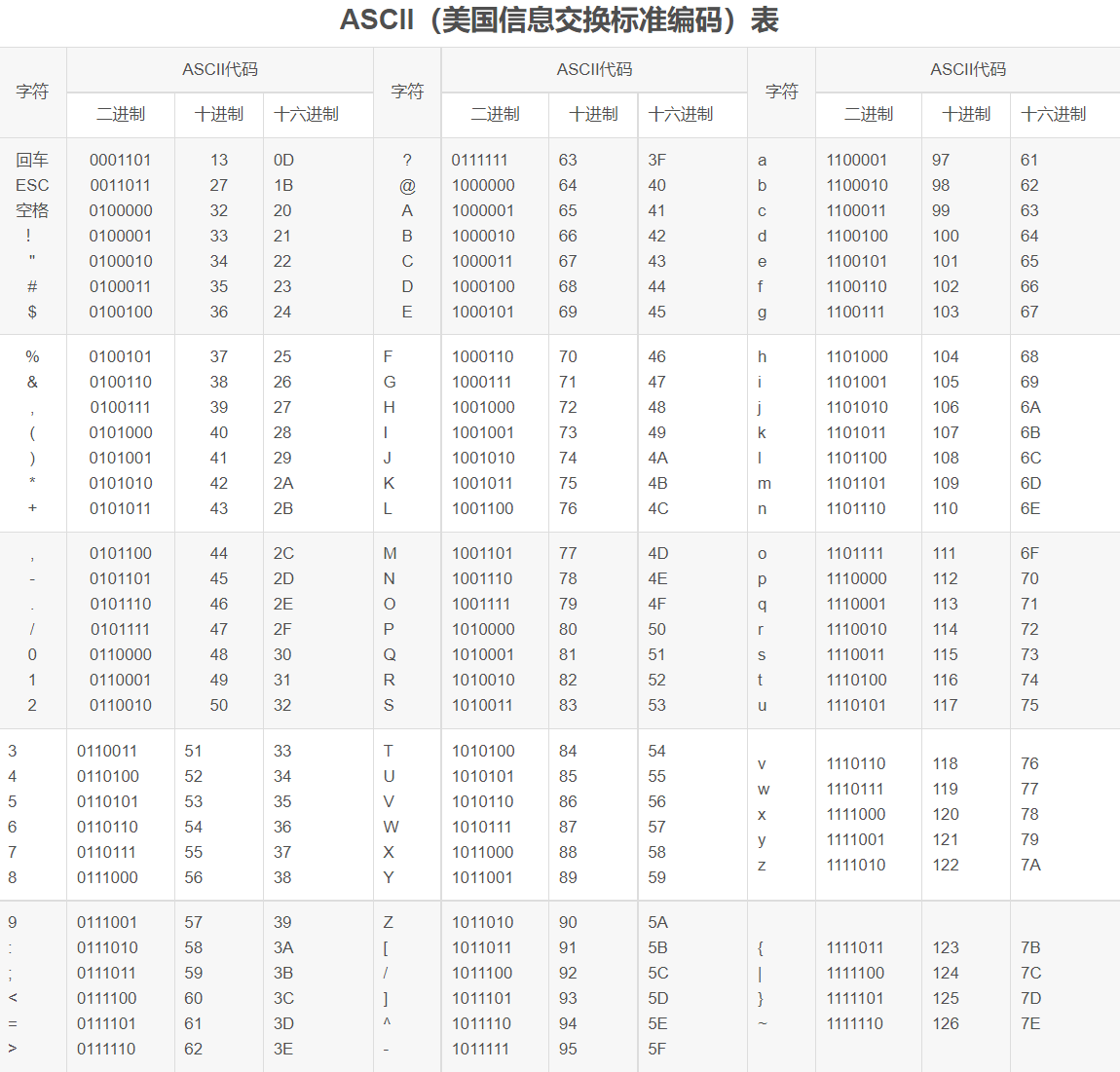
- 3.1 ASCII[ˈæski]
- 3.1.1 ASCII的编码方式
- 3.1.2 EASCII
- 3.2 GBK
- 3.2.1 GB 2312-80
- 3.2.2 GBK的制订
- 3.2.3 GBK的实现方式
- 3.3 Unicode(统一码、万国码)
- 3.3.1 Unicode的出现背景
- 3.3.2 Unicode的编写方式
- 3.3.3 Unicode的实现方式
- 3.3.3 Unicode的问题
- 3.3.4 Unicode的发展
- 四、锟斤拷和烫的来源
- 4.1 锟斤拷
- 4.2 烫、屯、
- 4.3 锘、匡、豢
- 五、使用Java程序编码、解码
资料来源【锟斤拷�⊠是怎样炼成的——中文显示“⼊”门指南【柴知道】、【一听就懂字符集、ASCII、GBK、UTF-8、Unicode、乱码、字符编码、解码问题的讲解】
一、背景
我们经常见到txt文本打开后却通篇是锟斤拷或者烫烫烫烫烫,也见过一些复杂或者生僻的字显示时换了字体样式,这是由于编码方式和解码方式不同造成的。
二、字符的相关概念
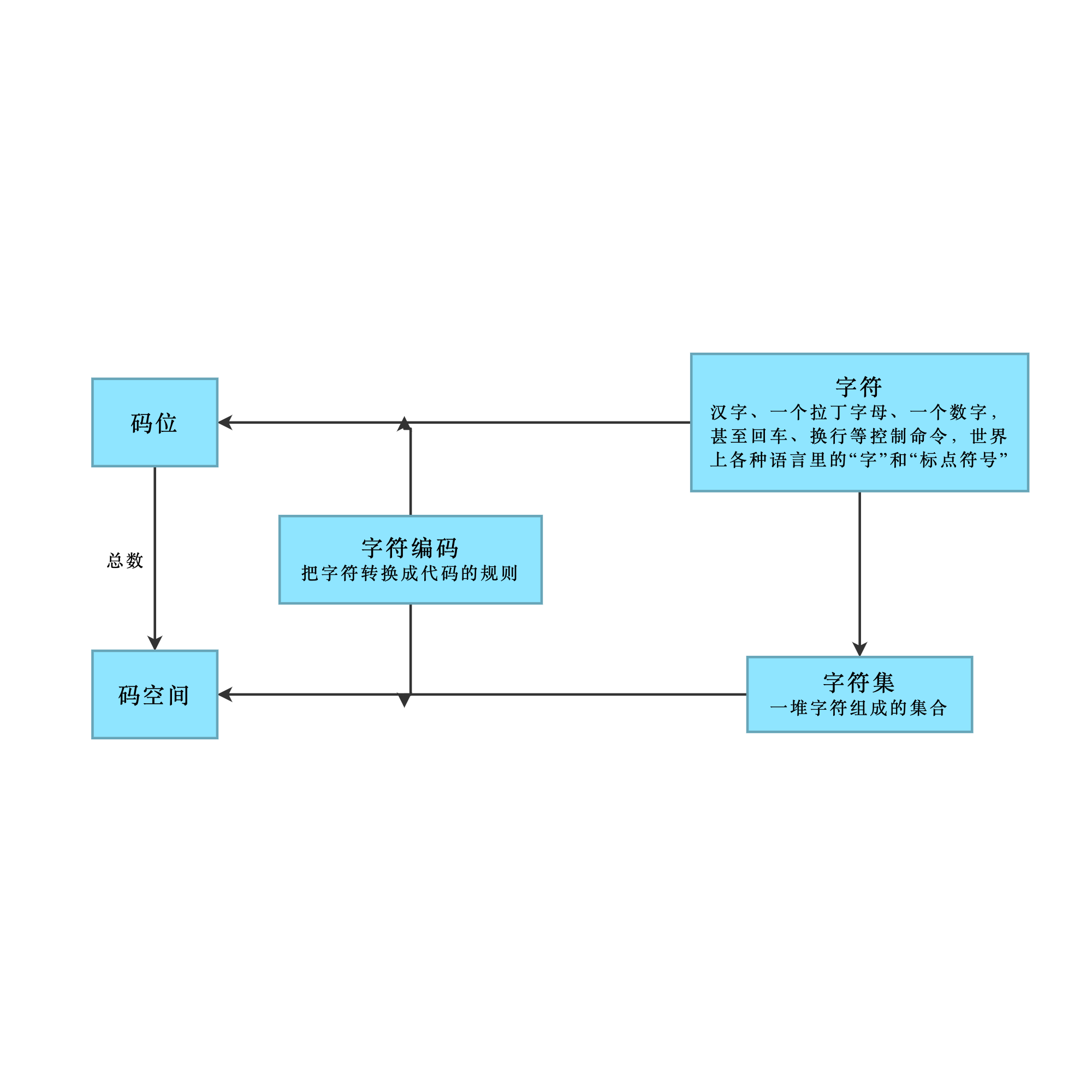
- 一个汉字、一个拉丁字母、一个数字,甚至回车、换行等控制命令,世界上各种语言里的“字”和“标点符号”,都属于“字符”。
- 一堆字符组成的集合,叫做“字符集”。
- 把字符转换成代码的规则,叫做“字符编码”。
- 每个字符经过字符编码后各自对应相应的“码位”(码点),譬如“A”对应“0011 0101”
- 码位的总数称为“码空间”
三、字符集
3.1 ASCII[ˈæski]
3.1.1 ASCII的编码方式
- 1967年,美国人先搞出了“美国信息交换标准代码”(American Standard Code for Information Interchange,简称 ASCII)。
- ASCII每个字符的码位都是一个字节,ASCII 总共收录了 128 个字符,包括大小写拉丁字母、数字、常用标点,以及像 ESC、换行这种看不见的控制字符。每个字符的码位首位一定是0。
3.1.2 EASCII
- 用一个字节编码字符,最多能容纳256个码位。ASCII 收录了 128 个,所以西欧一些国家,就制订了“扩展美国信息交换标准代码”,EASCII。
- EASCII的内码是由0到255共有256个字符组成。来表示其他的字符:比如上方有注音符号的法语字母,西班牙语里的特殊标点,数学上常用的 α、β 等希腊字母,以及一大堆特殊符号等等。
3.2 GBK
3.2.1 GB 2312-80
- 各国、地区的官方标准则是根据 ISO/IEC 10646 来制定的。ISO/IEC 10646 跟 Unicode 标准区别不大,码位完全一致,二者几乎可以划等号,只是面向的对象不同。
- 我国 1980 年公布的《GB 2312-80 信息交换用汉字编码字符集基本集》,就包含了 6763 个常用简体汉字,以及一些标点、符号、数字、拉丁字母等。
- 每个汉字及符号以两个字节来表示
因为绝大多数简体汉字字体,都还是只适配了 GB 2312 里的这六千多个常用汉字。比如最常见的公文字体之一「仿宋 GB2312」,意思就是说我只设计了 GB 2312 字符集中的字符。如果不这个字符集中,那么计算机会调用其他字体来显示或直接给你显示成个框框。
3.2.2 GBK的制订
- 微软就根据各地字符集和字符编码,扩展了 GB 2312 字符集,共包含2万多字符,加入了一些罕见字、繁体汉字同时兼容ASCII,这份扩展的字符集后来成为了“汉字内码扩展规范 GBK”,这里的 K 就是“扩展”的意思。
- 但即便是少量汉字,也会出现中日韩一字多形的问题,譬如:“户/户/戸”
3.2.3 GBK的实现方式
GBK兼容ASCII,但是一个是以单字节编码,一个是以双字节编码,怎么区分呢?
GBK规定,汉字字节的第一位必须是1,两个字节共16位,舍弃一位,仍有32768个码位,能够满足所需
3.3 Unicode(统一码、万国码)
3.3.1 Unicode的出现背景
为了解决相互之间的兼容性差的问题,Unicode 技术委员会为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年,统一码开始研发。Unicode 1.0发布于1991年10月
3.3.2 Unicode的编写方式
- Unicode 决定以「书写系统」为标准来分类和收录字符。虽然拉丁字母里的“o”,和西里尔字母“о”,以及希腊字母“ο”,长得几乎一样,但既然属于三个不同的书写系统,而且过去各地都已经搞出了相应的字符编码,为了兼容性,就需要安排三个不同的码位。
- 其中甚至还有为各个国家、地区、甚至企业准备的“私用区”,可以供大家自定义使用。像苹果就把自己的logo放进了私用区
- Unicode提供了三种编码方案:UTF-8,UTF-16,UTF-32
3.3.3 Unicode的实现方式
- UTF-32直接用四个字节表示一个字符
- UTF-16是变长编码方式,每个字符编码为2或4字节。
- 当码点<216时直接转换,不够在前补零
- 当码点>=216,讲码点-16(65536),最多需要20位表示,不够前面补零
- 将前10位单独取出和0xD800相加,得到了一个新的整数W1,W1的取值范围是 [0xD800,0xDBFF] 。W1又称为高位代理项
- 将后10位单独取出和0xDC00相加,得到了一个新的整数W2,W2的取值范围是[0xDC00,0xDFFF]。W2又称低位代理项
- 最后,将W1和W2合并起来,得到的二进制字节就是UTF-16的编码结果,总共是4个字节"
UTF-16的特点
- 对于在区间[0xD800,0xDFFF]中的码点,Unicode字符集未定义任何字符,这个区间的码点专用于UTF-16的代理项UTF-16中,高位代理项和低位代理项是不重叠的;
- 高位代理项的范围是[0xD800,0xDBFF],而低位代理项的则是[0xDC00,0xDFFF]
- UTF-16是一种“自同步(self-synchronizing)”的编码方式,即可以在不追溯前面代码单元的前提下,独立判断出是否是某字符的开始单元
- UTF-8也是自同步、变长编码方式,分为四个长度区,兼容ASCII,汉字占三个字节

3.3.3 Unicode的问题
- 安全问题:利用之间长得略微有点区别字符制作出钓鱼网站、利用康熙部首的“⼊”,替换了正常的“入”。

- UTF-32、UTF-16不兼容ASCII,且浪费空间
3.3.4 Unicode的发展
Unicode至今仍在不断增修前最新的版本为 2020 年 3 月公布的 13.0,收录了 13 万个字符。
具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
2022年1月,Unicode 技术委员会批准在同年9月Unicode 15.0中发布五个新符号。这些符号基于太阳系中新发现的跨海王星天体(TNO,在海王星轨道之外的天体);
5月6日,Unicode标准宣布将5个行星符号加入字符集,包括中国水神共工等。
四、锟斤拷和烫的来源
4.1 锟斤拷
- 当你以GBK 编码保存一段文字,
- 再用最常见的 UTF-8 编码打开,会因为识别问题用�替换,
- 再次保存,文档中所有的�字符,就被根据 UTF-8 编码,编码为了 0xEF BF BD。
- 再次使用 GBK 编码打开了这份文档。此时根据 GBK 编码规则,EFBF、BDEF、BFBD 这三个码位对应的,正是“锟斤拷”
4.2 烫、屯、
- 微软编译器访问未经初始化的栈内存,编译器在debug模式下会对这块栈内存写入0xCCCCCCC,而控制台默认以GBK显示,而“烫”的GBK编码是0xCCCC
- 访问未经初始化的堆内存,编译器会写入0xCD,并且堆的前后字节会写入0xFD来作为检测区防止数组越界,而0xCDCD对应屯
4.3 锘、匡、豢
与字节标记顺序有关(BOM)
UTF-8的字节标记:EF BB BF
锘:EFBB
匡:BFEF
豢:BBBF
五、使用Java程序编码、解码
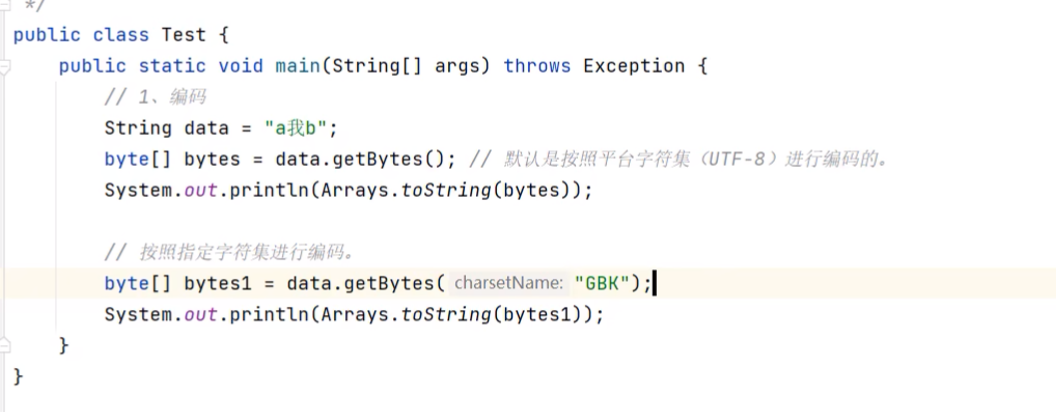
Java程序编码

Java程序解码



![[LeetCode]1237. 找出给定方程的正整数解](https://img-blog.csdnimg.cn/3a3c37b60d8a4b82bf6d8e537608bc38.png)
![[Android Studio] Android Studio Virtual Device(AVD)虚拟机的功能试用](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)