本期主题:
python的pandas使用
往期链接:
- python实用脚本(一)—— 批量修改目标文件夹下的文件名
- python实用脚本(二)—— 使用xlrd读取excel
- python实用脚本(三)—— 通过有道智云API实现翻译
- python实用脚本(四)—— 正则表达式
- python实用脚本(五)——numpy的使用
文章目录
- 1.pandas是什么
- 2.Series实例
- 3.DataFrame实例
- 3.pandas使用csv
- 1.使用 to_csv() 将DataFrame存储为csv
- 2.使用 read_csv读
1.pandas是什么
pandas是python data analyze libray,是一个基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。
pandas主要有两种数据结构:
- Series(一维数据),类似于一维数组的对象,由一组数据和一组与之相关的索引构成;
- DataFrame(二维数据),表格型的数据结构,由行数据和列数据构成;
2.Series实例
Series类似于表格中的一列,可以保存任何数据类型
Series 由索引(index)和列元素组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
其中:
- data:代表一组数据
- index:数据索引标签,不指定则默认从0开始计数
- dtype:数据类型,默认自己判断
- name:设置这个series的name
- copy:是否进行数据拷贝,默认为False
看一个实际例子:

3.DataFrame实例
DataFrame是一个表格型的数据结构,每一列可以有不同的值类型,每一列可以认为是 series.
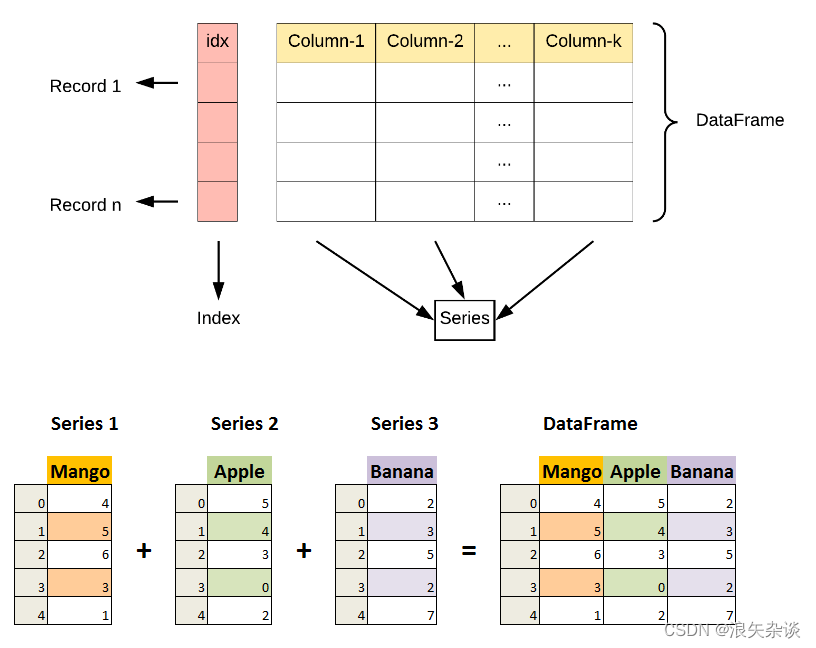
使用list创建DataFrame
>>> data = [['Google',10],['Runoob',12],['Wiki',13]]
>>>
>>> df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
<stdin>:1: FutureWarning: Could not cast to float64, falling back to object. This behavior is deprecated. In a future version, when a dtype is passed to 'DataFrame', either all columns will be cast to that dtype, or a TypeError will be raised.
>>>
>>> print(df)
Site Age
0 Google 10.0
1 Runoob 12.0
2 Wiki 13.0
3.pandas使用csv
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
1.使用 to_csv() 将DataFrame存储为csv
import numpy as np
import pandas as pd
# name
name = ['xiaoming', 'xiaohong', 'xiaolv']
# age
age = [10, 12, 13]
dict = {
'name' : name,
'age' : age
}
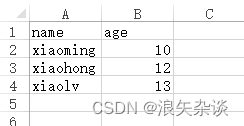
df = pd.DataFrame(dict)
df.to_csv('test.csv', index=False) #index=False就是不要最前面的那个索引
结果:
2.使用 read_csv读
df = pd.read_csv('test.csv')
print(df.to_string())
测试结果:
python .\pandas_test.py
name age
0 xiaoming 10
1 xiaohong 12
2 xiaolv 13