笔记整理:郭爱博,国防科技大学博士
论文发表会议:The 31th ACM International Conference on Information and Knowledge Management,CIKM 2022
动机
随着社交、电子商务、金融等行业的快速发展,现实世界编织出一张庞大而复杂的网络。然而,图(或网络)数据难以管理和挖掘,特别是对于经典的关系型数据库,这推动了图数据库的发展,Neo4j就是其中最流行的产品之一。Neo4j的查询语言Cypher(简称CQL)可实现对图的高效查询。但是CQL 的复杂操作和语法对用户的学习成本要求较高。因此,本文提出并定义了一种类似于Text-to-SQL的新任务Text-to-CQL。Text-to-CQL是一种新的语义解析任务,即将用户的自然语言查询转化为CQL查询,以帮助降低用户的学习和使用成本,提升图数据库与用户的交互友好度。同时,本文还为该任务构建了首个数据集SpCQL。
亮点
本文的亮点主要包括:
(1)提出并正式定义了Text-to-CQL任务,该任务目的是将用户自然语言查询自动转化为CQL查询,降低图数据库与使用者交互的学习和使用成本;
(2)构建了首个Text-to-CQL任务数据集SpCQL。
任务定义
Text-to-CQL 任务的目的是设计一个能够将自然语言查询转化为 CQL 查询的模型,如图 1 所示。
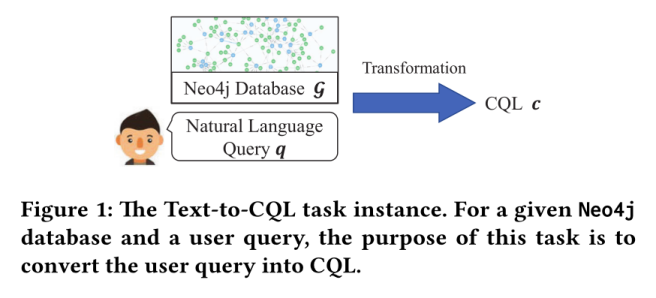
它可以正式表示为
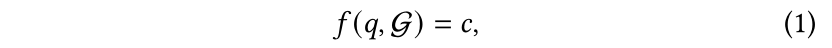
其中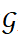 是给定的Neo4j数据库。数据库存储格式为
是给定的Neo4j数据库。数据库存储格式为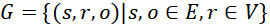 ,其中E代表节点集,V代表关系集。q表示用户提出的自然语言查询,记为
,其中E代表节点集,V代表关系集。q表示用户提出的自然语言查询,记为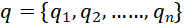 。每个 表示自然语言查询的一个token,n表示token的总数。结果c是生成的CQL。
。每个 表示自然语言查询的一个token,n表示token的总数。结果c是生成的CQL。
SpCQL数据集介绍
下面对SpCQL数据集进行介绍。
1.数据集概述
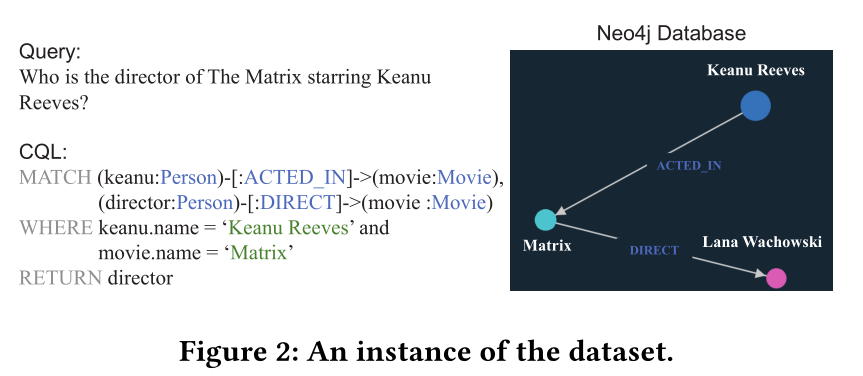
SpCQL包含两个主要部分:一个Neo4j图形数据库和10,000个NL查询-CQL对。在图2中展示的是一个查询对示例和对应的图数据。
2.数据采集
图数据库资源主体采用OwnThink。OwnThink是一个基于Neo4j的大规模开源知识图谱。这个知识图谱包含1.4亿个三元组,涵盖了人、组织、时间、活动和许多通用元素。
CQL查询通过网络爬虫从CSDN和Neo4j社区等技术论坛站点获取了Neo4j数据库中大约6,000个自然语言问题作为查询。为了确保数据库内容可以涵盖这些查询,作者调整了数据库中不存在的实体或关系。同时,还人工撰写了一些自然语言查询作为补充。
最后,经过数据清洗,获得10,000个自然语言查询。
3.CQL标注
为了准确地标注自然语言查询对应的CQL,邀请了10位精通Neo4j数据库和CQL语言的专业人员进行标注。为了确保NL查询-CQL对的多样性、自然性并且符合人类实际使用习惯,允许标注者在不改变语义的情况下进行微调。标注过程没有设计任何模板或脚本来生成CQL。标注后,进行交叉审查,以确保每个NL查询-CQL对满足使用和句法要求。
4.CQL分析
分三个部分介绍CQL查询的组件。
函数和运算符(Functions and Operators)
函数代表 CQL 查询中的主要功能关键字。最基本的有MATCH,WHERE和RETURN,它们与 SQL 的组成有些相似。其他包括但不限于OPTINAL MATCH,START,Aggregation,ORDER BY,LIMIT,SKIP。WITH,UNION等。
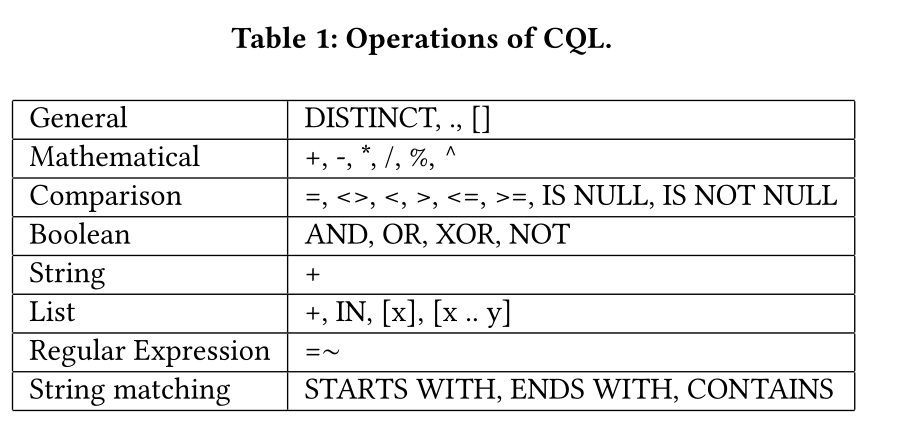
运算符可以对值、字符、列表等进行操作,也可以进行比较、匹配等操作。详情如表1所示。
模式(Patterns)
模式是 CQL 中最重要的概念,也是与 SQL 最大的区别。模式的引入不仅提高了用户路径查询的效率,而且相比 SQL 更加人性化。表 2 中列举出了所有模式及其相应的注释。
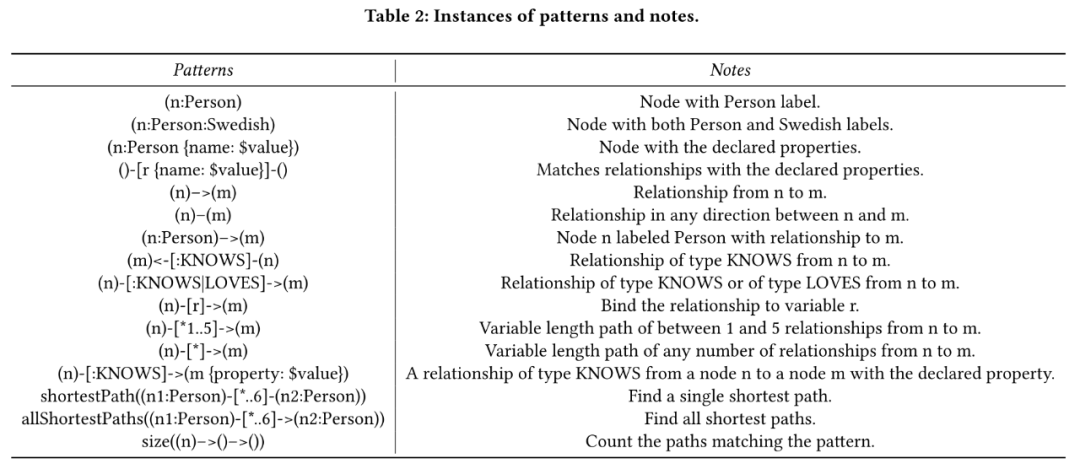
需要说明的是,CQL查询中存在方向规范,即有向关系查询。例如,(n)->(m)表示从n到m的关系。这种有向关系的查询对模型生成 CQL 提出了更大的挑战。
分类统计
本文分析了 SpCQL 数据集中的NL查询-CQL 对,以表明该数据集反映了真实世界的使用场景。首先统计每个查询中的函数和运算符的数量。直观地说,函数和运算符越多,对应于该查询的 CQL 就越复杂。统计结果见表3。
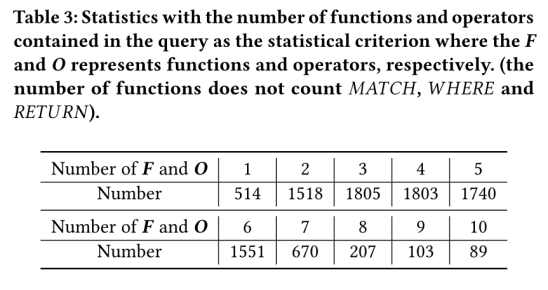
从统计数据可以看出,SpCQL 数据集中的查询通常包含多个函数和运算符。这使得 CQL 生成更加困难,因为涉及的组件更多。
此外,还统计到SpCQL数据集中总共 6,874 个查询涉及到模式。很容易理解,由于 Neo4j 数据库最大的特点是在图数据上查询路径(即模式),因此数据集中的大多数查询都与模式有关。模式查询相比于多函数/运算符的情况更具有挑战性。
考虑到模式的转换是一个更严峻的挑战,本文对涉及模式的查询进行了更深入的统计,分为三类,包括 1).无向边查询(Ud),2).有向边查询 (D) 和 3).限制路径长度查询和最短路径查询(RS)。三种类型的模式数量分别为 1,645、2,916 和 2,313。有向边查询的情况更多,因为用户通常指定一个人或组织作为查询的起点。此外,在查询过程中,对于限定路径(模式)长度的查询也是一种非常常见的使用场景。
实验分析
基线方法
该论文参考Text-to-SQL任务的基础解决方法,提供了三个Baseline,分别是Seq2Seq[1]、Seq2Seq+Attention[1]和Seq2Seq+Copying[2]。
测试指标
测试指标采用Text-to-SQL任务一致的Logical Accuracy和Execution Accuracy。
Logical Accuracy将模型生成的CQL查询与GOLDCQL的逻辑形式进行比较。它可能包含由条件顺序引起的误报,因为不排除WHERE子句中条件顺序的影响。它计算为
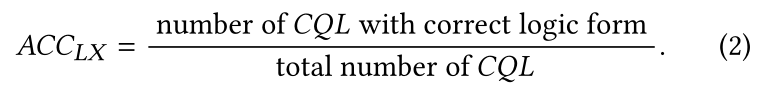
Execution Accuracy将模型生成的CQL查询结果与GOLDCQL执行结果进行比较。由于WHERE子句中的条件顺序不影响结果,因此可以忽略条件顺序的影响。它计算为
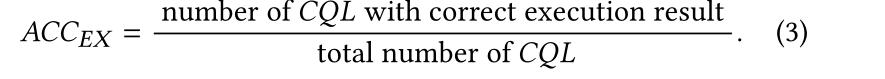
基线效果分析
表4中展示了上述三个Baseline的效果。
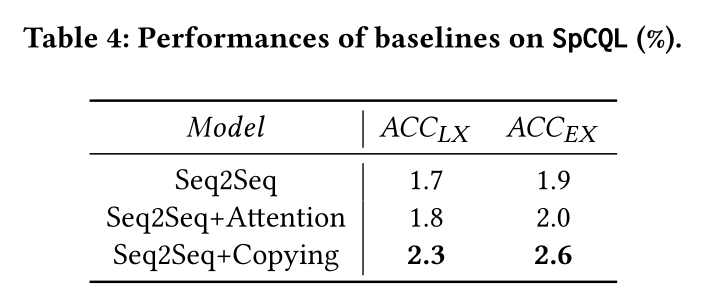
以Seq2Seq为基础的模型性能都很差,这是由于在解决复杂CQL查询场景时,无法正确地解码出CQL查询组件或内容。对于CQL包含模式甚至有向图关系的情况尤其如此,这是使用CQL进行查询时最常见的场景。此外,由于Seq2Seq模型存在重复解码等缺陷,因此及时添加注意力和复制机制并没有太大帮助。
本文还特意对模式查询问题进行了对比实验,比较了三种Baseline在三种模式查询下的性能,结果如表5所示。可以发现结果并不理想,尤其是在解析有向边CQL和限制边长和最短路径的查询等复杂查询时。
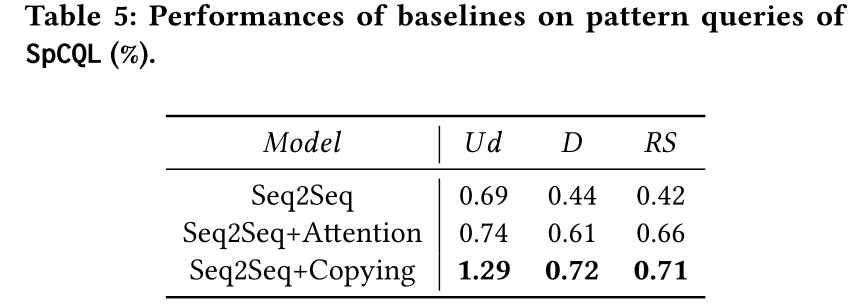
总结
本文构建了首个数据集SpCQL。SpCQL由两部分组成——存储在Neo4j中的图数据库和10000个NL查询-CQL对。基于这个数据集,正式定义了一个新的具有挑战性和现实意义的语义解析任务Text-to-CQL,即将自然语言查询转换为CQL查询。
基于此数据集可以推进此任务的研究,可以提升图数据库的用户友好性,并将降低学习和使用成本。考虑到SQL和CQL之间的根本差异,这一新数据集有望为Text-to-CQL任务提供研究基础。此外,Text-to-CQL的重要性不局限于Neo4j数据库,而是影响所有使用CQL作为操作语言的数据库。
参考文献
[1]DongL,LapataM.LanguagetoLogicalFormwithNeuralAttention[J].OfficeforOfficialPublicationsoftheEuropeanCommunities,2016.
[2]GuJ,LuZ,LiH,etal.IncorporatingCopyingMechanisminSequence-to-SequenceLearning[J].2016.
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
![[软件工程导论(第六版)]第1章 软件工程学概述(课后习题详解)](https://img-blog.csdnimg.cn/3b33be679f08482a87e40435212264e7.png)