文章目录
- 1、前言
- 2、跳表简介
- 3、理解“跳表”
- 4、用跳表查询到底有多快
- 5、跳表是不是很浪费内存
- 6、高效的动态插入和删除
- 7、跳表索引动态更新
- 8、跳表代码实现
1、前言
在开始讲解跳表之前,先来说一说积压结构。
何为积压结构?就是当数据达到了一定程度,会迎来性能瓶颈的时刻,然后再扩容,但是均摊下来的单次代价很低。总结来说就是不会频繁发生变化的结构。
比如ArrayList,有一个初始长度,当长度不够用的时候就达到了性能瓶颈时刻,需要扩容为原长度的2倍,并将原始的数据拷贝到新的空间中,但是它均摊完了是什么性能呢?算算扩容代价,1个数时扩容、2个数时扩容、4个数时扩容,…, N N N个数时扩容,是一个等比数列,所以虽然会迎来一个单点的瓶颈时刻,但是因为是一个等比数列,整体复杂度为 O ( N ) O(N) O(N),则均摊下来就是 O ( N ) / N = O ( 1 ) O(N)/ N = O(1) O(N)/N=O(1)。哈希表同理,均摊下来后的时间复杂度为 O ( 1 ) O(1) O(1)。
SB树以及红黑树都属于积压结构,虽然单点会迎来瓶颈时刻,但是整体会收敛到 O ( l o g N ) O(logN) O(logN) 的水平;但是AVL树不属于积压结构。
AVL树变化特别频繁,这种结构的操作在内存中做很快,但是如果将这种结构写到硬盘上,频繁地读写数据,硬盘的IO瓶颈就很容易达到,因为AVL树很敏感,所以很多硬盘组织的结构不使用它。而234树、B树、B+树和红黑树往往应用在硬盘结构中,是因为它们可以长时间不调整平衡,当它在调整的时候硬盘可能会迎来IO瓶颈,但是只有那么一下,然后又很长时间不变动,因为平衡性模糊。所以这种积压结构往往在硬盘中得到使用。但是随着材料科学的进步,如果硬盘读写速度和计算机的CPU或者内存一样快,那么这些积压结构会走向没落。
2、跳表简介
跳表相对于AVL树、SB树和红黑树来说,思想更加先进,原理更加简单。
首先,明确一点——跳表不是二叉树。
之前学习过二分查找算法,其底层是依赖的数组随机访问特性,所以只能用数组来实现。但是如果数据存储在链表中,就没法使用二分查找算法了吗?
实际上,只需要对链表稍加改造,就可以支持类似“二分”的查找算法。将改造之后的数据结构叫做跳表(Skip list)。
跳表是一种各方面性能都比较优秀的动态数据结构,可以支持快速地插入、删除、查找操作,写起来也不复杂,甚至可以替代红黑树。
3、理解“跳表”
对于一个单链表来说,即使链表中存储的数据是有序的,但是要向在其中查找某个数据,也只能从头到尾遍历链表。查找效率低,时间复杂度
O
(
N
)
O(N)
O(N)。
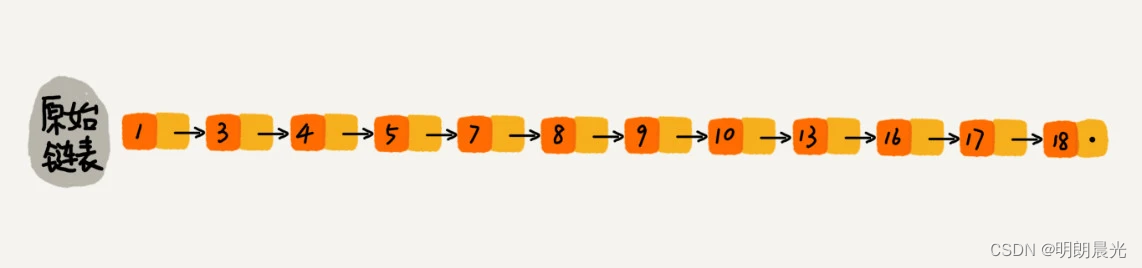
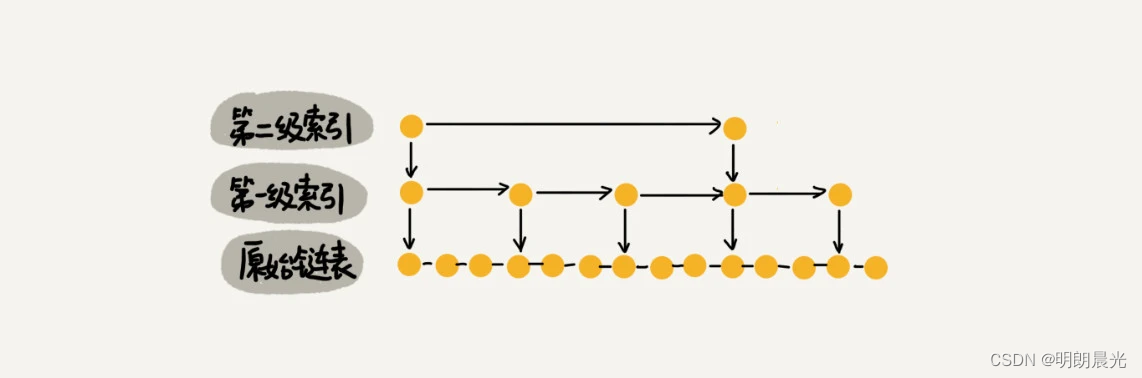
如何提高查找效率呢?如下图所示,对链表建立一级“索引”,查找起来是不是会更快一些呢?每两个结点提取一个结点到上一级,把抽出来的那一级叫做索引或索引层。图中的 down 表示 down指针,指向下一级结点。
假设现在要查找某个结点,如16。
先在索引层遍历,当遍历到索引层中值为13的结点时,发现下一个结点是17,那要查找的结点16肯定就在这两个结点之间。
然后通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。
此时,只需要再遍历2个结点,就可以找到值等于16的这个结点了。如此一来,原先要查找16,需要遍历10个结点,现在只需要遍历7个结点。
从该例可知,加一级索引之后,查找一个结点需要遍历的结点个数少了,即查找效率提高了。 那如果再加一级索引呢?效率是否会提升更多?
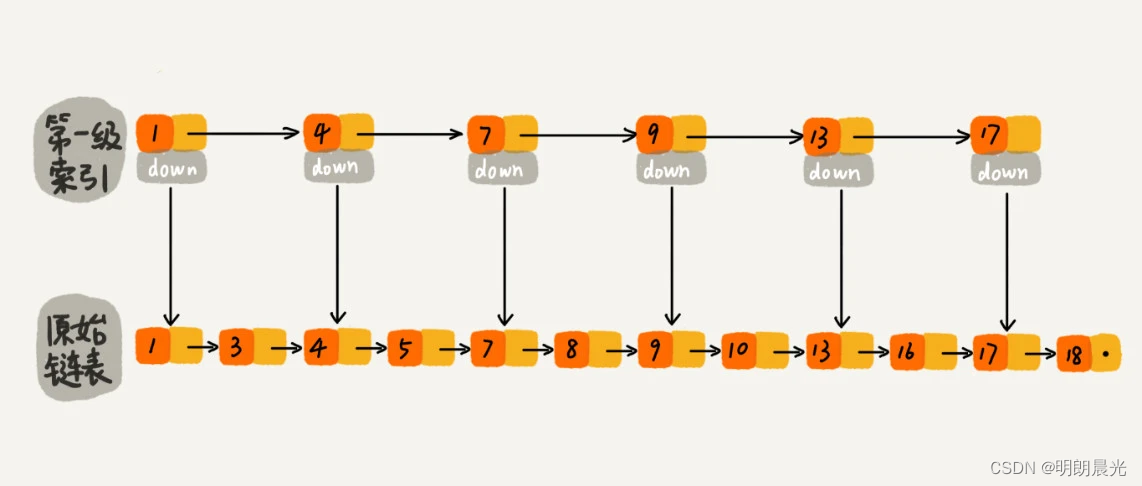
如下图所示,和前面建立索引的方式相似,在第一级索引的基础之上,每两个结点就抽出一个结点到第二级索引。
现在再来查找 16,只需要遍历 6 个结点了,需要遍历的节点数量又减少了。
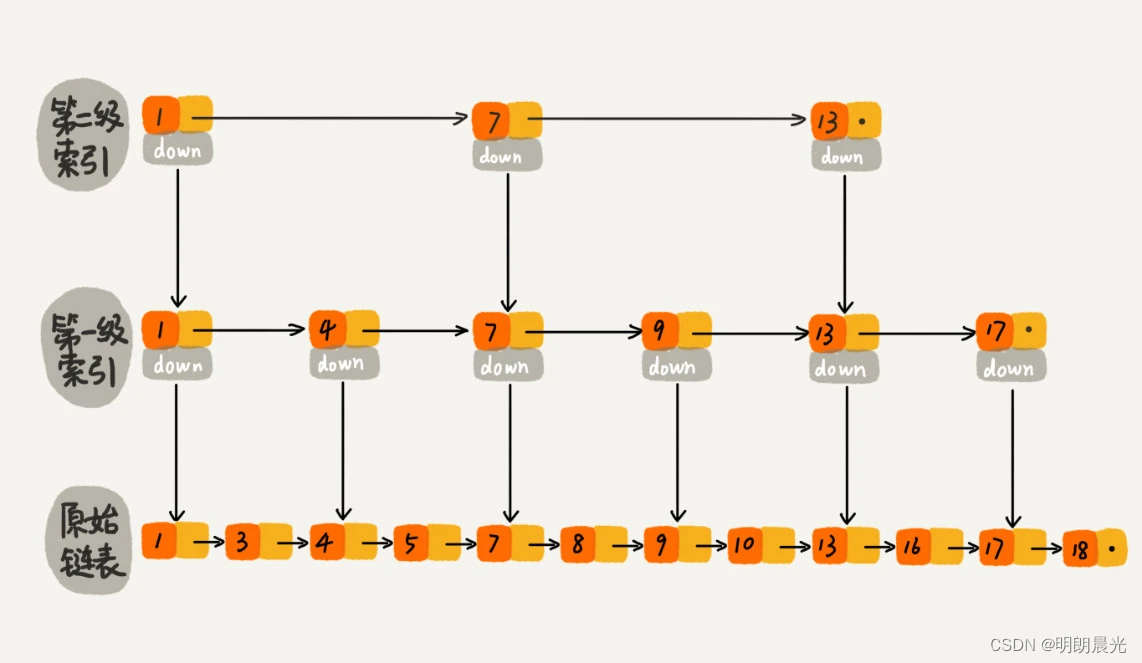
上述的例子数据量不大,所以即便加了两级索引,查找效率的提升也并不明显。为了真切地感受索引提升查询效率,下图画了一个包含 64 个结点的链表,按照上述的思路,建立了五级索引。
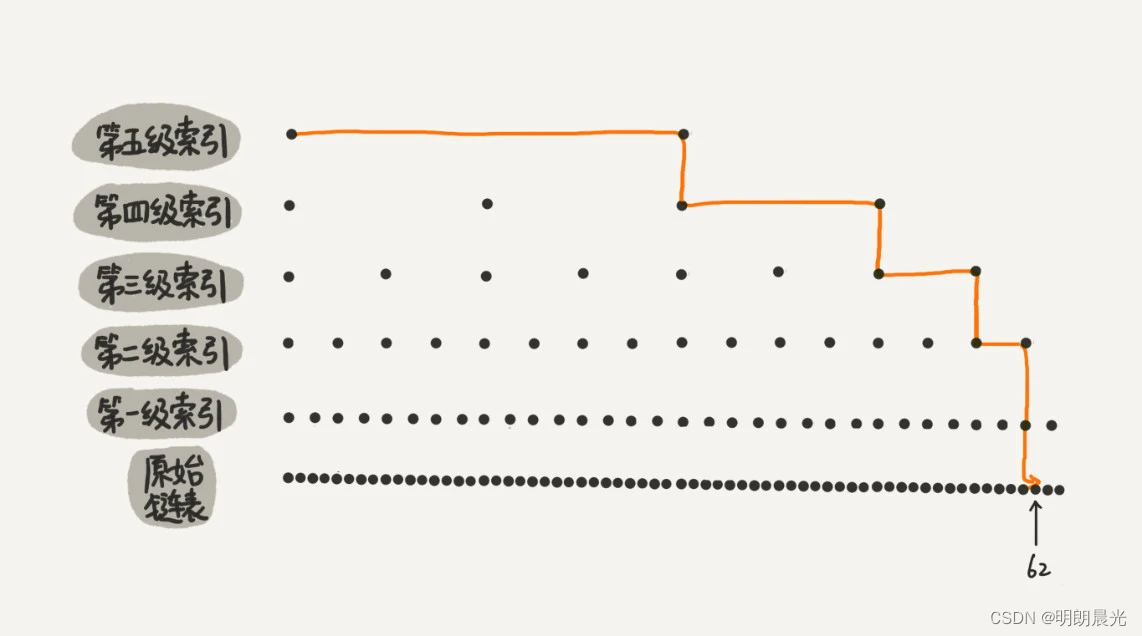
从图中可以看出,没有索引的时候,查找 62 需要遍历 62 个结点,现在只需要遍历 11 个结点,速度提高很多。所以,当链表的长度
n
n
n 较大时,如1000、10000 的时候,在建立索引之后,查找效率的提升就会非常明显。
前面讲的这种链表加多级索引的结构,就是跳表。
4、用跳表查询到底有多快
上述例子可以知道,跳表确实是可以提高查询效率的。接下来,定量地分析一下用跳表查询到底有多快。
在一个单链表中查询某个数据的时间复杂度是 O ( n ) O(n) O(n)。那在一个多级索引的跳表中,查询某个数据的时间复杂度是多少呢?
这个时间复杂度的分析方法比较难想到。将问题分解一下,先来看如果链表里有 n n n 个结点,会有多少级索引呢?
按照前文讲的,每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n / 2 n/2 n/2,第二级索引的结点个数大约就是 n / 4 n/4 n/4,第三级索引的结点个数大约就是 n / 8 n/8 n/8,依次类推,第 k k k 级索引的结点个数是第 k − 1 k-1 k−1 级索引的结点个数的 1 / 2 1/2 1/2,那第 k k k 级索引的节点个数就是 n / ( 2 k ) n/(2^k) n/(2k)。
假设索引有 h h h 级,最高级的索引有 2 个结点。通过上面的公式,可以得到 n / ( 2 h ) = 2 n/(2^h) = 2 n/(2h)=2,求得 h = l o g 2 n − 1 h = log_{2}n - 1 h=log2n−1。如果包含原始链表这一层,整个跳表的高度就是 l o g 2 n log_2n log2n。在跳表中查询某个数据时,如果每一层都要遍历 m m m 个结点,那在跳表中查询一个数据的时间复杂度就是 O ( m × l o g n ) O(m \times logn) O(m×logn)。
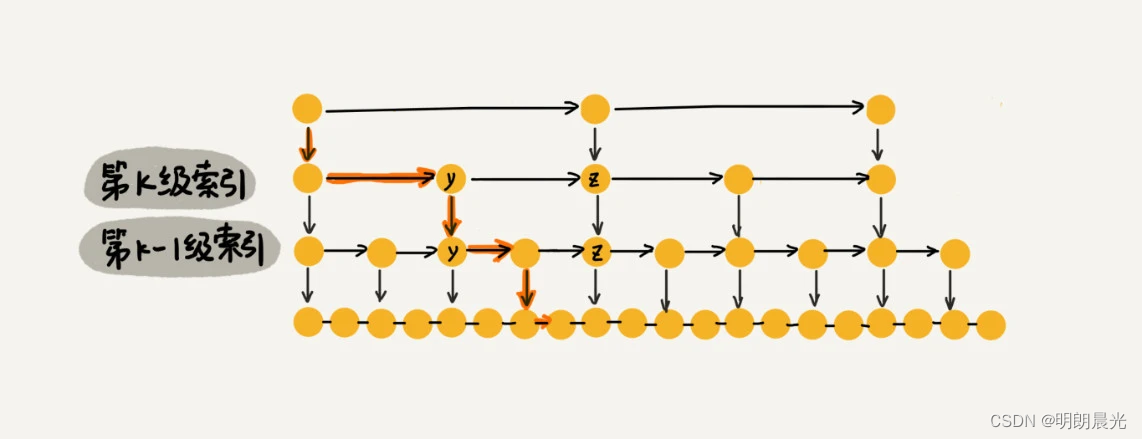
那 m m m 的值是多少呢?按照前面这种索引结构,每一级索引都最多只需要遍历 3 个结点,即 m = 3 m = 3 m=3,为什么是3呢?且看如下解释。
假设要查找的数据是
x
x
x,在第
k
k
k 级索引中,遍历到
y
y
y 结点后,发现
x
>
y
x > y
x>y,小于后面的结点
z
z
z,所以通过
y
y
y 的 down 指针,从第
k
k
k 级索引下降到第
k
−
1
k-1
k−1 级索引。在第
k
−
1
k-1
k−1 级索引中,
y
y
y 和
z
z
z 之间只有 3 个结点(包含
y
y
y 和
z
z
z),所以在
k
−
1
k-1
k−1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点。
通过上述分析,可得
m
=
3
m=3
m=3,所以在跳表中查询任意数据的时间复杂度就是
O
(
l
o
g
n
)
O(logn)
O(logn)。这个查找的时间复杂度跟二分查找一样的。换言之,其实是基于链表实现了二分查找。不过,这种查询效率的提升,前提是建立了很多级索引,也就是空间换时间的设计思路。
5、跳表是不是很浪费内存
比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。接下来分析一下跳表的空间复杂度。
前文讲过,假设原始链表大小为
n
n
n,那第一级索引大约有
n
/
2
n/2
n/2 个结点,第二级索引大约有
n
/
4
n/4
n/4 个结点,以此类推,每上升一级就减少一半,直到剩下两个结点。如果把每层索引的结点数写出来,就是一个等比数列:

这几级索引的结点总和就是
n
/
2
+
n
/
4
+
n
/
8
+
.
.
.
+
8
+
4
+
2
=
n
−
2
n/2 + n/4 + n/8 + ... + 8 + 4 + 2 = n-2
n/2+n/4+n/8+...+8+4+2=n−2。所以跳表的空间复杂度是
O
(
n
)
O(n)
O(n)。即是说,如果将包含
n
n
n 个结点的单链表构成跳表,需要额外再用接近
n
n
n 个结点的存储空间。那是否有办法降低索引占用的内存空间呢?
前文都是每两个结点抽一个结点到上级索引,如果每三个结点或五个结点抽一个结点到上级索引,是不是就不用那么多索引结点了呢?下面是每三个结点抽一个的示意图:
从图中可以看出,第一级索引需要大约 n / 3 n/3 n/3 个结点,第二级 n / 9 n/9 n/9 个结点。每往上一级,索引结点个数都除以 3。为方便计算,假设最高一级的索引结点个数为1。写下每级索引的节点个数,也是一个等比数列:

通过等比数列的求和公式,总的索引结点大约就是
n
/
3
+
n
/
9
+
n
/
27
+
.
.
.
+
9
+
3
+
1
=
n
/
2
n/3 + n/9 + n/27 + ... + 9 + 3 + 1 = n/2
n/3+n/9+n/27+...+9+3+1=n/2。尽管空间复杂度还是
O
(
n
)
O(n)
O(n),但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。
实际上,在软件开发中,不必太在意索引占用的额外空间。实际的软件开发中,原始链表中存储的可能是很大的对象,而索引结点值只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
6、高效的动态插入和删除
跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是 O ( l o g n ) O(logn) O(logn)。
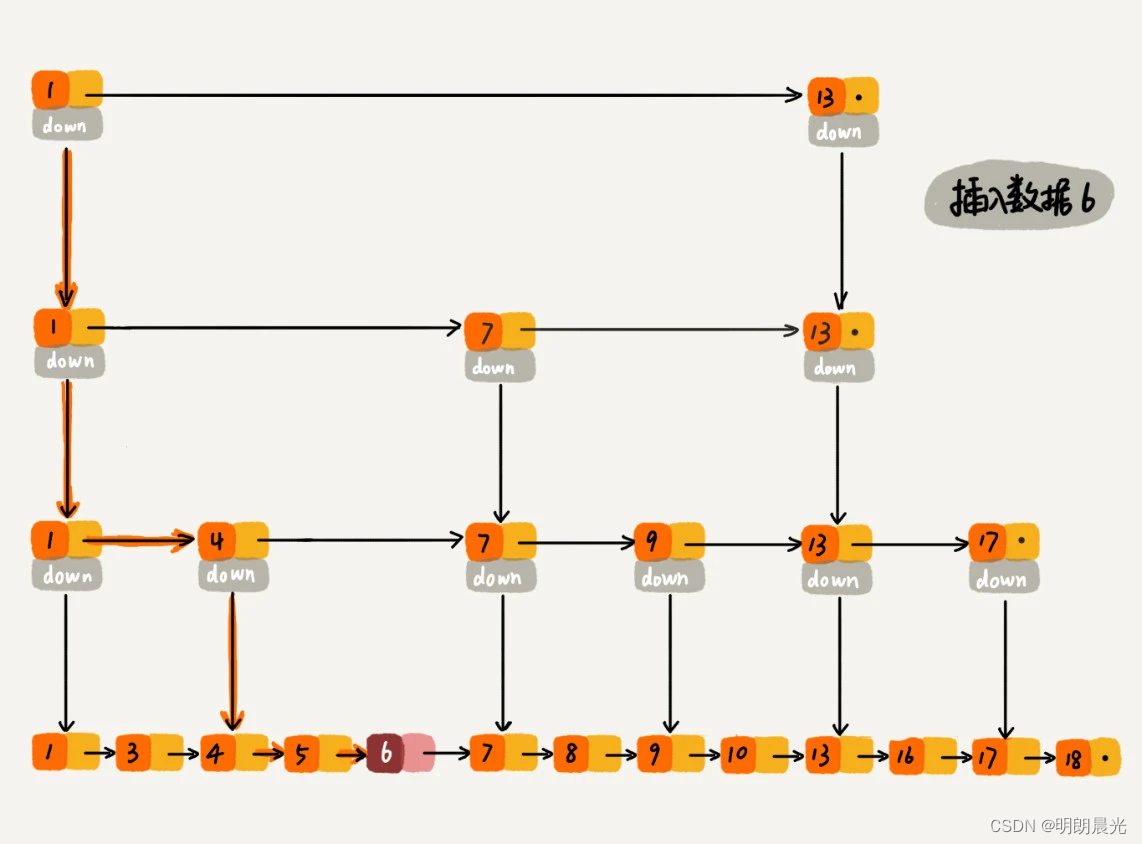
如何在跳表中插入一个数据?以及它是如何做到 O ( l o g n ) O(logn) O(logn) 的时间复杂度的?
已知,在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是 O ( 1 ) O(1) O(1)。但是为了保证原始链表中的有序性,需要先找到要插入的位置,这个查找操作就会比较耗时。
对于纯粹的单链表,需要遍历每个结点来找到插入的位置。但是,对于跳表来说,前文讲过,查找某个结点的时间复杂度是
O
(
l
o
g
n
)
O(logn)
O(logn),所以这里查找某个数据应该插入的位置,方法也是类似的,时间复杂度也是
O
(
l
o
g
n
)
O(logn)
O(logn)。下图可以很清晰地看到插入的过程:
再来看删除操作。
如果这个结点在索引中也有出现,除了要删除原始链表中的结点,还要删除索引中的。因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点。当然,如果使用的是双向链表,就不需要考虑这个问题了。
7、跳表索引动态更新
当不停地往跳表中插入数据时,如果不更新索引,就有可能出现某 2 个索引结点之间数据非常多的情况。极端情况下,跳表还会退化成单链表。
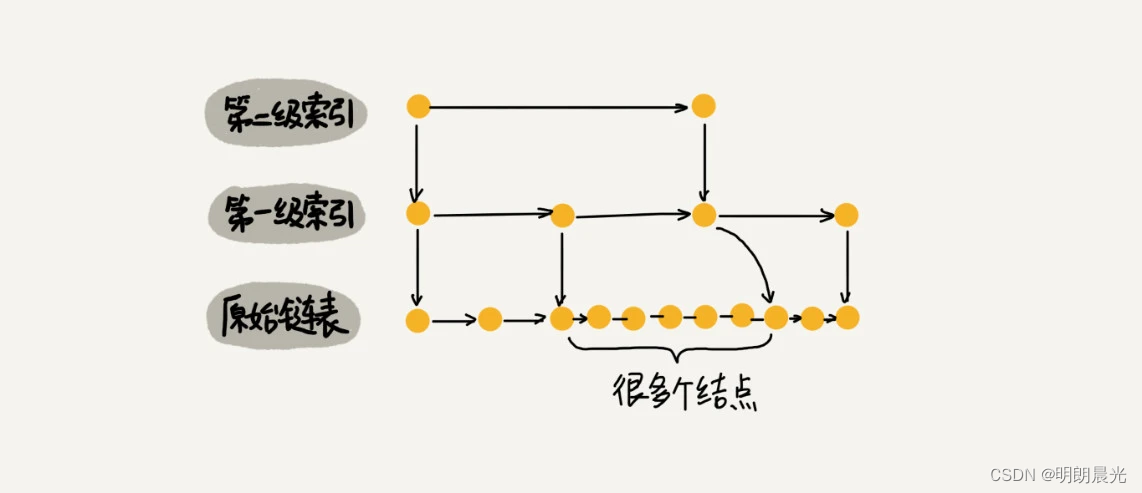
作为一种动态数据结构,需要某种手段来维护索引和原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
AVL树、红黑树这些平衡二叉树是通过左右旋的方式保持左右子树的大小平衡,而跳表是通过随机函数来维护索引和原始链表大小的平衡。
当往跳表中插入数据的时候,可以选择同时将这个数据插入到部分索引层中。如何选择哪些索引层呢?
通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K K K,那就将这个结点添加到第一级到第 K K K 级这 K K K 级索引中。
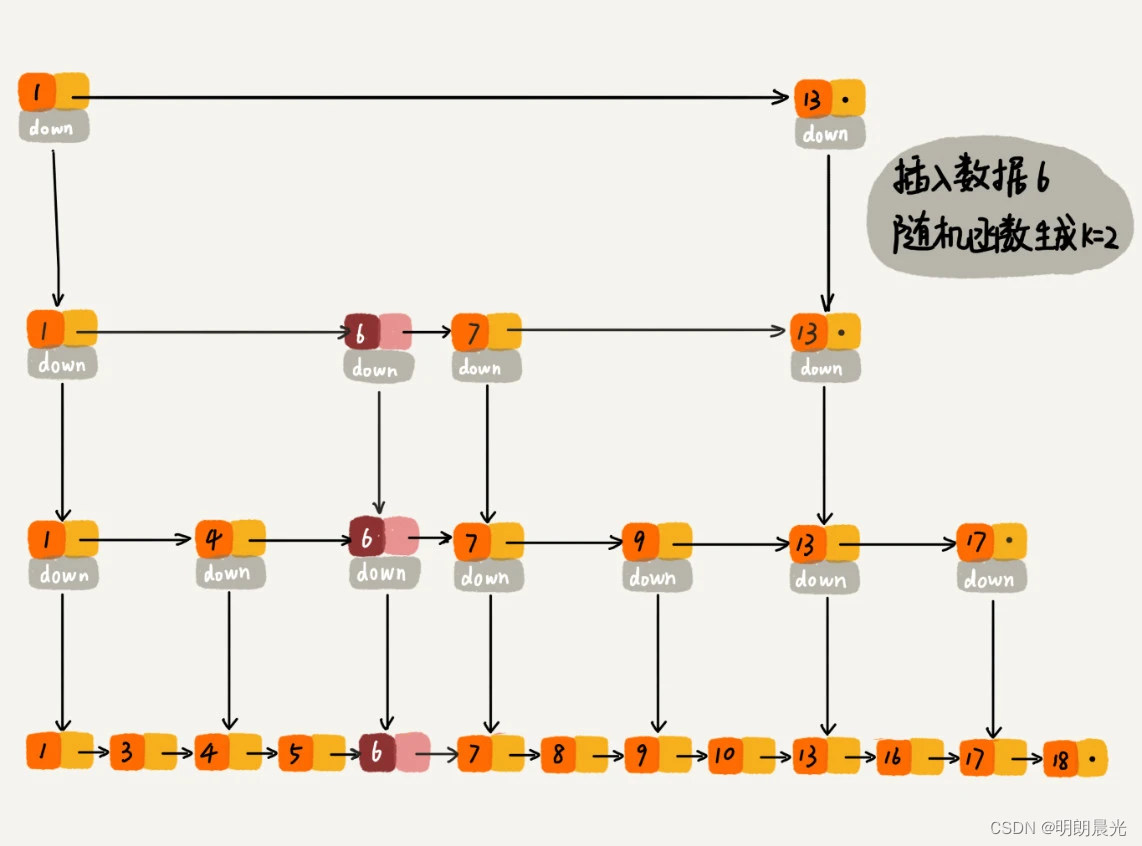
随机函数的选择很有讲究,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化。
8、跳表代码实现
import java.util.ArrayList;
public class SkipListMap {
// 跳表的节点定义
public static class SkipListNode<K extends Comparable<K>, V> {
public K key;
public V val;
public ArrayList<SkipListNode<K, V>> nextNodes; //每个节点都可能有多级索引,需要缓存多条链表
public SkipListNode(K k, V v) {
key = k;
val = v;
nextNodes = new ArrayList<SkipListNode<K, V>>();
}
// 遍历的时候,如果是往右遍历到的null(next == null), 遍历结束
// 头(null), 头节点的null,认为最小
// node -> 头,node(null, "") node.isKeyLess(!null) true
// node里面的key是否比otherKey小,true,不是false
public boolean isKeyLess(K otherKey) {
// otherKey == null -> false
return otherKey != null && (key == null || key.compareTo(otherKey) < 0);
}
public boolean isKeyEqual(K otherKey) {
return (key == null && otherKey == null)
|| (key != null && otherKey != null && key.compareTo(otherKey) == 0);
}
}
public static class SkipListMap<K extends Comparable<K>, V> {
private static final double PROBABILITY = 0.5; // < 0.5 继续做,>=0.5 停
private SkipListNode<K, V> head;
private int size;
private int maxLevel;
public SkipListMap() {
head = new SkipListNode<K, V>(null, null);
head.nextNodes.add(null); // 0
size = 0;
maxLevel = 0;
}
// 从最高层开始,一路找下去,
// 最终,找到第0层的<key的最右的节点
private SkipListNode<K, V> mostRightLessNodeInTree(K key) {
if (key == null) {
return null;
}
int level = maxLevel;
SkipListNode<K, V> cur = head;
while (level >= 0) { // 从上层跳下层
// cur level -> level-1
cur = mostRightLessNodeInLevel(key, cur, level--); //level层中<key
}
return cur;
}
// 在level层里,如何往右移动
// 现在来到的节点是cur,来到了cur的level层,在level层上,找到<key最后一个节点并返回
private SkipListNode<K, V> mostRightLessNodeInLevel(K key,
SkipListNode<K, V> cur,
int level) {
SkipListNode<K, V> next = cur.nextNodes.get(level);
while (next != null && next.isKeyLess(key)) {
cur = next;
next = cur.nextNodes.get(level);
}
return cur;
}
public boolean containsKey(K key) {
if (key == null) {
return false;
}
SkipListNode<K, V> less = mostRightLessNodeInTree(key); //找到第0层<key的最右结点
SkipListNode<K, V> next = less.nextNodes.get(0);//<key的最右节点的下一个节点
return next != null && next.isKeyEqual(key);//该节点如果等于key则说明存在key这个结点,否则不存在
}
// 新增、改value
public void put(K key, V value) {
if (key == null) {
return;
}
// 0层上,最右一个,< key 的Node -> >key
SkipListNode<K, V> less = mostRightLessNodeInTree(key);//先找到第0层上<key的最右侧的node
SkipListNode<K, V> find = less.nextNodes.get(0); //找到第0层上<key的最右侧的node的下一个结点
if (find != null && find.isKeyEqual(key)) { //要添加的key已经存在了,只需要修改值即可
find.val = value;
} else { // find == null 8 7 9
size++;
int newNodeLevel = 0; //新结点一定会拥有第0层(原始链表)
while (Math.random() < PROBABILITY) { //随机函数决定新的结点有几层索引
newNodeLevel++;
}
// newNodeLevel
while (newNodeLevel > maxLevel) { //随机函数得到的索引比头结点的索引值大,则头结点不断加空索引,直到和新结点的索引值一样大的高度,这个加索引的行为只会在头结点发生,其他数据是不会升层的
head.nextNodes.add(null);
maxLevel++;
}
SkipListNode<K, V> newNode = new SkipListNode<K, V>(key, value);
for (int i = 0; i <= newNodeLevel; i++) {
newNode.nextNodes.add(null);
}
int level = maxLevel;
SkipListNode<K, V> pre = head;
while (level >= 0) {
// level 层中,找到最右的 < key 的节点
pre = mostRightLessNodeInLevel(key, pre, level);
if (level <= newNodeLevel) { //只有当前结点的索引级数小于随机函数得到的索引级数时才要进行新结点的添加,其他级数跳过,不需要添加
//插入结点
newNode.nextNodes.set(level, pre.nextNodes.get(level));
pre.nextNodes.set(level, newNode);
}
level--;
}
}
}
public V get(K key) {
if (key == null) {
return null;
}
SkipListNode<K, V> less = mostRightLessNodeInTree(key);
SkipListNode<K, V> next = less.nextNodes.get(0);
return next != null && next.isKeyEqual(key) ? next.val : null;
}
public void remove(K key) {
if (containsKey(key)) { //先检查是否包含key这个结点
size--;
int level = maxLevel;
SkipListNode<K, V> pre = head;
while (level >= 0) {
pre = mostRightLessNodeInLevel(key, pre, level);
SkipListNode<K, V> next = pre.nextNodes.get(level);
// 1)在这一层中,pre下一个就是key
// 2)在这一层中,pre的下一个key是>要删除key
if (next != null && next.isKeyEqual(key)) {
// free delete node memory -> C++
// level : pre -> next(key) -> ...
pre.nextNodes.set(level, next.nextNodes.get(level));
}
// 在level层只有一个节点了,就是默认节点head
// level层在删除结点后除了head节点之外没有其他结点,就要削减这一层
if (level != 0 && pre == head && pre.nextNodes.get(level) == null) {
head.nextNodes.remove(level); //头结点删除这一层
maxLevel--;
}
level--;
}
}
}
public K firstKey() { //原始链表的第1个结点,O(1)复杂度
return head.nextNodes.get(0) != null ? head.nextNodes.get(0).key : null;
}
public K lastKey() { //从最高层索引开始,找每层索引的最后一个节点,一直到第0层的最后一个,O(logn)复杂度
int level = maxLevel;
SkipListNode<K, V> cur = head;
while (level >= 0) {
SkipListNode<K, V> next = cur.nextNodes.get(level);
while (next != null) {
cur = next;
next = cur.nextNodes.get(level);
}
level--;
}
return cur.key;
}
public K ceilingKey(K key) {
if (key == null) {
return null;
}
SkipListNode<K, V> less = mostRightLessNodeInTree(key);
SkipListNode<K, V> next = less.nextNodes.get(0);
return next != null ? next.key : null;
}
public K floorKey(K key) {
if (key == null) {
return null;
}
SkipListNode<K, V> less = mostRightLessNodeInTree(key);
SkipListNode<K, V> next = less.nextNodes.get(0);
return next != null && next.isKeyEqual(key) ? next.key : less.key;
}
public int size() {
return size;
}
}
// for test
public static void printAll(SkipListMap<String, String> obj) {
for (int i = obj.maxLevel; i >= 0; i--) {
System.out.print("Level " + i + " : ");
SkipListNode<String, String> cur = obj.head;
while (cur.nextNodes.get(i) != null) {
SkipListNode<String, String> next = cur.nextNodes.get(i);
System.out.print("(" + next.key + " , " + next.val + ") ");
cur = next;
}
System.out.println();
}
}
public static void main(String[] args) {
SkipListMap<String, String> test = new SkipListMap<>();
printAll(test);
System.out.println("======================");
test.put("A", "10");
printAll(test);
System.out.println("======================");
test.remove("A");
printAll(test);
System.out.println("======================");
test.put("E", "E");
test.put("B", "B");
test.put("A", "A");
test.put("F", "F");
test.put("C", "C");
test.put("D", "D");
printAll(test);
System.out.println("======================");
System.out.println(test.containsKey("B"));
System.out.println(test.containsKey("Z"));
System.out.println(test.firstKey());
System.out.println(test.lastKey());
System.out.println(test.floorKey("D"));
System.out.println(test.ceilingKey("D"));
System.out.println("======================");
test.remove("D");
printAll(test);
System.out.println("======================");
System.out.println(test.floorKey("D"));
System.out.println(test.ceilingKey("D"));
}
}
简单版本:
package skiplist;
/**
* 跳表的一种实现方法。
* 跳表中存储的是正整数,并且存储的是不重复的。
*
* Author:ZHENG
*/
public class SkipList {
private static final float SKIPLIST_P = 0.5f;
private static final int MAX_LEVEL = 16;
private int levelCount = 1;
private Node head = new Node(); // 带头链表
public Node find(int value) {
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
return p.forwards[0];
} else {
return null;
}
}
public void insert(int value) {
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
Node update[] = new Node[level];
for (int i = 0; i < level; ++i) {
update[i] = head;
}
// record every level largest value which smaller than insert value in update[]
Node p = head;
for (int i = level - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;// use update save node in search path
}
// in search path node next node become new node forwords(next)
for (int i = 0; i < level; ++i) {
newNode.forwards[i] = update[i].forwards[i];
update[i].forwards[i] = newNode;
}
// update node hight
if (levelCount < level) levelCount = level;
}
public void delete(int value) {
Node[] update = new Node[levelCount];
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; --i) {
if (update[i].forwards[i] != null && update[i].forwards[i].data == value) {
update[i].forwards[i] = update[i].forwards[i].forwards[i];
}
}
}
while (levelCount>1&&head.forwards[levelCount]==null){
levelCount--;
}
}
// 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
// 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。
// 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
// 50%的概率返回 1
// 25%的概率返回 2
// 12.5%的概率返回 3 ...
private int randomLevel() {
int level = 1;
while (Math.random() < SKIPLIST_P && level < MAX_LEVEL)
level += 1;
return level;
}
public void printAll() {
Node p = head;
while (p.forwards[0] != null) {
System.out.print(p.forwards[0] + " ");
p = p.forwards[0];
}
System.out.println();
}
public class Node {
private int data = -1;
private Node forwards[] = new Node[MAX_LEVEL];
private int maxLevel = 0;
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("{ data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}
}