来源:投稿 作者:王同学
编辑:学姐

Yolov5详解
官方源码仓库:https://github.com/ultralytics/yolov5
相关论文:未发表(改进点都被你们抢先发了)
0 前言
截止到2022年7月,Yolov5项目已经在Github上获得了28000+个star,工业应用也十分广泛,基于Yolov5改进的相关交叉学科论文也不计其数,所以了解Yolov5对找工作还是发论文都是十分有帮助的。

Yolov5目前已经迭代到了6.1版本,所以本篇文章主要针对6.1版本进行详解
Yolov5提供了10个不同版本的模型,他们除网络的深度和宽度外并无太大差别
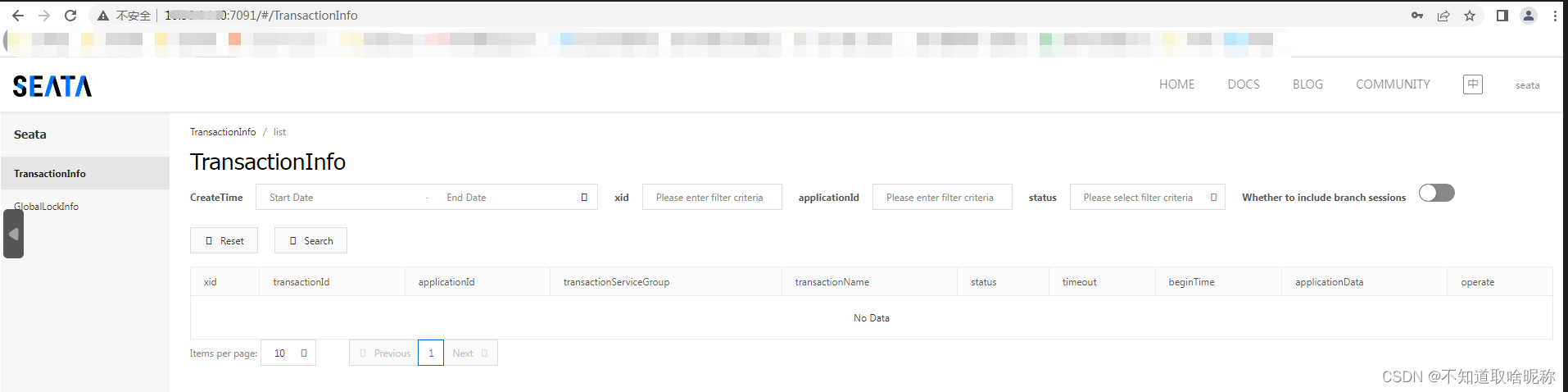
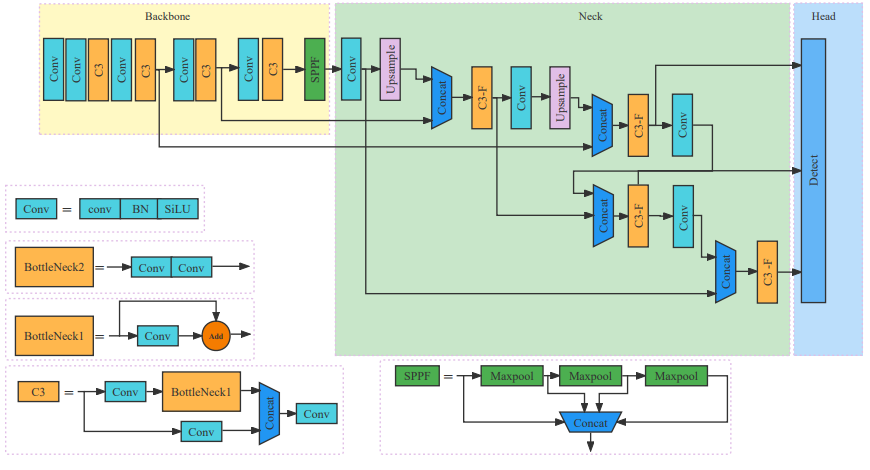
1 网络结构
Yolov5主要由以下几部分组成:
- 输入端: Mosaic数据增强、自适应锚框计算
- Backbone: New CSP-Darknet53
- Neck: SPPF, FPN+PAN
- Head: YOLOv3 Head
- 训练策略:CIoU loss
2 输入端
2.1 Mosaic数据增强
在 YOLOv5 中除了使用最基本的数据增强方法外,还使用了 Mosaic 数据增强方法,其主要思想就是将1- 4 张图片进行随机裁剪、缩放后,再随机排列拼接形成一张图片,实现丰富数据集的同时,增加了小样本目标,提升网络的训练速度。在进行归一化操作时会一次性计算 4 张图片的数据,因此模型对内存的需求降低。

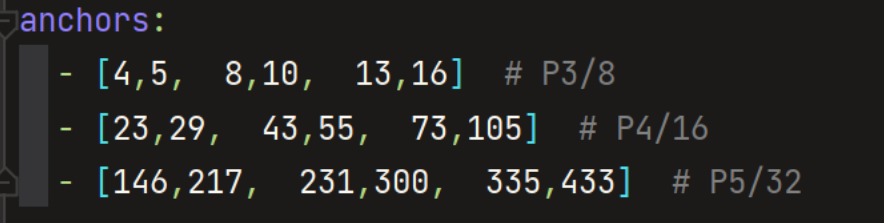
2.2自适应锚框计算
Yolov5每次训练时会自适应的计算不同训练集中的最佳锚框值,从而帮助网络更快的收敛。
3 Backbone
Yolov5在Backbone和Neck中用了两种不同的CSP结构,具体可参考下图-Yolov5网络结构图
4 Neck
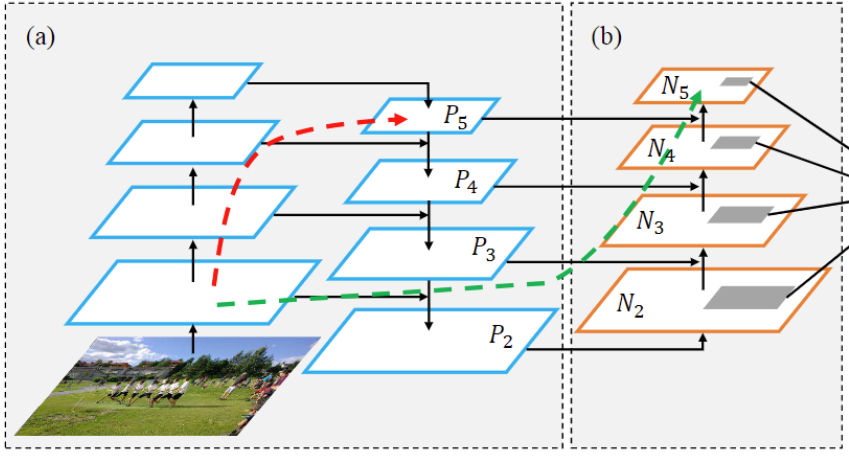
和「Yolov4中一样,都采用FPN+PAN」的结构;即除了上采样外,又增加了一部分下采样模块,通过这种方式可以融合更加丰富的特征
5 Head
在检测头方面依然采用Yolov3的检测头,并没有特别的改进
6 主要训练策略
- CIoU loss:在DIoU的基础上增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加的符合真实框
- Multi-scale training(0.5~1.5x):多尺度训练。
- Warmup and Cosine LR scheduler:训练前先进行Warmup热身,然后在采用Cosine学习率下降策略。
- Mixed precision:混合精度训练,能够减少显存的占用并且加快训练速度。
7 损失计算
YOLOv5的损失主要由三个部分组成:
- Classes loss,分类损失,采用的是BCE loss,注意只计算正样本的分类损失。
- Objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的obj损失。
- Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失。
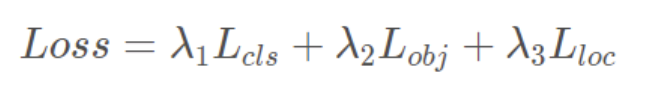
在源码中,针对预测小目标的预测特征层(P3)采用的权重是4.0,针对预测中等目标的预测特征层(P4)采用的权重是1.0,针对预测大目标的预测特征层(P5)采用的权重是0.4,作者说这是针对COCO数据集设置的超参数。
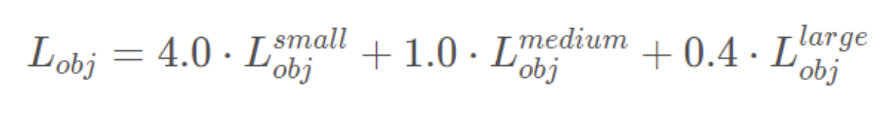
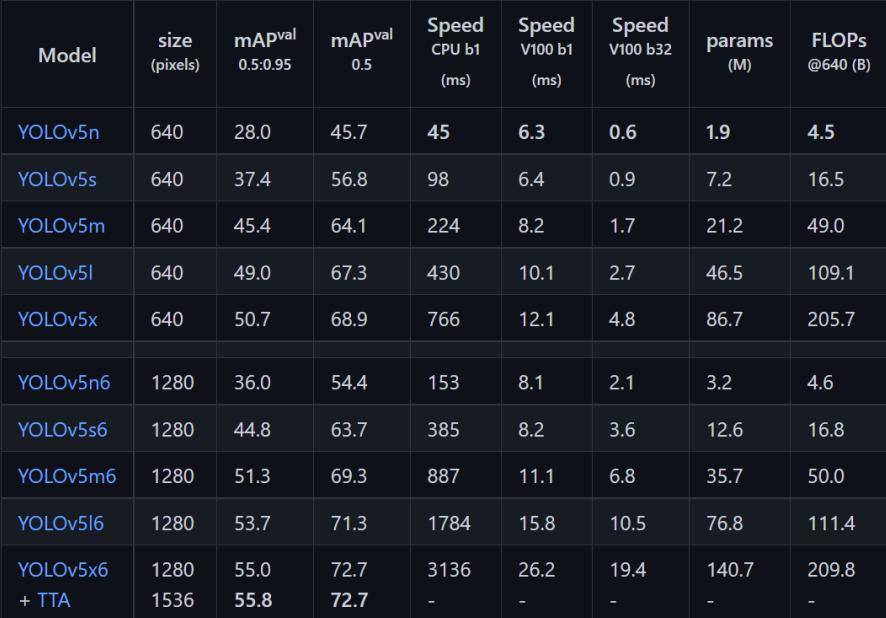
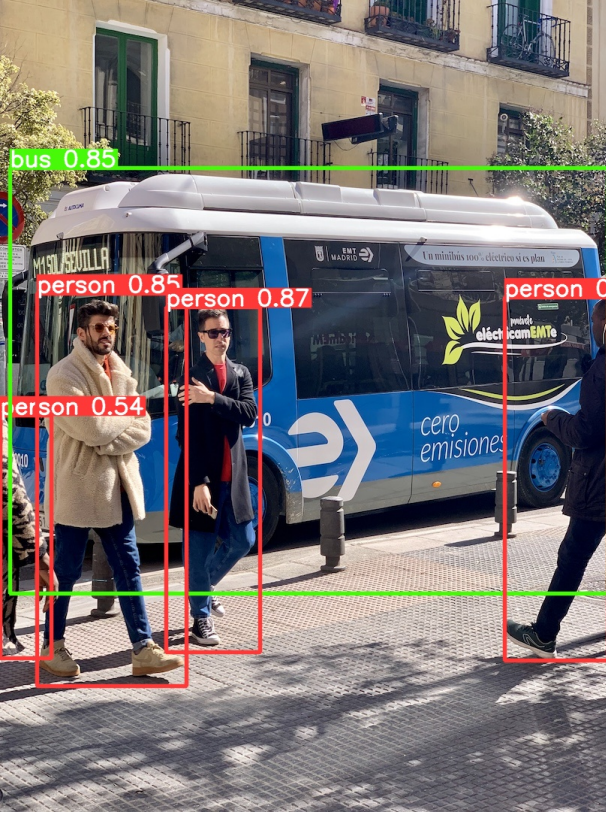
最后附上一张Yolov5的性能图,和实际检测效果图(yolov5s);


YOLO论文+代码数据🚀🚀🚀
关注下方《学姐带你玩AI》
回复“YOLO”免费领取
码字不易,欢迎大家点赞评论收藏!