浏览器工作原理
以打开百度官网为例
在浏览器地址栏输入网址www.baidu.com ,回车 这一过程发生了什么?
首先我们要知道www.baidu.com 这是个域名,需要通过DNS去解析为IP地址(也就是服务器地址),然后返回一个html网页(一般为index.html),最后浏览器会去解析代码
浏览器解析代码的过程遇到css文件,就要去服务器下载,遇到js文件,也是同理,去服务器下载下来,浏览器解析服务器返回的这些网页文件内容,靠的是浏览器内核(或浏览器引擎)(如谷歌引擎:Blink,后面提到的浏览器引擎都统一用谷歌引擎Blink代替)
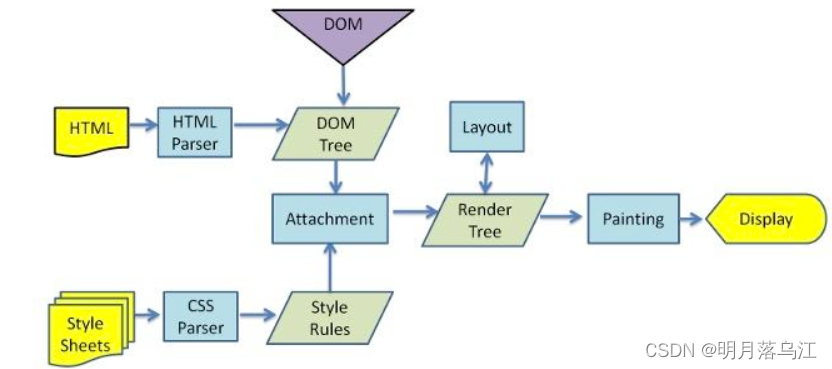
浏览器的渲染过程

HTML文件和CSS文件都会被各自的解析器解析,HTML代码生成DOM树,CSS文件生成Styles Rules,两者结合会生成Render树,结合Layout,painting后就可以在浏览器展示该页面
其中DOM树还会受到js代码的影响,js可以操作DOM
Blink可以解析HTML和CSS文件,但是电脑cpu没办法直接读取js代码,需要JavaScript引擎(如v8引擎)去解析js代码
V8原理(JavaScript代码解析过程)
Blink是浏览器内核,解析html过程中遇到js文件,这时候会以流的方式将js文件交给v8引擎去解析
Parser可以将js代码转化为AST抽象语法树
Ignition是解释器,将AST转化为字节码ByteCode
TurboFan是编译器,可以将字节码转化为cou可以直接执行的机器码,为什么有TurboFan的出现,因为当js代码中有一些函数被反复调用,这种函数我们也叫热点函数,经过TurboFan转化成优化的机器码,可以提高代码的执行性能
提高代码的执行性能**
![[LeetCode]1237. 找出给定方程的正整数解](https://img-blog.csdnimg.cn/3a3c37b60d8a4b82bf6d8e537608bc38.png)
![[Android Studio] Android Studio Virtual Device(AVD)虚拟机的功能试用](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)