什么是UUID
UUID 是指(UniversallyUnique Identifier)通用唯一识别码,128位。RFC 4122描述了具体的规范实现。
现实问题
我们开发的时候,数据库表总会有一个主键,以前我们可能会使用自增的数字作为主键。这样做去确实查询的时候比较快,但是在做系统集成或者数据迁移的的时候就麻烦了。这是id就有可能重复了。那么有什么比较好的方法解决这一问题呢? 于是jdk1.5出了UUID这个类来生成唯一的字符串标识。
UUID作用
UUID 的目的是让分布式系统中的所有元素都能有唯一的识别信息。如此一来,每个人都可以创建不与其它人冲突的 UUID,就不需考虑数据库创建时的名称重复问题。其作用视场景而定。
目前最广泛应用的 UUID,即是微软的 Microsoft's Globally Unique Identifiers (GUIDs),而其他重要的应用, 则有 Linux ext2/ext3 档案系统、LUKS 加密分割区、GNOME、KDE、Mac OS X 等等。
UUID定义
UUID使用16进制表示,共有36个字符(32个字母数字+4个连接符"-")组成,格式为8-4-4-4-12 ;【一个16进制只代表4个bit,所以是(8+4+4+4+12)*4=128位;】
是由一组32位数的16进制数字所构成,故 UUID 理论上的总数为,约等于

也就是说若每纳秒产生1百万个 UUID,要花100亿年才会将所有 UUID 用完。
格式:
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
示例:
96b31816-ae1c-11ed-904f-4531ee40a9e3
格式中M和N都有具体的含义
数字M的四位表示 UUID 版本,当前规范有5个版本,M可选值为1, 2, 3, 4, 5 ;
数字 N的一至四个最高有效位表示 UUID 变体(variant ),有固定的两位10xx因此只可能取值8, 9, a, b。
这5个版本使用不同算法,利用不同的信息来产生UUID,各版本有各自优势,适用于不同情景。具体使用的信息
版本 1:UUID 是根据时间和 MAC 地址生成的;
版本 2:UUID 是根据标识符(通常是组或用户 ID)、时间和节点 ID生成的;
版本 3:UUID 是通过散列(MD5 作为散列算法)名字空间(namespace)标识符和名称生成的;
版本 4 - UUID 使用随机性或伪随机性生成;
版本 5 类似于版本 3(SHA1 作为散列算法)。
故UUID每个版本不是根据精度区分的,Version5并不会比Version1精度高,在精度上,大家都能保证唯一性,重复的概率近乎于0。
为了能兼容过去的 UUID,以及应对未来的变化,因此有了变体(Variants)这一概念。
目前已知的变体有下面 4 种:
变体 0:格式为 0xxx,为了向后兼容预留。
变体 1:格式为 10xx,当前正在使用的。
变体 2:格式为 11xx,为早期微软的 GUID 预留。
变体 3:格式为 111x,为将来的扩展预留,目前暂未使用。
在上例中,M 是 1,N 是 a(二进制为 1010,符合 10xx 的格式),这就意味着这个 UUID 是“版本 1”、“变体 1”的 UUID。
目前大多数使用的 UUID 大都是变体 1,N 的取值是 8、9、a、b 中的一个。
version 1——date-time & MAC address
基于时间戳及MAC地址的UUID实现。它包括了48位的MAC地址和60位的时间戳,
v1为了保证唯一性,当时间精度不够时,会使用13~14位的clock sequence来扩展时间戳,比如:
当UUID的生产成速率太快,超过了系统时间的精度。时间戳的低位部分会每增加一个UUID就+1的操作来模拟更高精度的时间戳,换句话说,就是当系统时间精度无会区分2个UUID的时间先后时,为了保证唯一性,会在其中一个UUID上+1。所以UUID重复的概率几乎为0,时间戳加扩展的clock sequence一共有74bits,(2的74次方,约为1.8后面加22个零),即在每个节点下,每秒可产生1630亿不重复的UUID(因为只精确到了秒,不再是74位,所以换算了一下)。
相对于其它版本,v1还加入48位的MAC地址,这依赖于网卡供应商能提供唯一的MAC地址,同时也可能通过它反查到对应的MAC地址。Melissa病毒就是这样做到的。
Version2(date-time Mac address)
这是最神秘的版本,RFC没有提供具体的实现细节,以至于大部分的UUID库都没有实现它,只在特定的场景(DCE security)才会用到。所以绝大数情况,我们也不会碰到它。
Version3,5(namespace name-based)
V3和V5都是通过hashnamespace的标识符和名称生成的。V3使用MD5作为hash函数,V5则使用SHA-1。
因为里面没有不确定的部分,所以当namespace与输入参数确定时,得到的UUID都是确定唯一的。
具体的流程就是
把namespace和输入参数拼接在一起,如"http/http://wwwbaidu.com" ++"/query=uuid";
使用MD5算法对拼接后的字串进行hash,截断为128位;
把UUID的Version和variant字段都替换成固定的;
如果需要to_string,需要转为16进制和加上连接符"-"。
把V3的hash算法由MD5换成SHA-1就成了V5。
Version4(random)
这个版本使用最为广泛:
其中4位代表版本,2-3位代表variant。余下的122-121位都是全部随机的。即有2的122次方(5.3后面36个0)个UUID。一个标准实现的UUID库在生成了2.71万亿个UUID会产生重复UUID的可能性也只有50%的概率:
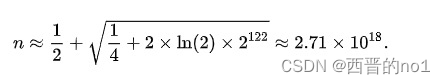
这相当于每秒产生10亿的UUID,持续85年,而把这些UUID都存入文件,每个UUID占16bytes,总需要45 EB(exabytes),比目前最大的数据库(PB)还要大很多倍。
UUID的重复概率
Java中UUID 使用版本4进行实现,所以由java.util.UUID类产生的 UUID,128个比特中,有122个比特是随机产生,4个比特标识版本被使用,还有2个标识变体被使用。利用生日悖论,可计算出两笔 UUID 拥有相同值的机率约为

其中x为 UUID 的取值范围,n为 UUID 的个数。
以下是以 x =
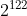
计算出n笔 UUID 后产生碰撞的机率:
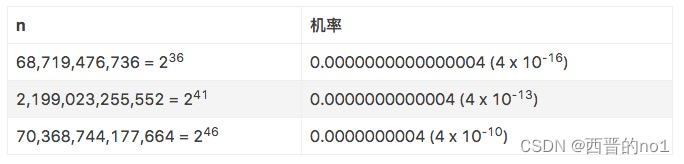
换句话说,每秒产生10亿笔 UUID ,100年后只产生一次重复的机率是50%。如果地球上每个人都各有6亿笔 UUID,发生一次重复的机率是50%。与被陨石击中的机率比较的话,已知一个人每年被陨石击中的机率估计为170亿分之1,也就是说机率大约是0.00000000006 (6 x ),等同于在一年内生产2000亿个UUID 并发生一次重复。
Java获取uuid示例
使用 JDK 原生的API
import java.util.UUID;
public class Test {
public static void main(String[] args) {
// JDK 原生的 API 获取UUID
// uuid版本3获取uuid
UUID uuid3 = UUID.nameUUIDFromBytes("test".getBytes());
int version3 = uuid3.version();
System.out.println("UUID3:" + uuid3 + " 版本 " + version3);
// uuid版本4获取uuid
UUID uuid4 = UUID.randomUUID();
int version4 = uuid4.version();
System.out.println("UUID4:" + uuid4 + " 版本 " + version4);
// 生成一个基于指定 UUID 字符串的 UUID 对象
UUID uuid = UUID.fromString("098f6bcd-4621-3373-8ade-4e832627b4f6");
int version = uuid.version();
System.out.println("UUID_fromString:" + uuid + " 版本 " + version);
}
}nameUUIDFromBytes() 会生成一个版本 3 的UUID,不过需要传递一个名称的字节数组作为参数。
randomUUID() 方法生成了一个版本 4 的 UUID,这也是生成 UUID最方便的方法。如果只使用原生 JDK 的话,基本上都用的这种方式。
fromString() 方法会生成一个基于指定 UUID 字符串的 UUID对象,如果指定的 UUID 字符串不符合 UUID 的格式,将抛出 IllegalArgumentException 异常。
使用com.fasterxml.uuid.Generators
除了使用 JDK 原生的 API 之外,还可以使用com.fasterxml.uuid.Generators,需要先在项目中加入该类的 Maven 依赖。
<dependencies>
<dependency>
<groupId>com.fasterxml.uuid</groupId>
<artifactId>java-uuid-generator</artifactId>
<version>3.1.4</version>
</dependency>
</dependencies>
代码:
import com.fasterxml.uuid.Generators;
import java.util.UUID;
public class Test {
public static void main(String[] args) {
// JDK 原生的 API 获取UUID
// uuid版本1获取uuid
UUID uuid1 = Generators.timeBasedGenerator().generate();
System.out.println("UUID : " + uuid1);
System.out.println("UUID 版本 : " + uuid1.version());
// uuid版本4获取uuid
UUID uuid2 = Generators.randomBasedGenerator().generate();
System.out.println("UUID : " + uuid2);
System.out.println("UUID 版本 : " + uuid2.version());
}
}Generators.timeBasedGenerator().generate() 可用于生成版本1 的 UUID,Generators.randomBasedGenerator().generate() 可用于生成版本4 的 UUID。
总结
使用较多的是版本1和版本4,其中版本1使用当前时间戳和MAC地址信息。版本4使用(伪)随机数信息,128bit中,除去版本确定的4bit和variant确定的2bit,其它122bit全部由(伪)随机数信息确定。
因为时间戳和随机数的唯一性,版本1和版本4总是生成唯一的标识符。若希望对给定的一个字符串总是能生成相同的 UUID,使用版本3或版本5。如果只是需要生成一个唯一ID,你可以使用V1或V4。
- V1基于时间戳和Mac地址,这些ID有一定的规律(你给出一个,是有可能被猜出来下一个是多少的),而且会暴露你的Mac地址。
- V4是完全随机(伪)的。
如果对于相同的参数需要输出相同的UUID,你可以使用V3或V5。
- V3基于MD5hash算法,如果需要考虑与其它系统的兼容性的话,就用它,因为它出来得早,大概率大家都是用它的。
- V5基于SHA-1hash算法,这个是首选。