目录
前言
一、题目理解
背景
解析
字段含义:
建模要求
二、建模思路
灰色预测:
编辑
二次指数平滑法:
person相关性
只希望各位以后遇到建模比赛可以艾特认识一下我,我可以提供免费的思路和部分源码,以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路,你们的关注和点赞就是我写作的动力!!!想要了解更多的欢迎联系博主,免费获取代码和更多细化思路。
前言
美赛补全计划第二篇了属实是,正好今天是周五下班晚上通宵研究美滋滋,想当年上一次参加美赛的时候还有两个学妹在给我加油打劲,现在已经孤身一人社畜995,时光一去不复返啊。(要是有学妹给我评论加油,我直接状态拉满哈哈)
对美赛A题感兴趣的同学去看:2023年美国大学生数学建模A题:受干旱影响的植物群落建模详解+模型代码(一)
还是老样子,思路和模型代码都是免费的,纯爱好。博主参与过十余次数学建模大赛,三次美赛获得过二次M奖一次H奖,国赛二等奖。建模的部分后续将会写出,想要了解更多的欢迎联系博主,免费获取代码和更多细化思路,只希望各位以后遇到建模比赛可以艾特认识一下我,我可以提供免费的思路和部分源码,以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路,你们的关注和点赞就是我写作的动力!!!大家可以参考。
一、题目理解
首先做MCM要从背景入手了解要做的事情,题目背景:
背景
Wordle是《纽约时报》目前每天提供的一个流行的谜题。玩家试图通过不超过六次的时间猜 测一个五个字母的单词来解决谜题,每次猜测都会得到反馈。对于这个版本,每个猜测都必 须是一个真实的英语单词。不允许猜测不被比赛认定为单词的结果。
《纽约时报》网站上的Wordle说明指出,在你提交文字后,瓷砖的颜色将会改变。黄色 平贴表示该贴中的字母在单词中,但它在错误的位置。绿色的贴表示该贴中的字母在单 词中并且在正确的位置。
图1是一个示例解决方案,在三次尝试中都找到了正确的结果。

玩家可以在常规模式或困难模式下玩。Wordle的困难模式让玩家的游戏更加困难,因为 一旦玩家找到了一个单词中正确的字母 (平铺是黄色或绿色的) ,这些字母必须在随后 的猜测中使用。
解析
首先我们可以得到该游戏的基本规则,也就是能够在26个字母之类,挑选出五个字母。困难模式下,如果第一次猜中了某个字母,该字母是绿的话那么不用挪动,若该字母为黄的,那么接下来五个位置中必定得填上该字母,当然字母和单词之间也有一定的逻辑关系。那么我们再去看数据集和数据集的解释:

字段含义:
Data:日期
Contest number:比赛编号
Word:比赛单词
Number of reported results:提交人数
Number in hard mode:hrad模型下提交人数
提交次数:
| Percent in | ||||||
| 1 try | 2 tries | 3 tries | 4 tries | 5 tries | 6 tries | 7 or more tries (X) |
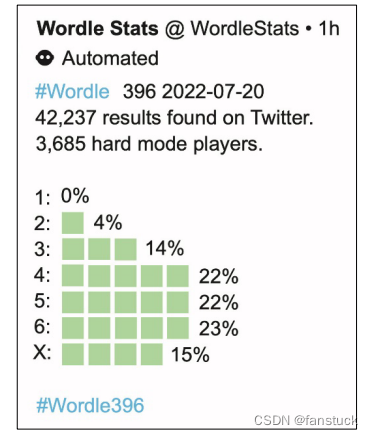
由于每天的单词是固定的,根据题意说例如,在图2中,2022年7月20日的单词是“TRITE”,结果是通过挖掘Twitter获得。尽管图2中的百分比总和为100%,但在某些情况下由于四舍五入,这可能不是真的。上一句信息不重要,可能就是解释一下为什么概率是整数而已。
建模要求
- 1.报告结果的数量每天都在变化。建立一个模型来解释这种变化,使用该模型能为2023年3月1日报告的结果数量创建一个预测概率区间序列,单词的任何属性是否会影响在hard模式下游戏人数?解释这种情况。
- 2.对于给定的未来解决方案,在未来的某个日期,开发一个模型预测报告结果的分布。换句话说,预测未来日期的百分比(1、2、3、4、5、6、X)。挖掘出模型的预测结果到底存在哪些影响预测准确性的因素,举一个你对这个词的预测的具体例子‘EERIE’于2023年3月1日发布。去校验模型的准确性。
- 3.开发和总结一个模型,按难度分类解决方案词,并识别与每个分类关联的给定单词 的属性。基于你的模型,ERNIE这个词有多难?讨论你的分类模型的准确性。
- 4. 列出并描述此数据集的其他一些特性。
二、建模思路
首先对Number of reported results提出来观察时序序列数据波动:

可以看出游戏一开始推出的时候是一个很明显的上升曲线,直到四月达到峰值之后,游玩人数开始逐渐下降,也就是过了游戏的吸引时期。后面的数据相对于比较平缓,我们仅取最近三个月的数据观察,其中有个别很明显的噪音我们将它用均值填补:
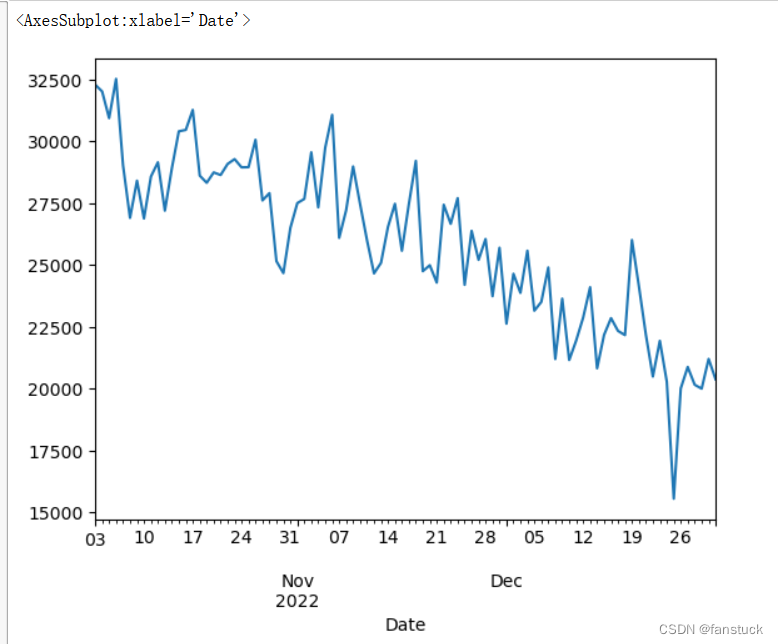
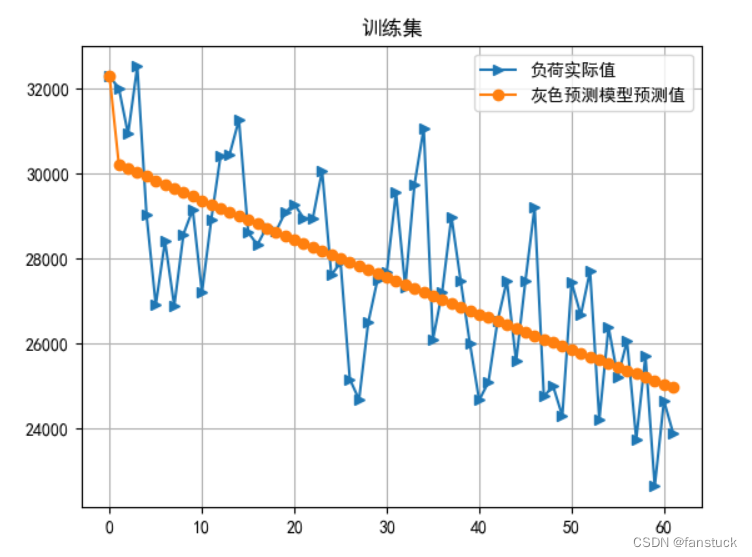
很明显的一个下降趋势,这里直接使用灰色时序预测最好了,当然你也可以选择用其他的时序预测模型:
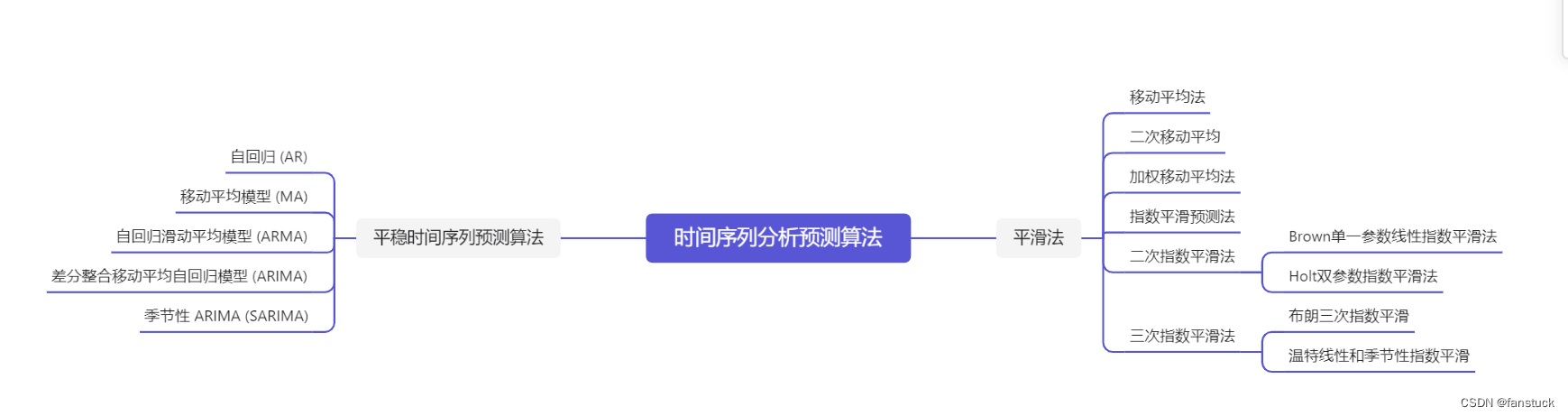
灰色预测:
二次指数平滑法:
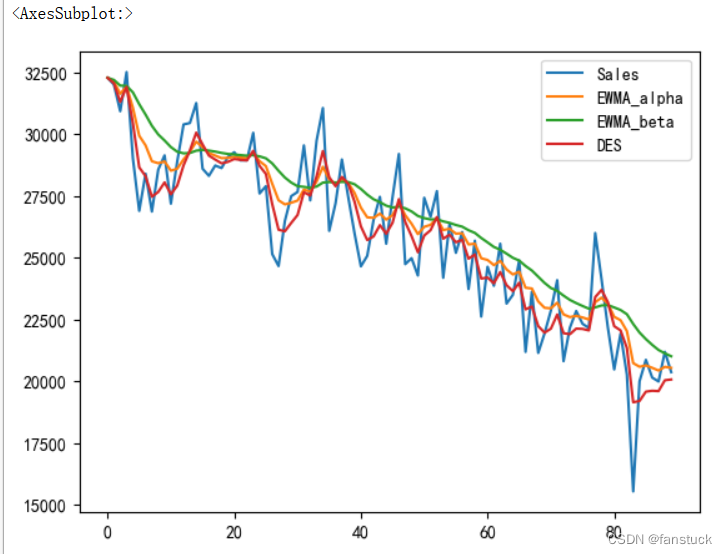
这里我建议还是用二次指数平滑法,不然灰色预测级比校验过不了:
该数据未通过级比检验 灰参数a: 0.00318897487491340454746069354996507172472774982452392578125 ,灰参数u: 30374.0096777603102964349091053009033203125 原数据样本标准差: 2104.8922894686443 残差样本标准差: 1804.1606900649451 后验差比: 0.8571273214746702 小误差概率p: 0.7142857142857143
对Word这行数据处理,首先我把我考虑到的因素列出:
单词难度-参考元音以及辅音区别划分,将该word直接切分,而且每个单词都是独一无二的,359天一个单词都没重复:

person相关性
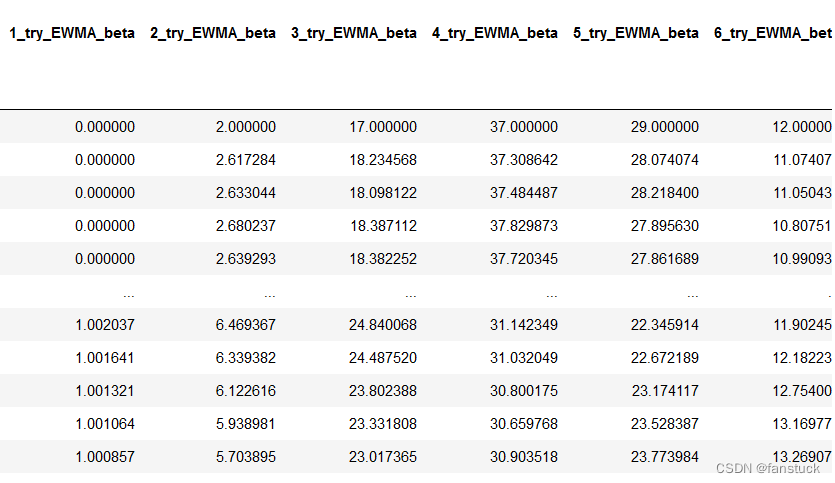
从而去对元音和辅音计数划分单词每个不同的含义,而且再对hard进行关联分析,这里还是老样子使用person分析即可:

有数据做这题属实简单啊,接着我们下一步再对整个预测区间做一个模型即可:
![[软件工程导论(第六版)]第1章 软件工程学概述(课后习题详解)](https://img-blog.csdnimg.cn/3b33be679f08482a87e40435212264e7.png)