目录
机器学习算法分类
数据集工具 Scikit-learn
Scikit-learn的安装
scikit-learn数据集API介绍
bunch对象
datasets模块
数据集的划分
train_test_split
代码示例
特征工程
特征提取
sklearn.feature_extraction API
字典特征提取示例
文本特征提取案例
jieba分词中文处理
Tf-idf文本特征提取
特征预处理
归一化
标准化
数据降维
低方差特征过滤
主成分分析(PCA)
相关系数
机器学习算法分类
- 监督学习(supervised learning)(预测)
- 定义:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
- 分类 k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
- 回归 线性回归、岭回归
- 无监督学习(unsupervised learning)
- 定义:输入数据是由输入特征值所组成。
- 聚类 k-means
数据集工具 Scikit-learn
数据集是机器学习、数据挖掘和其他数据分析领域中的重要组成部分,它包含一组数据样本,这些样本是用于训练、测试和评估模型的基础。
Scikit-learn是一个非常优秀的机器学习库,具有简单易用、多功能性、高性能、开源免费、与Python生态系统集成和丰富的社区支持等特点,被广泛应用于学术界和工业界。
Scikit-learn的安装
-
打开终端,更新包索引:
sudo apt update -
确认您已经安装了Python3。在终端中输入以下命令:
python3 --version如果 Python3 没有安装,可以输入以下命令进行安装:
sudo apt install python3 -
确认您已经安装了pip3,它是 Python3 的包管理器。在终端中输入以下命令:
pip3 --version如果没有安装,可以输入以下命令进行安装:
sudo apt install python3-pip -
通过 pip3 安装 scikit-learn:
pip3 install -U scikit-learn这将安装最新版本的 scikit-learn 包。
-
安装完成后,可以通过以下方式验证是否成功安装 scikit-learn:
python3 -c "import sklearn; print(sklearn.__version__)"如果成功安装,将会显示 Scikit-learn 的版本号
scikit-learn数据集API介绍
bunch对象
在Scikit-learn中,Bunch是一个类似于字典的对象,用于存储机器学习中的数据集和相关信息。Bunch对象的结构通常由以下三个属性构成:
data:特征数据,是一个n_samples * n_features的矩阵。
target:目标数据,是一个n_samples的数组,通常用于监督学习。
feature_names:特征的名称,是一个长度为n_features的字符串列表。
此外,Bunch对象还可能包括以下属性:
target_names:目标数据的名称,是一个长度为n_classes的字符串列表,通常用于分类问题。
DESCR:数据集的描述信息。
filename:数据集的文件名,如果数据集来自文件。
其他自定义属性:例如,可以通过设置自定义属性来保存数据集中的一些其他信息。
Bunch对象是Scikit-learn中数据集的常见格式,方便了数据的读取和处理,同时也方便了特征和目标数据的访问和转换。
datasets模块
-
加载标准数据集:
from sklearn.datasets import load_irisiris = load_iris()这里的
load_iris()函数可以加载鸢尾花数据集,返回一个类似于字典的Bunch对象,其中包括数据集的属性,如数据、标签、属性等信息。 -
加载小型数据集:
from sklearn.datasets import load_bostonboston = load_boston()这里的
load_boston()函数可以加载波士顿房价数据集,返回一个Bunch对象,包括数据、标签、属性等信息。 -
加载大型数据集:
from sklearn.datasets import fetch_openmlmnist = fetch_openml('mnist_784')这里的
fetch_openml()函数可以加载MNIST手写数字数据集,返回一个Bunch对象,包括数据、标签、属性等信息。这种方式可以从远程服务器上下载数据集,因此可以加载较大的数据集。 -
创建人工数据集:
from sklearn.datasets import make_classificationX, y = make_classification(n_samples=1000, n_features=10, random_state=42) -
这里的
make_classification()函数可以生成一个随机的二分类数据集,返回数据和标签,可以用于测试和验证机器学习模型。
通过加载和生成数据集,我们可以直接使用这些数据集进行模型训练和测试,同时也可以通过这些数据集学习和探索机器学习算法的性能和特征。
数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%
train_test_split
train_test_split是机器学习中常用的数据预处理工具,用于将原始数据集划分为训练集和测试集,以便在模型训练和评估过程中使用。
train_test_split函数是scikit-learn机器学习库中的一个函数,可以将原始数据集随机划分为训练集和测试集,常用的函数调用形式如下:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)其中,X表示原始数据的特征集合,y表示原始数据的标签集合。test_size参数指定了测试集所占的比例,random_state参数可以设置随机数种子,以保证每次划分结果的一致性。
train_test_split函数的工作原理是将原始数据集随机划分为两个子集,其中一个子集作为训练集,用于训练模型,另一个子集作为测试集,用于评估模型的性能。通过划分训练集和测试集,可以避免模型在训练过程中过拟合,并评估模型的泛化能力。
代码示例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载iris数据集
iris = load_iris()
# 输出数据相关内容
print("数据集特征:\n", iris.data[:5])
print("数据集标签:\n", iris.target[:5])
print("数据集特征名称:\n", iris.feature_names)
print("数据集标签名称:\n", iris.target_names)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
# 输出划分后的数据集形状
print("训练集特征形状:", X_train.shape)
print("训练集标签形状:", y_train.shape)
print("测试集特征形状:", X_test.shape)
print("测试集标签形状:", y_test.shape)

特征工程
特征工程是指根据机器学习的任务和数据特点,通过数据预处理、特征提取、特征选择、特征变换等一系列技术,构建更有代表性、更有判别能力的特征集合的过程。特征工程是机器学习的重要环节,对于机器学习的性能和效果具有重要意义。具体而言,特征工程的意义包括以下几点:
-
提高模型的准确率:特征工程能够提高模型的准确率,构建更有代表性、更有判别能力的特征可以帮助模型更好地区分不同类别的数据,从而提高模型的准确率。
-
降低模型的复杂度:特征工程能够降低模型的复杂度,通过特征选择和特征变换等技术,可以去除冗余和无用的特征,从而减少模型的复杂度,提高模型的泛化能力和鲁棒性。
-
提高模型的可解释性:特征工程能够提高模型的可解释性,选择和构造具有实际意义的特征可以帮助解释模型的预测结果,提高模型的可解释性和可信度。
-
加速模型训练:特征工程能够加速模型训练,通过特征提取和特征变换等技术,可以将原始数据转换为更高效、更紧凑的特征表示,从而加速模型的训练和预测。
特征提取
特征提取(Feature Extraction)是指从原始数据中提取出有用的特征,用于构建机器学习模型。在实际的数据处理过程中,原始数据往往是高维度、噪声和冗余信息较多的,因此需要对原始数据进行特征提取,减少特征维度,去除噪声和冗余信息,提高机器学习模型的精度和效率。
sklearn.feature_extraction API
sklearn.feature_extraction 模块是 scikit-learn 中的特征提取模块,提供了一些常用的特征提取方法。该模块中的类和函数可以帮助我们将文本、图像、音频等原始数据转换为适用于机器学习模型的特征表示。
该模块主要包括以下几个子模块:
- sklearn.feature_extraction.text:用于从文本中提取特征,例如单词计数、TF-IDF 等。
- sklearn.feature_extraction.image:用于从图像中提取特征,例如颜色、纹理、形状等。
- sklearn.feature_extraction.sequence:用于从序列数据中提取特征,例如 N-gram 特征、序列距离、序列转换等。
- sklearn.feature_extraction.dict_vectorizer:用于从字典数据中提取特征,例如 One-hot 编码等。
这些子模块中包含了多个特征提取类和函数,例如 CountVectorizer、TfidfVectorizer、DictVectorizer 等,这些类和函数都有统一的 API 接口,方便使用和组合。使用这些类和函数可以帮助我们快速有效地进行特征提取,提高机器学习模型的效果和效率。
字典特征提取示例
from sklearn.feature_extraction import DictVectorizer
# 定义一个包含字典的列表
data = [
{'age': 25, 'sex': 'male', 'location': 'New York'},
{'age': 30, 'sex': 'female', 'location': 'Chicago'},
{'age': 35, 'sex': 'male', 'location': 'San Francisco'},
{'age': 40, 'sex': 'female', 'location': 'Los Angeles'}
]
# 实例化 DictVectorizer
vec = DictVectorizer()
# 将列表转换为特征矩阵
features = vec.fit_transform(data)
# 查看特征矩阵
print(features.toarray())
# 查看特征名称
print(vec.get_feature_names())
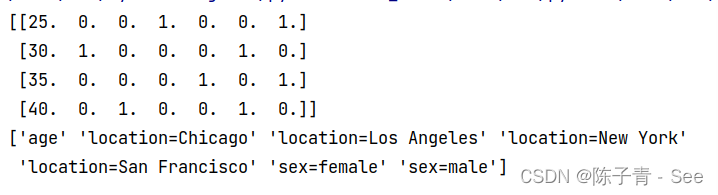
在这个案例中,我们首先定义一个包含字典的列表,每个字典表示一个数据样本。然后,我们实例化 DictVectorizer 类,并将列表作为输入调用 fit_transform() 方法,将其转换为一个特征矩阵。最后,我们查看特征矩阵和特征名称。特征矩阵是一个稀疏矩阵,每一列代表一个特征,每一行代表一个数据样本,特征值表示该特征在该数据样本中的取值。特征名称是一个包含特征名称的列表,每个特征名称表示一个特征。对于特征当中存在类别信息的我们都会做one-hot编码处理,例如2,3类代表了两种性别类别,4~7列则是四种城市类别。
文本特征提取案例
from sklearn.feature_extraction.text import CountVectorizer
# 定义一组文本数据
text_data = [
"hello world",
"hello python",
"python is great",
"hello scikit-learn"
]
# 实例化 CountVectorizer 类
vectorizer = CountVectorizer()
# 将文本转换为特征矩阵
features = vectorizer.fit_transform(text_data)
# 查看特征矩阵
print(features.toarray())
# 查看特征名称
print(vectorizer.get_feature_names())

特征矩阵是一个稀疏矩阵,每一行代表一个文本数据,每一列代表一个单词,特征值表示该单词在该文本数据中出现的次数。特征名称是一个包含所有单词的列表。可以看到,该方法将文本数据转换为了一个基于单词出现次数的特征表示,可以用于机器学习模型的训练和预测。
jieba分词中文处理
jieba是一种常用的中文分词工具,使用Python语言编写,能够快速高效地完成中文分词任务。它采用基于前缀词典的匹配算法,能够快速地找出文本中的所有可能的词语,从而完成分词任务。具体来说,jieba会先将文本中的汉字进行切割,然后依据词典匹配划分为不同的词语。
import jieba data = "阳光下有两个影子,一个是我的,一个也是我的。 鲁迅" print(list(jieba.cut(data)))

将中文进行分词切割后再进行分词提取
from sklearn.feature_extraction.text import CountVectorizer import jieba data = "阳光下有两个影子,一个是我的,一个也是我的。 鲁迅" feature = CountVectorizer(); data = feature.fit_transform(list(jieba.cut(data))) print(data.toarray()) print(feature.get_feature_names_out())

Tf-idf文本特征提取
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取方法,可以用来衡量一个词语对于一个文档或一组文档的重要性。该方法的核心思想是,一个词语在当前文档中出现的次数越多,同时在所有文档中出现的次数越少,那么它对于当前文档的重要性就越高。
TF-IDF方法通常包含两个部分:TF和IDF。
-
TF(Term Frequency):表示词语在当前文档中出现的频率,即该词语在当前文档中出现的次数除以当前文档中所有词语的总数。
-
IDF(Inverse Document Frequency):表示词语在所有文档中的逆文档频率,即该词语在所有文档中出现的次数除以所有文档的总数的对数。
TF-IDF的计算公式如下:
TF-IDF = TF * IDF
在Python中,可以使用sklearn库来进行TF-IDF特征提取。sklearn中的TfidfVectorizer类可以对文本进行特征提取,并将结果转化为稀疏矩阵的形式,方便进行机器学习模型的训练。
以下是一个简单的使用sklearn库实现TF-IDF特征提取的代码示例:
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
def cut_word(text):
return " ".join(list(jieba.cut(text)))
# 定义样本文本
corpus = ['我喜欢用Python进行自然语言处理',
'Python非常好用',
'我正在学习Python自然语言处理']
textList = []
for data in corpus:
textList.append(cut_word(data))
# 使用TfidfVectorizer类进行TF-IDF特征提取
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(textList)
# 输出提取的特征向量
print(tfidf.toarray())
print(vectorizer.get_feature_names_out())
特征预处理
特征预处理(Feature preprocessing)是机器学习中非常重要的一步,它通常是指对原始特征进行一系列处理操作,使得它们更适合用于训练机器学习模型。特征预处理包括了数据清洗、特征缩放、特征编码等多个方面。
归一化
归一化(Normalization)是指将特征缩放到一个特定范围内,通常是[0,1]或[-1,1]之间。归一化可以避免不同特征之间的差异对模型训练产生的影响,提高模型的准确性和稳定性。
MinMaxScaler是scikit-learn库中提供的一个预处理工具,主要用于将数据缩放到一个指定的范围内,通常是0到1之间。它将数据按照最大值和最小值进行缩放,使得原始数据集中的最小值被缩放到0,最大值被缩放到1,而其他值则被缩放到0和1之间的某个值。
MinMaxScaler适用于处理那些数据的取值范围差异较大的情况,比如某些特征的取值范围远远大于其他特征的取值范围,这会对模型的训练产生一定的影响。缩放后的数据不仅能使模型训练更加稳定和准确,还可以加快模型的收敛速度。
使用MinMaxScaler的过程非常简单,具体步骤如下:
-
导入
MinMaxScaler库:from sklearn.preprocessing import MinMaxScaler -
创建一个
MinMaxScaler对象:scaler = MinMaxScaler() -
使用
fit_transform()方法对数据进行缩放:scaled_data = scaler.fit_transform(data)
feature_range参数的取值是[0, 1],即缩放后的特征取值范围是0到1之间。如果需要将特征缩放到其他取值范围,可以通过修改feature_range参数来实现。
from sklearn.preprocessing import MinMaxScaler import numpy as np data = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) scaler = MinMaxScaler(feature_range=(-1, 1)) scaled_data = scaler.fit_transform(data) print(scaled_data)

标准化
标准化(Normalization)是指将数据按比例缩放,使之落入一个小的特定区间,常见的是将数据缩放到均值为0,方差为1的范围内。标准化可以消除数据之间的量纲和数量级差异,使得数据更具有可比性和可解释性,同时对于某些机器学习算法也有很好的效果。
标准化通常需要先对原始数据进行中心化处理,即将每个特征的数据都减去该特征的均值,使得数据的均值为0。然后再将数据缩放到方差为1的范围内,这样就可以保证数据的尺度一致,不会因为特征的取值范围不同而对模型产生不良影响。
特征的均值表示所有样本在该特征上的取值的平均数,方差则表示所有样本在该特征上的取值的离散程度。在标准化的过程中,将每个特征都减去该特征的均值,然后再除以该特征的标准差,从而将特征的均值变成了0,方差变成了1。这样就可以消除不同特征之间的量纲差异,使得模型更容易收敛。
from sklearn.preprocessing import StandardScaler
import numpy as np
# 构造数据
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
# 创建 StandardScaler 对象
scaler = StandardScaler()
# 对数据进行标准化
scaled_data = scaler.fit_transform(data)
# 输出标准化后的数据
print(scaled_data)
print("特征的均值:", scaler.mean_)
print("特征的方差:", scaler.var_)

数据降维
数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
降维的两种方式
- 特征选择
- 主成分分析(可以理解一种特征提取的方式)
方法
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- 相关系数
- Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
- 深度学习:卷积等
低方差特征过滤
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
方差是一种描述数据分布范围的统计量,用于衡量数据的离散程度。在特征选择中,方差可以作为一种度量特征重要性的指标,因为方差越大,代表数据分布的范围越广,样本之间的差异性也就越大,因此这个特征也就越重要。
简单来说,方差越大代表着数据中的差异性越大,而这些差异性可以用于区分不同类别的数据,因此具有较大的区分度,可以作为一种重要的特征。
下面使用sklearn进行特征选择的案例,其中采用的方法是方差过滤。
from sklearn.feature_selection import VarianceThreshold import numpy as np # 原始数据,共有3个特征 X = np.array([[0, 2, 0], [0, 1, 4], [1, 1, 0], [0, 1, 1]]) # 创建方差过滤器,阈值为1 selector = VarianceThreshold(threshold=1) # 对数据进行特征选择 X_new = selector.fit_transform(X) # 输出特征选择后的数据 print("特征选择后的数据:\n", X_new)
在这个例子中,我们使用了sklearn中的
VarianceThreshold类来进行特征选择。该类的作用是去除方差低于某个阈值的特征,因为方差较小的特征通常包含的信息较少。在代码中,我们先定义了一个3×3的数组
X作为原始数据,然后创建了一个VarianceThreshold对象,将阈值设置为1。最后,使用fit_transform方法对原始数据进行特征选择,得到了新的特征矩阵X_new。可以看到,在特征选择后,原始数据中第一个特征的方差为0,因此被过滤掉了。剩下的一个特征的方差大于1,因此被保留下来。

主成分分析(PCA)
-
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
-
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
- 应用:回归分析或者聚类分析当中
API sklearn.decomposition.PCA
- sklearn.decomposition.PCA(n_components=None)
- 将数据分解为较低维数空间
- n_components:
- 小数:表示保留百分之多少的信息
- 整数:减少到多少特征
- PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的array
from sklearn.decomposition import PCA import numpy as np # 构造数据集 X = np.array([[1, 2, 3, 4], [4, 5, 6, 7], [7, 8, 9, 10], [10, 11, 12, 13]]) # 使用PCA进行降维 pca = PCA(n_components=2) X_pca = pca.fit_transform(X) # 打印降维后的数据集 print('降维后的数据集:\n', X_pca)

可以看到,使用PCA将4维数据降到了2维。可以发现,降维后的数据集只有2列,分别对应PCA得到的两个主成分,其余列被过滤掉了。
相关系数
相关系数是用来衡量两个变量之间相关性强弱的指标。常见的相关系数有Pearson相关系数、Spearman秩相关系数、Kendall秩相关系数等。
Pearson相关系数是最常用的一种相关系数,用于衡量两个连续变量之间线性相关程度的大小,其取值范围在-1到1之间,0表示无相关性,正数表示正相关,负数表示负相关。
下面给出一个使用scipy.stats.pearsonr计算Pearson相关系数的案例:
from scipy.stats import pearsonr import numpy as np # 构造数据集 X = np.array([[-1, 2, 5, -4], [2, -1, -3, 6], [5, -3, -2, 1], [-4, 6, 1, 0]]) # 计算第一列和第三列的Pearson相关系数 r, p = pearsonr(X[:, 0], X[:, 2]) print('Pearson相关系数:', r)
可以看到,使用pearsonr计算出了第一列和第三列的Pearson相关系数为-0.61,说明两列之间存在一定的负相关性。值越接近于-1或1表示两个变量之间的相关性越强,值越接近于0表示两个变量之间的相关性越弱。