前言
之前介绍过 Coqui TTS 的安装,不过那个环境被我玩挂掉了……
这次记录一下 docker 版本的使用。
参考网址:Docker images - TTS 0.11.1 documentation
正文
首先按照官网指示先把镜像 pull 下来。(后记:确保 GPU driver 支持 11.8 以上的 CUDA)
docker pull ghcr.io/coqui-ai/tts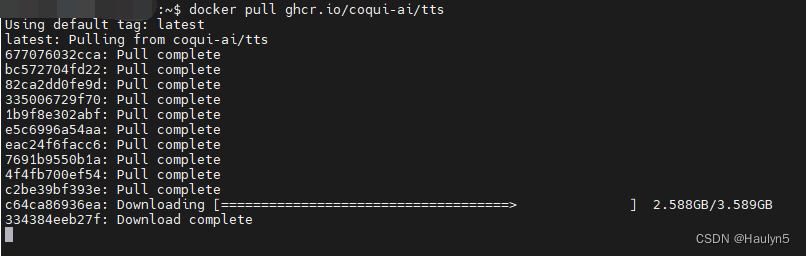
至少大约4 GB 以上的内容需要下载,所以要等一会儿了。
好,下载还专门找了 GPU 版本下载,结果发现自己不配。
For the GPU version, you need to have the latest NVIDIA drivers installed. With
nvidia-smiyou can check the CUDA version supported, it must be >= 11.8
需要保证 CUDA 能支持 11.8 以上的显卡驱动才可以,在下老显卡只配 CPU 版了,白下了。(我使用 CUDA 11.4,成功运行并报错)
重新下载一下 CPU 版本
docker pull ghcr.io/coqui-ai/tts-cpu执行测试命令。
docker run --rm -v ~/tts-output:/root/tts-output ghcr.io/coqui-ai/tts-cpu --text "Hello." --out_path /root/tts-output/hello.wav这条命令会运行容器,生成 hello 的语音,并保存在 ~/tts-output 这个目录。然后运行一下,需要下载预训练模型。网络原因,一阵好等了……

等了 17 分钟,终于下载好了默认模型。下面是输出信息。
user@server:~$ docker run --rm -v ~/tts-output:/root/tts-output ghcr.io/coqui-ai/tts-cpu --text "Hello." --out_path /root/tts-output/hello.wav
0%| | 0.00/113M [00:00<?, ?iB/s] > Downloading model to /root/.local/share/tts/tts_models--en--ljspeech--tacotron2-DDC
100%|██████████| 113M/113M [17:07<00:00, 110kiB/s]
> Model's license - apache 2.0
> Check https://choosealicense.com/licenses/apache-2.0/ for more info.
> Downloading model to /root/.local/share/tts/vocoder_models--en--ljspeech--hifigan_v2
100%|██████████| 3.80M/3.80M [00:01<00:00, 2.80MiB/s]
> Model's license - apache 2.0
> Check https://choosealicense.com/licenses/apache-2.0/ for more info.
> Using model: Tacotron2
> Setting up Audio Processor...
| > sample_rate:22050
| > resample:False
| > num_mels:80
| > log_func:np.log
| > min_level_db:-100
| > frame_shift_ms:None
| > frame_length_ms:None
| > ref_level_db:20
| > fft_size:1024
| > power:1.5
| > preemphasis:0.0
| > griffin_lim_iters:60
| > signal_norm:False
| > symmetric_norm:True
| > mel_fmin:0
| > mel_fmax:8000.0
| > pitch_fmin:1.0
| > pitch_fmax:640.0
| > spec_gain:1.0
| > stft_pad_mode:reflect
| > max_norm:4.0
| > clip_norm:True
| > do_trim_silence:True
| > trim_db:60
| > do_sound_norm:False
| > do_amp_to_db_linear:True
| > do_amp_to_db_mel:True
| > do_rms_norm:False
| > db_level:None
| > stats_path:None
| > base:2.718281828459045
| > hop_length:256
| > win_length:1024
> Model's reduction rate `r` is set to: 1
> Vocoder Model: hifigan
> Setting up Audio Processor...
| > sample_rate:22050
| > resample:False
| > num_mels:80
| > log_func:np.log
| > min_level_db:-100
| > frame_shift_ms:None
| > frame_length_ms:None
| > ref_level_db:20
| > fft_size:1024
| > power:1.5
| > preemphasis:0.0
| > griffin_lim_iters:60
| > signal_norm:False
| > symmetric_norm:True
| > mel_fmin:0
| > mel_fmax:8000.0
| > pitch_fmin:1.0
| > pitch_fmax:640.0
| > spec_gain:1.0
| > stft_pad_mode:reflect
| > max_norm:4.0
| > clip_norm:True
| > do_trim_silence:False
| > trim_db:60
| > do_sound_norm:False
| > do_amp_to_db_linear:True
| > do_amp_to_db_mel:True
| > do_rms_norm:False
| > db_level:None
| > stats_path:None
| > base:2.718281828459045
| > hop_length:256
| > win_length:1024
> Generator Model: hifigan_generator
> Discriminator Model: hifigan_discriminator
Removing weight norm...
> Text: Hello.
> Text splitted to sentences.
['Hello.']
> Processing time: 0.36794090270996094
> Real-time factor: 0.3480223449191248
> Saving output to /root/tts-output/hello.wav
可以在 ~/tts-output 目录找到新生成的语音。太短了,听感还算可以。难过的是忘了去掉 --rm ,执行完毕后容器给我删了……我下了20分钟的模型啊……
docker + 服务器程序测试
接下来试一下用 docker 开一个服务器。下面命令启动容器,相比官方文档,我删除了 --rm ,避免运行后容器失效。-p 后面的 40499 是宿主机映射的端口。
docker run -it -p 40499:5002 --entrypoint /bin/bash ghcr.io/coqui-ai/tts-cpu执行后进入容器内的终端。输入下面的命令。
python3 TTS/server/server.py --list_models #To get the list of available models输出如下:
Name format: type/language/dataset/model
1: tts_models/multilingual/multi-dataset/your_tts
2: tts_models/bg/cv/vits
3: tts_models/cs/cv/vits
4: tts_models/da/cv/vits
5: tts_models/et/cv/vits
6: tts_models/ga/cv/vits
7: tts_models/en/ek1/tacotron2
8: tts_models/en/ljspeech/tacotron2-DDC
9: tts_models/en/ljspeech/tacotron2-DDC_ph
10: tts_models/en/ljspeech/glow-tts
11: tts_models/en/ljspeech/speedy-speech
12: tts_models/en/ljspeech/tacotron2-DCA
13: tts_models/en/ljspeech/vits
14: tts_models/en/ljspeech/vits--neon
15: tts_models/en/ljspeech/fast_pitch
16: tts_models/en/ljspeech/overflow
17: tts_models/en/ljspeech/neural_hmm
18: tts_models/en/vctk/vits
19: tts_models/en/vctk/fast_pitch
20: tts_models/en/sam/tacotron-DDC
21: tts_models/en/blizzard2013/capacitron-t2-c50
22: tts_models/en/blizzard2013/capacitron-t2-c150_v2
23: tts_models/es/mai/tacotron2-DDC
24: tts_models/es/css10/vits
25: tts_models/fr/mai/tacotron2-DDC
26: tts_models/fr/css10/vits
27: tts_models/uk/mai/glow-tts
28: tts_models/uk/mai/vits
29: tts_models/zh-CN/baker/tacotron2-DDC-GST
30: tts_models/nl/mai/tacotron2-DDC
31: tts_models/nl/css10/vits
32: tts_models/de/thorsten/tacotron2-DCA
33: tts_models/de/thorsten/vits
34: tts_models/de/thorsten/tacotron2-DDC
35: tts_models/de/css10/vits-neon
36: tts_models/ja/kokoro/tacotron2-DDC
37: tts_models/tr/common-voice/glow-tts
38: tts_models/it/mai_female/glow-tts
39: tts_models/it/mai_female/vits
40: tts_models/it/mai_male/glow-tts
41: tts_models/it/mai_male/vits
42: tts_models/ewe/openbible/vits
43: tts_models/hau/openbible/vits
44: tts_models/lin/openbible/vits
45: tts_models/tw_akuapem/openbible/vits
46: tts_models/tw_asante/openbible/vits
47: tts_models/yor/openbible/vits
48: tts_models/hu/css10/vits
49: tts_models/el/cv/vits
50: tts_models/fi/css10/vits
51: tts_models/hr/cv/vits
52: tts_models/lt/cv/vits
53: tts_models/lv/cv/vits
54: tts_models/mt/cv/vits
55: tts_models/pl/mai_female/vits
56: tts_models/pt/cv/vits
57: tts_models/ro/cv/vits
58: tts_models/sk/cv/vits
59: tts_models/sl/cv/vits
60: tts_models/sv/cv/vits
61: tts_models/ca/custom/vits
62: tts_models/fa/custom/glow-tts
Name format: type/language/dataset/model
1: vocoder_models/universal/libri-tts/wavegrad
2: vocoder_models/universal/libri-tts/fullband-melgan
3: vocoder_models/en/ek1/wavegrad
4: vocoder_models/en/ljspeech/multiband-melgan
5: vocoder_models/en/ljspeech/hifigan_v2
6: vocoder_models/en/ljspeech/univnet
7: vocoder_models/en/blizzard2013/hifigan_v2
8: vocoder_models/en/vctk/hifigan_v2
9: vocoder_models/en/sam/hifigan_v2
10: vocoder_models/nl/mai/parallel-wavegan
11: vocoder_models/de/thorsten/wavegrad
12: vocoder_models/de/thorsten/fullband-melgan
13: vocoder_models/de/thorsten/hifigan_v1
14: vocoder_models/ja/kokoro/hifigan_v1
15: vocoder_models/uk/mai/multiband-melgan
16: vocoder_models/tr/common-voice/hifigan
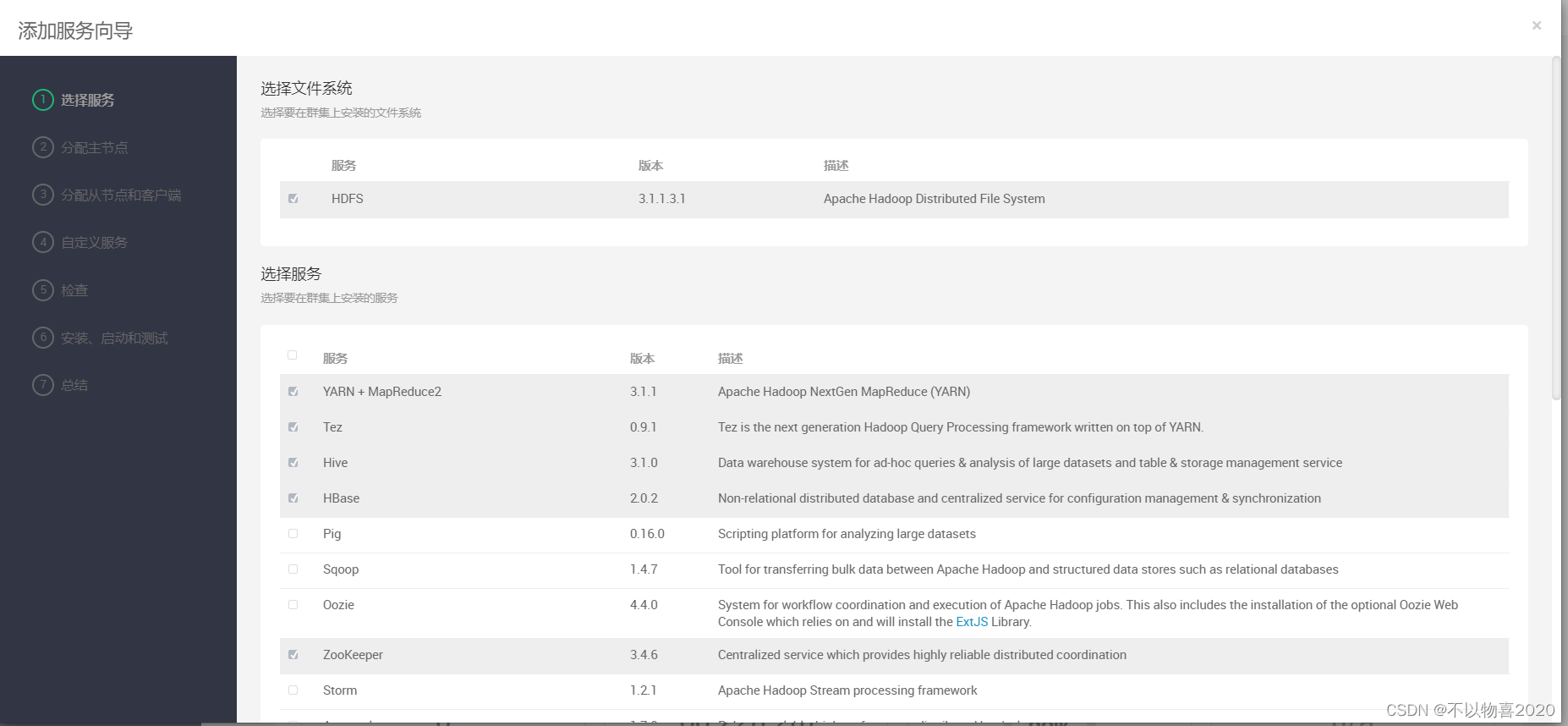
中文模型只有一个 tts_models/zh-CN/baker/tacotron2-DDC-GST,我们这里就测试这个模型。(后来发现还有几个多国语言版本)
注意这里如果按照官网的写法就是下面,这样执行,是没有进度条的……非常的焦虑
python3 TTS/server/server.py --model_name tts_models/zh-CN/baker/tacotron2-DDC-GST 大约等了半个小时以上吧,服务器程序成功运行,可惜这里误操作不小心把窗口关了,没有截图了……我重新运行了一下。(这里记得要看容器的端口映射)

左侧的 {"0": 0.1} 是一个 python 字典格式的字符串,测试了几次发现,基本就是"0" 表示 style 0,第 0 种分割,然后后面的 0.1 是对应的权重,试了试,权重超过 0.2 就没法听了。
style 换成其他数字,就会略微改变说话风格,但是影响不大,音色没有改变。
整体来说,测试了几个句子,听感还可以,就是有点机械但是能听清楚内容,略有杂音。人类在安静情况下应该还是能明显辨别是合成语音。
值得注意的一点是,记得给输入内容加句号,否则生成的语音会很地狱。有兴趣的朋友可以测试一下输入 0.5 不加标点符号进行测试。