工作原因要对一个 newreno 实现增加 sack 支持。尝试写了 3 天 C++,同时一遍又一遍梳理 sack 标准演进。这些东西我早就了解,但涉及落地写实现,就得不断抠细节,试图写一个完备的实现。
这事有更简单的方法。根本没必要完全实现 RFC,目标是高吞吐,而不是实现标准 TCP,因此只要保证最宽容的可用性,剩下的交给现实。我们做 cc 时,为提高性能,何尝不是这里 cwnd += 10,那边 cwnd += whatever(sk),异曲同工。
前面两周写了一些关于 TCP 演进的文字,无论怎样,这是个好机会以一个实例来展示演进过程中的方法论。捕捉其中关于 sack 的两个细节,降窗和重传,再写一些文字。
TCP 丢包后进入 fast retransmit/recovery 后涉及如何降窗和如何重传两件事,TCP 经过 40 多年的演化,关于这两件事铸建了 4 个里程碑。
最初的 TCP 只有 rto,没有 fast retransmit,此即 TCP tahoe,只要有丢包,即将 cwnd = 1,重新开始慢启动。第 1 个里程碑是 TCP reno 和 TCP newreno,二者一脉相承。
reno 引入了 fast retransmit,但有很多问题,newreno 解决了这些问题。这部分参见 Wiki。seastar 只实现了 RFC6582 定义的 newreno,非常原始,但基本上这就是一个最小能用的 TCP 实现。
从第 2 个里程碑开始,TCP 开始起飞。我的工作也就是尽量追着这个尾迹跟着飞,在必要时加入一些自己的 trick,或觉得标准实现太麻烦时偷一下懒裁剪掉些东西。
引入 fast retransmit 时 TCP 还不支持 sack,收到 3 个 dupack 即进入 fast retransmit/fast recovery,但只留下一个未被 ack 的 hole,hole 后面的情况什么也看不到,没有任何启发式手段让 sender 猜测哪些 seg 丢了。
降窗如 范雅各布森 所述,直接将 cwnd = ssthresh = cwnd / 2。RFC5681 不允许超过一半的 seg 在途(这似乎是在迎合或确认 ssthresh = cwnd/2 这件事,详见:雅各布森管道):
until all lost segments in the window of data in question are repaired, the number of segments transmitted in each RTT MUST be no more than half the number of outstanding segments when the loss was detected.
这显然降低了带宽利用率,但这时没有任何信息指示如何做得更好(每发送一个 seg 只能至多带回 1 个 ack),解决这个问题的条件尚未具备。
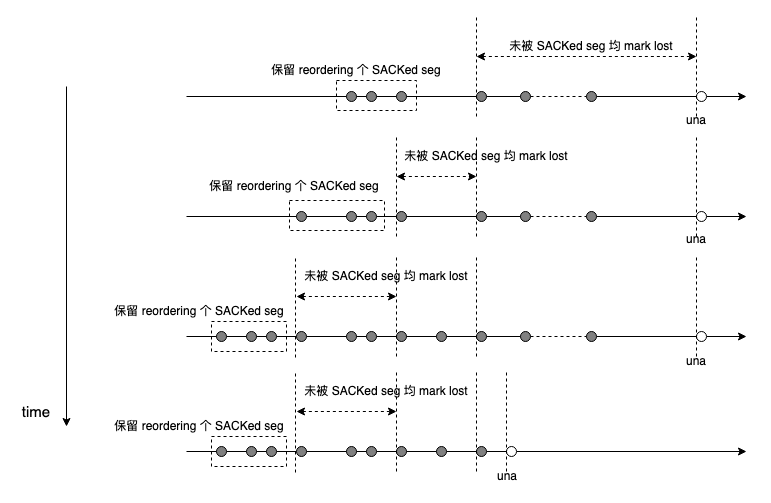
关于重传,除了一个 hole 没有任何辅助信息,只能从 una 开始每次重传 1 个往前挪 nua,没有任何别的办法。如下图所示,整个图景相当于一个 seq space 构成的一维世界,一 hole 以障目:
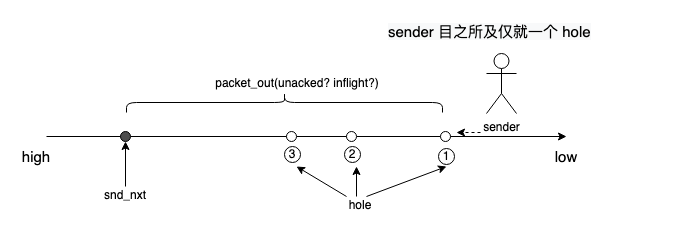
随着 sack 被引入,降窗和重传逻辑均起了大变化。我们关注的是这个变化是如何如丝般顺滑而一气呵成的,以便这个方法论能指示 TCP(or any others) 未来的演化方向。
第 3 个里程碑来自 sack 被引入后。详见 RFC6675。 sack 反馈了更加丰富的信息,sender 有了绕到 hole 后面查看究竟的途径,这相当于引入了额外的维度,将 seq space 直立了起来,仰起头就能看到 seq space 的细节:
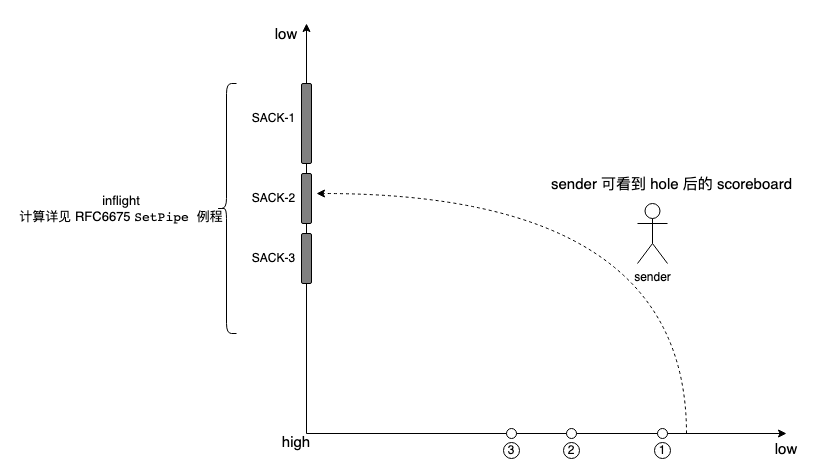
TCP 将 seq space 抽象成一个 scoreboard,该 scoreboard 上对 seq space 的每一个 seg 区分对待,可 mark sacked,mark lost,mark reordering,针对 lost seg 进行重传并 mark retrans,inflight 从而可精确获取:
inflight = snd_nxt - snd_una + snd_retrans - snd_lost - snd_sacked
基于守恒律,于是 cwnd = inflight 更加精确。
二维世界丰富的多的信息指示 sender 做出更好的决策,不再每次 retransmit 一个 seg,TCP 重传算法第一次统一处理重传 seg 以及新 seg,它们统一受 cwnd 限制:cwnd - inflight > 0。
重传逻辑将 seg 分三个优先级,mark lost 的 seg 被优先传输,因为它们最容易补 hole 而推进 una,新 seg 第二优先,它们可能带回新的 sack,推进 mark lost,背后的考虑是尽量延后 mark lost,而剩余的最后重传:
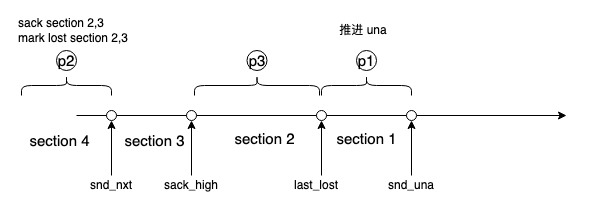
下面再看降窗逻辑。
重传 seg 和新 seg 在 fast retransmit/recovery 状态被统一安排,一个 seg 带回的 sack 可导致大量 mark lost,参考前面 inflight 公式,大量 seg 由于 mark lost 被清出 pipe,inflight 急剧减少而腾出大量 pipe 空间。cwnd 一定时,后果便是 burst(可 burst 一个 cwnd = ssthresh 的数据)。而 burst 会加剧网络拥塞而丢包,形成正反馈。
TCP 第一次以 ack 携带信息(sack)而非 ack 本身来计数,引入了 scoreboard 细化了 seq space,但处理降窗的方式却没有同步跟进处理这个 burst 问题。
有两个更平滑降窗的方案,第一个是 Linux TCP 的 rate-halving 算法。rate-halving 思路很简单,不再一下子将 cwnd 折半,而是每收到 2 个 ack 将 cwnd 减 1,这样收到一个 cwnd 的 ack 后,cwnd 即原来的一半了。
但彼时 cc 已模块化,丢包降窗的目标可自定义,比如 cubic 将 cwnd 降为 0.7*cwnd,而 rate-halving 写死了比例 0.5,且未考虑 sack 计数而精度不够(sack 大大提高了判断精度,rate-halving 却没有利用任何 inflight 信息)。 后来 Google 提出了 prr 算法,将 cwnd 精确平滑收敛到 ssthresh = (1 - beta)*cwnd。
思路和 rate-halving 类似,只是 prr 基于 scoreboard 精确计算 fast retransmit/recovery 期间被 ack/sack 的数据 prr_delivered 和实际发送的数据 prr_out 以获得收益。按照正常的 seg 守恒律:
cnt = prr_delivered - prr_out
结果应为 0,意思是 prr_delivered 被确认之后才能兑换等量的 prr_out 而发出,按比例缩放这个守恒律即可:
cnt = (1 - beta)*prr_delivered - prr_out
以 beta = 0.3 为例,意思是 0.7 个单位的 prr_delivered 被确认后兑换 一个单位的 prr_out,为了满足守恒律使结果为 0,prr_out 也要进行 0.7 缩放,因此必须从 cwnd 中扣除这个差异:
cwnd = inflight - |cnt|
由此在一个 rtt 内,sender 缓慢地,平滑地,等比例地将 cwnd 降到 (1-beta)*cwnd。
…
降窗逻辑看起来很 perfect。
让我们回看引入 sack 后的第 3 个里程碑的重传逻辑,看它有什么问题不能解决,并且该问题还必须被解决。
随着带宽资源的增加,传输协议对带宽利用率有所期待,而不再仅仅满足于保证可用性的 AIMD 算法。需实时测量的 rate-based cc 在这个背景下被设计。
与 cwnd-based cc(cwnd 配额用尽即不可再发送) 不同,实时测量考虑 delivery rate 反馈而非仅仅 ack 时钟,需要 sender 有持续数据流可发送,即使 rwnd 憋死(矢量滑动 rwnd 导致,我对此有单边解法),在收不到重传 seg 的 sack 后,要再次重传该 seg(这在某种意义上确实可以取消 rto 了,但这是后话)。
RFC6675 标准 sack 重传机制涉及两个细节,一个是 reordering 更新,一个是依赖前者的 mark lost,先看 reordering 更新:
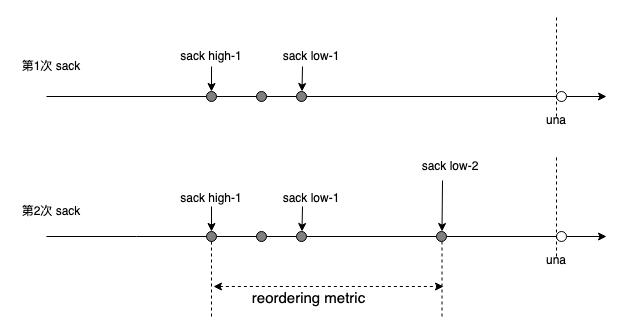
reordering 根据 sack 的布局和批次不断被更新,关于 reordering 的细节,详见早期的一篇分析:TCP 的乱序&丢包判断。
基于此,再看 mark lost:
这两个机制揉在一起非常复杂。
RFC6675 的算法显然无法满足多次重传相同 seg,因为 sender 的 scoreboard 没有信息区分多次 mark lost 被重传的 seg,这就无法在 mark lost 和 mark reordering 之间做判断:

每个 seg 只能 mark lost 一次,如果重传丢了,只能 rto。
第 4 个里程碑就来了。
在 sack 引入的额外维度后,一维 seq space 展成了二维,sender 可以从额外的维度绕过 hole 看到信息量更大的 scoreboard。寻着同样的思路,再加一个维度,为传输加上时间轴,这就是 rack:
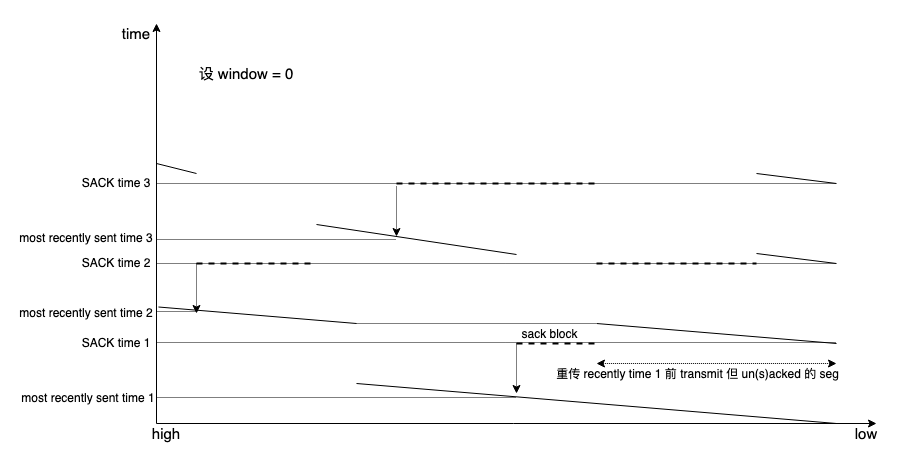
两根坐标轴就搞定了所有事情,不再需要额外的两个过程,虽然也依然会有由于 reordering 对 rack window 所做的调整,但相比更新 reordering 值本身的逻辑就太简单和直观了。
看一下清爽的 rack 全景:

sender 维护一个统一安排 mark lost 重传 seg 和新 seg 的按发送时间 fifo 队列。每一个 hole 只要在一定时间(比它后发送的都被 ack/sack,而它在此一定时间后仍是 hole)内没被 ack/sack 可以重新被 mark lost,与其是否被重传过以及重传过几次无关。每次传输都会将时间戳打入,以区别传输轮次。
就这样,rack 引入一个时间序解决了 reordering 和 mark lost 歧义的问题。
rack 靠时间驱动,即时间序,而此前的方法则是在 seq space 上根据字节序关系靠启发(且看 Linux TCP 的 update scoreboard)驱动,再往前,则连启发都没得启发了,因为根本没信息。过程的发展非常柔滑,值得再次总结。
一维世界,一个 hole 就堵住了,sack 相当于二维平面,sender 可绕到 hole 后看情况,顺着往后,用时间编码发送顺序,就是 rack,sender 在一个三维看板看到的信息更详细,从而可做出更精确合理的判断。
接下来的事情尚未发生(或者发生了一点点),但按照上面的推理逻辑,它应该会发送。
rack 就像一架引擎,只要 ack 时钟不断,在丢包时亦始终有 seg 被发送,这些 seg 将带回驱动引擎的进一步的 ack 流,该策略非常适合高速网络,发送引擎不再区分 seg 类型,与 scoreboard 解耦,rack 将代替任何基于重复 ack/sack 的启发算法 mark lost,发送引擎维持高速运转,源源不断提供数据用于实时测量。
BBR 即使用 rack 作为自己的丢包探测驱动。
随着带宽资源进一步丰富,类似 BBR 的算法未竞全功。由于 TCP 没有打包直接传输 seq space 字节流,导致无边界确认处理非常复杂,由此带来了 undo 歧义和 ack 歧义问题,不必要重传,不准确的 rtt 测量和 delivery rate/cwnd 计算都是其影响。这些复杂且不精确的处理是高带宽利用率的绊脚石。
问题根源在于,正向传输的 seg 是 seq space 的矢量字节流,而 ack/sack 指导 cwnd 更新的只有标量 account,丢失了 seg 传输顺序。换句话说,sender 发送的 seg 是按序的,而 sender 接收到的 ack/sack 却没有信息可还原对应 seg 的顺序。
按以往惯例,既然 rack 已将时间序编码到了 sender 本地,只需将该时间序同时编码到 seg 本身,这样 seg 将引导 ack 反馈更丰富的 receiver 端信息,该信息与 sender 的本地传输时间序进行比对,就什么都有了。过年期间,我曾想了一个方法,详见:重新设计 TCP。下面是对该文字的一点前置分析。
如果 seg 携带 1 bit 额外信息,就能区分一次重传和原始 seg,携带 2 bit 能区分 3 次重传和原始 seg,以此类推,携带 32 bit 能区分 4G 次传输(1 次原始 seg 和 4G-1 次重传),为将每次传输识别为一个不允许切割的整体,需将 seq space 的字节流按序打包进固定长度的 packet,以 packet 为单位传输并针对 packet 确认,为每一个 packet 打标递增的 packet id 作为序列号。
这想法是个自然而然的过程。逻辑反而更简单明,加入一个 packet id 便清除了启发式判断。
可 TCP 没地方编码 packet id 了,况且 TCP 的标准处理流程无法要求不切割,打包过程很难合并入 TCP。但 QUIC 接力了。虽然 QUIC 未必是 TCP 后继,但它在 sack,rack,重传等方面的处理方式,正是针对 TCP 的 bugfix,整个过程一脉相承,可理解。
后面的路怎么走我不知道,也不预测,但俯拾皆是的肯定依然一地鸡毛,而且如果它确实发生了,将它与前面的事情连起来,必将在同一条线上。
浙江温州皮鞋湿,下雨进水不会胖。



![[软件工程导论(第六版)]第1章 软件工程学概述(课后习题详解)](https://img-blog.csdnimg.cn/3b33be679f08482a87e40435212264e7.png)