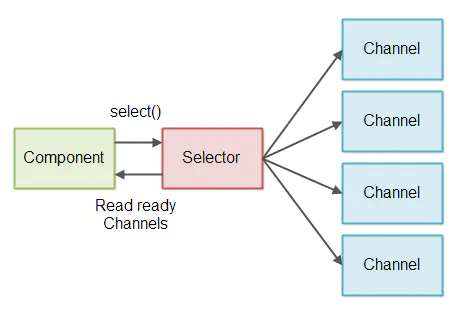
1.文章信息
本次介绍的文章是来自韩国科研团队的一篇2023年火灾检测文章,文章立足于森林火灾检测,题目为《An Improved Forest Fire Detection Method Based on the Detectron2 Model and a Deep Learning Approach》。
2.摘要
随着全球变暖和人口的增加,森林火灾已经成为全球关注的一个主要问题。这可能导致气候变化和温室效应等不利后果。令人惊讶的是,人类活动造成了不成比例的森林火灾。快速、高精度的检测是控制这一突发事件的关键。为了解决这个问题,我们提出了一种改进的森林火灾检测方法,基于新版本的Detectron2平台(Detectron库的重写),使用深度学习方法对火灾进行分类。此外,为训练模型创建了自定义数据集并进行标记,该数据集获得了比其他模型更高的精度。通过使用自定义数据集和5200张图像在各种实验场景中改进Detectron2模型,实现了这一稳健的结果。该模型可以在白天和夜间远距离探测小型火灾。使用Detectron2算法的优点是它可以对感兴趣的对象进行远距离检测。实验结果表明,所提出的森林火灾检测方法成功检测到火灾,准确率提高了99.3%。
3.介绍
森林火灾,也被称为野火,是近年来发生的最具破坏性的事件之一,造成了生命损失和财产损失。在2002年至2016年期间,由于无法控制的火灾,估计有422.5万平方公里的土地被烧毁。森林火灾可分为两大类:自然火灾和人为火灾。干旱天气、风、闪电、火山、流星、煤层火灾、加热和吸烟是自然原因的例子,而烹饪、意外或故意的疏忽行为是人为造成的火灾的例子。自然火灾和人为火灾都严重影响野生动物和人类生活。早期发现火灾是预防这种意外事件的关键,可以挽救许多生命和资源。
快速检测是降低整体影响的关键。传统的人工监控是昂贵的,而且不如检测模型有效。人力的管理和资源的维护既费时又费钱。自动化是一种更好、更准确的方法。天气条件、温度、雨水和风都会影响火灾探测。因此,实时收集数据的成本更低。
Detectron2是一种强大、可靠的自动火灾探测方法,使用maskRCNN。探测火灾具有挑战性,因为火灾的大小、颜色、运动、速度、接近方式、阳光,以及这些不同因素的组合。尽管这些因素使火灾探测具有挑战性,但数据集、训练模型和数据角度的使用可以达到最大的精度。文章的主要贡献如下:
(1)开发了一种森林火灾自动检测方法,减少了自然灾害和森林资源损失。
(2)为了训练所提出的模型,收集了一个大型自定义数据集,包含两个类别,火灾和非火灾,具有不同的场景(白天和黑夜),火灾和火焰,光和阴影。该数据集可在GitHub上供公众使用。我们使用LabelMe数据注释工具,它使用多边形而不是矩形来注释触发和非触发。
(3)利用火灾和非火灾图像及数据增强技术,提高了森林火灾检测精度。此外,该模型显著提高了精度,降低了误检率,即使是在较小的火灾区域。
4.模型
A. 森林火灾数据集
在目标检测中,主要的限制是在自定义训练模型中实现的数据收集。为了解决这个问题,我们从不同的数据库中收集了森林火灾数据,并使用了几种计算机视觉技术来增强数据集。为了获得更准确的结果,创建了两类数据集:火灾和非火灾。
数据集是公开的,一些图像是从谷歌收集的。为了首先训练数据集,将所有图像调整为相同的高度和宽度,以避免意外的结果或错误。数据采集后,数据集较小。为了增加数据集,我们在互联网上搜索森林火灾的视频,并捕获这些视频的帧。我们的训练数据集压缩了5200个昼夜森林火灾图像和非火灾图像,以区分火灾图像和非火灾图像,以达到最大的精度。小的数据集使我们无法达到预期的精度,如下表所示。因此,我们采用数据增强技术来扩展数据集。下一节详细描述了自定义数据集的收集和扩展。

使用计算机视觉算法增加数据集,将每张图像旋转15◦角度至360◦,如下图所示。通过应用该技术,我们的数据集增加了23倍。如前所述,我们在数据集中压缩了5200张图像。增强后,图像总数扩展到119,600张,为了防止假阳性结果,有10,120张fire-like图像。简单的线性代数将提供用一个角度旋转任意点p和q的方程。Detectron2在小型数据集上提供了良好的结果。

然而,与小数据集相比,大数据集的火灾探测精度显示出提高的结果。因此,最好是扩展训练数据集。其次,将所有森林火灾图像旋转到90◦,180◦和270◦(下图)。当图像旋转值大于15◦时,输出几乎相似,而当图像旋转约90◦时,我们失去了森林火灾图像的兴趣区域。

使用LabelMe软件来注释图像,这是Detectron2训练过程中的重要步骤,如下图所示。我们的关卡文件是一个JSON文件,保存在与培训文件相同的文件夹中。此外,在Detectron2中,所有图像大小必须具有准确的大小(高度和宽度)。因此,在注释图像之前,我们使用OpenCV将所有图像调整为相同的高度和宽度。此外,我们将非火灾图像添加到我们的训练集中,并将其标记为此类图像。训练非火灾图像的目的是减少误检次数。
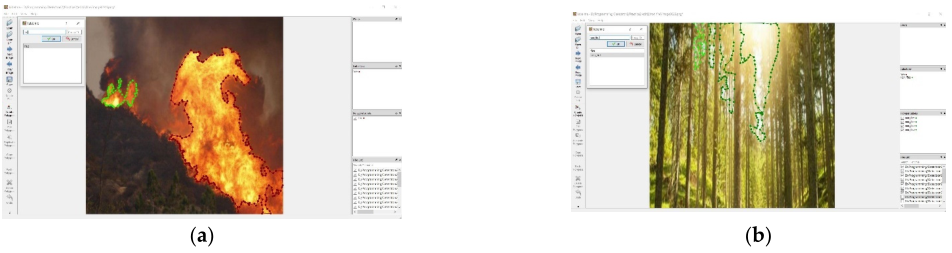
在数据集中,每个图像都被旋转15◦到360◦,结果是来自同一图像的23张图像。如果图像是手动标记的,我们在重复执行相同的任务时会损失相当多的时间。因此,我们使用仿射变换方法来旋转同一图像。图像变换是用NumPy表示在一个矩阵中。
B.模型
文章调整了森林火灾图像的大小和形状。开发数据集应用了几种技术。首先,我们使用OpenCV2将输入图像调整为224 × 224、320 × 320和512 × 512,如下图所示。在研究中,使用了416 × 416张图像来提高我们森林火灾模型的准确性,降低假检率。在CNN训练模型之前,实现了数据增强和图像对比度信息处理。
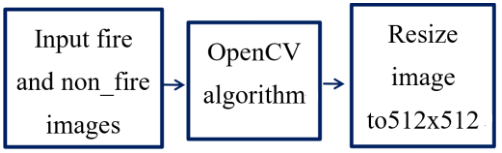
在Detectron2中,以同样的方式将森林火灾和非火灾的输入图像设置为512 × 512。如下表所示,得到了不同指标下训练和测试准确率的结果。Mask_rcnn_50_FPN_3x在62 h内的训练准确率分别为83.8%和79.8%。Keypoint_rcnn_R_50_FPN_3x为82.4%,测试准确率为77.8%。Mask_rcnn_50_FPN_3x和Keypoint_rcnn_R_50_FPN_3x的准确性和测试相似。但是,在权重较小的情况下,模型训练时间有所不同。提高准确性需要更多的训练时间,这是昂贵的。在Detectron2中训练的挑战是找到PyTorch在GPU模式下与Cuda的能力。人眼可以根据火灾的颜色、大小、形状和反射[5],轻易地将森林火灾图像与非火灾图像区分开来。

与人眼不同的是,由于形状、颜色和相似的环境,我们的模型可以区分非火图像和火图像,这可能导致错误检测。因此,大数据集可以实现更准确的目标检测。下图显示了森林火灾般的灯光图像,如太阳、雾霾和其他。

实时错误检测很不方便。在检测到这些错误后,我们使用新的训练参数升级了我们的实验。因此,我们意识到mask-RCNN模型比改进我们的参数更准确。火没有特定的形状和颜色,有不同的色调、饱和度和曝光,如下图所示。因此,在训练过程中,随机改变这些参数可以提供更好的结果。

由于对色调和不透明度的错误图像检测,改变了对数据集的方法。在数据集中,有一些低质量的图像尺寸小于512 × 512。因此,我们决定不使用自动色调、曝光或饱和度值。此外,在训练的模型之前,使用一种基于像素值、亮度和对比度值的算法来增加数据集。
数据集包含109,480张森林火灾图像和10,120张非火灾图像。在对数据库进行自定义分析后,删除了低质量和低分辨率的图像,获得了116,200张图像。在使用火灾图像对比度和亮度的公式和算法后,数据集大小从119,600张图像增加到348,600张,如下表所示。首先,在数据集中,与原始图像相比,我们将对比度提高了一倍,并将亮度降低了一半。

为了获得更好的实时准确性,还包括了13800张非火灾图像,类似于火灾图像。如前所述,非火灾图像实现了更好的实时森林火灾检测,从而减少了误报。一般来说,阳光是实时探测森林火灾最具破坏性的方法。正因为如此,大型数据集将允许区分不同森林天气条件下的阳光,如下图所示的日出和日落。

测试了不同的算法,Mask_rcnn_50_FPN_3x得分最低。相比之下,Panoptic_fpn_R_101_3x得分最高。在将非火灾图像添加到我们的数据集后,模型显著改善。
5.实验结果与分析
A. 实施详细信息
在笔记本电脑上使用Visual Studio 2022 c++实现和测试了模型,CPU速度为3.20 Hz, 32 GB RAM和3GPU。为了测试森林火灾检测模型,在不同的环境中实现了它。在前面的小节中,使用Detectron2讨论并实现了我们的模型。本节讨论所提出的模型的优点和局限性。传统上采用fast - rcnn框架进行实时火力探测,其精度较高。然而,提出的模型比传统的森林火灾检测方法改进了火灾检测,并表明掩模RCNN可以达到99.3%的精度。为了达到高精度,模型使用不同的参数进行训练:色调、饱和度、不透明度和小图像像素。此外,所提出的模型在不同的情况下都能有效工作,如下图所示。


将使用不同的参数和方法讨论模型的压缩。使用Detectron2深度学习和自定义数据集,用我们的模型准确检测森林火灾。为了准备研究,分析了以前的方法。然而,由于在初始化我们的模型时,多余的源代码是公开可用的,并且真正的对象检测合作的限制,正如我们前面提到的,方法使用了三层升级来达到模型中99.3%的最高精度。测试了F-measure (FM),它测量加权平均值,并平衡精度和召回率。这个分数考虑了假阴性率和真阳性率。由于测量准确率是困难的,FM是检测物体最常用的参数。在使用相同权重的检测模型中,假阴性和真阳性的检测效果更好。但是,如果真阳性和假阴性不一样,则必须考虑精度和查全率。
模型的结果根据上述七个标准中强大、正常和不强(弱)的不同类型的分类而有所不同。强大意味着该算法可以针对各种事件实现,正常意味着该算法可以在突发情况下失效。然而,不强也不弱意味着基于颜色、不透明度、图像噪声甚至大小的算法经常失败。
B. 局限

如上表所述,一个模型的好与坏不能基于整体性能以外的特定标准来确定。提出的模型有一定的局限性。例如,当在不同的环境下测试模型时,电灯或太阳在某些情况下被认为是火,如下图所示。我们打算使用更多来自不同环境的数据集来升级所提出的模型来解决这个问题。

6.结论
使用基于CNN的深度学习模型来改进森林火灾探测系统的研究已经进行了大量的研究。然而,Detectron2深度学习模型在森林火灾探测中的潜力尚未被探索。收集足够的图像数据用于森林火灾检测模型的训练是一项挑战,导致数据不平衡或过拟合问题,损害了模型的有效性。本研究提出了一种利用改进的Detectron2模型检测森林火灾的方法,并创建了一个数据集。
首先,用一个模型来检测火灾,然后用一个不同的深度学习对象检测模型来检测森林火灾。接下来,准备了数据集,为了在不同阶段和场景中更准确地检测火灾,用小图像升级了数据集,并删除了低质量的像素图像。此外,为了扩展我们的数据集,我们使用数据增强算法创建了比原始图像多23倍的图像。通过实验将所提方法与现有方法进行了对比,验证了模型的准确性。在达到最高精度后,在树莓派3B+中实现了我们的模型,这允许同时运行CPU和GPU细节。
此外,观察到实时应用程序中的一些局限性,例如不能从的数据集中标记烟雾图像。未来的任务包括在黑暗条件下解决模糊问题,并提高方法的准确性。计划在识别和医疗环境中使用3D CNN/U-Net开发一个具有可靠火灾探测性能的小型模型。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!