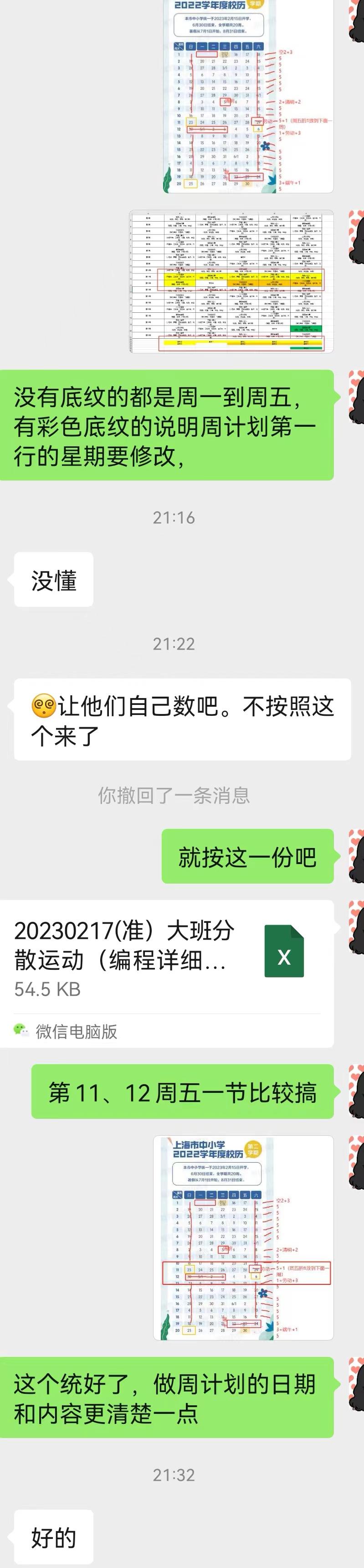
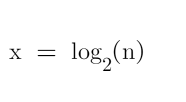前言:
目前中长尾推荐的方法有很多,主流的方法有几类比如:1)在没有项目ID嵌入的情况下提高推荐模型的鲁棒性,2)利用有限的交互数据提高学习效率,如使用元学习方法;3)利用物品侧面信息,便于物品ID嵌入的初始化,4)辅助数据引入,包括知识图谱网络,跨领域转换等等
在优化的过程中,结合自己的一些工作,感觉是不是也可以从一致性的角度的来考虑这个问题,这样的好处是有个统一的切分方式,那么看到哪块还不一致,是不是就可以作为一个未来的优化点?
一,冷启动&长尾问题存在哪些一致性问题
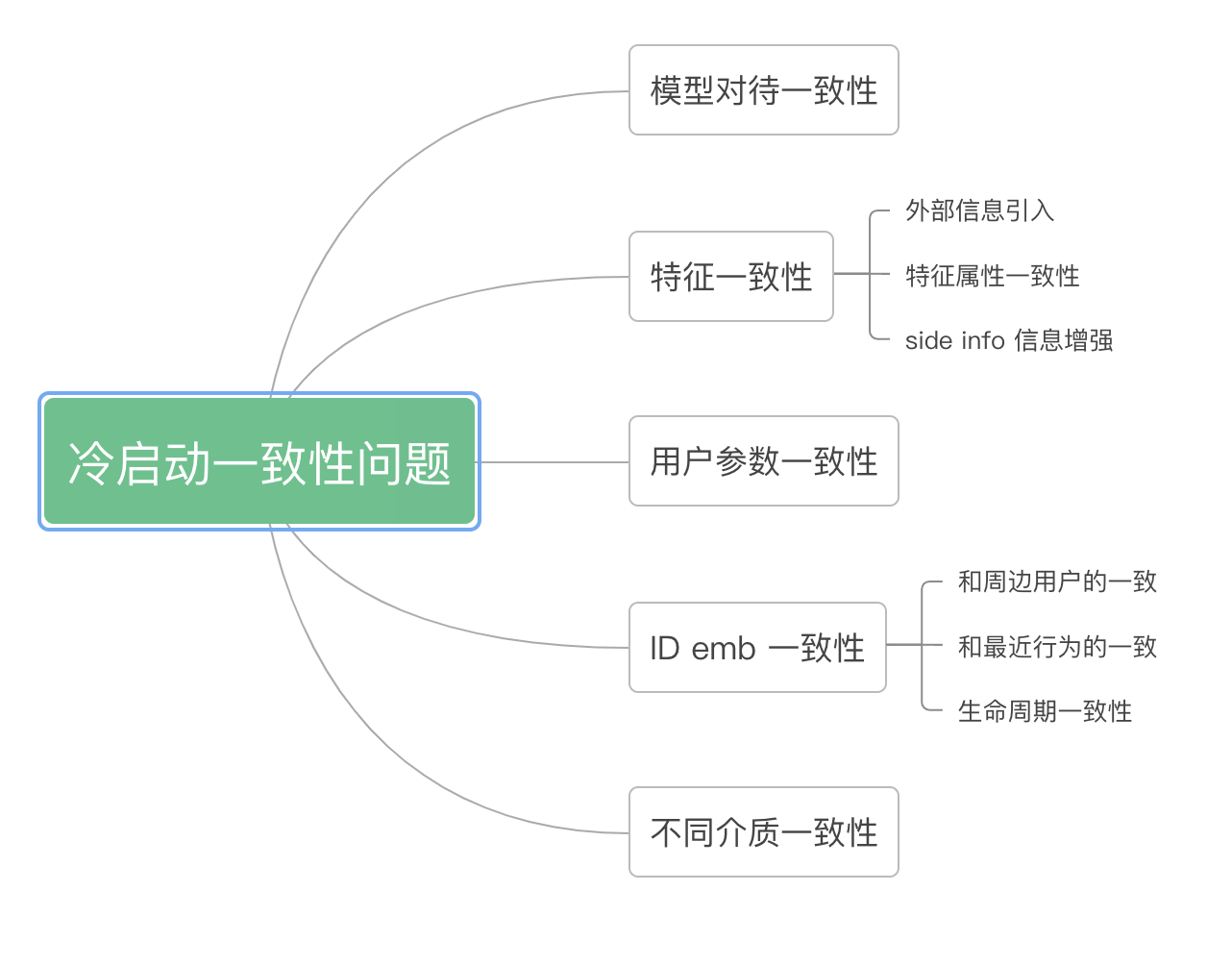
1,模型对待一致性
主要方法为在没有项目ID嵌入的情况下提高推荐模型的鲁棒性,在模型训练中对项目ID嵌入使用dropout或masking,使得同模型对待缺失的特征鲁棒较好,如
《[NIPS2017]DropoutNet: Addressing Cold Start in Recommender Systems》在训练过程中加入dropout的机制,使得模型不过度依赖于ID embedding,而是其他内容特征。从而使得冷启动推荐主要是根据内容特征来进行推荐,减小了不好的ID embedding的影响。

2,特征一致性
主要方法认为高活和低活特征分布上存在差异,通过拉齐特征的分布来缓解这个问题:代表的文章如《ESAM: Discriminative Domain Adaptation with Non-Displayed Items to Improve Long-Tail Performance》
ESAM认为,
“曝光item”与“未曝光item”的特征之间的关系是一致的。比如,无论曝光与否,奢侈品牌的价格都要比普通品牌的价格要贵。如下图左所示
“曝光item”与“未曝光item”的高阶特征(embedding的不同维度)之间的关系,也应该保持不变。所下图右所示

3,用户和参数一致性
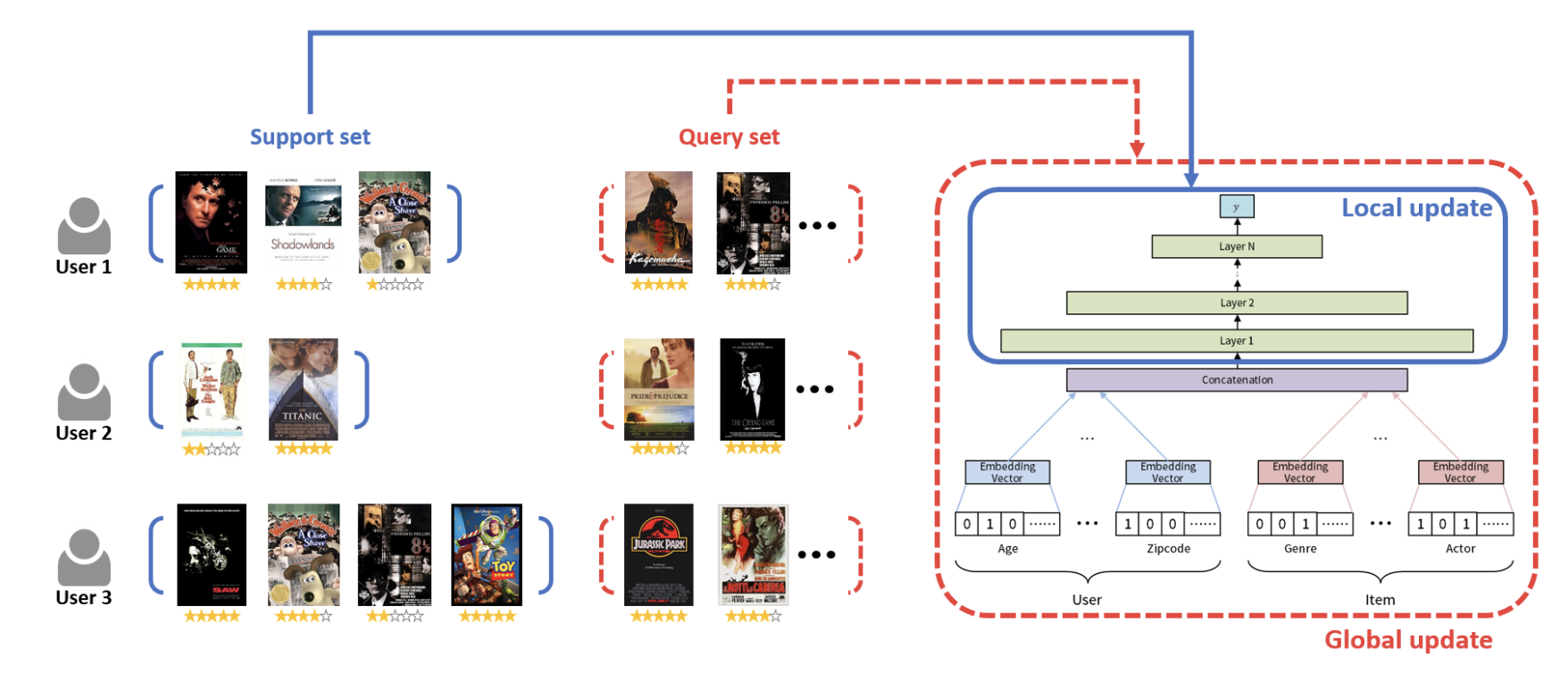
主要思路在于得到一个适用与该用户的模型,并可以在查询集上得到较好的效果。大部分采用元学习的思路。如《MeLU:Meta-Learned User Preference Estimator for Cold-Start Recommendation》主要包含两个集合,分别是支持集(support set)和查询集(query set),两个集合分别用于计算训练loss和测试loss。在局部更新时,主要在支持集(训练过程)上进行参数优化;在全局更新时,在查询集上最小化损失。训练模型快速地从一个新的,包含少量样本(训练阶段从未见过的)的数据集上进行学习。