HTML面试题(一)
前言:
面试题及答案解析,大部分来自网络整理,我自己做了一些简化,如果想了解的更多,可以搜索一下,前端面试题宝典微信公众号或者查百度,另外如果出现错误请积极指正❤❤❤
1.什么是HTML5,以及和HTML的区别是什么?
-
HTML5是HTML的新标准,其主要目标是无需任何额外的插件如Flash、Silverlight等,就可以传输所有内容,
它囊括了动画、视频、丰富的图形用户界面等。
-
HTMl5是由万维网(W3C)和
Web Hypertext Application Technology Working Group合作创建的HTML新版本。
区别:
从文档声明类型上看:
- HTML是很长的一段代码,很难记住
- HTML5却只有简简单单的声明,方便记忆
从语义结构上看:
- HTML没有体现结构语义化的标签
- HTML5提供了一些新的标签
2.什么是渐进增强和优雅降级
-
渐进增强(progressive enhancement):
主要是针对低版本的浏览器进行页面重构,保证基本的功能情况下,再针对高级浏览器进行效果,交互等方面的改进和追加功能,以达到更好的用户体验
-
优雅降级 graceful degradation:
一开始就构建完整的功能,然后再针对低版本的浏览器进行兼容
区别:
-
优雅降级是从复杂的现状开始的,并试图减少用户体验的供给
而渐进增强是从一个非常基础的,能够起作用的版本开始的,并在此基础上不断扩充,以适应未来环境的需要
-
优雅降级(功能衰竭)意味着往回看,
而渐进增强则意味着往前看,同时保证其根基处于安全地带
3.Node与Element的关系
Element 继承于 Node,具有Node的方法,同时又拓展了很多自己的特有方法
Element的一些方法里,是明确区分了Node和Element的(比如说:childNodes与 children, parentNode与parentElement等方法
Node的一些方法,返回值为Node,比如说文本节点,注释节点之类的,而Element的一些方法,返回值则一定是Element
4.导致页面加载白屏时间长的原因有哪些?怎么优化?
白屏时间:
从屏幕空白到显示第一个画面的时间
白屏时间的重要性:
提升用户的体验,减少用户的跳出,提升页面的留存率
白屏的过程:
1、浏览器会先对页面进行域名解析,获取到服务器的IP地址后,进而和服务器进行通信。
Tips: 通常在整个加载页面的过程中,浏览器会多次进行DNS Lookup,包括页面本身的域名查询以及在解析HTML页面时加载的JS、CSS、Image、Video等资源产生的域名查询。
2、建立TCP连接请求
浏览器和服务端TCP请求建立的过程,是基于TCP/IP,该协议由网络层的IP和传输层的TCP组成。IP是每一台互联网设备在互联网中的唯一地址。
TCP通过三次握手建立连接,并提供可靠的数据传输服务。
3,服务端请求处理响应
在TCP连接建立后,Web服务器接受请求,开始进行处理,同时浏览器端开始等待服务器的处理响应。
Web服务器根据请求类型的不同,进行相应的处理。静态资源如图片、CSS文件、静态HTML直接进行响应;如其他注册的请求转发给相应的应用服务器,进行如数据处理、缓存中取数据,将数据按照约定好的格式响应给浏览器。
在大型应用中,通常为分布式服务架构,应用服务器的处理有可能经过很多个系统的中间件,最终获取到需要的数据
4,客户端下载、解析、渲染显示页面
在服务器返回数据后,客户端浏览器接收数据,进行HTML下载、解析、渲染显示
a. 如果是Gzip包,则先解压为HTML
b. 解析HTML的头部代码,下载头部代码中的样式资源文件或脚本资源文件
c. 解析HTML代码和样式文件代码,构建HTML的DOM树以及与CSS相关的CSSOM树
d. 通过遍历DOM树和CSSOM树,浏览器依次计算每个节点的大小、坐标、颜色等样式,构造渲染树
e. 根据渲染树完成绘制过程
浏览器下载HTML后,首先解析头部代码,进行样式表下载,然后继续向下解析HTML代码,构建DOM树,同时进行样式下载。当DOM树构建完成后,立即开始构造CSSOM树。理想情况下,样式表下载速度够快,DOM树和CSSOM树进入一个并行的过程,当两棵树构建完毕,构建渲染树,然后进行绘制。
Tips:浏览器安全解析策略对解析HTML造成的影响:
- 当解析HTML时遇到内联JS代码,会阻塞DOM树的构建
- 特别悲惨的情况: 当CSS样式文件没有下载完成时,浏览器解析HTML遇到了内联JS代码,此时!!!根据浏览器的安全解析策略,浏览器暂停JS脚本执行,暂停HTML解析。直到CSS文件下载完成,完成CSSOM树构建,重新恢复原来的解析。
一定要合理放置JS代码!!!
白屏-性能优化
1.DNS解析优化
针对DNS Lookup环节,我们可以针对性的进行DNS解析优化。
- DNS缓存优化
- DNS预加载策略
- 稳定可靠的DNS服务器
2.TCP网络链路优化
针对网络链路的优化,好像除了花钱没有什么更好的方式!
3.服务端处理优化
服务端的处理优化,是一个非常庞大的话题,会涉及到如Redis缓存、数据库存储优化或是系统内的各种中间件以及Gzip压缩等…
4.浏览器下载、解析、渲染页面优化
根据浏览器对页面的下载、解析、渲染过程,可以考虑一下的优化处理:
- 尽可能的精简HTML的代码和结构
- 尽可能的优化CSS文件和结构
- 一定要合理的放置JS代码,尽量不要使用内联的JS代码
5.大量图片加载优化
- 优先加载首屏所需图片,完成之后再加载其他部分图片
- 图片裁剪
- 使用更优的图片格式 jpeg ,png ,gif、webp
5.浏览器渲染流程&Composite(渲染层合并)简单总结
浏览器请求、加载、渲染大致过程:
- DNS查询
- TCP连接
- HTTP请求即响应
- 服务器响应
- 浏览器渲染
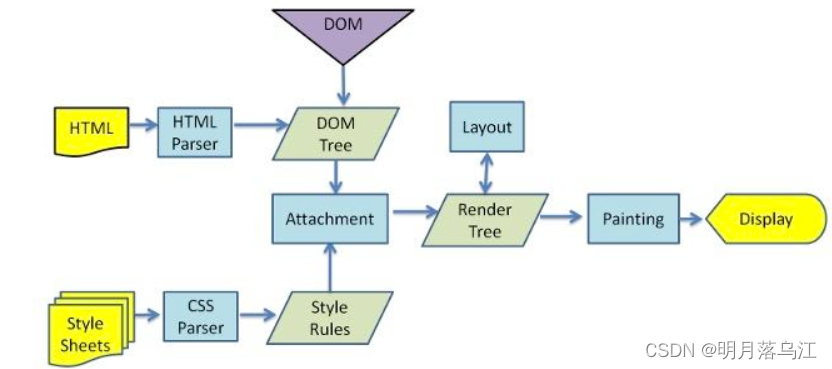
- 浏览器渲染线程接收到请求,加载并渲染网页大致过程
- 解析HTML 建立 DOM tree
- 解析 css 建立 css rules tree
- DOM 和 CSS 合并后生成 render tree
- 布局 render tree ,负责元素尺寸, 位置计算
- 绘制 render tree ,绘制页面像素信息
- 浏览器会将各层的信息发送给GPU(GPU进程:最多一个,用于3D绘制等),GPU会将各层合成(composite),显示在屏幕上
6.前端浏览器动画性能优化
1、精简DOM,合理布局
2、使用transform代替left、top减少使用引起页面重排的属性
3、开启硬件加速
4、尽量避免浏览器创建不必要的图形层
5、尽量减少js动画,如需要,使用对性能友好的requestAnimationFrame
6、使用chrome performance工具调试动画性能
7.什么渐渐式jpg?
在 Web 浏览器中呈现时,会首先给出模糊图像的外观
然后一点一点地开始图片渲染,直到它显示完全渲染的图像
浏览器实际上是逐行解释图像,但在占位符中提供了完整图像的模糊预览
8.怎么在选择图片后,通过浏览器预览待上传的图片?
那么无论哪种方法,首先都得得到文件数据,获得文件数据是从files集合中获取
- 一种是用
window.URL.createObjectURl方法对选择的图片数据(可以勉强理解为input的value)生成一个图片对象路径
function imgChange(img) {
document.querySelector("img").src=window.URL.cteateObejectURL(img.files[0]);
}
- 第二种是使用
FileReader读取器- 创建
FileReader对像; - 调用
readAsDataURL方法读取文件; - 调用
onload事件监听。因为我们需要拿到完整的数据,但我们又不知道文件何时读完,所以需要第三步监听; - 通过
FileReader的result属性拿到读取结果。
- 创建
function imgChange(img) {
// 生成一个文件读取的对象
const reader = new FileReader();
reader.onload = function (ev) {
document.querySelector("img").src = imgFile;
}
//发起异步读取文件请求,读取结果为data:url的字符串形式,
reader.readAsDataURL(img.files[0]);
}
9.怎么实现点击回到顶部的功能?
1.锚点
使用锚点链接是一种简单的返回顶部的功能实现。
该实现主要在页面顶部放置一个指定名称的锚点链接,然后在页面下方放置一个返回到该锚点的链接,用户点击该链接即可返回到该锚点所在的顶部位置。
<body style="height:2000px;">
<div id="topAnchor"></div>
<a href="#topAnchor" style="position:fixed;right:0;bottom:0">回到顶部</a>
</body>
2.scrollTop
scrollTop属性表示被隐藏在内容区域上方的像素数。
元素未滚动时,scrollTop的值为0,如果元素被垂直滚动了,scrollTop的值大于0,且表示元素上方不可见内容的像素宽度
由于scrollTop是可写的,可以利用scrollTop来实现回到顶部的功能
<body style="height:2000px;">
<button id="test" style="position:fixed;right:0;bottom:0">回到顶部</button>
<script>
test.onclick = function(){
document.body.scrollTop = document.documentElement.scrollTop = 0;
}
</script>
</body>
3.scrollTo
scrollTo(x,y)方法滚动当前window中显示的文档,让文档中由坐标x和y指定的点位于显示区域的左上角
设置scrollTo(0,0)可以实现回到顶部的效果
<body style="height:2000px;">
<button id="test" style="position:fixed;right:0;bottom:0">回到顶部</button>
<script>
test.onclick = function(){
scrollTo(0,0);
}
</script>
</body>
4.scrollBy()
scrollBy(x,y)方法滚动当前window中显示的文档,x和y指定滚动的相对量
只要把当前页面的滚动长度作为参数,逆向滚动,则可以实现回到顶部的效果
<body style="height:2000px;">
<button id="test" style="position:fixed;right:0;bottom:0">回到顶部</button>
<script>
test.onclick = function(){
var top = document.body.scrollTop || document.documentElement.scrollTop
scrollBy(0,-top);
}
</script>
</body>
5.scrollIntoView()
Element.scrollIntoView方法滚动当前元素,进入浏览器的可见区域
该方法可以接受一个布尔值作为参数。如果为true,表示元素的顶部与当前区域的可见部分的顶部对齐(前提是当前区域可滚动);如果为false,表示元素的底部与当前区域的可见部分的尾部对齐(前提是当前区域可滚动)。如果没有提供该参数,默认为true
使用该方法的原理与使用锚点的原理类似,在页面最上方设置目标元素,当页面滚动时,目标元素被滚动到页面区域以外,点击回到顶部按钮,使目标元素重新回到原来位置,则达到预期效果
<body style="height:2000px;">
<div id="target"></div>
<button id="test" style="position:fixed;right:0;bottom:0">回到顶部</button>
<script>
test.onclick = function(){
target.scrollIntoView();
}
</script>
</body>
10.SPA应用怎么进行SEO?
SPA全名是Single Page Application,指的是单页面应用。
SEO全称为Search Engine Optimization,指的是搜索引擎优化。
SPA技术将产出html的逻辑从服务器转移到了客户端,在进入React, Vue等UI框架进行开发时,我们开发的页面更多的是在客户端进行脚本执行、数据请求和UI动态装载。
那么搜索引擎爬虫在抓取这样的页面的时,在未做任何优化的情况下,通常拿到的是类似下面的字符文本:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>title</title>
</head>
<body>
<div id="root"></div>
<script src="index.js"></script>
</body>
</html>
除了可以事先定义的title(可能title也不能事先确定),在SPA下很多内容需要通过ajax请求server拿到数据通过脚本执行产生。
通常爬虫不会有类似浏览器的执行环境去产生这些内容。
那么如何让爬虫拿到的数据和用户通过浏览器看到的数据尽量是一致?
SPA的优缺点
优点:用户体验好,前后端代码分离,利于后期的维护
缺点:SEO不好,首次加载时长比较久,导航需要自己去实现前进后退。
SPA如何解决SEO的问题
- SSR 服务端渲染
优点:首屏加载快(因为服务器返回的网页已经包含数据, 所以之下载完JS/CSS就可以直接渲染)。每次请求返回的都是一个独立完成的网页, 更利于SEO。
缺点:就是服务器压力会比较大,对网络要求比较大,
- 预渲染
无需服务器实时动态编译,采用预渲染,在构建时针对特定路由简单的生成静态HTML文件
本质就是客户端渲染, 只不过和SPA不同的是预渲染有多个界面
最大优点: 由于有多个界面, 所以更利于SEO
最大缺点: 首屏加载慢, 预编译会非常的慢
11.Script标签放在header里和放在body底部里有什么区别?
放在 header 中,你能看到 html 第一时间被加载进来,但页面 body 内容迟迟没有渲染出来。因为在等待 header 标签中 script 脚本的加载,3 秒后,整个页面渲染完成。
放在 body 底部,这次 html 内容第一时间渲染完成,随后等待 js 的加载。
脚本会阻塞页面的渲染,所以推荐将其放在 body 底部,因为当解析到 script 标签时,通常页面的大部分内容都已经渲染完成,让用户马上能看到一个非空白页面。
另外你能看到多个脚本之间都是异步向服务器请求,他们之间不互相依赖,最终只等待 3 秒,而非 3+3+3 秒。
12.如何实现SEO优化
内部优化
- 保持站内的更新
- 服务器端渲染
- 内部链接优化
- 优化关键词
外部优化
- 保持链接多样性
- 交换友情链接
- 坚持添加一定数量的外部链接
13.SEO是什么?
Search Engine Optimization
搜索引擎优化
一种利用搜索引擎的搜索规则来提高目前网站在有关搜索引擎内的自然排名的方式
14.SEO的原理是什么?
- 爬行和抓取
- 索引
- 搜索词处理
- 排序
15.前端跨页面通信方法有哪些?
同源策略
通常,对于两个不同页面的脚本,只有具有相同的协议(https),端口豪(433为https的默认值),以及主机时,这两个脚本才能相互通信。
同源页面之间的通信的方法
- BroadCastChannel
- Service Worker
- LocalStorage
- Shared Worker
- IndexedDB
- window.open() + window.opener
非同源页面之间的通信的方法
- jsonp
- window.postmessage()
- iframe
总结
广播模式:
- Broadcast Channe
- Service Worker
- LocalStorage+StorageEvent
共享存储模式:
- Shared Worker
- IndexedDB
- cookie
口口相传模式:
- window.open + window.opener
基于服务端:
- Websocket
- Comet
- SSE
16.DNS预解析是什么?怎么实现?
DNS优化
- 减少DNS请求次数
- 缩短DNS解析时间
dns-prefetch
什么是dns-prefetch?
dns-prefectch(DNS预获取)
提前解析之后可能会用到的域名,使解析结果缓存到系统缓存中,缩短DNS解析时间
为什么要用dns-prefetch?
发送一次请求,就要先通过DNS解析将该域名解析为IP地址,浏览器才能发出请求
如果某一时间内,有多个请求都发送给同一个服务器,那么DNS解析会多次并且重复触发
导致整体的网页加载有延迟
dns-prefetch原理
当浏览器访问一个域名的时候,需要解析一次DNS,获取对应域名的ip地址
解析过程:
- 浏览器缓存
- 系统缓存
- 路由器缓存
- ISP(运营商)DNS缓存
- 根域名服务器
- 顶级域名服务器
- 主域名服务器
的顺序逐步读取缓存,直到拿到IP地址
dns-prefetch就是在将解析后的IP缓存在系统中
这样一来,后续的解析步骤就不用执行了
浏览器DNS缓存与dns-prefetch
现在浏览器为了优化DNS解析,也设有了浏览器DNS缓存
每当在首次DNS解析后会对其IP进行缓存。至于缓存时长,每种浏览器都不一样,比如Chrome的过期时间是1分钟,在这个期限内不会重新请求DNS。
DNS在系统的缓存时间是大于浏览器的。
dns-prefetch缺点
dns-prefetch最大的缺点就是使用它太多。
过多的预获取会导致过量的DNS解析,对网络是一种负担。
注意
dns-prefetch 仅对跨域域上的 DNS查找有效,因此请避免使用它来指向相同域。
这是因为,到浏览器看到提示时,您站点域背后的IP已经被解析。
除了link 还可以通过使用 HTTP链接字段将 dns-prefetch(以及其他资源提示)指定为 HTTP标头:
Link: <https://fonts.gstatic.com/>; rel=dns-prefetch
17.HTML5有哪些drag相关的API?
- dragstart:事件主体是被拖放元素,在开始拖放被拖放元素时触发
- darg:事件主体是被拖放元素,在正在拖放被拖放元素时触发
- dragenter:事件主体是目标元素,在被拖放元素进入某元素时触发
- dragover:事件主体是目标元素,在被拖放在某元素内移动时触发
- dragleave:事件主体是目标元素,在被拖放元素移出目标元素是触发
- drop:事件主体是目标元素,在目标元素完全接受被拖放元素时触发
- dragend:事件主体是被拖放元素,在整个拖放操作结束时触发
18.浏览器乱码的原因是什么?如何解决?
产生乱码的原因:
- 网页源代码是
gbk的编码,而内容中的中文字是utf-8编码的,这样浏览器打开即会出现html乱码,反之也会出现乱码 html网页编码是gbk,而程序从数据库中调出呈现是utf-8编码的内容也会造成编码乱码- 浏览器不能自动检测网页编码,造成网页乱码
解决办法:
- 使用软件编辑HTML网页内容
- 如果网页设置编码是
gbk,而数据库储存数据编码格式是UTF-8,此时需要程序查询数据库数据显示数据前进程序转码 - 如果浏览器浏览时候出现网页乱码,在浏览器中找到转换编码的菜单进行转换
19.Canvas和SVG有什么区别?
**SVG:**在 SVG 中,每个被绘制的图形均被视为对象。如果 SVG 对象的属性发生变化,那么浏览器能够自动重现图形。
其特点如下:
- 不依赖分辨率
- 支持事件处理器
- 最适合带有大型渲染区域的应用程序(比如谷歌地图)
- 复杂度高会减慢渲染速度(任何过度使用 DOM 的应用都不快)
- 不适合游戏应用
Canvas: Canvas是画布,通过Javascript来绘制2D图形,是逐像素进行渲染的。其位置发生改变,就会重新进行绘制。
其特点如下:
- 依赖分辨率
- 不支持事件处理器
- 弱的文本渲染能力
- 能够以 .png 或 .jpg 格式保存结果图像
- 最适合图像密集型的游戏,其中的许多对象会被频繁重绘
20.title与h1的区别,b与strong的区别,i与em的区别?
-
strong标签有语义,是起到加重语气的效果,而b标签是没有的,b标签只是一个简单加粗标签。
b标签之间的字符都设为粗体,strong标签加强字符的语气都是通过粗体来实现的,而搜索引擎更侧重strong标签。
-
title属性没有明确意义只表示是个标题,H1则表示层次明确的标题,对页面信息的抓取有很大的影响
-
i内容展示为斜体,em表示强调的文本
21.浏览器是如何对HTML5的离线存储资源进行管理和加载?
在线的情况下:
浏览器发现 html 头部有 manifest 属性,它会请求 manifest 文件,如果是第一次访问页面 ,那么浏览器就会根据 manifest 文件的内容下载相应的资源并且进行离线存储。
如果已经访问过页面并且资源已经进行离线存储了,那么浏览器就会使用离线的资源加载页面
然后浏览器会对比新的 manifest 文件与旧的 manifest 文件,如果文件没有发生改变,就不做任何操作,如果文件改变了,就会重新下载文件中的资源并进行离线存储。
离线的情况下:
浏览器会直接使用离线存储的资源。
22.HTMl5的离线存储怎么适用,它的工作原理是什么?
离线存储是指:
在用户没有与因特网连接时,可以正常访问站点或应用
在用户与因特网连接时,更新用户机器上的缓存文件
原理:
HTML5的离线存储是基于一个新建的 .appcache 文件的缓存机制(不是存储技术)
通过这个文件上的解析清单离线存储资源,这些资源就会像cookie一样被存储了下来
之后当网络在处于离线状态下时,浏览器会通过被离线存储的数据进行页面展示
后记
后续会继续更新!冲冲✨✨✨
![[LeetCode]1237. 找出给定方程的正整数解](https://img-blog.csdnimg.cn/3a3c37b60d8a4b82bf6d8e537608bc38.png)
![[Android Studio] Android Studio Virtual Device(AVD)虚拟机的功能试用](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)